
机器学习系统毒化攻击综述*
2020-03-22 03:12张义莲朱旻捷
通信技术 2020年3期
张义莲,颜 晟,朱旻捷,陈 艳
(1.国网上海嘉定供电公司,上海 201800;2.国网上海市电力公司,上海 200122)
0 引言
机器学习因为具有能够从大数据中习得数据的特定模式的强大能力和解决传统编程难以解决的任务的巨大潜力,吸引了全球研究者的关注和研究。如今,机器学习在诸如模式识别、自动驾驶、机器辅助决策等方面取得了广泛且成功的应用。
机器学习已经被应用于诸多安全关键性领域,如垃圾邮件过滤[1-2]、恶意软件检测[3-5]、蠕虫病毒检测[6]、网络协议认证[7]等。自机器学习系统被越来越多地部署在安全关键性领域以来,越来越多的人开始关注机器学习系统的脆弱性和鲁棒性。除安全专家以外,也有怀有各种目的的恶意攻击者。更令人感到危险的是,机器学习系统总是认为它是从一个具有自然或者纯净分布的可信源处取得的数据,使得机器学习系统更容易遭受基于数据驱动的攻击。在这些攻击方式中,数据毒化攻击成为一种新兴的且强有力的攻击威胁。针对机器学习系统的攻击方式,它可以分为原因性的攻击和探索性的攻击两种[8]。原因性攻击旨在操纵训练数据,而探索性攻击则直接攻击模型本身。数据毒化攻击属于原因性攻击,通过将精心构造的毒化样本注入数据集中来实现攻击者的目的。这种攻击在实际操作中很容易实现,原因是大多数情况下攻击者虽然无法修改已经被模型采样利用的数据,但可以向数据集中注入自行构造的新数据。文献[9]中,Suciu 从特征、算法、实例和能力4 个维度对攻击者知识进行建模。本文采用与大多数研究相同的分类方式,即将攻击者知识简单划分为受限知识[7,10-11]和完整知识[7-8,11-15]。拥有完整知识的攻击者了解受害模型的特征集F、数据集D和使用的算法。这往往表明了最坏的情况。在受限知识的情况下,攻击者仅仅知道部分的特征集和数据集,甚至完全不知道模型采用的特征集和数据集,仅仅知道模型使用的算法。这种情况下攻击者往往会使用一个替代数据集来实施攻击。
本文对现存的数据毒化攻击方式进行调研,并根据它们的攻击模型进行分类。数据毒化攻击的相关研究正变得越来越热门,然而相关的论文却略显混乱。相关文章中很多着眼于特定的模型、特定的学习条件或者攻击者特定的目的与攻击能力,亟待被分类总结。第1 节首先介绍针对线性分类器的毒化攻击。该攻击方式采用迭代式次梯度上升算法构造毒化样本。第2 节介绍针对线性回归的毒化攻击。该攻击方式与针对线性分类器的攻击方式十分相似,在线性分类器攻击算法的基础上进行了少许修改,以适应回归学习的条件。第3 节和第4 节分别阐述针对SVM 和贝叶斯分类器的毒化攻击。关于深度神经网络,在第5 节主要介绍了生成梯度算法和纯净标签攻击算法两种十分典型且有效的攻击方式。
1 针对线性分类器的毒化攻击
在线性分类器中,模型通过最小化损失函数学得一个仿射函数f(x)=ωTx+b作为决策边界。该损失函数在由f(x)和y计算得到的二次损失与正则项Ω(ω)之间做出权衡:

此处λ为正则参数,组成数据集D。引入Ω(ω)的目的是通过在参数ω和b上施加限制来防止过拟合。机器学习中存在3 种常用的正则项。LASSO 正则项使用l1正则,即Ω(ω)=||ω||1,能够在参数中引入稀疏性,从而带来了良好的最优化解特点。吉洪诺夫正则使用了l2正则项,即。弹性网络是LASSO 正则项和吉洪诺夫正则项的线性组合:

文献[16]中,作者假设攻击者目标是使得目标分类器的分类错误达到尽可能最大,可被归类为无目标攻击。这种攻击方式尝试最大程度地降低系统的性能。攻击策略可被表达为:

在计算梯度的过程中,即计算W关于xc的偏导数时,文献[17]计算得到:

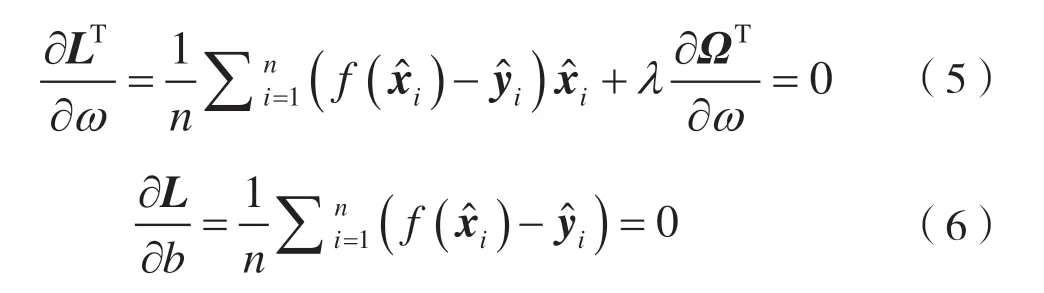
在LASSO 或者弹性网络中,Ω是凸函数但不可微的情况下,可以简单将偏导数替换为sub(ω)。KKT 条件使计算变得简便,因为在最优化过程中可以简单得到,绕过了由sub(ω)造成的多种梯度上升方向的问题。
因为KKT条件在最优化过程中总是满足,式(5)和式(6)关于xc的偏导数应当恒等于0。将的计算结果重写为矩阵形式:

代码中,文献[17]提出在每一步迭代过程中仅优化一个毒化点xc,并在每一步的开始更新分类器参数ω和b。这一更新步骤可以显著提升攻击点的攻击效果,因为xc的每一次修改都是基于刚刚学习到的参数。此处使用了一个投影运算ΠB,将结果投影到一个可行域B。这一运算通常会施加一个框式约束如B=[0,1]r,以求得梯度上升方向d,然后算法执行一个线搜索得到梯度上升步长η。当目标损失函数W在两次相邻迭代间不产生大的变化后,算法达到收敛,并输出要求的毒化数据集。

图1 对线性分类器的毒化攻击算法
2 针对线性回归的毒化攻击
回归学习已经被应用于诸多领域,如价格预测分析、销售影响因素分析、地震预测、健康数据分析等,但对线性回归的毒化攻击研究很少。Jagielski 等研究者改进肖等人提出的基于梯度的优化算法应用于回归学习[18]。
线性分类器和先行回顾的主要区别在于响应变量y是连续变量而不是离散标签。因此,Jagielski等研究者提出同时优化x和它相应的y。文献[18]将xc替换为相应的zc=(xc,yc),由此式(7)变为:

其中θ=(ω,b),。将式(5)和式(6)变为下列矩阵形式:

这里与文献[17]使用训练集的方式不同,文献[18]采用未受污染的数据集来评估误差,最终得到需要的梯度。这里算法使用提到的线搜索来构造毒化数据。
3 针对支持向量机的毒化攻击
文献[12]中,Biggio 等研究者基于支持向量机(Support Vector Machine,SVM)学习问题的最优解特性,提出了针对SVM 的毒化攻击。如同文献[13]中的增量学习策略证明的,最优解依赖于二次规划问题的参数和数据点的几何分布。这使得毒化攻击的实现具有了可行性,即攻击者可以向训练集中注入精心构造的数据点来最大化分类误差。
攻击者的目的是通过注入构造数据点(xc,yc)来最大化分类误差,可以数学表达为通过在Dtr∪(xc,yc)上训练SVM 模型达到最大化验证集上的hinge 损失函数:

为优化式(10),需要L关于xc的梯度。攻击者通常会计算,此处u是所求的表征最优化方向的梯度值,t是前进步长。式(11)明确写出了间隔条件gk与xc有关的项:
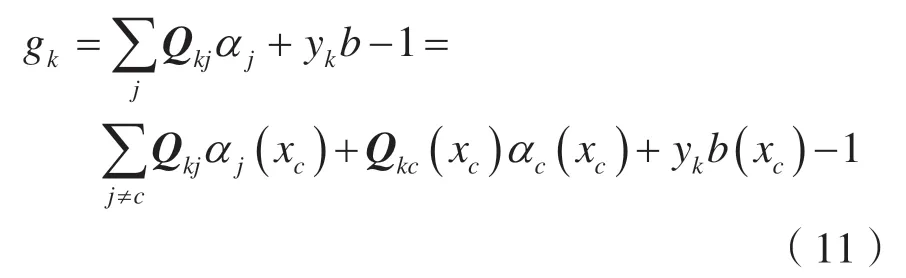
计算gk关于u的偏导数:

Q下标表明Q相应的向量或子矩阵,Qks指Q的子矩阵中与第k个验证集数据点和S中的间隔支持向量的积有关的部分。
通过使用文献[13]的隔离更新技术,Biggio 等人发现KKT 条件在训练过程中保持恒定,即对于训练集中的第i个数据,存在:

通过对式(13)和式(14)中的xc求微分,可以得到S中的间隔支持向量。文献[12]使用Sherman-Morrison-Woodbury 定理[14]将其重写为:


针对SVM的毒化攻击算法的伪代码如图2所示[12]。
为计算方便简单,将随机选取的数据点的标签进行反转来构初始毒化点。算法将t固定为一个小常数。验证集的错误的梯度计算依赖于假设:集合S和R在更新过程中保持不变。在每步迭代过程中,SVM 最优解采用递进方式[13]进行重计算,使得攻击效果更强。
4 针对贝叶斯分类器的毒化攻击
Nelson 等人在文献[19]中证明了可以通过操纵小部分的训练集来反转基于贝叶斯分类器的垃圾邮件过滤器,提出了两种基于“污染假设”的攻击方式,即攻击者能够通过注入恶意数据来操控训练集。Nelson 等人提出了使得垃圾邮件过滤器瘫痪的“字典式攻击”与阻碍正常邮件接收的“集中式攻击”。该攻击基于一个免费开源且常用的垃圾邮件过滤器SpamBayes。
SpamBayes 在对邮件进行评分前会先将邮件的头和正文部分进行分词。该操作基于一个假设:一封邮件中词条的出现与否会独立影响该邮件的垃圾邮件评分。对于每一个词条ω,其评分由式(18)计算得到:

式(18)中,NH、NS、NH(ω) 和NS(ω) 分 别 代表了垃圾邮件、有用邮件、包含词条ω的垃圾邮件和包含词条ω的有用邮件的数量。
Robinson 对PS(ω)和x的凸组合分别进行平滑,平滑以N(ω)(带有词条的训练邮件)和s(预先选择)为权重进行:

SpamBayes 使用来自词条集δ(E)的最重要的一些词条的垃圾邮件评分计算信息评分I(E)。I(E)由E中评分在[0.4,0.6]区间外且离0.5 最远的前150个词条组成。

SpamBayes 使用了两个可调节的阈值θ0和θ1来预测一封邮件是否属于垃圾邮件。当邮件评分I(E)落入区间[0,θ0]、[θ0,θ1]或[θ1,1]时,SpamBayes 分别将其判为有用邮件、不确定邮件或垃圾邮件。
文献[19]将攻击者的目标概括为选取攻击邮件a以求最大化由分布p得到的下一封合法邮件m预测得到的垃圾邮件评分I(a)(带有恶意邮件a在训练集中计算得到式(22)),攻击者的目的可以表达为:

4.1 字典式攻击
为使过滤器无效,即将大部分的合法邮件判为垃圾邮件或者不确定邮件,字典式攻击的思路十分直接:构造大量包含合法邮件单词的垃圾邮件并将它们发送给过滤器。经过这些恶意数据的学习后,SpamBayes 最终会将这些单词与垃圾邮件联系在一起,导致大部分有用邮件的误判。
如果攻击者没有对合法邮件使用的单词的先验知识,可以简单使用一个包含所有可能出现的单词的英语词典作为替代。如果攻击者拥有合法邮件可能使用的部分单词的先验分布,攻击者可以选取更有可能出现在合法邮件中的单词并构造更简短的恶意邮件,使得攻击更有效率。
4.2 集中式攻击
在集中式攻击条件下,攻击者通常知晓部分甚至全部的特定合法邮件使用的单词。攻击者可以向受害分类器发送包含这些单词的恶意邮件,从而提高相应词条的垃圾邮件评分。SpamBayes 在受污染的毒化训练集上训练后,极有可能将目标邮件判定为垃圾邮件。
5 针对深度神经网络的毒化攻击
尽管有大量的研究集中在针对诸多传统模型的毒化攻击上,而针对深度神经网络(Deep Neural Network,DNN)的毒化攻击研究却很少,即便DNN 已经成为如今最著名也最具潜力的学习模型。正如有限的数篇论文显示的,DNN 对于毒化攻击暴露出明显的脆弱性。Steinhardt 等研究者在文献[20]中发现仅仅3%的训练集的改动会导致11%的测试准确率的下降,即便模型采用了强有力的防御措施。
文献[21]中,Shafahi 等人提出了一种更加贴近现实情况的攻击算法,命名为“纯净标签攻击”。这种攻击算法不需要攻击者对标记函数有任何的控制,通常注入的数据往往由经过认证的权威机构进行标记。该攻击也是目标式的,意味着攻击者的目标是使一个特定的实例在测试阶段被误分类,同时保证系统的性能不会显著下降。Shafahi 等人讨论了两种学习方式——迁移学习[22]和端到端训练条件下该攻击的实现方式。文献[23]中,Yang 等研究者首先对神经网络应用传统的基于梯度的攻击算法,并通过引入称为“生成器”的新网络产生毒化点有效提升了攻击效率。这一方法突破了传统攻击算法的计算开销平静。
5.1 基于梯度的攻击
文献[23]中,Yang 等研究者首先将传统的基于梯度的毒化攻击应用于神经网络。直接梯度攻击算法伪代码如图3 所示。
其中,下标i、p表明是原始和毒化点,上标(p)说明是毒化模型。在xp调节过程的每步迭代中,直接梯度方法调整xp的每个元素以计算,这一项控制了xp每步迭代的更新方向。每步调整的步长固定为α,当相邻两次迭代的损失差异低于一个固定门限Lth时算法收敛。直接梯度方法的计算和时间开销与输入数据的维度和目标模型的复杂度密切相关,因此随着学习模型复杂度和使用的数据集规模逐渐增大,该算法的应用受到了很大限制。

图3 针对深度神经网络的直接梯度毒化攻击算法
受GAN[24]概念的启发,Yang 等人提出训练一个称为“生成器”(G)的新模型,以产生旨在破坏成为“判别器”(D)的原始模型的毒化点xp。文献[23]选取了一个自编码器作为生成器,其中自编码器的更新采用了从判别器中提取的损失函数和梯度的加权函数。判别器在毒化数据集上进行重训练并计算其关于正常数据的损失函数,然后输出加权函数的计算结果返回生成器,以指导训练过程。图4 描绘了生成式梯度方法产生毒化点的过程[23]。
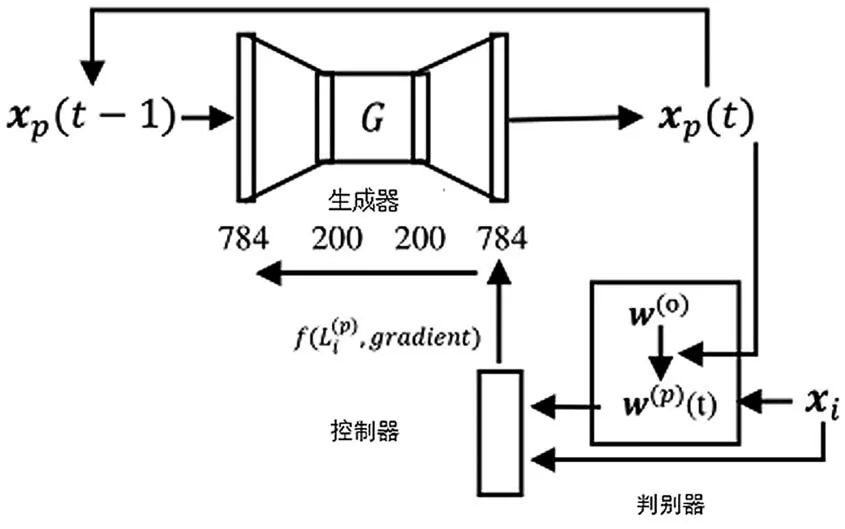
图4 生成式算法结构
生成式方法产生毒化点的算法伪代码如图5 所示。

图5 针对深度神经网络的生成式梯度毒化攻击算法
首先注入初始毒化点xp(0)污染原始模型,然后计算损失函数并计算加权函数。算法使用加权函数更新G,并通过G 将xp(t)更新至xp(t+1)。生成式算法仅仅计算梯度的和,而不是在每一次更新中更新xp的单个元素。因此,它大大减少了计算量和时间开销,使得攻击更灵活也更有效率。
5.2 纯净标签攻击
该攻击方式构造毒化点的过程十分简单。首先,攻击者选择一个被标记为目标类的目标实例,此处实例即数据集中的数据点。其次,为构造相应的毒化点,攻击者需要选择一个基准实例作为基类。基类正是攻击者希望基准实例被DNN 误判为的类。攻击者对基准实例进行了一些难以察觉的改动,以构造毒化实例。在将构造的毒化实例注入训练集后,攻击者使用被污染的数据集重训练模型。当测试阶段模型将目标实例误判为基准类时,认为攻击成功。
文献[21]提出了构造毒化实例的基本思想是构造与基准实例看似相似但实则与目标实例在特征空间发生碰撞的实例。DNN 函数的复杂性和非线性使得这一想法具备实现的可能。定义f(x)表示DNN 从输入x至倒数第二层的函数。t、b和p分别表示目标实例、基准实例和毒化实例。构造p的过程可表达为:
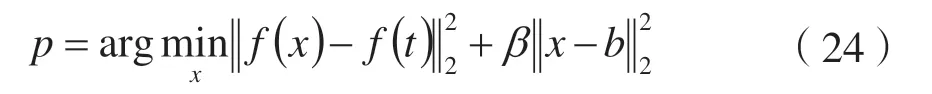
为优化式(24),Shafahi 等研究者使用了一个前向后向分离过程[25]。
纯净标签攻击伪代码如图6 所示。

图6 纯净标签攻击算法
其中,前向步骤是一个在特征空间最小化f(x)和f(t)的梯度上升步骤,后向步骤是一个最小化基准实例与b的Frobenius 距离的临近更新,后向步骤的目的是增大b和p的相似性。
5.2.1 迁移学习
迁移学习是一种广泛使用的学习策略,仅仅重训练网络的softmax 层以适用于特定的任务。在迁移学习中,纯净标签攻击十分有效。甚至仅仅注入一个构造的中毒实例,攻击可以造成目标实例的误判率达到100%[21]。
通过在训练集中注入毒化实例,网络学习到的决策边界会发生旋转,以将中毒实例包含在基准类一侧,将导致目标实例也被包含在基准类一侧,因为中毒实例和目标实例在特征空间发生了碰撞,由此引发了目标实例的误分类。
5.2.2 端到端训练
端到端训练的含义是整个网络在面临学习问题时需要经过重训练。在这一条件下,简单使用与迁移学习相同的攻击方式会完全失败。因为上述的攻击方式利用了特征提取核的一些缺陷,经过重训练过程中毒实例将回到基准类分布,决策边界几乎不发生旋转。为解决这一问题,Shafahi 等人使用了水印技术和多实例毒化的组合。为使得中毒实例和目标实例在特征空间不会发生分离,水印技术可以在中毒实例中引入某些目标实例不可分离的特征,由式(25)所示:

透明度参数γ控制了目标实例和中毒实例的重叠程度。水印技术能够有效提高单个中毒实例的攻击效果,但仅此还不够。为使得攻击更加有效,文献[21]采用了从多个基准实例计算得到的多个中毒实例来毒化训练集。这将有效防止DNN 从目标实例和中毒实例中学习到不同的特征,因为模型必须找到一个能够区分目标实例和每一个中毒实例的公共特征。当仅使用一发毒化时,中毒实例回到了基准类分布,目标实例的判别没有发生变化。但是,使用了多中毒实例攻击后,目标实例被成功导向基准类分布,导致模型成功误判了特定的目标实例。
最终,当网络被重训练后,目标实例被中毒实例导向基准类分布,攻击成功实施。与迁移学习不同,造成误分类的并不是决策边界的旋转,端到端训练的误分类是由于将目标导向了基准类分布,这一过程中模型学习的决策边界几乎是没有发生改变的[21]。
6 结语
目前,毒化攻击已经成为机器学习系统安全日益严重的威胁,越来越多的研究者开始关注针对不同机器学习模型的攻击方法。选取并总结最有影响力且最为典型的攻击算法,将它们根据相应的攻击模型进行分类。选取的这些攻击算法十分有效,某些算法能够躲避现存的检测方法,某些算法如纯净标签攻击甚至能够通过仅注入一个中毒实例达到100%的攻击成功率,希望本文的工作能够使现存的关于机器学习系统毒化攻击的研究成果更加清晰,为相关研究者的研究工作提供启发。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
电子产品世界(2022年4期)2022-04-21
英语文摘(2021年10期)2021-11-22
计算机系统应用(2021年2期)2021-02-23
计算机与网络(2020年4期)2020-04-20
电子技术与软件工程(2019年18期)2019-11-18
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
电子技术与软件工程(2017年14期)2017-09-08
现代计算机(2016年11期)2016-02-28
