
基于ML-kNN多标记学习的中医体质辨识模型研究*
2020-04-06 07:15周作建宋懿花商洪涛战丽彬
世界科学技术-中医药现代化 2020年10期
严 玲,周作建**,宋懿花,胡 云,商洪涛,战丽彬,董 青
(1. 南京中医药大学人工智能与信息技术学院 南京 210046;2. 江苏省中医院 南京 210029;3. 南京中医药大学中医学院·中西医结合学院 南京 210046;4. 连云港市卫生健康委员会 连云港 222007)
1 引言
中医认为,疾病的发生及发展与体质差异有一定联系。体质是个体在生命周期中形成的形态结构、生理功能和心理状态方面相对稳定的固有特质[1]。体质因人而异,但可通过类来划分体质特征,“王琦中医体质九分法”[2]将中医体质分为平和质、气虚质、阳虚质、阴虚质、痰湿质、湿热质、血瘀质、气郁质、特禀质,是目前权威且主流的体质划分方法。“治未病”[3]是中医学的主要研究内容之一,强调未病先防、欲病早治、既病防变,虽然体质在每个个体中都有一定的差异性,但是把握个体体质的差异性以及群体体质的规律性有助于将疾病从“治病”到“防病”的转变。中医体质辨识[4]就是以人的体质为认知对象,通过某些方式判断个体所属体质类型,从整体上把握健康与疾病的个体差异,进而制定适宜的治疗、促进等干预措施,弥补西医体检在“未病先防”的不足。体质辨识的主要工作[5]包括辨识个体体质状态、年龄老少、南北居住、奉养优劣等,从而判断所属体质类别。《“健康中国2030”规划纲要》《中国防治慢性病中长期规划(2017-2025年)》以及习总书记在十九大报告中均强调,为实施健康中国战略需以预防为主,发挥中医在“治未病”中的重要作用,而中医体质辨识是“治未病”的具体措施,有效的、高效的体质辨识已经成为目前中医治未病的重要课题之一。
目前中医体质辨识研究领域主要采用体质辨识量表及统计分析方法,体质辨识量表几乎采用被列为中华中医药学会标准的《中医体质分类与判定》标准[6];统计分析方法基本采用SPSS软件作为分析工具。杨玲玲等[7]将中华中医药学会的《中医体质分类与判定》作为辨识量表,以问卷形式进行数据收集,采用一般性统计描述进行分析,但是只能判定单一体质类型;陈燕丽等[8]将《中医体质分类与判定》作为调查问卷,通过人工计算每一项得分及转化分从而判定所属的体质类型,但是每次计算需要花费40 min/人次,耗费较大的人力成本及时间成本;左文英等[9]同样将《中医体质分类与判定》作为量表计算条目的得分及转化分,并采用SPSS软件进行计量资料和计数资料的统计分析,得出社区高血压患者的体质分布规律。单个生命体会存在几种不同的体质类型,即存在主要体质类型和次要体质类型,回顾已有的体质辨识研究可以发现,大多数研究只是将《中医体质分类与判定》标准运用于特定的环境或人群,以此来分析体质的分布规律,从而进行干预措施的建议。但是体质辨识量表本身会花费大量的人力成本,随着人工智能领域的兴起及发展,中医体质辨识的智能化研究需要进一步被提出,考虑到个体与体质之间存在一对多的关系,由此机器学习中的多标记学习算法可以应用在中医体质类型智能化辨识的研究中。本文提出了基于多标记k近邻算法(multi-label k nearest neighbor,ML-kNN)的中医体质辨识模型,为中医体质辨识的智能化、自动化研究提供新思路和新方法。
2 相关知识
多标记学习[10,11]研究 1 个单独实例与 1 组标签相关联的问题。假设xi为输入,Yi为输出,用(xi,Y)i表示1 个样本集中的1 个输入输出对,其中Yi是1 个二进制向量,y(ijyi1、yi2……yiq)表示第i个样本的第j个标记,yij=0表示该标记为负,yij=1表示该类别为正,这就是多标记学习基本思想。在多标记学习中,训练集中的样本都对应多个标记,目标任务是预测测试样本的标记集合。
2.1 ML-kNN算法
ML-kNN[12-14]改造“惰性学习”k近邻算法以适应多标记数据,使用kNN 的思想查找训练集中的k个近邻样本,并使用最大后验概率确定测试样本的标记集合。给定多标记训练集D={(xi,Yi)|1 ≤i≤m},测试示例x,假设Q(x)代表x在训练集中的k个近邻样本的集合,那么对于j个类别yj(1 ≤j≤q),Q(x)中标签j为1的样本数可表示为每个标记先验概率可表示为其中s为平滑项,m为训练集样本数,q为标签数。未知样本的每个标记条件概率可表示为(1 ≤j≤q,0 ≤Cj≤k),其中kj[r]表示自身及k近邻中r个近邻均具有标记yj的训练样本个数。将先验概率及条件概率代入多标记分类器h(x) ={yj|P(Hj|Cj)/P(¬Hj|Cj)>0.5,1 ≤j≤q}获得测试样本的标记集合。
2.2 ML-kNN评价指标
多标记评价指标[15]首先评价多标记分类器在单个测试样本上的分类效果,最终返回其在整个测试样本集上的“均值”。假定多标记分类器表示为h(.),多标记测试集表示为S={(xi,Yi)|1 ≤i≤p},其中Yi为xi的标记集合,p为测试集样本数,用如下多标记评价指标评估模型效果。
2.2.1 汉明损失
汉明损失[16](hamming loss,HLoss)计算分类器预测出的结果序列与实际结果序列之间数值上的距离,用来评估样本在单个标记上的分类错误的情况。HLoss 取值越小,分类器预测结果越好,最优值为HLoss(h)= 0。表达式为其中q为所有标签总数。
2.2.2 1-错误率
1-错误率[17](OneError)用来评估样本类别标记序列最前端的标记不属于相关标记集合的情况。OneError取值越小,系统性能越优,最优值为OneError(h)= 0。表达式为其中,f(.,.)为h(.)对应的实值函数。
2.2.3 覆盖率
覆盖率[18](Coverage)用于评估样本类别标记序列中,覆盖所有相关标记所要的搜索深度情况。Coverage 取值越小,系统性能越优,最优值为表达式为:Coverage(h) =其中,rank为与实值函数f(.,.)f(.,.)对应的排序函数。
2.2.4 排序损失
排序损失[19](ranking loss,RLoss)用于评估样本类别标记序列中无关标记与相关标记排序错误的情况。RLoss取值越小,系统性能越优,最优值为RLoss(h)=0。表达式为:其中,为集合Yi的补集。
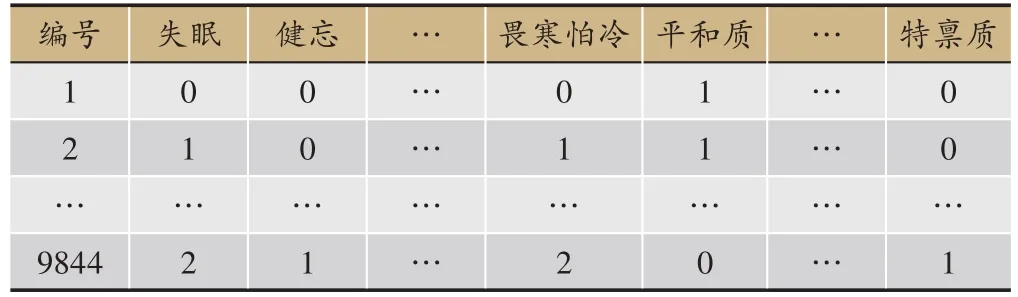
表1 实验数据结构
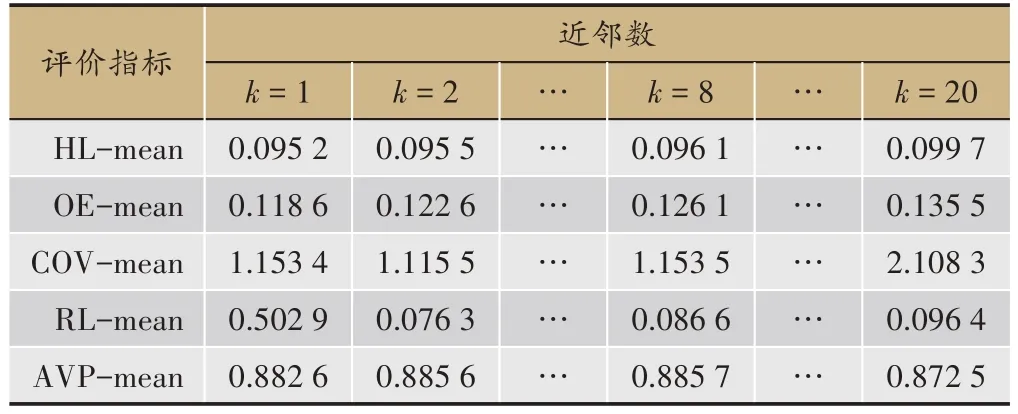
表2 不同近邻数下评价指标值
2.2.5 平均精度
平均精度[20](average precision,Avgprec)用于考察样本类别标记序列中,排序靠前的标记均为相关标记的情况。Avgprec 取值越大,系统性能越优,最优值为Avgprec(h) = 1。 表 达 式 为 :
3 中医体质辨识模型构建
3.1 数据描述
数据来源于江苏省中医院体检中心,共60个属性9个标签,过滤掉不完整、无意义的数据最终纳入9844条数据作为研究对象,其中60个属性是将原始数据的体质自测问题规范化为中医症状,9个标签是平和质、气虚质、阳虚质、阴虚质、痰湿质、湿热质、血瘀质、气郁质及特禀质9种体质类型,原始数据标签根据《中医体质分类与判定》计算相应条目分及转化分得到。属性值按照“没有(根本不)”“很少(有一点)”“有时(有些)”“经常(相当)”“总是(非常)”分别赋值为0、1、2、3、4,标签值按照体质类型有无分别赋值为1和0,实验数据结构见表1。
3.2 模型构建过程描述
中医体质辨识模型ML-kNN 构建过程:①使用k近邻算法查找训练集中与测试样本最接近的样本,通过计算先验概率及后验概率预测测试样本的体质标签矩阵,详细步骤如下:
初始化:指定体质数据样本为x,体质标签集合Y⊆ Ω,体质标签l ∈ Ω,样本体质标签向量y→x,样本x在训练集中的k近邻N(x),测试样本t(2952 条体质数据),初始化平滑参数s为1。
Step1:根据公式(1)、(2)分别求得体质标签值为1、0的先验概率。

Step2:计算N(x),并根据公式(3)、(4)分别求得体质标签值为1和0的后验概率。其中c[j]指训练样本中含有l且其k近邻中有j个l的样本数。

Step3:计算测试样本t的k近邻N(t),并根据公式(5)、(6)求得t的体质标签集合

②采用10折交叉验证,每次训练将数据集随机分为10 份,按9∶1 的比例分配训练集与测试集,以此考察体质辨识模型的拟合性能。
③从1-20 调整k值以寻找模型最佳参数,并运用5项评价指标的均值评估模型预测效果。
3.3 模型构建结果与应用
采用10 折交叉验证训练模型,并在1-20 之间调整k值,评价指标对应的值见表2,从表中可以看出,模型的平均精度不会随着近邻数的增加而增加,当k=8时,模型的 HLoss、OneError、Coverage 及 RLoss 的取值相对较小且Avgprec 最高,模型效果最佳,体质分类效果最好,此时平均汉明损失(HL-mean)为0.096 1,平均1-错误率(OE-mean)为0.126 1,平均覆盖率(COV-mean)为1.153 5,平均排序损失(RL-mean)为0.086 6,平均精度(AVP-mean)为88.57%。江苏省中医院体检中心体质辨识根据《中医体质分类与判定》所列出的问题条目计算得出,而本文基于体检中心数据建立的体质辨识模型在评价指标中表现良好,有科学意义,表明ML-kNN 算法用于体质辨识是有效的。综上说明,ML-kNN 模型解决中医体质智能化辨识问题及其存在的体质多标记问题有现实意义。
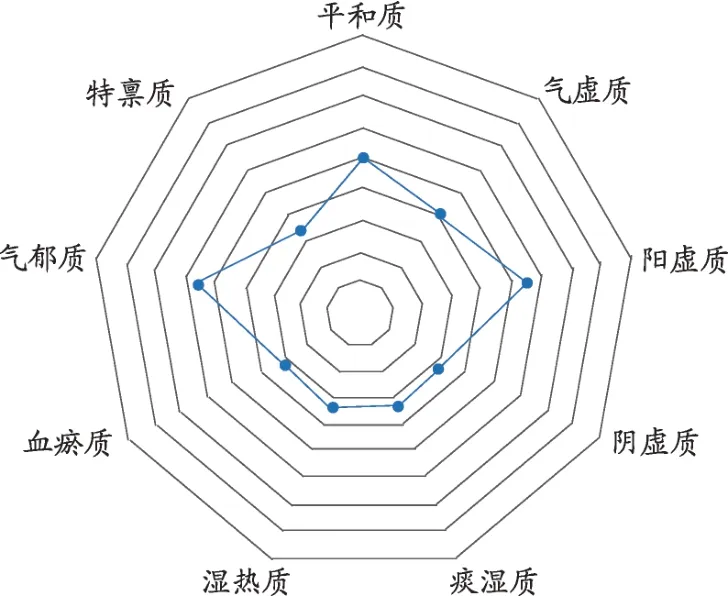
图1 体质辨识可视化结果
基于ML-kNN 算法建立的中医体质辨识模型能够以可视化的界面展示体质辨识结果,如图1所示,体质辨识的结果可以通过可视化界面直观地反映给用户,能够提高体检中体质辨识的效率,促进中医体质辨识客观化研究。
4 总结
中医认为疾病治疗应该将人作为整体,而体质状态可以从整体上把握健康与疾病,体质偏颇是疾病变化的依据,疾病发生及发展与体质有一定的联系,由此体质辨识可为疾病预防及促进提供依据。目前研究中普遍采用的体质辨识量表无法避免测试者的主观意识,且随着体检人数的增加耗费大量的人力、物力,由此需建立科学的体质辨识方法;部分研究采用数据挖掘算法辨识体质,但是忽略了单一个体存在几个主次不一的体质类型而采用单标记学习算法,并不能较为科学准确地判断出体质类型,由此需要引入人工智能中的机器学习算法,建立多标记学习模型进行体质类型自动、客观辨识。本文运用ML-kNN 算法构建中医体质辨识模型,采用10 折交叉验证训练模型,并用多标记学习评价指标评估模型效果,最终模型的 HLoss、OneError、Coverage、RLoss 及Avgprec 的值证实了ML-kNN 算法运用在体质辨识中的可行性及有效性,且当近邻数的值为8 时模型的效果最佳,对中医体质的分类效果最好,表明采用ML-kNN 算法建立体质辨识模型一定程度上可以代替传统的体质辨识方法且能弥补单标记学习不能识别多个体质类型的局限性,节约人力、物力成本且符合中医辨识体质的思想,为中医体质辨识智能化及自动化发展提供新方法,为实施健康中国战略提供新思路。
猜你喜欢
中老年保健(2022年2期)2022-08-24
中老年保健(2022年4期)2022-08-22
中老年保健(2022年6期)2022-08-19
海峡姐妹(2020年7期)2020-08-13
领导决策信息(2018年16期)2018-09-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学学习与研究(2017年3期)2017-03-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
