
基于图表示学习的会话感知推荐模型
2020-03-21 01:10曾义夫牟其林
计算机研究与发展 2020年3期
曾义夫 牟其林 周 乐 蓝 天 刘 峤
1(电子科技大学信息与软件工程学院 成都 610054) 2(提升政府治理能力大数据应用技术国家工程实验室(中电科大数据研究院有限公司) 贵阳 550022) 3(中电科大数据研究院有限公司 贵阳 550022)(ifz@std.uestc.edu.cn)
基于会话的推荐系统(session-based recom-mender systems, SRS)是推荐系统领域的一个重要研究分支,因其在电子商务中的实用性而受到广泛关注[1].SRS研究的基本问题是如何利用用户会话日志中记录的历史行为(如浏览、购买等点击行为)来预测用户下一次将要点击的物品.因此,SRS问题也被称为点击预测(next-click prediction)问题[2].
与传统推荐系统相比,SRS问题的困难性主要体现在:1)SRS中的用户通常是匿名的,仅通过当前会话很难获得足够的上下文信息对用户兴趣进行建模;2)SRS数据仅包含用户浏览点击行为,不包含用户对物品的主观意见(如评分),因此只能通过该数据对用户兴趣进行间接推测.简言之,SRS需要根据有限的点击行为序列所反映出的用户隐含兴趣,预测用户的真实兴趣并做出针对性推荐[2].
当前性能表现较好的SRS模型多为基于循环神经网络(recurrent neural networks, RNNs)的深度学习模型,其共性在于对用户点击物品(item)采用实值向量进行表达(称为embeddings),并且采用随机值对embeddings向量进行初始化,通过对用户点击序列进行学习,迭代更新得到物品的向量表达[2-5].
本文认为这种基于会话子序列学习得到物品表达,并依据子序列编码进行预测的方式会导致模型的注意力局限于会话中的已点击物品,倾向于推荐与已点击物品类似的物品,难以捕获用户浏览行为中隐含的兴趣变化.例如用户在浏览手机产品时可能注意力会自然地迁移到附件产品如耳机、手机壳,充电宝等,这种情况称为兴趣漂移[6].
为解决该问题,本文提出一种基于协同过滤思想的SRS算法模型,称为基于图表示学习的会话感知模型(graph embedding based session perception, GESP).该模型首先基于训练数据构造一个全局的物品依赖关系图(item dependency graph, IDG),用于描述用户会话中物品的点击先后顺序.然后,利用本文提出的图表示学习算法(graph embedding learning algorithm, GELA)对IDG进行学习,得到推荐系统中所有物品的向量表达.最后,再利用预训练得到的物品表达,采用双向LSTM(bidirectional long short-term memory, BiLSTM)构建一个混合记忆网络模型,实现对用户点击行为的预测.由于GESP模型在训练最后的预测模型时不对预训练得到的物品向量表达进行更新,为区别于相关工作,我们将其称为固定表达模型.
本文的主要贡献有3个方面:
1) 提出将一种基于协同过滤思想的固定物品表达用于SRS任务,为推荐模型提供物品之间复杂的关联信息与被点击的规律信息,提高推荐模型的预测能力,缓解会话中的兴趣漂移问题;
2) 提出了一个从全局角度表示用户会话中物品点击先后顺序的物品依赖关系图IDG,同时提出一种图表示学习算法GELA从IDG中学习图中的结构化信息,获得物品的固定向量表达;
3) 提出了一种基于图表示学习的会话感知推荐模型GESP.除了将物品固定表达作为输入之外,GESP模型与相关工作的主要区别在于利用BiLSTM进行特征抽象,可以使模型从不同角度观察用户浏览行为并进行学习,更好地捕获用户会话中的兴趣变化.在2个公开数据集上的实验结果表明,GESP模型在准确性、泛化性和多样性方面均优于相关工作.
1 相关工作
1.1 基于会话的推荐系统
SRS是推荐系统领域的近期研究热点之一,其目标是根据历史会话记录中的潜在信息(如用户的点击浏览记录)预测用户下一次点击.
传统的推荐系统模型,如矩阵分解模型(matrix factorization, MF)[7]和Markov链模型(Markov chains, MC)[8],并不能很好地应用于SRS任务中,分别是因为用户-物品矩阵中用户评分的缺失和无法有效建模序列中的上下文信息(一阶依赖问题).受MF和MC的启发,一些研究人员提出结合二者优势的混合模型[9-10],如Markov链个性化分解模型(factorization personalized Markov chains, FPMC),通过分解底层MC上的转移矩阵来建模用户的顺序浏览行为,提供个性化推荐.
随着深度学习模型近年来在各领域不断取得的进展,SRS领域也提出利用深度学习的方法预测用户的下一次点击[11].Hidasi等人[5]使用带有门控循环单元的深度循环神经网络(GRU4Rec),利用历史点击记录来建模会话数据.GRU4Rec在SRS任务中预测下一次点击时会通过RNN的结构来综合考虑用户的历史行为.在GRU4Rec的研究基础上,Quadrana等人[12]在SRS任务中结合用户画像使用分层循环神经网络进行个性化推荐.Li等人[4]提出一种物品注意力机制(item-level attention mecha-nism)来明确考虑会话中每个物品的重要程度,结合编码器-解码器(encoder-decoder)架构,来捕获用户在会话中的主要目的.Liu等人[2]提出了基于注意力/记忆机制的模型,该模型同时考虑了用户的长、短期兴趣,并在推荐时增强了短期兴趣对推荐结果的影响.此外,一些研究将重点放在了物品间的关联性上.Hu等人[3]提出一种浅层神经网络结构,通过计算上下文物品之间的相对距离来捕获其间的关联性.本文与这些工作主要区别在于,本文采用图表示学习的方法学习物品的向量表达,并将其作为预测模型的“固定”输入,利用BiLSTM从不同角度对用户浏览行为进行特征提取,同时考虑用户的长短期兴趣以缓解兴趣漂移带来的影响,最终在不牺牲预测准确性的前提下,为用户提供多样且新颖的选项.
1.2 图表示学习
近期,表示学习在知识库中的应用受到了各领域研究人员的关注,如推荐系统[7]、知识图谱[13]、复杂网络[14]和生物信息学[15]等.表示学习是学习使用各种大型真实网络进行预测的基本步骤[16-17].与图表示学习有关的模型可以根据他们的合成方式分为非线性模型和线性模型.评分函数中包含用于特征提取的非线性激活函数的ER-MLP[13],NTN[18],ConvE[19]等模型称为非线性模型,反之,RESCALL[20],TransE[21],DistMult[22],HoIE[23],ComplEx[24]等模型则被称为线性模型[25].
近期研究工作表明基于图的向量表达已经被使用于一些推荐任务中.如Wang等人[26]提出了一种新闻推荐模型,利用知识图谱中的实体向量表达提供有区分度的互补信息.并在进一步的研究中,将知识图谱作为推荐系统的辅助信息源[27].然而,当前利用物品表达的相关SRS工作通常使用独热(one-hot)编码,或者在深度学习结构中添加表示层,通过随机初始向量表达来表示物品[2-5].对此,Li等人[28]提出异议,认为对于具有海量物品数据的大型电子商务平台而言,上述方法会增加时间复杂度,使其失去性能优势[5].为此,本文提出从图表示学习的角度解决SRS中下一次点击预测问题,并提出利用固定物品表达作为输入构建SRS模型.
2 基于图表示学习的会话感知模型
2.1 符号系统描述
符号约定.用集合S={s1,s2,…,s|S|}表示SRS中所有的会话数据,每个会话si对应一个顺序点击的物品序列,即si=〈v1,v2,…,vNi〉,Ni表示会话si的长度,vj表示在会话si中用户第j次点击的物品,另外利用物品字典(item dictionary, ID)V={v1,v2,…,v|V|}表示在会话集合S中出现的所有物品集合,有vj∈V.
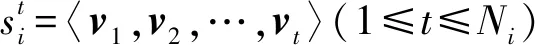
2.2 物品依赖图(IDG)
本文中,IDG表示为G=(V,E),其中V表示物品字典,E表示物品间有向边的集合.在本模型中,物品vi和vj之间的边
IDG结构展示出物品vi∈V在历史会话记录中的顺序依赖关系,可以用于相关物品的协同过滤.
2.3 基于图的表示学习算法
图表示学习在图信息挖掘任务中十分重要[29],常用来作为机器学习前的特征工程,由这个过程得到的表示向量的质量在极大程度上决定了算法最终的实验结果性能[16],因此受到学术界的广泛关注[17].

score(vi,vj,vk)=(vi+vj)·vk.
(1)

Fig.1 The graph embedding learning algorithm图1 基于图的表示学习算法

(2)
2.4 会话感知模型
近期研究表明,用户的长期兴趣和短期兴趣在SRS任务中均具有重要意义[31],STAMP[2]模型通过结合这2种兴趣记忆提高了对用户的下一次点击的预测准确性.受STAMP模型启发,本文提出的GESP模型也包含2种类型的记忆,如图2所示.

(3)

短期记忆mT基于双向LSTM隐状态构建.LSTM可以捕捉长距离依赖关系,但在序列过长的情况下,LSTM的隐状态会聚焦在输入序列较尾端的部分.为解决这个问题,本文选用BiLSTM获取用户的短期兴趣.在时刻t,前向LSTM的网络结构定义:
i=σ(Wixt+Uiht-1),
(4)
f=σ(Wfxt+Ufht-1),
(5)
o=σ(Woxt+Uoht-1),
(6)
g=tanh(Wgxt+Ught-1),
(7)
ct=f⊙ct-1+i⊙g,
(8)
ht=o⊙tanh(ct),
(9)
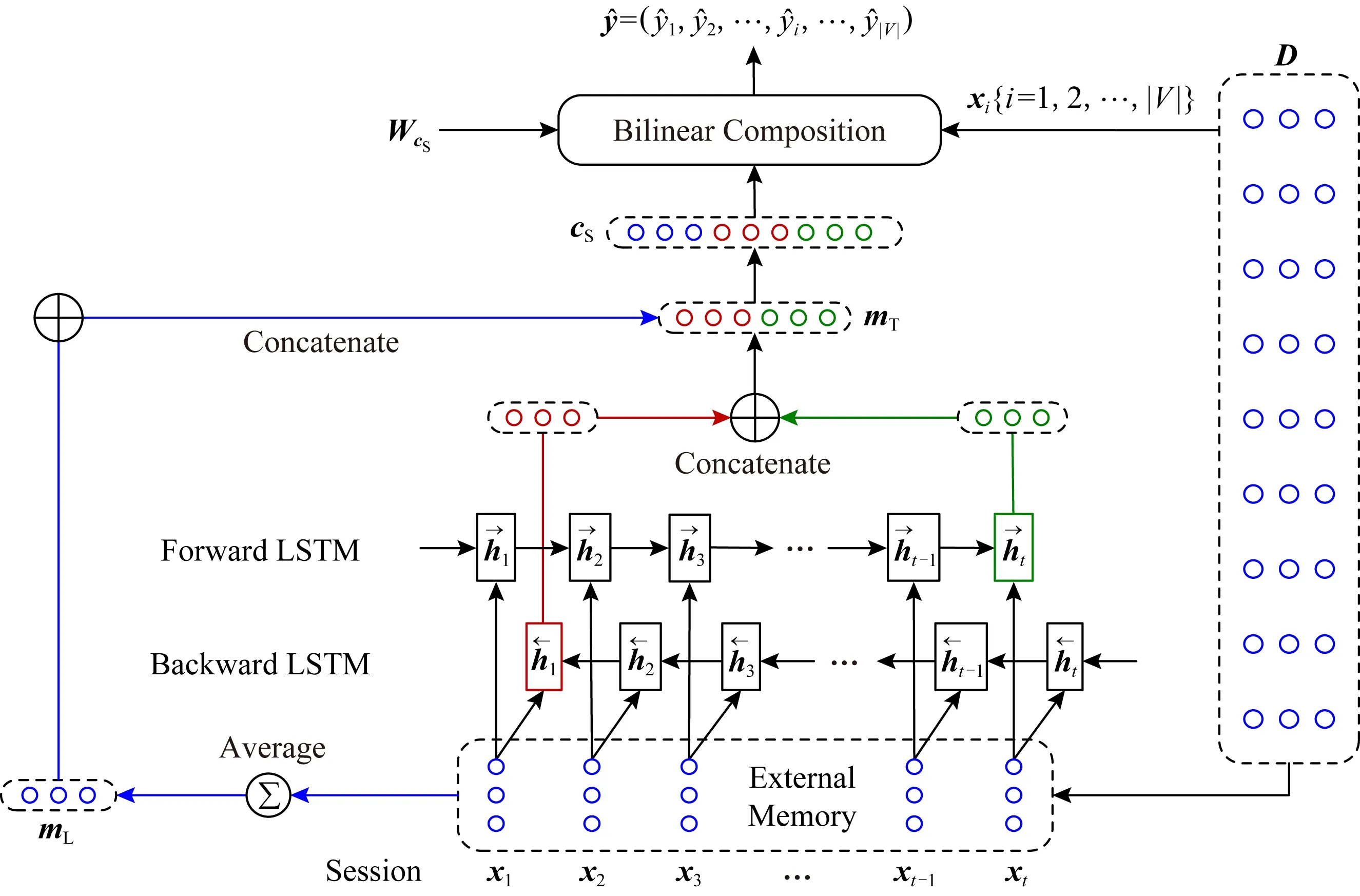
Fig.2 Schematic illustration of the GESP model图2 GESP模型示意图
mT=ht⊕h1,
(10)
其中,⊕表示连接操作,ht表示用户的当前浏览兴趣,h1表示用户的初始浏览兴趣,二者结合,可以更客观地表示用户近期的实际兴趣,提高系统对用户兴趣漂移的敏感度.为了区别于先前定义的长期记忆mL,本文称mT为表示用户短期兴趣的短期记忆.
长期记忆负责捕获用户的长期兴趣,而短期记忆负责捕获用户的短期兴趣,本文将二者结合在一起形成一个新的记忆向量cS:
cS=mT⊕mL.
(11)

(12)
算法1.基于图表示学习的会话感知推荐算法.
输入:训练集S={s1,s2,…,s|S|},si={v1,v2,…,vNi},vj∈V、向量维度d、batch1、batch2、学习率η、学习率衰减速率λ.
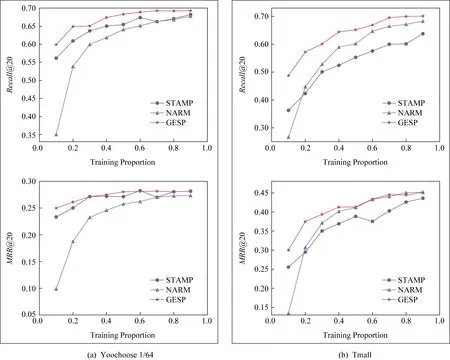
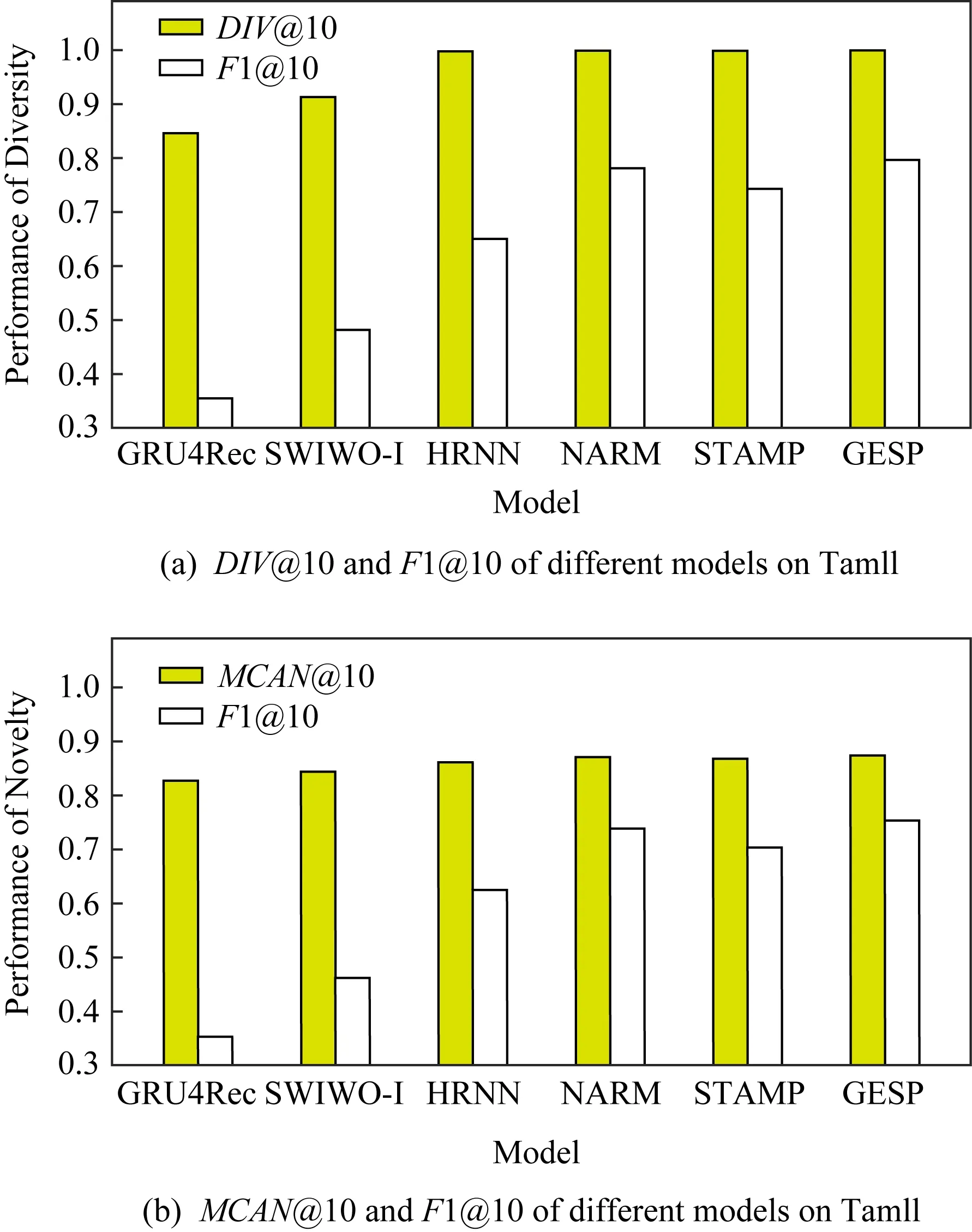
① 初始化S←S-si(∀i,Ni vj(∀j,Count(vj) ② loop ③Sbatch1←Sample(S,batch1); ④ foreach ⑤ foreachvk∈Vdo ⑥qk←scorevk=(vi+vj)·vk; ⑦ end foreach ⑧p←one-hot(V); 人生百年,欢嫛能几?当其百昌,外铄牢愁,中沍冥心,孤运往而不复。琼楼夜冷,锦瑟春啼,结想所生,神光离合。作者、述者,各有会心。皇穹鉴其忠诚,圣人知其怨悱。辞取复意,何假蹄筌?莼农微旨,或在斯乎?[注](民国)王蕴章:《燃脂馀韵》,王英志主编《清代闺秀诗话丛刊》,第621-622页。 为验证基于图表示学习的会话感知推荐模型的有效性,本文在Yoochoose和Tmall等2组公开数据集上进行了评估实验. Yoochoose数据集来自RecSys’15挑战赛,其数据包含yoochoose.com电子商务网站连续6个月的匿名用户会话日志.Tmall数据集来自IJCAI’15竞赛,其数据包含tmall.com在线购物网站连续6个月的脱敏用户会话日志.2个数据集均没有预先分为训练集和测试集. 本文参照其他相关工作对数据进行了预处理.在Yoochoose数据集上,首先将用户会话日志中最后一天的数据作为测试集,余下数据作为训练集.过滤仅包含1次点击的会话以及在训练集和测试集中出现总次数少于5次的物品,然后过滤仅出现在测试集中的物品.在Tmall数据集上,针对购买记录,首先过滤少于3次会话的用户记录以及仅包含一次点击的会话数据,然后随机选择数据集中最后1个月内20%的会话作为测试集,余下数据作为训练集.经过预处理,Yoochoose数据集包含7 966 257个会话,31 637 239次点击,37 483个物品,Tmall数据集包含200 289个会话,600 289次点击,52 206个物品. 根据Tan等人[32]的工作,本文在模型训练之前,对实验数据进行了数据扩充.例如对于给定输入会话si=〈v1,v2,…,vNi〉,生成子序列〈([v1],v2),([v1,v2],v3),…,([v1,v2,…,vNi-1],vNi)〉,将每个子序列中括号内的物品作为输入数据,而剩余一项(即该会话下一次点击的实际结果)作为标签数据.由于Yoochoose数据量过大,现有研究表明使用该数据集较后部分的数据可以获得更好的预测结果[32],因此,本文只取训练数据的最后1/64作为模型的实际训练集,并称之为Yoochoose 1/64.2个数据集的详细统计数据如表1所示: Table 1 Statistics of the Experiment Datasets表1 实验数据集的统计信息 实验开始前,为验证固定表达模型的合理性,本文首先将单个会话中按浏览顺序依次取出的相邻2项物品定义为物品对(item-pair),然后在2个公开数据集上按物品对出现的次数对其进行分类,分别统计在总点击量中物品对出现次数的分布,以及在所有会话中包含该类物品对会话的分布情况,如图3所示.结果表明,物品对出现次数的分布与含有该类物品对会话的分布高度相关,且具有某种规律性,此外,2种分布均显示出与随机分布的明显偏差.因此,在本文构建的IDG上根据物品对来对这种规律性进行建模,学习固定的物品向量表达,这比随机初始化embeddings向量产生的结果更有说服力. Fig.3 Item-pair distribution and session distribution图3 物品项对分布以及会话分布 为评估GESP模型的性能,将在上述2个数据集上与相关工作中提及的8种模型进行对比. 1) POP.最简单的SRS算法模型,始终根据训练集中物品的出现频率排名进行推荐. 2) FPMC.文献[9]提出将MF和MC的相结合的模型,该模型为每个用户生成单独的转移概率矩阵,生成转移矩阵立方体.利用张量分解中的标准分解(canonical decomposition, CD)方法,分解该立方体.此后,引入贝叶斯个性排名(Bayesian personalized ranking, BPR)来优化模型参数,使推荐结果更为准确.为了使其适用于SRS,本文在计算其推荐分数时不考虑原模型中用户的潜在表示. 3) SWIWO-I.文献[3]提出的一个浅层神经网络模型,该模型将会话中的物品以独热向量的形式,作为高维数据输入到编码层,生成低维向量,获得会话上下文表达,用以生成多样化的推荐结果. 4) GRU4Rec.文献[5]提出的GRU模型,该模型将会话进行拼接,利用小批量的并行计算,提高训练效率.并根据物品“热门程度”进行采样,对采样结果划分正负样本,采用基于排名的损失函数. 5) HRNN Init.文献[12]提出的基于GRU4Rec的分层模型,该模型引入了一个额外的GRU层来跟踪用户在整个会话中的兴趣演变过程. 6) HRNN All.HRNN模型的另一个变体[12],具有更复杂的结构,其中附加的GRU层用于在模型初始化时生成用户的向量表示并在会话之间传递信息. 7) NARM.文献[4]提出的在RNN中加入了注意力机制的模型,该模型利用注意力机制从隐状态捕捉用户的意图,并结合用户浏览时的顺序行为信息生成最终兴趣表达来进行推荐物品选择. 8) STAMP.文献[2]提出的短期记忆/注意力优先的模型.该模型引入记忆力与注意力机制同时考虑用户长/短期兴趣,并通过提高短期兴趣的重要性来缓解兴趣漂移对推荐模型的影响. 其中,对于SWIWO-I,GRU4Rec,HRNN,NARM,STAMP,本文使用了原论文发布的代码,在缺少相关结果的数据集上进行参数调优获得最终的实验结果,对于POP和FPMC模型,引用了相关论文中发布的结果. 在评测模型性能时,本文采用Recall@K和MRR@K评价指标. Recall@K用于衡量会话推荐系统预测准确性的指标,表示推荐结果排名列表中排在前K个推荐物品中有正确答案数量占所有测试数的比例,该算法定义: (13) 其中,N表示测试集中的样本数量,nhit表示前K个推荐物品有该样本正确答案的样本数. MRR@K指平均倒数排名(mean reciprocal ranks, MRR),表示如果某样本推荐结果vt的排名大于或等于K,则将其MRR@K值设置为0,否则将保持该排名值,并用于平均计算: (14) MRR@K分数的值的范围被限制在[0,1]区间内,其值越大,表明推荐的命中率越高. 本文在评价模型结果时取用K=10和K=20,因为在SRS的实际应用中,多数用户仅关注出现在第一页的推荐结果. 本文GESP模型的超参数通过网格参数寻优法进行选择,其参数选择范围设定:学习率η∈{0.001,0.005,0.01,0.1,1}、学习率衰减速率λ∈{0.75,0.8,0.85,0.9,0.95,1.0}、物品向量表示维度d∈{50,100,200,300}.根据随机选择的测试集进行网格寻优,取Recall@20指标最优时的参数组合d=100,η=0.005,λ=1.0作为本文实验参数.训练批量设为512,Adam算法迭代次数设置为50轮.所有权重矩阵均采用服从N(0,0.052)的正态分布的随机数初始化. 表2记录了GESP模型和其他对比模型的实验结果: Table 2 Next-Click Prediction on Yoochoose and Tmall表2 Yoochoose和Tmall数据集上点击预测实验结果 % Note: Best results are in bold. 通过实验结果分析可以得出3方面认识: 1) 本文提出的GESP模型在Recall@20的测度上始终优于最先进的模型NARM和STAMP,与NARM模型相比,GESP模型在2个数据集上的准确率分别提高了1.05%,3.20%,与STAMP模型相比,分别提高了0.63%,7.93%.GESP模型的MRR@20得分在Tmall数据集上排名第1,在Yoochoose 1/64数据集上排名第2,与最优模型结果相近.本文认为准确率提升的结果源于GESP模型的2个特点:①它综合考虑了用户的短期兴趣和长期兴趣,这有助于缓解用户兴趣漂移的问题.已有研究可以证明这种长/短期记忆机制的有效性[2].此外,本文的实验结果为研究SRS中用户的行为模式提供了新的发现,例如基于图生成的物品固定表达有助于构建长期记忆,使用BiLSTM网络有助于对短期记忆建模,本文将在3.6节和3.7节深入讨论这2个问题.②它从IDG学习物品向量的固定表达,这有助于GESP模型更好地从全局角度捕获用户浏览时的兴趣变化规律.相较之下,传统的采用随机初始化物品向量表达的方法会忽视掉物品之间重要的隐式关联信息. 2) 基于RNN的深度学习模型在测试集中均有较好表现,这表明在对序列会话建模时,RNN对捕捉会话序列中用户的浏览模式起着重要作用.进一步对比发现,GESP模型、NARM模型、STAMP模型的表现明显优于GRU4Rec模型和HRNN模型(即HRNN All和HRNN Init),由此推论,结合用户长/短期兴趣可能是提高SRS模型推荐准确性的必要条件. 3) 当采用不同的数据集评估时,我们发现FPMC的性能极不稳定,其评估结果在Tmall数据集上的表现特别差.考虑到Tmall数据集具有明显的稀疏性问题(平均而言,Tmall数据集中每个会话只包含2.99次点击),这个结果表明矩阵分解方法对数据的稀疏度非常敏感.相比之下,SWIWO-I模型在2个数据集上的表现都较为稳定,这进一步表明神经网络解决方案比矩阵分解方法更适合解决基于会话的推荐问题,而基于记忆力机制的深度神经网络模型在一定程度上可以提升这种优势(如GESP和STAMP). 综上,2个公开数据集上的实验结果证明GESP模型在SRS中的有效性.为验证模型各组成部分的有效性,本文设计了进一步的实验. 如引言所述,本文的主要贡献在于提出了一种基于IDG的固定物品表达,并以此为基础来进行推荐.现通过2个方面验证利用图表示学习方式生成固定物品表达的必要性:1)使用固定物品表达是否可以提高模型的稳定性;2)使用固定物品表达是否可以提高模型的准确率. 在SRS任务中,由于用户和物品数量众多,历史会话数据常过于庞大,使用全部数据进行模型训练会使训练时间无法满足在线推荐服务的需求.因此从有限的数据子集中训练出一个性能较好的预测模型具有重要实际意义.本文利用固定物品表达作为GESP模型输入的初衷源于IDG的结构可以反映物品之间复杂的关联信息,使用这种表达的GESP模型比使用随机初始化embedding的其他模型可以获得更稳定的表现.为验证这一猜想,本文将训练集随机划分为10个子集,分别对GESP模型、STAMP模型、NARM模型进行10轮实验,每轮实验增加一个子集来扩充训练集.使用相同的测试集进行评测,结果如图4所示: Fig.4 Performance on different proportion of training data图4 训练集增量实验效果 图4显示了3种模型在增量实验中的结果,在Yoochoose和Tmall数据集上,GESP模型的预测准确性始终优于另外2个当前性能最好的模型,而且随着训练数据量的增加,GESP模型在保证了准确性的情况下具有更高的稳定性(折线图的波动性相对更小).结果表明:利用图表示学习从IDG中得到的固定物品表达,使GESP模型性能更优,且对数据稀疏性的敏感度降低,因此GESP更适用于实际SRS任务. 为进一步验证由图表示学习得到的物品表达的适用性,本文新增了一个基线模型GESP-G进行对比实验,与GESP不同的是,GESP-G采用随机初始化的方式生成物品表达,且在模型训练过程中通过反向传播进行更新,实验结果如表3所示.实验数据表明,基于IDG构建的物品表达在GESP模型中具有重要作用,在不采用这种机制的情况下,模型的性能显著下降,尤其是在处理高度稀疏数据时(如Tmall数据集). Table 3 The Impact of the Graph-Based Item Embeddings表3 图表示学习的影响 % Note: Best results are in bold. 本文所提出的混合记忆网络模型利用了一种基于BiLSTM隐状态构建的长/短期兴趣建模机制,为验证本文所提出的用户兴趣模型各部分的有效性,在相同的条件设计了1组对比实验,结果如表4所示.其中,1)GESP是本文提出的标准模型;2)GESP-C是GESP的变体,无短期记忆mT;3)GESP-M是GESP的变体,无长期记忆mL. 由表4可知,GESP在2个数据集上的Recall@20和MRR@20得分,以及在更严苛条件下的Recall@10和MRR@10得分均优于其他2个变体.与此同时,GESP-M的性能整体优于GESP-C. Table 4 The Impact of General/Temporal User Interests表4 用户长短期兴趣的影响 % 由表4可以得出2个结论: 1) 短期记忆mT和长期记忆mL所携带的信息在预测下一次点击时是互补的,这验证了GESP使用的长/短期记忆组合机制的有效性. 2) 短期记忆mT所携带的短期兴趣可能比长期记忆mL所携带的长期兴趣更重要. 为了进一步研究这2种兴趣(长期兴趣、短期兴趣)的作用,本文分别计算了这3个模型在不同长度会话(基于Yoochoose 1/64数据集)上的表现,结果如图5所示.分析数据可以看到GESP-M的性能与GESP接近,但GESP-C的性能明显弱于其他2个模型.并且随着会话长度的增加,GESP-C模型的准确性显著下降.这种差异表明了长会话中存在的用户兴趣漂移问题对SRS的影响,并显示出考虑用户短期兴趣的必要性;通过对GESP和GESP-M性能的比较,说明了同时考虑用户的长短期兴趣有助于进一步缓解用户的兴趣漂移问题;GESP模型也受会话长度的影响,随着会话长度的增加,其预测准确率也会随之降低,这表明本模型的短期兴趣建模机制仍有改进的空间. Fig.5 Evaluation results calculated separately with regard to different session length on Yoochoose 1/64图5 Yoochoose 1/64上不同会话长度的评测结果 除了推荐准确性之外,多样性和新颖性也是SRS中重要的评估指标.推荐多样且新颖的内容,可以提高SRS的用户体验,缓解由于模型过拟合(过度关注当前会话浏览内容)带来的问题[33-34].本文通过引入IDG,利用一种基于协同过滤思想的图表示学习算法构造物品的固定表达,从全局角度捕获物品之间的复杂关联,可有效缓解上述问题.本文设计了一组对比实验,比较不同模型推荐结果的多样性和新颖性. 尽管多数研究人员都认为在构建SRS模型时应将多样性与新颖性考虑在内,但目前学术界关于多样性与新颖性的衡量方法还没有达成共识[33].根据之前的研究[3],本文列出DIV@K和MCAN@K指标作为参考. DIV@K得分是指在含有N个测试样本的推荐结果中,任意2组推荐结果(Ri,Rj)之间的平均非重叠比率(每组推荐结果由推荐得分排名前K的物品组成).该指标常被用于衡量推荐内容的多样性[3,35],其定义: (15) 其中,i≠j,N表示测试样本的数量,因此所有可能组合的数量为N(N-1)/2. (16) F1@K得分是召回率和精确率的调和平均值.本实验中引入的F1@K得分定义与F1得分类似,在评估推荐结果的多样性时,精确率由DIV@K替换,在评估推荐结果的新颖性时,精确率由MCAN@K替换.因此,相应的F1@K得分可以综合考虑推荐结果的准确性和多样性及新颖性: (17) (18) 当K=10时,GESP与另外5个对比模型在Tmall数据集上的实验结果如图6所示,经过分析可以得出3个结论:1)本文提出的GESP模型与其他2个性能最优的NARM模型和STAMP模型表现不相上下,但在F1@10分数方面,GESP模型、NARM模型、STAMP模型都优于GRU4Rec模型、SWIWO-I模型、HRNN模型,这意味着后者的推荐结果虽然具有多样性和新颖性但是牺牲了推荐准确性.2)除GRU4Rec模型外,其余模型的DIV@K分数都在90%以上;所有模型的MCAN@K分数都在80%以上,分析认为由于Tmall数据集的数据稀疏性导致了结果略有失真.3)值得注意的是,HRNN这种致力于个性化推荐的模型,其实验结果比GESP模型和STAMP模型等基于长短期记忆的模型稍差,但始终优于GRU4Rec模型.这表明一方面长短期记忆机制能有效缓解用户兴趣漂移,带来推荐准确性的提升;在另一方面,用户的历史会话信息是生成多样且新颖的推荐结果的重要补充信息源. Fig.6 Diversity and novelty of different models on Tmall图6 不同模型在Tmall数据集上的多样性和新颖性 本文进一步通过与其他图表示学习算法(包括TransE[21],DistMult[22],ComplEx[24],ConvE[19])进行比较来验证GELA的有效性.实验思路是分别使用不同的图表示学习算法学习物品的向量表达,然后使用学到的物品向量表达作为GELA的输入在测试集上进行推荐实验,即根据模型的输出得分得到推荐结果,实验结果如表5所示: Table 5 Recall@20 of Different Graph Embedding Methods表5 不同图表示学习方法的Recall@20得分 % 从表5可以看出,GELA模型始终优于其他模型,在处理极稀疏的Tmall数据集时,这种优势更加明显.这表明本文所提出的算法能更加有效的学习物品向量表达.此外,除了推荐的准确率,模型的运行时间也是衡量性能的重要指标.因此,本文将GELA模型与其他图形嵌入方法在计算效率方面进行比较,使用相同100维的初始向量和GPU环境.得到各个模型在Yoochoose 1/64数据集上训练迭代一次的时间开销如表6所示: Table 6Time Cost of Training Different Graph Embedding Methods表6 Yoochoose 1/64上训练不同图模型的时间开销 s 从表6可以发现,除了TransE模型之外,本文提出的GELA模型计算成本显著低于其他图表示学习方法,且TransE模型需近1 000次训练迭代得到最好结果,而GELA模型设计简单,只需要30次迭代.以上实验结果证明GELA模型适用在大规模的IDG上进行物品的表示学习. 关于GELA算法中跳数的选择问题.如2.3节所述,本文选用2跳路径进行模型训练.对于给定的物品点击序列 Fig.7 The results of GESP by employing different hops embeddings on Yoochoose 1/64图7 Yoochoose 1/64上使用不同跳数生成的embedding的GESP模型性能 从图7可以看出,GESP在跳数为2时性能最佳,增加跳数长度将导致性能下降.这是因为当采样路径变长时,用户的浏览兴趣会随着时间的推移而不断改变.根据这一实验结果,本文采用2跳路径进行物品向量表达的学习. 本文首次提出一种利用协同过滤思想的基于图表示学习的会话感知模型(GESP)用于基于会话的推荐系统任务.该模型基于用户会话日志构造一个全局物品依赖关系图,利用图表示学习算法学习物品固定向量表达,以此为输入,采用双向LSTM构建一个混合记忆网络模型,实现对用户点击行为的预测.采用固定的物品向量表达作为输入,在不牺牲预测准确性的前提下,利用物品依赖图中的结构信息,同时考虑用户长短期兴趣,缓解用户的兴趣漂移问题,生成多样且新颖的推荐结果.本文为基于图表示学习的会话推荐研究提供了新的建模思路和解决方案,同时也为后续研究留下了一些值得思考的问题,如在Yoochoose 1/64数据上,STAMP模型在MRR@K得分方面略优于GESP和NARM,这表明在构建SRS模型时需要对注意力机制进行进一步研究. 总体来说,本文实验结果表明,在预测准确性方面,GESP模型优于其他相关先进模型,在长会话和稀疏数据集上也具有更稳定的表现.此外,与其他模型相比,本文提出的模型可以有效缓解用户的兴趣漂移对预测结果带来的影响,能够在不牺牲预测准确性的情况下,提供更加多样新颖的推荐结果.


3 实验结果与分析
3.1 数据集与预处理


3.2 对比模型
3.3 评价指标
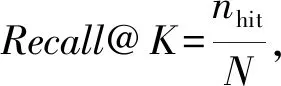
3.4 超参数
3.5 点击预测

3.6 图表示学习的必要性

3.7 对用户兴趣建模的有效性


3.8 推荐结果多样性和新颖性分析
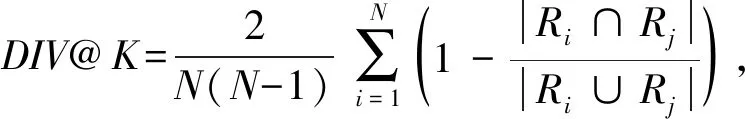
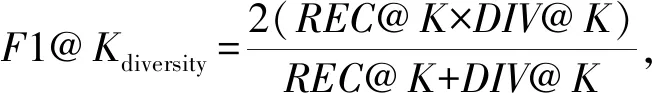

3.9 与其他图表示学习算法的比较


3.10 依赖图采样跳数的影响

4 结束语
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17新高考·高一数学(2022年3期)2022-04-28计算机研究与发展(2022年1期)2022-01-19中学生数理化(高中版.高考数学)(2021年1期)2021-03-19长江丛刊(2020年17期)2020-11-19考试周刊(2016年82期)2016-11-01高中生学习·高三版(2016年9期)2016-05-14新高考·高二数学(2015年11期)2015-12-23文苑(2015年9期)2015-09-10新课程学习·中(2013年3期)2013-06-14
