
一种改进的高维度离群点检测方法*
2020-03-26 08:25吴远超
通信技术 2020年2期
吴远超,范 磊
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
离群点检测是数据挖掘的重要一部分,是指从大量事物中发现少量与多数事物具有明显区别的异常个体的过程[1]。离群点理论应用广泛,如信用卡欺诈检测、入侵检测、故障检测、灾害预测、公共卫生中的异常疾病的爆发、恐怖活动防范以及气象预报等。
在高维度场景下,传统的离群点检测算法效果大多不甚理想。这是因为普通的离群点检测方法大多是基于数据之间的相似度和距离来挖掘离群点。而在高维空间数据变得稀疏,数据点之间的距离及密度不再具有直观的意义,因此常规算法对高维离群点的检测不再有效或效率较低[2]。
Pang等[3]提出了适合于高维空间的CINFO方法,通过将子空间搜索和离群点评分方法关联起来,提高了检测精度。本文对该方法进行改进,引入扩展的孤立森林算法(Extended Isolation Forest,EIF)[4],提出了EIF-CINFO方法,在保持原有检测精度的情况下,提高了效率。
1 相关算法研究
高维数据常包含大量不相关的特征,这些噪声特征可以将离群点伪装成正常对象。因此,对高维数据而言,发现有意义的离群点变得十分复杂和不明显。目前,已有一些针对特定场景下的离群点检测方法,但在效率和精度上仍需改进。
1.1 经典高维度离群点检测算法的不足
在现有的高维度离群点检测算法中,基于子空间/特征选择的方法[5-7]是主要的解决办法。他们寻找相关的特征子集,在相关的特征子集上应用离群点检测方法,以缓解由不相关的特征造成的负面影响。然而,这些方法往往将子空间搜索和后续的离群点评分方法分离开来,因此会保留与得分无关的特征,降低了检测性能。
1.2 CINFO方法中的孤立森林算法及其不足
CINFO方法针对经典高维度离群点检测算法的不足,通过将离群点评分和子空间搜索关联起来相互优化,提高了检测效果。孤立森林(iForest)[8]是CINFO中的离群点评分算法,主要思想是对一个数据集构成的属性空间,随机选定一个特征进行空间分割得到两个子空间。之后继续在剩下的特征里随机选定一个特征,对每个子空间切分,直至每个子空间只包含一种数据点或者树的深度达到设定的最大值。
具体过程如下:对于大小为n、维度为m的数据集D,先通过随机抽样获得一个数据子集Di={d1,d2,…,ds};之后随机选择一个特征A,在其最小值和最大值的范围内随机获得一个切割值pa;根据pa对Di中的每个数据实例dj,按照其特征A的值di(A)进行划分,将Di中dj(A)<pa的部分归到结点的左边,其余部分归到节点的右边,从而得到两个子树的数据集。按此方式分别在左右两边的数据集上重复构造左右子树,直到达到终止条件。终止条件如下:(1)训练数据中只包含一个样本或只包含相同的样本;(2)树的高度达到限定高度。最后重复上述过程,构造出t棵iTree得到iForest。
因为离群点一般距离正常点较远,所以能被更好地区分开。在树上的体现是离群点距离iTree的根结点较近,因此可以通过统计不同iTree下数据点d的平均路径长度计算数据点的离群值。
iForest的缺点是不适用于特别高维的数据。由于每次切割数据空间都只使用了一个维度,建完树后仍然有大量的维度信息没有被利用,导致在高维空间下算法可靠性不高。另外,高维空间还可能存在大量噪音维度或不相关维度,影响分割的效果。本文针对iForest对CINFO方法进行了改进。
2 EIF-CINFO方案设计
在CINFO中,iForest只考虑了部分维度信息,因此对后续降维影响较大。而EIF-CINFO中的EIF采用随机超平面的隔离机制,考虑了所有特征,有利于后续的特征降维。
EIF-CINFO方案过程如下:对原始数据集进行离群点打分,之后设定一个阈值得到初步的离群点集合,再通过lasso回归函数,剔除与离群点集合无关的特征;将得到剔除无关特征后的数据集再进行离群点打分;一直重复上述步骤,直到lasso回归的损失函数不再减小。具体流程如图1所示。

图1 方案流程
2.1 离群点打分
孤立森林不能很好地适应高维度数据场景,会导致后续lasso回归特征降维速度缓慢。为此,通过引入EIF来改正这一缺点。
孤立森林通过创建与某一轴平行的超平面来切割数据属性空间。在高维度空间下,iForest切割数据空间使用的维度远小于总属性维度,因此有很多维度信息并没有被使用上。EIF通过允许在数据空间中随机产生一个超平面,在切割平面的过程中兼顾到了所有维度信息。
EIF创建用来分割的超平面的方式由式(1)确定:

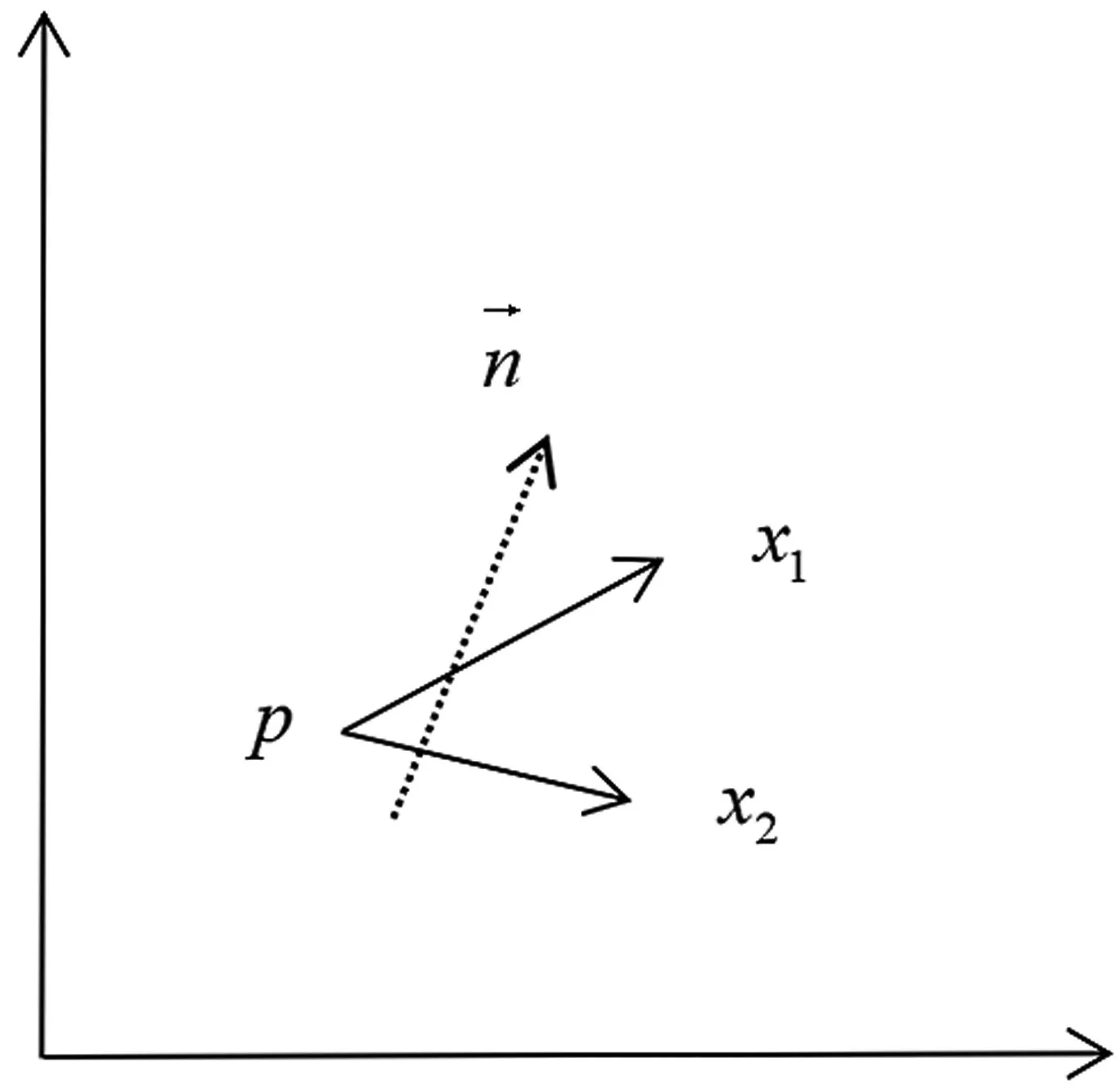
图2 EIF单次分割
EIF的一个切割超平面在二叉树上表现为一个节点建立左右子树的功能。如果满足上述不等式,则点x被传递到树的左分支;否则,它将被传至右分支。如图2所示,分割中的x1被分到了左分支,x2被分到了右分支。
图3是iForest中的一棵树和EIF中一棵树分割数据空间的对比图[4]。
从图3可以明显看出,iForest中隔离超平面平行于坐标轴,EIF中隔离超平面的方向是随机的。

图3 iForest和EIF中的一棵树分割数据空间对比
2.2 设定阈值获得离群点候选集
得到离群点评分后,设定阈值。超过阈值,则暂时认定为离群点;反之,则暂时认为是正常点。利用Cantelli不等式[9]设定的阈值,可以将误报率控制在一定范围内,具体如下。
给出异常值向量y∈RN,y中大的数表示较高的离群度,μ和δ2是y的期望值和方差。那么,离群候选集R定义如下:

假设y具有期望值μ和方差δ2。令yi∈Y,离群阈值函数η(yi,a)=yi-μ-aδ,然后这个阈值设定导致的误报率上限便为
证明过程如下:

式(3)为Cantelli不等式,因为大的值表示离群值,这个不等式意味着当将阈值定义为μ+aδ时,即令α=aδ,则yi大于等于μ+aδ的概率小于等于,那么可能错误地将正常对象识别为离群值的概率最大为
Cantelli不等式是单边的切比雪夫不等式。与切比雪夫不等式类似,它不对特定概率分布进行假设,适用于具有统计平均值和方差的概率分布。
2.3 剔除无关特征
在得到初步离群点集合后,将初步离群点作为被预测变量,数据集中的特征作为预测变量,进行lasso回归,以剔除与初步离群点集合无关的特征。R是离群阈值阶段新创建的只包含初步离群点的数据集,L为被初步识别为离群点的数量,然后进行如下的稀疏回归学习:
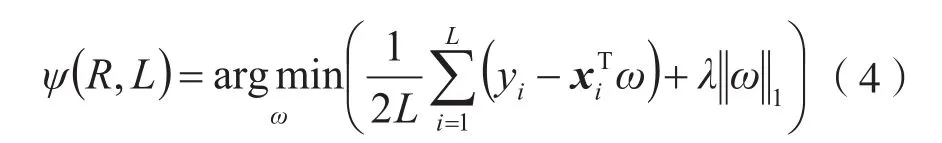
其中ω是系数矢量,λ是正则化参数。式(4)获得最小二乘模型的收缩解,得到与离群点集合R不相关的特征。然后,将之前数据集中的这些无关特征剔除,获得新的数据集S:
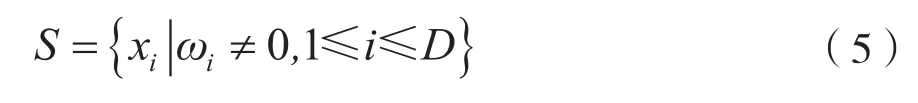
2.4 算法描述
输入:X为数据集,a为离群值阈值参数
输出:M为对象异常值得分排序
y0←Φ(X)得到初始离群集合
mse0=1,t=0初始损失函数为1,t为迭代系数
repeat
t←t+1
Rt←η(yt-1,a)用阈值函数得到离群点候选集
ωt,mset←ψ(Rt,λt)进行一次 lasso 降维
St←{x·i|ωit≠0,1≤i≤D|}剔除相关系数为0的特征,得到新集合
yt←φ(St)得到新的离群点打分
until mset>mset-1直到损失函数不再下降
M←SortXw.r.t score对得分进行排序
return M
3 实验及结果分析
3.1 实验数据集及评价标准
本节通过实验对CINFO和EIF-CINFO的有效性和性能进行对比分析。实验分为两部分,第一部分使用加州大学欧文分校机器学习数据库中的Isolet和APS数据集,用于测试算法效果。第二部分为某公司实际采集的手机设备特征数据(Device),检测算法在该数据集下的实际效果。
Isolet数据集为隔离字母语音识别,150名受试者两次说出字母表中每个字母的名字,特征表里包含光谱系数、轮廓特征、声呐特征、前音特征和后音特征等,数据集数据量为730个,特征维度为617。APS数据集为Scania卡车APS(空气压力系统)故障数据集。数据集的正类由APS系统特定组件的组件故障组成,负类由与APS无关的部件故障组成,由专家选择组成。其中数据量为3 000个,特征维度为170。
在用Isolet和APS数据集进行测试后,用实际的手机设备特征信息数据集进行实验,该数据集有两类数据:描述设备固有属性的静态数据,如内存大小;随着时间变化的动态数据,如地理位置信息。该数据集中将模拟器标记为异常用户,数据集数据量为3 200个,特征维度为245。

表1 数据集详细情况
为了评估算法的性能,实验以ROC曲线和曲线下面积AUC为效果评价指标,AUC范围为[0,1],它的值越接近1说明算法检测效果越好[10]。
3.2 实验设置与结果
本节对两种算法进行精度和效率测试。考虑到EIF-CINFO主要是基于CINFO的改进,在保持其检测效果的同时,提高检测效率。论文中指出,CINFO在他的竞争者算法里有更好的表现,因此本实验考虑只将CINFO和EIF-CINFO进行实验对比分析。
实验环境:CPU为2.40 GHz,内存为8 GB;软件环境:操作系统为Microsoft Windows 10,实验程序用Matlab编写,开发环境为Matlab2017a。
算法参数设置:在所有的实验中,a设定为1.732(即误报率上界为25%);iForest和EIF的参数设定为iTree的数量T=50,子样本数量ψ=256。
在相同的环境下,实现了CINFO和EIF-CINFO。
图4和图5分别给出了两种算法在不同数据集上的ROC和AUC的表现。

图4 CINFO在3个数据集下的ROC曲线

图5 EIF-CINFO在3个数据集下的ROC曲线
表2为两种方法在不同数据集上的AUC值。
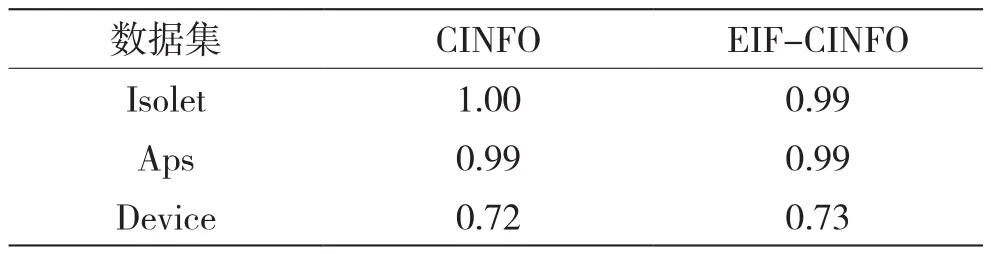
表2 两种方法的AUC值
表3给出了算法运行时间和效率的提升效果。

表3 算法运行时间
从实验可以看出,在准确性方面,两个算法差别不大,但在效率方面,EIF-CINFO有很大的提升。这是因为CINFO中的孤立森林每棵树只考虑到有限特征,导致在lasso回归中速度较慢。而EIF是基于对每个特征的考虑,因而在lasso回归筛选与离群点无关的特征时速度较快。表4为lasso降维时间的对比,可以看出EIF-CINFO中的lasso降维的时间要比CINFO的快很多,证明了之前的观点。因为EIF的随机超平面的隔离机制考虑了所有特征,用EIF得到的预备离群点能够更快地把与离群点无关的特征筛选出来。
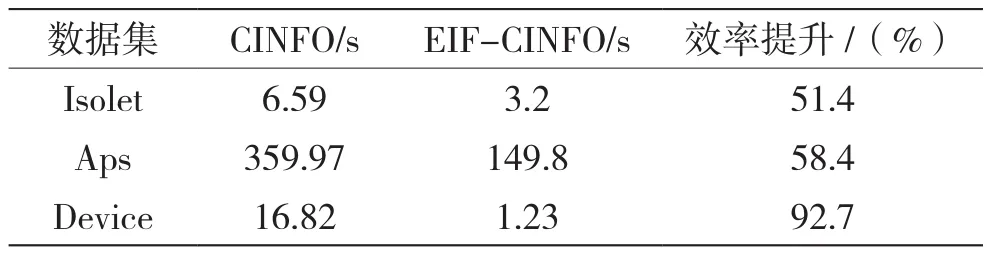
表4 平均每次lasso降维时间
4 结 语
高维度离群点检测是数据挖掘中的一个重要研究领域。本文对CINFO方法进行改进,用实际数据和公司生产数据的实验,证明了EIF-CINFO具有在高维度空间下良好识别离群点的能力,并且在计算时间上有较大改进,同时具有较高的执行效率。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
计算机应用与软件(2022年4期)2022-06-24
计算机应用与软件(2022年2期)2022-02-19
建材发展导向(2021年19期)2021-12-06
中北大学学报(自然科学版)(2021年5期)2021-11-15
临床骨科杂志(2020年1期)2020-12-12
小型微型计算机系统(2018年8期)2018-09-07
环球市场信息导报(2017年36期)2017-12-24
阅读(中年级)(2016年4期)2016-11-19
探测与控制学报(2015年4期)2015-12-15
