
基于孤立森林算法的取用水量异常数据检测方法
2020-04-03 08:15赵臣啸薛惠锋
中国水利水电科学研究院学报 2020年1期
赵臣啸,薛惠锋,王 磊,万 毅
(1.中国航天系统科学与工程研究院,北京 100048;2.水利部水资源管理中心,北京 100053)
1 研究背景
水是基础性的自然资源和战略性的经济资源,是生态环境的控制性要素,是经济社会发展的重要支撑和保障,水资源供需矛盾突出是制约我国可持续发展的主要瓶颈之一。在当前全国范围内进行水资源税费改革的大背景下,水资源监控能力越来越受到社会各界的关注,保障取用水数据的准确性,对用水总量控制和水资源税征收具有重要意义。取用水量异常值的检测是保障取用水数据准确的重要手段之一。
异常值检测是数据挖掘中十分重要的部分,国内外学者在该领域提出了一系列的思路和方法,形成了较为完整的体系。目前,主要的异常值检测方法按照检测原理可分为基于偏差、基于统计、基于密度、基于聚类以及基于距离等方法[1]。传统的异常值检测方法以基于密度和基于偏差的方法为主。侍建国等[2]采用拉依达准则处理区域水文数据异常值,肖树臣等[3]运用格拉布斯法对实验数据进行分析和筛选,但此类异常值检测方法,都默认样本数据符合某种概率分布模型如正态分布、高斯分布等,而水资源监测数据随机性强、易受外界影响,仅简单将其归纳为某种分布缺乏科学性、严谨性。基于小波变换、基于最小二乘拟合法的异常值检测方式[4-6]本质上都是基于偏差的异常值检测方法,即首先利用小波变换或最小二乘拟合法对已有数据进行处理,再对处理后的数据与原始样本数据进行残差分析,彭小奇等[7]、方海泉等[8]在此基础上进行了研究。这类算法的主要问题在于,数据拟合本身以已有数据作为样本,拟合结果受已有数据影响较大,数据拟合中存在很多参数,不同的参数选择会对拟合结果产生较大影响。近年来,随着数据挖掘理论与实践水平的不断提升,越来越多的仿生算法被引入到异常值检测中。王琰等[9]将Bayes方法引入时间序列异常值检测,韩旻等[10]采用仿生学中的阴性选择算法对飞行数据异常值进行检测。文献[11]于2007年提出Isolation Forest算法并将其应用到异常值检测,张荣昌[12]、张为金[13]等分别将其应用到用电数据的分析方面,朱佳俊等[14]将孤立森林算法应用到用户画像的异常行为检测,均取得了很好的检测效果。
作为数据处理分析的第一步,数据异常值的检测一直以来都是数据挖掘领域研究者所关注的重点。水资源的开放性特点给水资源的监测和管理带来很多困难,对取用水数据异常值的检测不能简单沿用传统的异常值检测方法和模型,大数据时代的到来推动了数据挖掘领域向纵深发展,这为取用水数据的分析和利用提供了新的思路和方法。本文以某取水户日取水量数据为研究对象,以基于Ensemble的孤立森林算法为主要方法进行异常值的检测。
2 取用水量数据特征分析
本文以实际取水户的实际监测数据为试验样本,在实际取水过程中,数据存在很大的随机性,且易受外界不确定因素影响。无论基于哪种异常值检测方法,单纯依靠数据特征筛选异常值往往都是不全面的,且都存在一定程度的误报。对于取用水数据而言,基于数据特征只能找出“疑似异常值”,准确判定是否为异常值,还需要结合取水点其他信息以及专家知识,为方便理解,本文仍然使用“异常值”一词,但应该明确文中异常值与实际异常值存在的差异。
2.1 取用水量数据特征 取用水量数据属于典型的时间序列数据,数据整体具有明显的趋势性、周期性、随机性、综合性等特点。数据维度方面,以水利部组织建设的水资源管理系统为例,数据维度包含小时取水量(m3/h)、日取水量(m3/d)、年取水量(m3/a)等。不同维度下呈现的数据虽然紧密关联,但数据特征具有很大区别,在进行分析时,只能对同一维度的数据进行分析比较,不同维度间的数据不存在可比性。
不同于电力、石油等相对封闭、来源相对单一的资源,水资源具有开放、分散和不确定的特点,易受环境及人为因素的影响。这些特点给水资源的监控和管理带来挑战,行政部门如何在海量监测数据中甄别有效、真实数据,并通过对数据的分析支撑决策,是当前水资源监控能力建设需要解决的重要问题。
2.2 异常数据定义及分类 在数据挖掘领域,通常将数据中的异常点定义为离群点(outlier),将异常检测定义为偏差检测(deviation detection)或例外挖掘(exception mining)。异常数据具有以下基本特点:①在数据样本中占比很少;②相比于样本中的正常数据,异常数据具有明显不同的属性。作为时间序列数据,取用水量数据异常值还具有复杂性、多样性、滞后性和被动性的特点。
根据异常的成因进行分类,取用水量异常数据可分为两大类:主体异常和客体异常。主体异常是指取水行为本身存在异常,在数据特征上表现为数据突然上升或下降、与相邻时间数据规律不符,通常不会连续出现;客体异常是指数据采集、传输、交换和存储的过程存在异常,在数据特征上表现为连续出现极大数据或极小数据,甚至出现负值。
根据异常数据特点分类,取用水量异常数据可分为异常大值、异常小值、零值、负值、缺报值等类型。零值、负值成因复杂,需要筛选出来进行人工鉴别,考查数据中的零值是否为异常时,需结合取用水户类型,季节性取水的灌区、企业等连续出现零值不应判定为异常;异常大值、异常小值是指有违于样本数据正常取水规律的值,不能简单理解为某一阈值之外的数据,取水量处于正常范围但与临近时间点取水规律不一致的数据应判断为异常数据;缺报值一般是由客体异常造成的,若对缺报值进行简单的删除或置零处理,将对缺报值附近数据的准确性造成影响,因此在数据处理时,应采用统计方法处理缺报值。
根据异常数据识别难易度分类,取用水量异常数据还可分为可直观识别的数据异常值和不能直观识别的数据异常值,具体类型见表1。

表1 取用水量数据异常值分类
3 数据预处理与数据异常值筛选方法
异常值筛选是数据进行分析处理的前提,数据预处理则是数据异常值筛选的重要基础。由上文可知,取用水监测数据异常值可分为可直观识别的数据异常值和难以直观识别的数据异常值,数据预处理的目的即区分这两类异常值,并首先对可直观识别的数据异常值进行处理,以减小甚至消除此类数据异常值对周围数据的影响,从而提高难以直观识别的数据异常值的检出率,降低检错率。
3.1 数据预处理方法 通常,可直观识别的数据异常值是指数据中的负值、缺报值等,这些异常值往往难以通过某种特定方式修正,需要结合专家知识进行人工判断。
在已有研究中,通常将可直观识别的异常值直接剔除或置零,这种处理方法简单易实现,但忽略了被剔除、置零数据点对其他数据点产生的影响。若使用基于偏差的异常值检测算法进行异常值检测,可直观识别的异常值处理不当将大大提高算法的误检率。在取用水监测数据分析中,经常会对数据未来趋势进行预测,基于拟合的预测方法十分依赖已有数据的数据特征,若只对可直观识别的异常值进行简单的剔除或置零,将严重影响拟合精度。
本文采用均值法对可直观识别异常值进行处理,这种方法虽然会影响数据的方差,损失数据信息,但保证了数据的连续性、平稳性和合理性,极大地方便了后续分析。
可直观识别异常值的处理一般可分为两种情况:


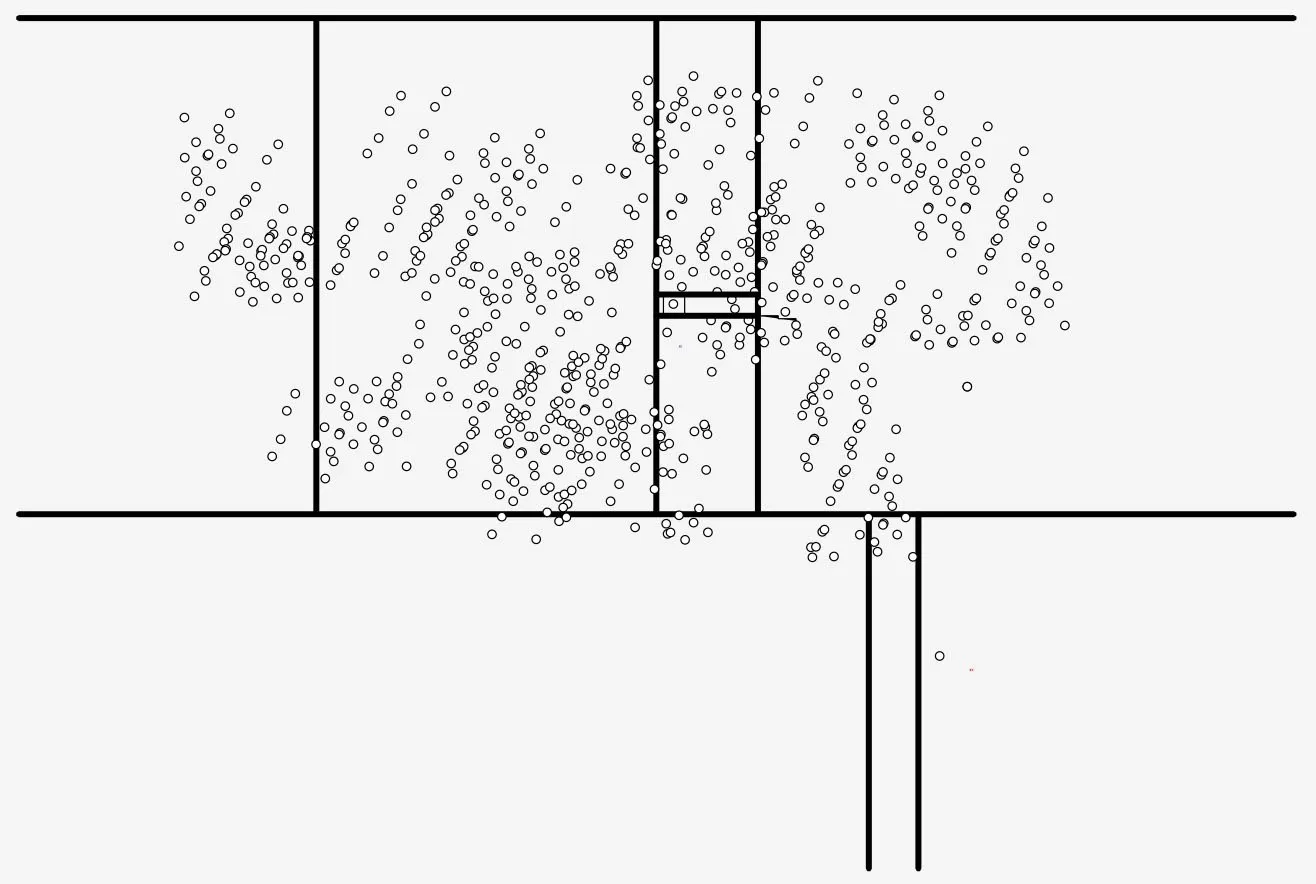
图1 孤立森林算法原理
3.2 基于孤立森林的数据异常值检测算法 孤立森林(Isolation Forest)是一种由周志华等人提出的基于Ensemble的快速异常值检测算法,具有线性时间复杂度和高精准度,是符合大数据处理要求的神经网络算法(图1)。与本文对异常值的定义一致,孤立森林算法将异常值定义为“容易被孤立的离群点”,即分布稀疏且离密度高的群体较远的点。孤立森林算法的基本思想是,对描述同一对象的不同维度的数据构建一系列的随机二叉树。这些随机二叉树每个节点或有两个子节点,或为叶子节点。通过在取值范围内随机取值,将该范围内的数据划分为两个分支,再在两个分支中继续随机取值进行划分,不断重复,直到不可分割或者树的高度达到上限。相对于数据样本中的正常点,异常点通常表现出稀少的特性,因此在随机树中异常数据会很快被划分到叶子节点中,即异常数据在随机树中的深度较浅;相反,正常数据由于集中为簇且密度较大,往往通过多次分割才能划分为叶子节点。因此,该算法通过叶子节点到根节点之间的路径长度,可以快速判断一条数据是否为异常数据,将多维数据的分割结果相综合,则可以得知某一对象是否为异常对象。例如,图1中,xi为正常对象,需经过多次切割,才能将其从所有数据中孤立出来;xo为异常对象,只需经过较少次数的切割即可将其孤立。
孤立森林算法的实现过程可以分为两个阶段。
(1)构建t个孤立二叉树(Isolation Tree)组成的孤立森林。孤立二叉树是构成孤立森林的基本元素,由于孤立森林算法的学习过程属于无监督学习,即不需要专门的训练集对其进行训练,因此构造孤立二叉树的过程大大简化:①从待检测数据中随机选择φ个样本点作为子样本集,放入树的根节点;②随机选取一个数据维度,在当前节点数据中随机产生一个切割点p—切割点产生于当前节点数据中指定维度的最大值和最小值之间;③以此切割点为基础形成一个超平面,将当前节点的数据空间划分成2个子空间,把指定维度中小于p的数据放在当前节点的左边,把大于等于p的数据放在当前节点的右边;④在子节点中递归步骤②、③,不断构造新的子节点,当数据本身不可再分或已经达到树的最大深度log2φ时,递归过程结束。
生成一个孤立二叉树的伪代码如表1所示。

表1 孤立二叉树伪代码
(2)对被检测样本计算异常分值。获得t棵孤立二叉树后,孤立森林形成,训练过程结束。由于孤立二叉树的形成具有随机性,单独一棵树的结果并不可靠,因此对于待测数据样本,令其遍历孤立森林中的每一棵树,计算数据样本中的每一个样本值落在每棵孤立二叉树的第几层,最后得出样本x在每棵树的平均深度h(x)。异常分值与样本在孤立二叉树的深度有关,当样本在孤立二叉树中的深度越小,则异常分值越高,即该样本为异常样本的概率越大。
对n个数据样本,将其路径长度记为h(n),则其平均路径长度c(n)为:

其中H(i)为谐波数,等于ln(i)+欧拉常数。
通过对孤立二叉树的长度进行归一化处理,可以得到介于0~1之间的数即为被检测样本的异常分值。记s(x ,n)为异常指数,有:

式中:E(h(x))为对某一个给定值的路径长度的期望;s(x,n)为对该值所对应的路径的归一化。

孤立森林具有以下特点:①孤立森林具有线性时间复杂度,不需要计算距离或者密度来寻找异常数据;②抗噪能力强;③模型稳定性好;④可用于分布式系统,运算效率高;⑤不善于处理特别高维的数据,且仅对全局稀疏点敏感。
4 实例分析
为充分验证孤立森林算法的有效性并比较该算法与传统异常值检测算法的性能差异,本文以传统的基于偏差的最小二乘拟合算法作为对比项。在数据预处理完成后,首先运用孤立森林算法对数据样本进行异常值检测,分析检测结果的合理性和准确性;再对两种异常值检测方法的检测结果进行对比,验证孤立森林算法在处理此类问题方面的优越性。
4.1 数据说明 试验采用水利部水资源管理中心提供的广东省辖区内国家重点监控用水户某城市供水企业2016年日取水量数据366条、2017年日取水量数据365条,主要研究供水企业取水量变化情况。供水企业担负着保障本地区生活、生产用水的直接责任,在水资源监测系统中处于主体地位。
4.2 可直观识别异常值的处理 以该城市供水企业2017年日取水量监测数据为例。在全部365条数据中,共有有效数据350条,缺失数据15条。数据中不存在负值、零值、连续不变值等情况,补充缺失数据后可直接进行分析检测异常值,数据预处理结果如表2所示。在此基础上,对预处理后的样本数据进行特征分析,结果如表3所示。

表2 2017年数据预处理

表3 样本数据特征分析
图2为2017年数据预处理前后对比。从图2中可以看出,经过数据预处理,数据波形中的断点消失,而数据的总体特征得以完整保留,为后续的数据分析奠定了基础。应该注意,进行补充的数据点本身已经属于可直观识别的异常值,因此在进一步分析时,即使异常点中存在修补数据,也不应纳入统计,以避免重复统计,从而降低误检率。
同上,对该城市供水企业2016年数据进行可直观识别异常值的处理。在全部366条数据中,共有有效数据364条,缺失数据2条。数据中不存在负值、零值、固定值等情况,补充缺失数据后可直接进行分析检测异常值,数据预处理结果如表4所示,2016年数据预处理前后效果对比见图3。与对2017年数据的处理方式相同,对预处理后的2016年样本数据进行特征分析,结果如表5所示。

图2 2017年数据预处理前后效果对比

表4 2016年数据预处理

表5 样本数据特征分析

图3 2016年数据预处理前后效果对比
4.3 非可直观识别异常值的处理 孤立森林算法运用了集成学习的思想,在基于孤立森林的取用水量数据异常值算法中有两个重要参数:孤立二叉树采样数φ,称为采样规模;孤立二叉树数量t,称为集成规模。
采样规模和集成规模的确定遵循以下规则:①孤立森林算法的计算时间随着采样规模和集成规模的增加呈现线性增长趋势;②当孤立二叉树数量t达到一定值以后,模型精度的提升十分有限;③当采样规模过大时,模型的性能会明显下降,查准率、查全率均会受到影响。
以此为基础,结合已有研究的经验[15],本文将采样规模设定为256;集成规模设定为100。将预处理后的2016年、2017年数据分别输入试验程序,将得到全部数据点在100棵孤立二叉树上的平均路径长度。

表6给出了数据样本中异常概率最高的10个数据。如表6所示,这些数据在数据样本中的分布情况见图4。
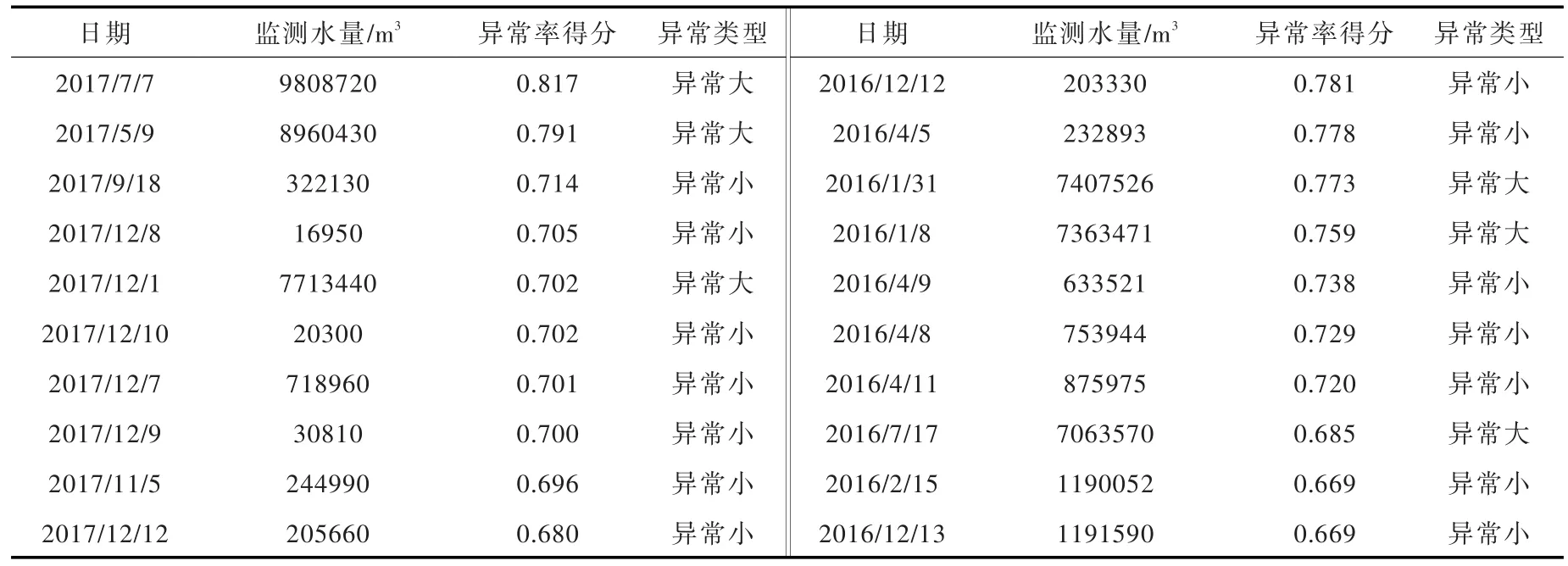
表6 数据异常值检测结果(孤立森林算法)
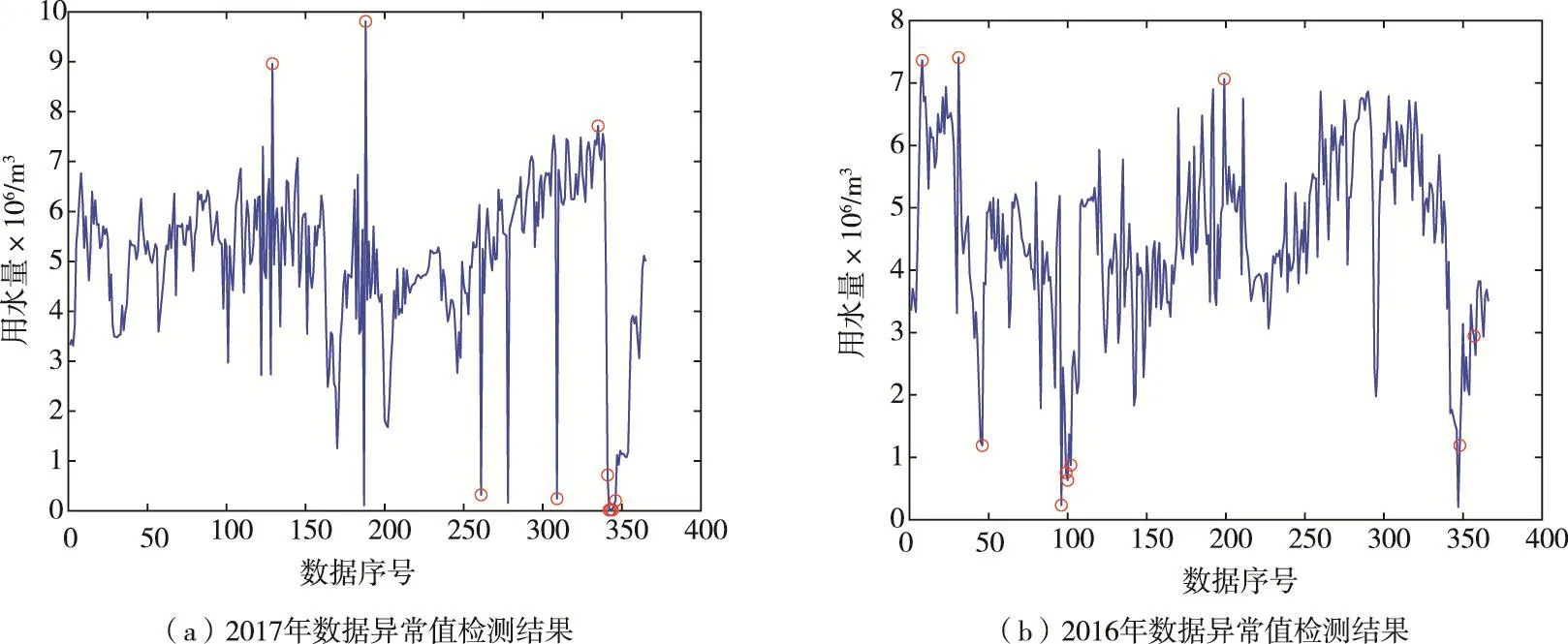
图4 数据异常值检测结果(孤立森林算法)
孤立森林算法本身并不会对样本数据中存在的异常值数量和规模进行限定,仅按照异常概率进行排序。在本文中,异常值的确定结合了专家经验。首先,对数据异常值进行检测的首要目的是监控取用水总量,因此数据异常值中最需要关注的是极大值和极小值。当出现极大值时,应考虑取水户是否存在超量取水,或计量统计过程是否产生偏差;当出现极小值时,应考虑取水户是否存在偷采行为。
4.4 算法效果评估 为验证孤立森林算法的检测效果和性能,引入传统的最小二乘拟合异常值检测算法,这一算法的原理是基于已有数据进行曲线拟合,计算得到的拟合曲线与原有数据之间的偏差,通过残差分析得出残差较大的数据点,将其认定为异常值。采用最小二乘法拟合法获得的异常值检验结果如表7所示,异常值在数据样本中的分布情况见图5。
将孤立森林算法的检测结果与最小二乘拟合法的检测结果进行对比。以孤立森林算法的检测结果为基准,两种算法的检测重合度为50%。与最小二乘拟合法相比,孤立森林算法对连续出现的异常值具有较高的检出率,最小二乘拟合法虽然能检出部分异常数据,但对于连续出现的异常值缺乏有效检测,且对某些接近均值或中位数的正常波动数据存在误检。

表7 异常值检测结果(最小二乘拟合法)
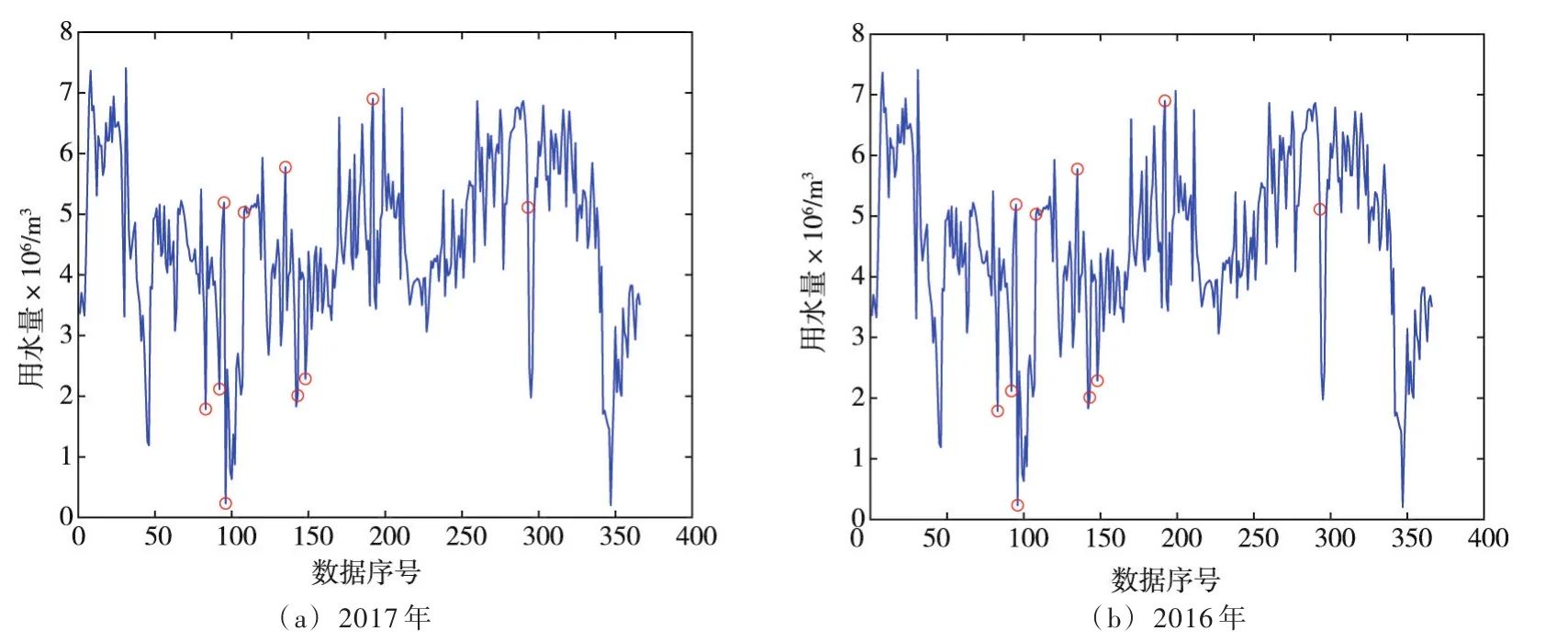
图5 数据异常值检测结果(最小二乘拟合法)
此外,传统的异常值检测算法通常具有滞后性,无法做到对异常值的实时监测,孤立森林算法在这一方面进行了优化,已有数据的特征已经存储在各个孤立二叉树中,即孤立森林已经涵盖了已有数据的基本特征,以此为基础可为按时间顺序出现的新数据进行判断。
4.5 讨论 取用水量监测数据存在多个维度,而不同维度之间的数据不具备可比性,这一特点限制了本文对于数据的应用范围。如本文所使用的样本数据,当数据维度缩减到一维时,孤立森林算法实际上将异常值的筛选问题抽象为数据出现的频次问题,异常值出现频次较低,分布稀疏,因此更容易被区分出来,孤立森林算法在本研究中的应用正是基于这一原理。但这种单一维度的数据处理并没有发挥出孤立森林算法的最佳性能。
若能将数据维度进行拓展,运用孤立森林算法就能实现对数据更立体、更全面的分析。假设将取水点的日取水数据细化为小时取水数据,则1维数据被拓展到24个维度,这24个值共同描绘了某一取水点某日的取水行为。将该取水点一年的小时取水量数据进行综合,可以得到一个365×24的矩阵,在此基础上运用孤立森林算法,算出平均路径,则可以对365 d的取水行为进行排序,得到最可能属于异常取水行为的数据。这种方式基于对小时取水量的全面分析,数据量大,孤立森林的优势得以完全发挥。
5 结论
对取用水量数据进行分析,得出取用水量数据具有趋势性、周期性、随机性、综合性的特点,且数据维度多元,不同维度的数据变化趋势不同,缺乏可比性;按照数据特点,将取用水量数据异常值分为异常大值、异常小值、零负值、缺报值等4类;孤立森林算法基于数据本身的位置特征筛选异常值,具有抗噪能力强、模型稳定性好、运算效率高的特点,该方法可用于处理水量数据异常值检测。通过实证分析,以最小二乘法为代表的传统的基于偏差的数据异常值检测算法易受异常数据干扰,检测结果不稳定,无法发现连续出现的异常值,孤立森林算法基于数据整体特征,不易受数据中异常值的影响,对各类异常值有较高的检出率。
水资源管理系统中的数据以小时为单位进行上报,将日水量数据分解为小时水量数据,可以在更高维度描述一天内的取水行为;在处理高维数据异常值问题时,孤立森林算法使用超平面对高维数据进行分割,相比传统方法效率更高,筛选结果更加准确。
猜你喜欢
电子制作(2022年16期)2022-09-23
舰船电子工程(2022年7期)2022-09-06
温州大学学报(自然科学版)(2022年2期)2022-05-30
小学科学(学生版)(2021年5期)2021-07-22
现代计算机(2021年14期)2021-07-09
小学科学(2021年5期)2021-06-24
潍坊学院学报(2020年2期)2021-01-18
今日农业(2020年14期)2020-12-14
计算机与数字工程(2020年8期)2020-10-14
制导与引信(2017年3期)2017-11-02
