
面向研究性项目文档的知识画像模型
2020-04-02 09:27艾中良刘忠麟李常宝
计算机与现代化 2020年2期
武 迪,艾中良,刘忠麟,李常宝
(华北计算技术研究所,北京 100083)
0 引 言
在文档知识化解析日益重要的今天,如何高效准确地获取特定领域文档中的核心知识成为当下的研究热点。在文档知识化的背景下,项目申报和论证中形成的大量限定领域的研究性项目文档需要进行文档结构化解析,提取文档的核心知识,为面向领域的项目规划与协调、项目论证与管理、项目考核与评估等实际应用提供信息检索技术支撑。
面向领域的深层语义搜索和文档相关性分析的效果很大程度上取决于知识描述模型对特定领域文档中知识的描述准确率。基于XML文档的知识描述模型的研究[1-3]已经比较完善,针对文本文档的知识描述模型的研究有很强的限定性,普适性不足。近年来,根据特定领域用知识元描述文本文档的研究[4-6]发展迅速,知识元可以完善地描述文档知识,但忽略了原始文档的行文结构,难以支撑多维度搜索的需求。同时,另一类通过建立文档结构树描述文本文档的方法在专利文献[7]、PDF文档[8]等领域也有良好的应用效果。文档结构树保留了原始文档的行文结构,但在文档知识的提取上有所欠缺。
除了选择科学的知识描述模型架构,设计适应特定领域文档的知识提取方法也是文档知识化解析的重要一环。基于整篇文档提取知识和要点短句的研究[9-12],已经形成较完整的理论体系,但这类知识提取方法的粒度粗,提取中知识信息损失多,不利于提高知识描述准确率。针对语义段落的知识提取,有3类主流思路[13]:1)人工提取,此类方法难以处理大规模文档;2)利用领域文档类型定义(DTD)和文档模式进行知识提取[14-15],此类方法对文本文档适应性差,精确度不足;3)利用词汇的语义分析进行知识提取,这类方法广泛应用于限定领域文档的知识要点提取[16]。利用词汇进行知识提取的相似研究主要有:使用分析句子主要成分并加权统计的方法查找知识要点[17];在自然语言理解处理过程中加入固定提取规则配合的基于本体的语义知识提取[18-19];采用集成学习的思路,结合2个语义要点的选择公式进行联合选择[20]。这些方法的知识提取效果良好,但难以直接移植到特定领域文档的处理中。近些年来,句子级的文档知识提取的方法也有大量研究[21-22]。句子级的知识提取方法精准程度更高,但对文档质量有较高要求,难以适应文档结构频繁变动的文档集。
现有研究在文档描述模型建立和文档知识提取方面都取得了一定的成果,但未对结合知识提取的文档描述模型进行相关研究。本文旨在提高研究性项目文档的知识的管理和利用效率,分析研究性项目文档的行文结构,结合现有研究成果,提出建立文档知识画像描述研究性项目文档,并按语义段落提取文档核心知识,准确地对文档中的知识进行自动提取,更全面、深入地表达研究性项目文档的知识。
1 研究性项目文档的知识画像构建
研究性项目文档的知识画像是多层次、多粒度地储存研究性项目文档知识要素的类文档结构树的文档描述模型。该模型对项目文档的知识进行形式化描述,并为项目文档相关性搜索和查重提供描述模型支撑。
研究性项目文档主要包括合同文档和项目规划设计文档等类型,在写作上有相对固定的行文结构,其中与核心知识相关的描述结构包括基本信息、研究目标、主要研究内容和技术要求及指标,这4个部分的结构之间有明确的区分标识。因此,一篇研究性项目文档可以转化为一个知识画像对象ProjectDocument,研究性项目文档知识画像在第一层次可以形式化地描述为ProjectDocument=
1)DId是文档知识画像的序号,用于标识不同的文档实例。
2)DBasicInfomation是文档的基本信息,包含文档类型、文档名称、项目负责人、承担单位等描述文档基本内容的字段。
3)DResearchObject是对项目文档中研究目标核心知识的提取结果,可以用于支撑基于关键词的特征语义计算。
4)DTechniqueItem是对项目文档中技术条目核心知识的提取结果,主要包括主要研究内容和技术要求,可以用于支持特征的自然语言理解。
5)DTechniqueIndicators是对项目文档中技术指标核心知识的提取结果,可以用于支持特征的自然语言理解。
研究性项目文档知识画像的第一层次描述模型如图1所示。该层次的5个要素在模型中属于并列关系,有同等的重要程度。
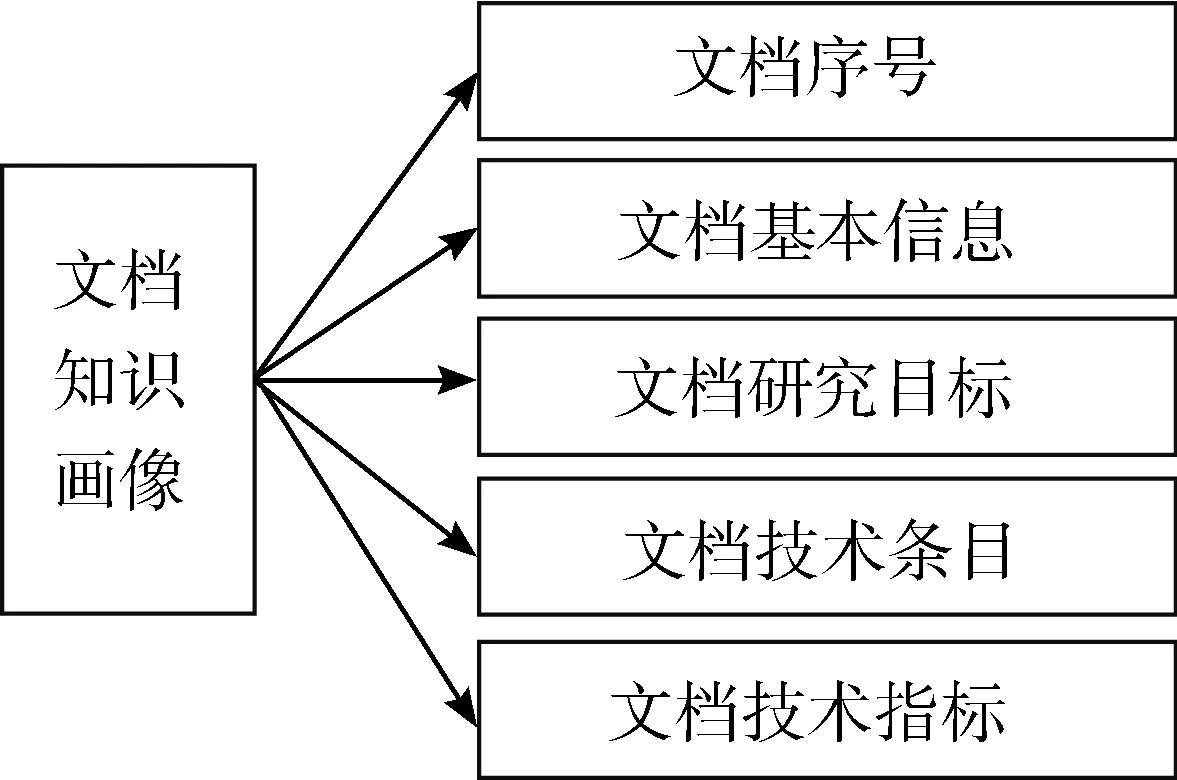
图1 研究性项目文档知识画像第一层次描述模型
文档中除DId外其余4个画像结构要素均对研究性项目文档构成独立语义描述能力,能够为文档知识信息的分析和搜索提供数据支撑。
第一层次描述模型中的文档研究内容和文档技术指标描述的文档知识内容比较相似,区别在于研究内容侧重于提取使用描述性的语言阐述的知识要点,而技术指标则侧重于提取有明确的指标结构表示的知识要点。
知识画像的第一层次描述模型将文档划分为5个一级结构要素,对知识信息的描述不够精准,粒度比较粗。为了提高研究性项目文档的知识描述精准度,同时提高对行文结构略有差异的文档的兼容性,第一层次模型中的部分要素需要进一步按条目划分,因此引入了第二层次描述模型——条目描述模型ItemModel。条目描述模型针对第一层次模型中的结构要素文档研究目标、文档技术条目和文档技术指标的内容进行多层次信息抽取和划分。
第一层次描述模型中的一级结构要素StructuralElement可以形式化地描述为StructuralElement=
1)IName是条目名称,表现为一个词或短句。
2)IOriginal是条目原文,即从研究性项目文档中抽取得到的对应文本段落。
3)IEssential是条目要点,表示为该条目抽取得到的核心短句。
4)IKeywords是条目关键词集,词集只包括经过筛选得到的名词和名词短语。
5)IFeature为条目特征知识,主要包括特征知识对象,每一个特征知识对象都是在该结构要素中出现的科学技术名词,如自然语言处理、疫苗、大功率芯片、铜锌合金等。
以一级结构要素文档研究目标为例,展示研究性项目文档知识画像的条目描述模型的架构,如图2所示。
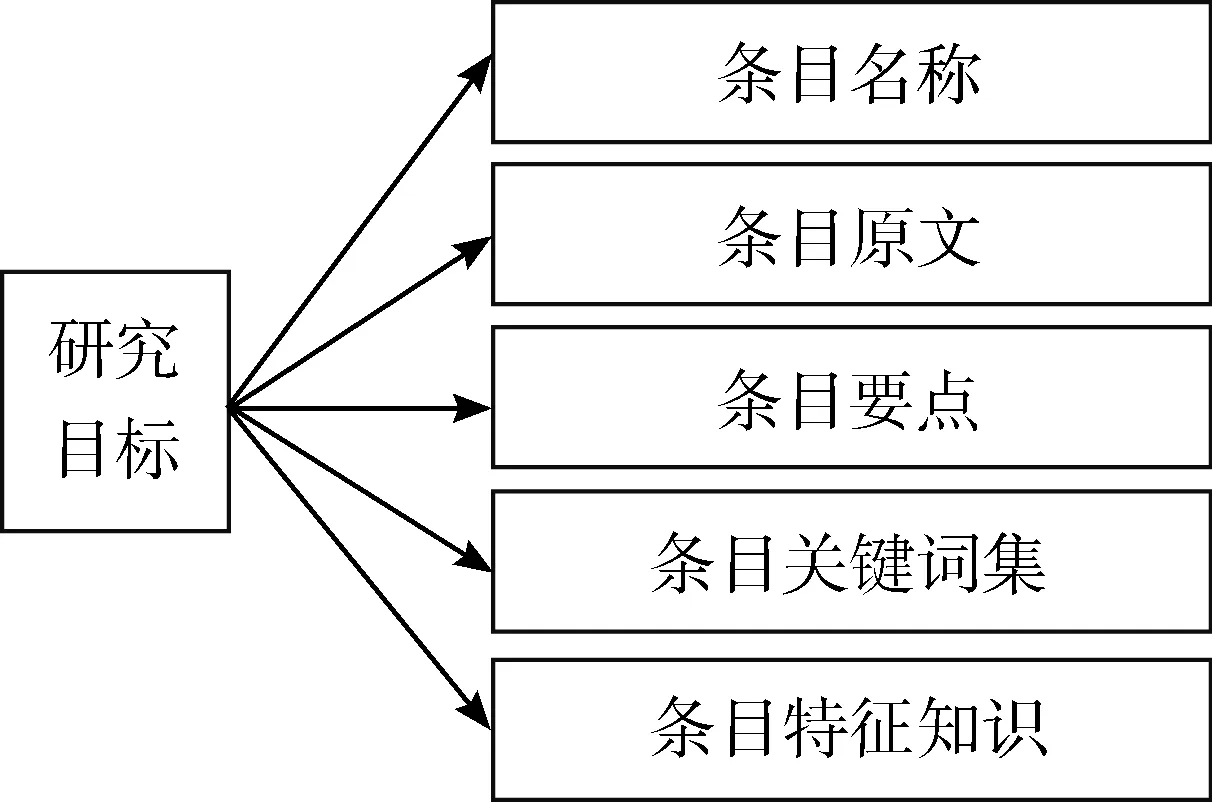
图2 研究性项目文档知识画像第二层次描述模型
该层次的描述模型支持不同粒度的知识描述,条目关键词集和条目特征知识的知识提取度最高,条目要点次之,条目原文未做知识提取处理,保留全部原文信息。随着知识提取程度的提高,非核心内容的信息损失增加,难以保留原文意图,对检索精准度产生影响。而多层次、多粒度的知识描述,可以提供多层次的源数据,提高检索精准度。
对研究性项目文档中的画像结构要素用条目描述模型进行结构化的解析,把非结构化的文档信息转化为多粒度、结构化的表示模型,进一步提高知识画像的知识抽取精准度。
针对文档技术条目和文档技术指标2个一级结构要素中核心的知识内容——指标信息,上述条目描述模型难以精确描述技术指标中体现的知识层次,需要引入结构化描述技术指标的第三层次描述模型——指标描述模型IndicatorModel。一条技术指标可用指标描述模型IndicatorModel=
1)IMainBody是技术指标的主体,通常为名词或者名词短语。
2)IRelation是技术指标的关系信息,包括描述比较关系的词语和其它形式的前提条件,如大于、等于、在1000摄氏度的环境下。
3)INumber是技术指标的数值,在绝大多数情况下与量纲字段同时出现。
4)IMagnitude是技术指标的量纲,主要包括各研究领域常用的计量单位,如米、km/s。
研究性项目文档知识画像的指标描述模型如图3所示。

图3 研究性项目文档知识画像的指标描述模型
指标描述模型承载每一条技术指标中的主要内容,并分类识别和储存,进一步细化指标中的知识信息,提高知识画像精准度。
2 研究性项目文档的知识提取
依据上一章建立的知识画像模型,一篇研究性项目文档可划分为5个一级结构要素,每一个一级结构要素又进一步按多层次、多粒度的原则进行知识提取,构建第二层次的描述结构。本文根据不同结构要素的知识提取粒度的差异,结合研究性项目文档相对固定的行文结构,设计了相应的知识提取方法,以准确填充知识画像模型中的所有结构要素。
研究性项目文档的知识提取流程如图4所示,不同粒度的二级结构要素采用相应的知识提取方法。条目原文使用语义段落划分的方法直接从文档截取,得到的原文支撑条目要点和条目关键词集的提取。条目要点的提取采用了结合行文结构的自动要点提取方法,关键词集的提取采用了针对名词的关键词提取方法。通过关键词集和特征知识库的匹配,从条目关键词集筛选得到条目特征知识。采用不同的知识提取方法得到的不同粒度的结构要素分别填充到知识画像的对应位置,保留其逻辑结构,并储存到数据库,完成研究性项目文档的知识提取。

图4 研究性项目文档的知识提取流程
2.1 条目原文的知识提取
条目原文是第二层次描述模型中的粒度最大的结构要素,也是条目要点、条目关键词集和条目特征知识的知识提取数据源。本文通过统计分析研究性项目文档的行文结构,总结所有的第二层次结构要素之间的语义分段标志点的特征规律。由于各部分内容都有较固定的标题或明确的标志词语,这些标志自然就是语义分段点。按照语义分段标识对文档的原文进行自动切分,组成若干知识画像的条目原文。
2.2 条目要点的知识提取
条目要点的粒度为短句,其主要内容是条目原文中提取的最能概括整体语义段落的一个或多个要点短句。大多数研究性项目文档的行文结构较固定,在研究目标、研究内容和技术指标等主要知识内容的介绍中,在语义段落中均采用首句概括式或尾句总结式的行文方式。针对此类结构,直接提取整体语义段落的首句或者尾句作为条目要点短句的候选对象。
同时,采用自动要点提取算法对同一段落进行要点提取,得到的短句作为另一类候选对象。研究性项目文档的领域广,知识覆盖面大,难以找到合适的训练文档集,采用无需训练的可从单篇文档提取要点的TextRank[23]算法更适应研究性项目文档的知识提取。
TextRank算法的核心思路是模拟人类对于段落要点的理解,拟定一个权重评价标准,给语义段落中的每一个句子迭代评分,最终给出排名靠前的若干个结果。该算法的核心计算过程如公式(1)所示:
(1)
段落中一个语句的权重,等于每一个与该语句相邻的语句的权重对该语句权重的贡献值,而TextRank算法认为段落中的所有语句都是相邻的。公式(1)中的ωij和ωjk均表示2个语句之间的相似程度,语句相似度的计算采用了BM25算法。所有语句的权重在经过反复迭代计算后达到稳定状态。
对于一段条目原文内容,先划分为大量短句,所有短句按相同的中文分词方法进行自动分词并排除停用词。短句的分词结果使用BM25相关性矩阵计算,迭代计算直至稳定,权重排序靠前的若干语句即为段落的要点短句的候选对象。
对于2类方法得到的条目要点的候选对象,采用交叉比对确定最终的条目要点。若2类方法得到的候选对象的相似程度大于70%,说明该段条目原文在行文中使用了首句概括式或尾句总结式的行文方式,选择该段落的首句或者尾句作为条目要点;若2类方法得到的候选对象的相似程度不足70%,说明该段条目原文在行文中使用了其他的行文方式,选择TextRank算法的提取结果作为条目要点。
2.3 条目关键词集和条目特征知识的知识提取
条目关键词集的粒度最细,其主要内容是条目原文中提取的最能反映语义段落知识的关键词的集合。关键词的提取同样采用了上文介绍的基于TextRank算法的自动提取技术。确定每一个单词的权重的公式如下:
(2)
公式(2)与计算句子权重的公式(1)相似,二者的区别是2个单词之间不存在句子相似度。TextRank算法认为,在一个段落中,并非所有单词都是相邻的,在计算每一个单词的权重时需要建立大小为5的窗口。计算单词的BM25相关性矩阵时,每个单词的权重只会影响前后距离为5以内的单词。根据迭代后稳定的矩阵,选择权重排序靠前的若干单词组成该条目的关键词集。
本文对大量研究性项目文档进行统计后发现,文档的核心知识在中文词性分类系统中都被判定为名词或者名词短语。基于这一文档特性,只有语义段落中出现的名词或者名词短语才能作为条目关键词集的候选对象。使用TextRank算法自动提取关键词时,仅名词和名词短语参与相关性计算,其他词性的词语全部被排除,保证关键词集只从段落出现的名词中筛选。这种改进的TextRank关键词提取算法可以提高知识提取精准度。
条目特征知识是条目原文中明确提到的知识名词的集合。条目特征知识通过条目关键词集和预先经专家总结得到的研究性项目文档特征知识库进行匹配后得出,每一项条目特征知识链接到特征知识库的对应位置,特征知识库主要包括特征知识ID、特征知识名称和特征知识简介3个属性,从而方便使用者通过条目特征知识进一步了解知识的具体信息。
2.4 其他要素的知识提取
针对技术指标这一类特殊的结构要素,预先统计研究性项目文档中技术指标的典型描述句式,建立适应各类句式的提取指标中主体、关系、数值和量纲的提取模板,灵活依据识别到的技术指标句式更换模板,抽取4类核心知识。
3 实验及结果分析
3.1 实验数据及评价指标
实验数据来自于不同研究领域项目产生的行文格式基本相同的研究性项目文档,总计316份文档。实验文档使用知识画像进行建模和知识提取,并比对研究性项目文档的第一层次模型中的结构要素文档研究目标、文档技术条目和文档技术指标的自动知识提取结果和经专家人工评定的知识提取结果,独立统计各结构要素知识提取结果的准确率(Accuracy)。若在条目要点上,自动提取结果和人工评定结果相同,则计为正确;若在条目关键词集上,自动提取结果和人工评定结果的重合程度不低于60%,则计为正确。计算平均值时采用各类要素权重相同的加权策略。
对照实验选择了无需训练的自动摘要提取方法——标准TextRank算法、基于图论的标准LexRank算法和基于词频统计的标准TF-IDF算法作为对照对象。TextRank算法、LexRank算法和TF-IDF算法的评价指标同样采用了各结构要素知识提取结果的准确率。
3.2 实验结果与分析
实验通过比对知识画像中的一级结构要素和二级结构要素在自动提取和人工评定结果上的差异,统计知识表达准确率,统计结果如表1所示。
表1 各类结构要素在316份研究性项目文档上的知识表达准确率
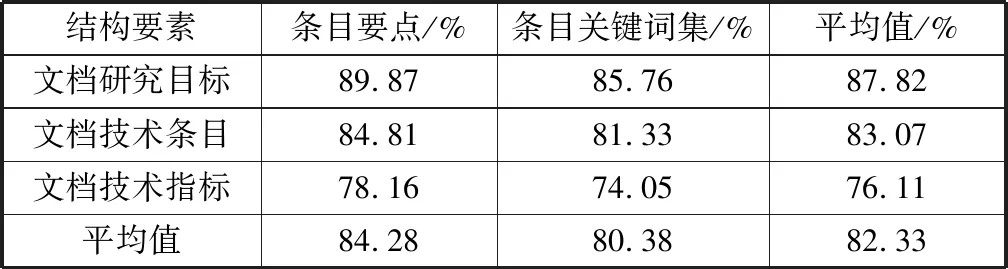
结构要素条目要点/%条目关键词集/%平均值/%文档研究目标89.8785.7687.82文档技术条目84.8181.3383.07文档技术指标78.1674.0576.11平均值84.2880.3882.33
从表1看出,条目要点的知识表达准确率要高于条目关键词集,主要原因是大多数研究性项目文档的行文规则都是首句或尾句概括的形式,交叉比对2类候选对象的处理方式能有效提高要点的知识抽取准确率。文档研究目标、文档技术条目和文档技术指标的知识表达准确率依次降低,主要原因是文档技术条目和文档技术指标的行文结构的变化形式多于文档研究目标,增加了知识提取的复杂度。
对照实验分别获取知识画像的知识提取算法和标准TextRank算法、标准LexRank算法和标准TF-IDF算法在316份研究性项目文档的二级结构要素上的自动提取结果,并与专家评定的知识提取结果对比,得到平均知识表达准确率,统计结果如表2所示。
表2 4类算法在316份研究性项目文档的二级结构要素上的平均知识表达准确率
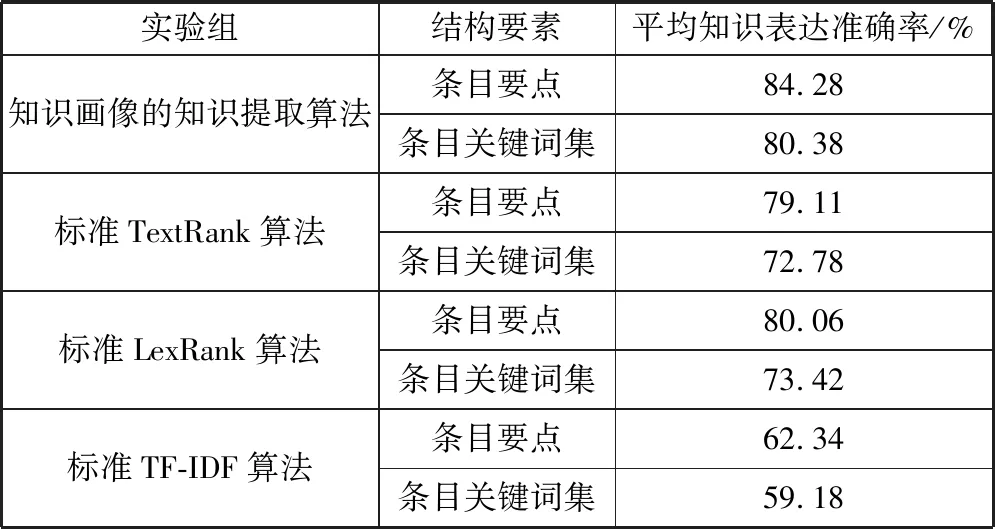
实验组结构要素平均知识表达准确率/%知识画像的知识提取算法条目要点84.28条目关键词集80.38标准TextRank算法条目要点79.11条目关键词集72.78标准LexRank算法条目要点80.06条目关键词集73.42标准TF-IDF算法条目要点62.34条目关键词集59.18
根据表2可知,TF-IDF算法的平均知识表达准确率最低,主要原因是研究性项目文档的领域范围大,大量要点关键词的逆文档概率(IDF)比较低,而且大量关键词在指定语义段落中的词频(TF)并非最高,导致统计结果和专家评定的结果出现较大差异。标准LexRank算法和标准TextRank算法的思路差异较大,但二者的准确率基本相同。知识画像的知识提取算法在2类结构要素的平均知识表达准确率分别比标准TextRank算法和标准LexRank算法提高了5.17%、7.60%和4.22%、6.96%,整体知识表达效果在研究性项目文档上优于文档知识提取常用的2类算法。在条目关键词集上的提升效果更明显,表明在筛选关键词的处理过程中预先排除非名词词性的候选词语可以有效提升知识的提取精准度。
从总体分析,研究性项目文档知识画像在实验涉及的316篇文档上达到了82.33%的整体准确率,说明知识画像能够有效地对研究性项目文档进行结构化解析和知识提取,并形成便于文档多粒度相关性分析和检索的层次化模型。
4 结束语
本文通过分析研究性项目文档的行文结构,提出了采用知识画像的文档描述模型结构化解析文档并提取文档中的知识,达到了较高的准确率,为进一步的文档相关性分析提供了数据支撑。该文档描述模型在研究性项目文档的解析工作上已经取得了较好的效果,不过在文档行文结构适应性和文档技术指标的知识提取过程上仍有进一步提升准确度的空间,另外在知识画像整体层次架构设计和各级结构要素的划分标准上也有进一步优化的价值。这些对模型的优化策略可以作为今后的研究方向。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
河北画报(2021年2期)2021-05-25
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
作文成功之路·小学版(2019年12期)2020-01-19
人间(2015年22期)2016-01-04
散文百家(2014年11期)2014-08-21
