
基于深度学习的实体和关系的联合抽取研究
2020-04-01 18:11艾鑫
现代计算机 2020年6期
艾鑫
(四川大学计算机学院,成都610065)
0 引言
随着互联网的快速发展,在信息爆炸式增长的今天,如何高效获取所需信息是一个热门研究问题,信息抽取技术应运而生[1]。实体识别和关系抽取是信息抽取中的两个子任务,实体识别是指从文本中识别出专有名称和有意义的数量短语并加以归类[2],而关系抽取在此基础上进行,目的是识别实体对之间存在的语义关系。例如:“中国的首都是北京”,首先识别文本中的实体:“北京”、“中国”,然后识别实体间关系,通常使用<主体,关系,客体>三元组表示,如<中国,首都,北京>。为了便于叙述,本文统称三元组中的客体和主体为关系的论元。实体关系抽取是构建知识库和知识图谱的基础,并且为问答系统、智能检索等下游应用提供支持,其意义不言而喻。
为了从文本中抽取关系三元组,Zelenko等[3]采用了一种流水线方法,即先进行实体识别,然后对已经抽取出的实体进行关系预测。但是,这种方法存在两个缺点:1)错误传播;2)忽略了实体识别和关系抽取的内在联系。因此,研究者提出了联合抽取方法。初期的联合抽取工作多数基于人工构造特征[4-5],特征提取耗时耗力。随着深度学习的发展,基于神经网络的联合抽取工作占据主流。如:Miwa等[6]、Gupta等[7]把使用神经网络进行端到端的联合抽取、Zheng等[8]提出了一个新标注模式并使用神经网络进行序列标注。
1 相关工作
目前基于深度学习的联合抽取方法大致可以分为两类:一是通过联合训练的方式,让两个子任务共享部分参数,如:Miwa等[6]首次提出端到端抽取的神经网络模型;二是采用联合建模的方式,直接对关系三元组进行建模,如:Zheng等[8]新标注模式(NovelTaging)、Zeng等[9]拷贝生成模型(CopyRE)。以下对这两类模型中几个具有代表性的工作进行详细阐述。
1.1 联合训练
Miwa等[4]在2016年首次将神经网络的应用于实体和关系的联合抽取,如图1所示。模型大致可分为三部分:编码层、实体识别层、关系抽取层。编码层使用的是一个双向的循环神经网络,可以让每个时刻的隐藏表达同时编码前后文的信息。另外,模型还将每个词的词性信息也编码到隐藏状态中。对文本编码完成后,即可进行实体识别。该模型把实体识别看作是一个序列标注任务,使用编码层的输出生成实体标签序列。最后,在实体识别的基础上,模型将实体进行两两配对,输出最终的关系抽取结果。为了提高关系抽取的准确度,该模型引入了依存语法信息,并使用一个双向的树神经网络(Bi-Tree LSTM)编码两个实体间的最短依存路径。从严格意义上讲,这并不是一个联合抽取模型,两个子任务依然是分开决策的,只是通过共享底层编码信息来捕捉任务间的关联。但是该模型最早把深度学习应用于联合抽取,为之后的联合建模等工作奠定基础。基于该模型这种架构的工作还有许多,特点是共享参数,但是两个子任务分开决策,如:Li等[10]、Katiyar等[11]、Giannis等[12]。
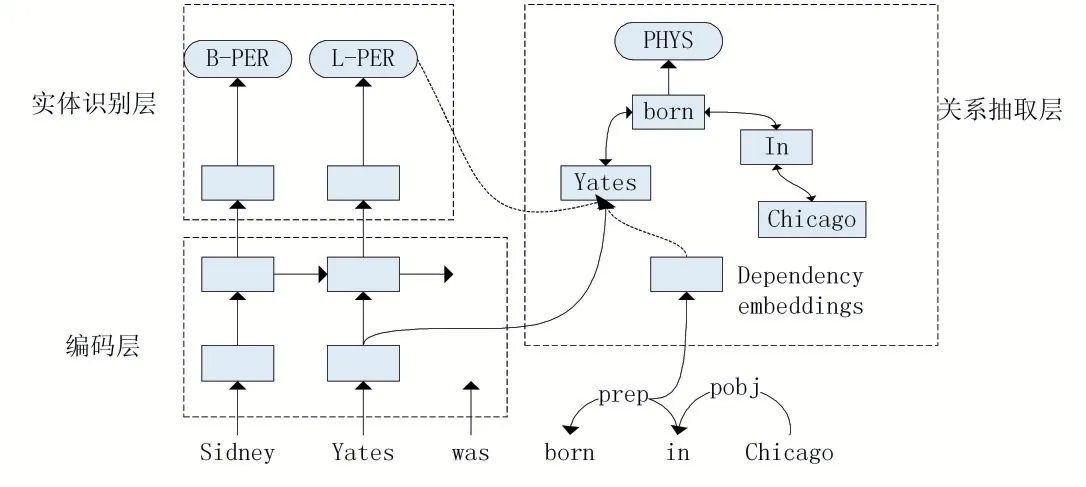
图1 联合训练模型图
1.2 联合建模
Zheng等[5]直接对三元组建模,提出了NovelTag⁃ging方法,这是第一个真正意义上的联合建模(抽取)工作。Zheng等把实体和关系的联合抽取转换为序列标注问题,通过一套精心设计的标签体系,同时表达实体信息和语义关系,其模型如图2所示。模型架构和普通的序列标注模型基本一致,主要分为:编码层、解码层。编码层是一个Bi-LSTM,解码层是一个LSTM,输出的是一个实体关系标签序列。关系标签可以分为三部分:实体边界、语义关系、主体客体(实体一或实体二),非关系标签“O”表示不存在语义关系。该模型输出的不是完整的关系三元组,最终还需要将同一个关系对应的实体一和实体二组合起来才完整。但是这一过程却存在一个问题,如果文本中同一个关系出现两次,此时无法对关系标签进行准确配对。虽然作者提出一个就近原则,但这无疑是不准确的。另外,该模型对每个词只打一个标签,而现实情况是实体可能会参与多种关系。NovelTagging是第一个联合建模工作,但是存在关系标签配对、实体无法参与多关系的问题。
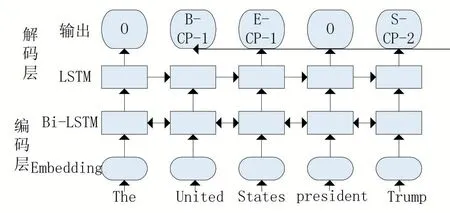
图2 NovelTagging模型图
通常实体可能会参与多种关系,即存在三元组重叠现象,如:A、B、C三个实体,可能AB、AC都存在某种语义关系。Zheng的标注模式无法处理三元组重叠,因此Zeng等[9]于2018年提出拷贝生成模型。Zeng等将三元组抽取任务规约为序列生成问题,即输入一段文本,然后输出完整的关系三元组序列。模型架构和一般的序列框架类似,主要由编码器和解码器组成。编码器使用的是Bi-LSTM,每个时刻的输出代表每个词的隐藏状态。解码器使用的是一个单向的LSTM,每个时刻的输出代表关系三元组的一个部分(关系或实体)。这个生成过程和普通的生成过程有些不同,三元组中的关系采用生成的方式,而两个实体则采用拷贝的方式(实体必定存在于原文本中)。模型的解码过程以三为周期循环执行,先解码生成关系,然后根据关系分别拷贝实体一、实体二,直到生成表示结束的关系三元组<NA,NA,NA>。Zeng的模型基本解决了标注模式所存在的不足,应该算是比较完整的联合抽取工作,但是却存在一个明显缺陷,不能识别实体的边界。在这个工作中,实体是用单个词表示的,由多个词组成的实体取最后一个词。
随后又有不少工作针对拷贝生成模型进行改进,Takanobu等[13]于2019年提出了一个基于强化学习的层级网络模型(Hierarchical Framework with Reinforce⁃ment Learning,HRL)。HRL模型分为上下两层,上层为关系识别层,下层为实体标注层。对于关系识别,Takanobu提出了一个关系指示器概念(Relation Indica⁃tor),即文本中某个可指示语义关系的位置,关系指示器可能是词或者标点符号等,与关系触发词有所不同。但是,关系数据集不存在这样的标注,而如果采用人工标注,费时费力。因此,作者采用了强化学习的方式。在关系识别过程中,代理(Agent)根据历史状态信息判断每个位置是否产生关系,动作空间为{NR}∪R,NR表示没有关系,R表示关系类型集合,如果存在某种关系则带着当前状态转到实体识别层。实体识别层也是采用强化学习的方式,动作空间为({S,T,O}×{B,I})∪{N},S、T分别表示参与关系的主体、客体,O表示普通实体(没有参与当前关系),B、I表示实体边界,N表示普通词。当实体识别完毕后,下层会把状态传回上层,继续进行关系识别。这个工作较好地解决了实体边界问题,但是强化学习并不稳定,实验结果难以重现。
2 数据集
关系抽取的数据集根据标注方式,可分为两类。一类是Miwa等[6]使用的人工标注的数据集,如:ACE(Automatic Content Extraction)[14]数据集。另一类则是Zheng等[8]使用的远监督[15]产生的数据集,如:纽约时代(New York Times,NYT)数据集。
关系抽取任务最初是由美国国防高级研究计划委员会(Defense Advanced Research Projects Agency,DAR⁃PA)资助的MUC(Message Understanding Conference)[16]会议于1988年首次正式提出的,其发展最初由MUC[16]评测会议所推动,后来NIST举办的ACE替代了该会议。ACE会议每年都会发布与信息抽取相关的任务,主要包括命名实体识别、关系抽取等。ACE数据集便来源于此,该数据集是由人手工标注的,其中包含了会议定义的3大类和6子类实体关系。
NYT数据集是通过远程标注产生的。该数据集使用1987-2007年纽约时代新闻文章作为语料,并从中采样出118万个句子作为样例进行标注。目前该数据集有两个版本,一个是由Riedel等[17]发布,包含了29种有效关系以及74345个句子,而另一个相对较小的NYT11则由Ren等[18]发布,包含了24种有效关系。远监督产生的数据集包含大量噪声,但是在实验过程中,多数工作把该数据集直接作为有监督标注数据,不考虑噪声影响,而目前也有些工作在研究如何对数据集进行去噪或者容噪处理。Zeng等[9]还在实验中使用了网络自然文本生成(Web Natural Language Generation,WebNLG)数据集[19],这个数据集是用来测试模型的生成能力的,在关系抽取中的任务中并不常用。
3 结语
实体和关系的联合抽取是近年来一个热门研究问题,自Miwa等[6]首次将神经网络引入联合抽取后,该任务在后续几年里有了较大提高,但是目前这块的研究依然存在一些问题。一个是联合建模(或者联合解码),一些工作虽然自称为”联合建模“,其实不然,两个子任务是分开决策的,无法避免错误传播问题,Zheng等[8]是较早采用联合建模的工作,随后的一些工作在联合建模方面仍存在争议。另一个问题是数据问题,深度学习,特别是有监督学习,依赖于大量且高质量的标注数据,但是目前并没有这样一个大型数据集。而且,Zeng等[9]研究提出的三元组重叠问题,在传统的关系数据集(ACE)中出现较少,因而只能采用远监督标注的数据集(利用知识库可以对句子进行更全面的标注),但该数据集噪声较大。
因此,未来的工作一方面应该是继续探索联合建模的方式以及优化模型结构,联合决策应该是未来工作的重点。另一方面则是对远监督关系数据集的去噪研究,毕竟远监督能利用已有的知识库进行大规模标注,虽然该数据可能会包含大量噪声数据,但是如果能将噪声程度控制在较低水平,再依靠深度学习的容噪能力,联合抽取工作将迎来进一步的发展。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
计算机应用与软件(2022年5期)2022-07-07
中国典型病例大全(2022年7期)2022-04-22
煤气与热力(2022年2期)2022-03-09
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年4期)2021-11-24
计算机应用与软件(2021年4期)2021-04-15
河北科技大学学报(2020年4期)2020-09-10
软件(2017年6期)2017-09-23
