
卷积神经网络的参数优化和函数选择
2020-03-31 02:57:58展华伟
太原师范学院学报(自然科学版) 2020年1期
展华伟,唐 艳,付 婧
(西华师范大学 计算机学院 , 四川 南充 637002)
0 引言
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks简称CNN)[1].经过十多年的发展,从早期的LeNet-5[2]到最新的ResNet[3],卷积神经网络已成为各大学科领域研究的热点,在语音识别[4]、人脸识别[5]、目标检测[6]、自然语言处理[7]等领域均有所突破.
卷积神经网络作为一种高效率的识别方法,可以很方便地进行各种类型的特征提取.但是在处理具体任务或具体项目时,需要根据不同的需求来进行参数调整和优化,这种人为操作不仅费时费力而且很难达到训练的最优效果,许少华等[8]研究了样本先验知识对神经网络的性能影响,何莉[9]等提出了一种基于人群搜索算法的方法,来调整神经网络中的权重及阈值等系数,赵宏等[10]对神经网络中的代价函数与激活函数做了详细的研究,并找到了最优的组合方式.本文将在此基础上,广度探索分析了更多的参数(尤其是优化器),并在准确率更高和速度更快之间,找到了一种广泛的结合方式,使之能够达到效率最佳的平衡点,从而提升神经网络模型的训练性能.
1 卷积神经网络原理
卷积神经网络是一种深度前溃神经网络,通过特征提取层的不断叠加从而得到其基本特征.主要由输入层、隐层、全连接层和输出层组成,而隐层是由卷积层和下采样层交替连接的[2].
1.1 卷积层
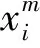
其中的f是一个非线性函数,通常取sigmoid,tanh和ReLU函数.卷积层就是为了提取图像的特征,而不断地进行卷积操作,但由于提取到的特征维度较高很容易过拟合,所有通常在卷积层后面都会接一个池化层来对图像进行降维.
1.2 池化层
引入池化层的唯一目的就是减少图像的大小,是为了提取特征在不同位置和规模上的变化,同时聚合不同特征映射的响应.常用的池化方法有最大池化(max- poopling)、均值池化(average pooling).均值池化是通过均值化局部领域中的像素值,来综合考虑周围像素的特征.而最大池化则是用来提取相邻像素间最重要的特征信息,避免学习到一些无用的特征.
1.3 全连接层
在经过多次卷积-池化操作后,已经提取到了我们所需要的特征图,接下来就要应用全连接层来生成一个等同于需求数目的输出.在全连接层中的每个神经元的激励函数通常采用ReLU函数[11].
2 相关参数与函数
2.1 初始化参数
在CNN中需要初始化的参数主要是权值和偏置值,传统的初始化方法是从某个分布中随机的进行初始化,更简单的是直接初始化为0或1,但这种方法效果很一般.如何定义这些参数将会直接影响到整个模型的收敛速度以及最终的分类效果.
2.2 激活函数与损失函数
非线性激活函数的引入主要是为了增强网络的表达能力,使深层神经网络更加有意义.
目前比较热门的激活函数主要是:Sigmoid,tanh,ReLu,Leaky ReLu,Maxout等.神经网络的求解主要围绕着代价函数的优化进行,经验风险函数也称为损失函数,用来度量输出值与真实值之间的拟合程度,结构风险函数则用来度量模型的复杂程度.
2.3 优化算法
当神经网络训练一轮之后,就需要对其进行调整优化,也就是目标函数的最优化.传统的优化算法是随机梯度下降法以及衍生出的NAG[12]等,除此之外还有Momentum,Adagrad,Adadelta,Rmsprop,Adam等适合不同需求的优化算法.其中Adam算法可以看作是修正后的Momentum算法[13].
2.4 学习率
学习率为每一次梯度下降的步长,通常设置为0.1.当学习率较大时,模型的前期收敛速度加快,但始终达不到最优点;当学习率较小时,收敛的速度变得极慢.所以最优的方法是在前期设置较大学习率,使得梯度快速下降,然后将学习率减小,使得模型逐渐达到最优点,但同时也要防止出现过拟合问题,可以使用dropout或者正则化来解决.
3 建立模型及实验结果
3.1 模型构建
本次实验是利用Google平台TensorFlow框架构建的卷积神经网络,拥有2个卷积-池化层、2个全连接层,32个5*5的卷积核,其中使用到的相关超参数和函数如表1所示.实验中使用MNIST数据集作为实验的训练和测试数据集.MNIST数据集是一个计算机视觉数据集,包含70 000张手写数字的灰度图片,其中每张图片包含28×28个像素点,部分数据可视化后如图1所示.
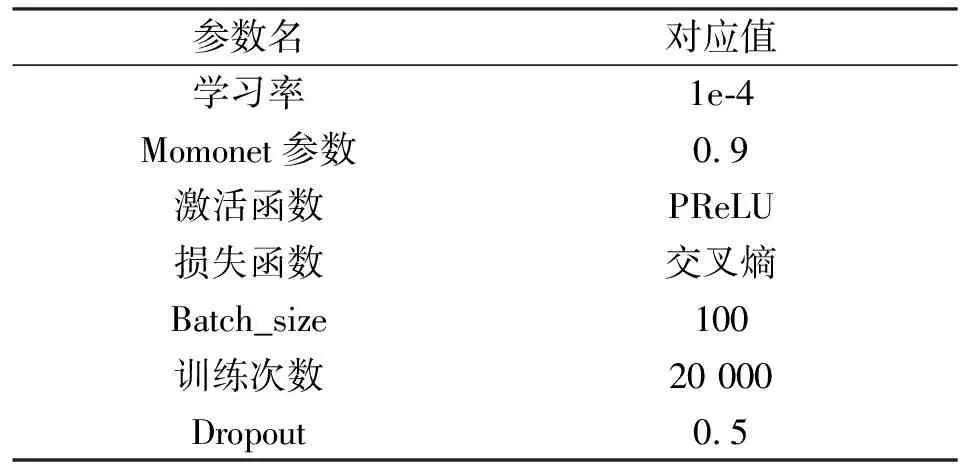
表1 超参数和函数

图1 MNIST数据集
另一方面,目前可用的优化器有多种,如何进行组合来适应该模型就成为了关键所在.如果输入的数据很稀少,那么可以使用自适应学习率方法中的一种来获得最佳结果.RMSprop作为Adagrad的延伸,引入了衰减系数,解决了学习速率急剧下降的问题.Adam是带有动量系数的RMSProp,在经过偏置矫正后,每一次迭代学习率都有个确定范围,使得参数比较平稳.
3.2 实验结果
表2为各优化器在不同迭代次数下的实验结果.本实验探索了在确定了超参数和函数的情况下,不同优化器对模型的性能影响.通过对比发现,Adam和RMSProp这两种优化器的最终准确率相近,并优于其他优化器,其中,Adam在迭代500次时准确率就已经稍高于RMSProp,说明该优化器收敛速度更快、效率更高.
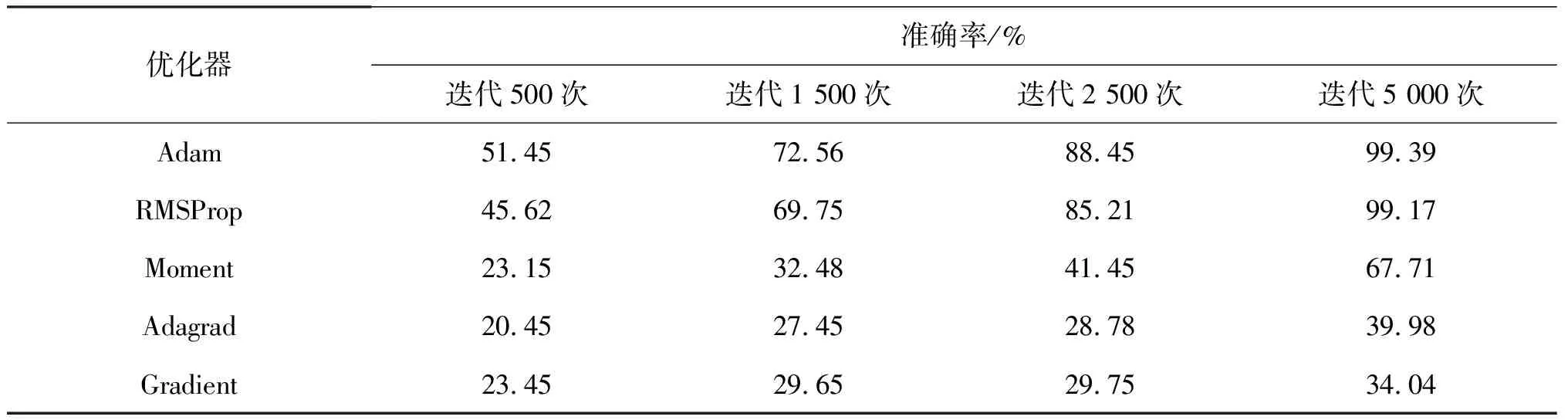
表2 不同优化器性能对比
4 结论
本文对卷积神经网络中的参数设置和函数选择等方面进行了探索及实验,揭示了这些参数在模型训练过程中的影响.实验结果表明,通过预先设定好相关超参数,并且在与RMSProp或者Adam搭配时,能够更快地达到收敛时的准确率,从而提高卷积神经网络的训练效率.
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科技创新与应用(2021年23期)2021-08-30 11:46:16
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
雷达科学与技术(2018年3期)2018-07-18 00:59:32
