
基于最大频繁子图挖掘的动态污点分析方法
2020-03-21 01:10郭方方王欣悦王慧强吕宏武胡义兵冯光升
计算机研究与发展 2020年3期
郭方方 王欣悦 王慧强 吕宏武 胡义兵 吴 芳 冯光升 赵 倩
1(哈尔滨工程大学计算机科学与技术学院 哈尔滨 150001) 2(哈尔滨商业大学计算机与信息工程学院 哈尔滨 150028)(guofangfang@hrbeu.edu.cn)
近年来由于恶意代码攻击事件发生频率越来越高,危害性日益凸显.高效率的恶意代码识别方法对于保障主机运行时安全必不可少.现有识别恶意代码方法按检测时代码是否在内存中真实运行可分成2类:1)静态分析方法;2)动态分析方法.动态分析方法相比较于静态分析方法提取到的特征更加准确.因为,即使经过混淆处理后的代码,代码在运行时特征是无法隐藏和改变的,具有更高的识别准确率.因此,使用动态分析方法识别恶意代码已成为研究热点.其中,最常用的技术是动态污点分析技术[1-2].动态污点分析方法首先通过污点标记、污点传播、应用程序接口(application programming interface, API)进行中间截取污点文件,污点文件就是把污点传播路径记录下来,最后使用得到的污点文件构建恶意代码的行为依赖图(malicious code behavior dependency graph, MBDG).目前具有代表性的动态分析工具包主要有CWSandbox[3],TTAnalyze[4],Norman Sandbox[5],Anubis[6]等.
目前,国内外研究重点关注的对象是动态污点分析方法的实现问题.Mchaisen等人[7-8]提出一种AMAL分类器,该分类器能够根据恶意代码的行为进行自动的分析.但该分类器忽视了程序的控制依赖关系,易造成漏报现象.Fattori等人[9]设计了一套恶意代码行为检测系统AccessMiner,实时检测恶意行为,但该系统存在数据量过大、匹配时间过长的问题.Alam等人[10-11]提出了一种MARD框架,该框架主要是针对各种变异恶意代码的检测,能够对变异恶意代码实时快速检测.此外,他们还提出了一种SWOD-CFWeight方法,该方法能够根据恶意代码的控制流语义对恶意代码进行实时捕获.但该方法依然存在存储空间消耗过大问题.Ghiasi等人[12]提出一种基于寄存器内容的恶意代码检测框架,但该框架受环境限制较大且存在存储空间爆炸问题.Salehi等人[13]使用分类算法对恶意代码的API调用和参数一起作为输入特征对恶意代码进行检测,但该方法提取的特征较少,准确率不高.Qiao等人[14]假设频繁API调用序列可以准确反映恶意代码行为,通过聚类算法探索恶意代码之间的内部规律,此外,提出了一种使用聚类和分类相结合的技术来识别恶意代码,该方法主要是计算各个二进制形式的文件来进行预测[15].Toderici等人[16]提出一种Chi-Squared方法,将隐Markov模型与卡方检验的统计框架相结合,用来检测变形恶意代码.但这2个方法都存在存储空间消耗过大的问题.
综上所述,目前的研究成果对依赖图数量多、存储空间消耗过大的问题描述较少甚至未加说明,而此问题已经逐渐成为影响动态污点分析技术发展的重要瓶颈.因此,以减少依赖图数量为切入点,力图保证特征完整性,并削减行为依赖图数量,从而进一步提高识别效率.
1 行为依赖图的定义与生成
本文提出了基于最大频繁子图挖掘的动态污点分析方法.即根据每个恶意代码家族具有共性的特点[17-19],把每个恶意代码家族的最大频繁子图挖掘出来,各个恶意代码家族的依赖图数量会大幅度减少.恶意代码家族及其变种恶意代码的主要特征都包含在挖掘出的最大频繁子图中,待测代码只需和挖掘出的这些最大频繁子图进行匹配就可得出结论,这样提高了识别效率.最大频繁子图方法采用基于生成树的挖掘(spanning tree based maximal graph mining, SPIN)方法.下面对该方法进行详细介绍.
1.1 行为依赖图定义
在介绍具体方法之前,先给出行为依赖图的定义:Gbeh={V,DE,CE,φ,L},Gbeh表示行为依赖图.其中,V表示图的顶点,DE(DE⊆V×V)表示数据关联边,控制关联边用CE(CE⊆V×V)表示,标号集为φ,集合内部有相应API名称、必要的输入性参数、某些输出参数和结果的返回值,L为V和φ间的一种映射关系,具体为L:V→φ.动态污点分析方法主要依靠分析污点文件,污点文件中包括在执行一段恶意代码过程中,该段代码在执行过程中调用的重要API以及相应重要指令返回值,当执行一段程序后,根据污点文件生成许多行为依赖图,这些依赖图被记入一个集合中,称为总行为依赖图集合,表示为GG,在这里把集合GG记为
GG={Gbeh1,Gbeh2,…,Gbehi,…,Gbehn},1≤i≤n.
1.2 生成行为依赖图
生成行为依赖图包括4个主要部分:顶点添加部分、数据关联边添加部分、控制关联边添加部分和生成结束判断部分.其中行为依赖图采用邻接矩阵的形式存储,而顶点间的数据关联边用1表示,控制关联边用2表示,无相应依赖边用0表示.详细步骤描述为:
1) 添加顶点.首先分析污点文件,对于某一API来说,污点参数存在该API中,那么该API为邻接矩阵中的一个顶点.

3) 添加控制关联边.某段代码在运行时,会出现新的API被调用的情况,这时必须考虑这个API是否存在于某个污点数据使用控制转移指令所能抵达范围之内.如果使用控制转移指令可以到达,那么邻接矩阵某对应位置记为2,代表控制关联关系存在于它们之间.
4) 判断结束条件.当有2种情况出现时,行为依赖图被终止生成:①污点文件分析完成.对污点文件不断分析,行为依赖图中的顶点数量以及边的数量都不断增多.当某污点文件被分析完成,邻接矩阵中所有空位被补上0,据此邻接矩阵生成最终行为依赖图.②当未污染的数据重新覆盖目前已存在的污点数据时.
由邻接矩阵生成对应行为依赖图的方法由算法1表示:
算法1.生成行为依赖图.
输入:邻接矩阵A;
输出:行为依赖图G.
① for each API inA
② 向G中添加顶点;
③ end for

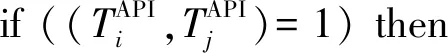
⑧ end if
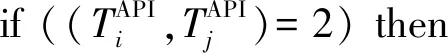
2 最大频繁子图生成
最大频繁子图生成算法是核心与重点,其名称是SPIN-MGM(MBDG mining method on spin).该方法首先从获得的行为依赖图集中使用FFSM(fast frequent subgragh mining)方法获得候选频繁子图集,再通过扩展方法进行候选数据关联边和控制关联边的添加生成最大频繁子图集.
2.1 FFSM方法
FFSM方法使用规范邻接矩阵CAM(canonical adjacency matrix, CAM),通过该矩阵能够得到规范编码,通过使用CAM矩阵就不需要直接计算同构子图,既可以唯一的表示图,又能降低时间复杂度.要想得到有向图的规范编码需要遍历邻接矩阵,这是因为行为依赖图是有向图.
FFSM方法首先使用FFSM_Join函数和FFSM_Extension函数产生候选子图.其次,对产生的候选子图进行剪枝,这是为了筛选掉非频繁子图以及CAM不是次优的子图,最终达到减少候选子图数量的目的.FFSM方法具体过程由算法2表示:
算法2.FFSM.
输入:行为依赖图集GG、最小支持度SUPmin;
输出:候选频繁子图集W.
①S←{频繁顶点的CAM集合};
②P←{频繁边的CAM集合};
③ for eachp∈Pdo
④ if (pis CAM) then
⑤W←W∪{p},D←∅;
⑥ forq∈Pdo
⑦D←D∪FFSM_Join(p,q);
⑧ end for
⑨D←D∪FFSM_Extension(p,q);
⑩ 剪枝去掉候选子图中非频繁子图或
CAM不是次优的;
2.2 SPIN-MGM方法
SPIN-MGM方法对由FFSM方法产生的候选频繁子图集进行剪枝和扩展处理来获得最大频繁子图集.SPIN-MGM方法由算法3表示:
算法3.SPIN-MGM.
输入:行为依赖图集GG、最小支持度SUPmin;
输出:最大频繁子图集EG.
①Trees←{T|T是GG中的一棵频繁树};
②F←{EG|EG∈Expansion(T) andT∈Trees};
③ return {EG|EG∈FandEGis maximal}.
其中扩展方法Expansion由算法4表示:
算法4.扩展方法Expansion.
输入:频繁子树T;
输出:频繁子图集EG′.
①D←{de|de是T中的候选数据关联边};
②F←SearchGraphs(T,D);
③C←{ce|ce是T中的候选控制关联边};
④F←SearchGraphs(T,C);
⑤ Return{EG′|EG′∈F,EG′是频繁的,EG′和T有相同的正则生成树}.
其中SearchGraphs方法由算法5表示:
算法5.SearchGraphs方法.
输入:频繁子树、候选控制依赖边(T,C)或候选数据依赖边(T,D);
输出:M.
①M←∅;
② for eachei∈Cor eachei∈Ddo
③M←M∪SearchGraphs(G⊕ei,{ei+1,ei+2,…,en});
④ end for
⑤ returnM.
2.3 最大频繁子图的应用
最大频繁子图的作用主要体现在实际匹配过程中.设计的匹配方法主要实现过程是:挖掘出所有恶意代码家族行为依赖图中的最大频繁子图后,生成特征库,然后实时跟踪恶意代码,绘制出依赖图.通过匹配方法来得到行为依赖图之间的相似度.
匹配方法将目标行为依赖图Gtarget与特征库中行为依赖图集GG中每个最大频繁子图都进行匹配,得到1组匹配结果,得到的结果被存储到数组中.当进行匹配时,对数组进行一次遍历,遍历得到的最大值就是最终的匹配结果.由算法6表示:
算法6.匹配方法.
输入:GG,Gtarget;
输出:匹配结果.
① for eachg∈GG
②m←0;
③n←0;
④i←0;
⑤ for eache∈g
⑥ ife∈Gtarget
⑦m++;
⑧ else
⑨n++;
⑩ end if
3 实验结果与分析
3.1 实验指标
实验对提出的基于最大频繁子图挖掘的动态污点分析方法进行实验,并通过实验数据对该方法可行性进行研究.此外,与传统面向恶意代码识别的动态污点分析法以及文献[9,16]中提到的一些方法进行性了对比实验,突出本文所提出方法的有效性.
实验结果的测量使用准确率、误报率、漏报率、最小支持度和识别时间进行度量.这些度量标准主要是由下列4个检验指标来计算,它们的含义如表1所示:

Table 1 Inspection Metric表1 涉及的检验指标
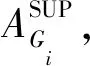
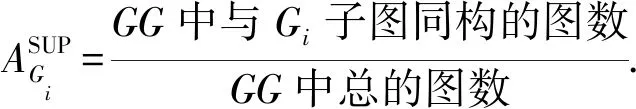
(1)
PR(precision rate),代表能够按样本真实类别分类的样本个数占总样本个数的比率,值越高,代表方法分类效果越好:
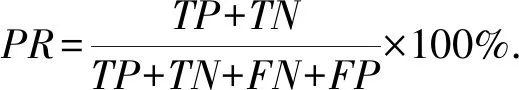
(2)
FPR(false positive rate),代表把正常样本错误地识别为恶意样本的比率,对样本进行了误判.如果误报率越低,那么代表这个方法识别效果就越好:
(3)
FNR(false negative rate),是方法做出了错误的判断,把原本为正常的恶意样本,错误地识别为恶意的.误报率越低代表误判的样本越少,方法效果更好:
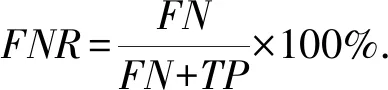
(4)
识别时间,表示从方法开始运行到识别实验所用全部样本所需的时间.
3.2 实验数据
实验所用的恶意代码的来源为http://malware.lu网站,该网站是一个巨大的恶意代码站,目前是由美国进行维护.该网站现有4 963 698个恶意代码样本.在这个网站上可以自由进行恶意代码的下载,并可根据恶意代码的名字和恶意代码的Hash值进行恶意代码搜索.
实验抽取了6类典型恶意代码家族,共6 410个恶意样本,具体如表2所示:

Table 2 Samples of Malicious Code Family表2 恶意代码家族样本
所抽取的6类恶意代码家族是目前最突出且最具代表性的.这些恶意代码大多数以上都经过加壳处理,因此在进行识别之前,要先对恶意代码进行查壳与脱壳处理.
使用的正常样本数据均来自于常见的应用程序,并通过杀毒软件进行验证,如360云盘、QQ音乐、网易云音乐、WPS、GoogleChrome、腾讯视频等,共16 065个.
3.3 实验结果分析
首先,针对SPIN-MGM方法的SUPmin进行实验分析,分析识别准确率PR、误报率FPR和漏报率FNR随最小支持度SUPmin的变化情况,结果如图1所示:
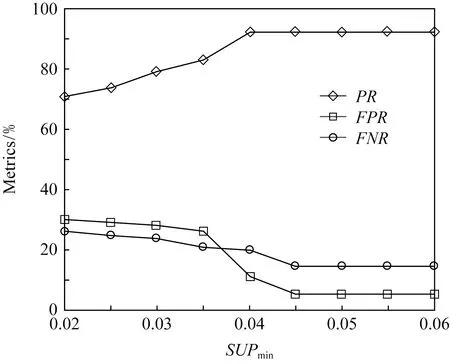
Fig.1 Recognition results varies with SUPmin图1 识别结果随SUPmin变化情况
从图1可以看出,当SUPmin<0.045时,准确率PR逐渐上升,漏报率FNR和误报率FPR都逐渐下降.这是由于支持度变大,SPIN-MGM方法挖掘出的行为依赖图包含更多的共同特征;当SUPmin=0.045时,PR达到92.15%,FPR达到5.64%,FNR为14.67%;当SUPmin>0.045时,PR,FPR,FNR基本保持平稳.当SUPmin=0.045时,识别时间、PR、FPR和FNR达到不错的结果.因此,据以上分析后,SPIN-MGM的最小支持度设置为0.045.
其次,研究SUPmin对识别时间和识别效率的影响.将最小支持度SUPmin依次设置为0.02,0.025,0.03,0.035,0.04,0.045,0.05,0.055,0.06.如图2和图3所示,可以清楚地看到行为依赖图数量以及识别时间随最小支持度变化趋势.
从图2和图3中可以发现,当最小支持度SUPmin从0.02变化至0.045时,经过SPIN-MGM方法不断挖掘,行为依赖图数量不断地在减少.与此同时,识别时间不断削减.这种现象存在的原因是随着SUPmin逐渐增加,符合该支持度的最大频繁子图数量会越来越少,也即特征库中需要进行匹配的行为依赖图越少.因此,识别样本所需时间也越来越少;当SUPmin=0.045时,行为依赖图数量为216个,识别时间约为401 s;当SUPmin>0.045时,行为依赖图数量和识别时间基本不在变化.由上面的分析可以推断出这时挖掘出的行为依赖图数量不再变化.相比之下,传统未经挖掘的识别方法,其识别时间为2 201.3 s.因此,可以得出结论,使用SPIN-MGM方法后可缩短样本识别时间,提高识别效率.
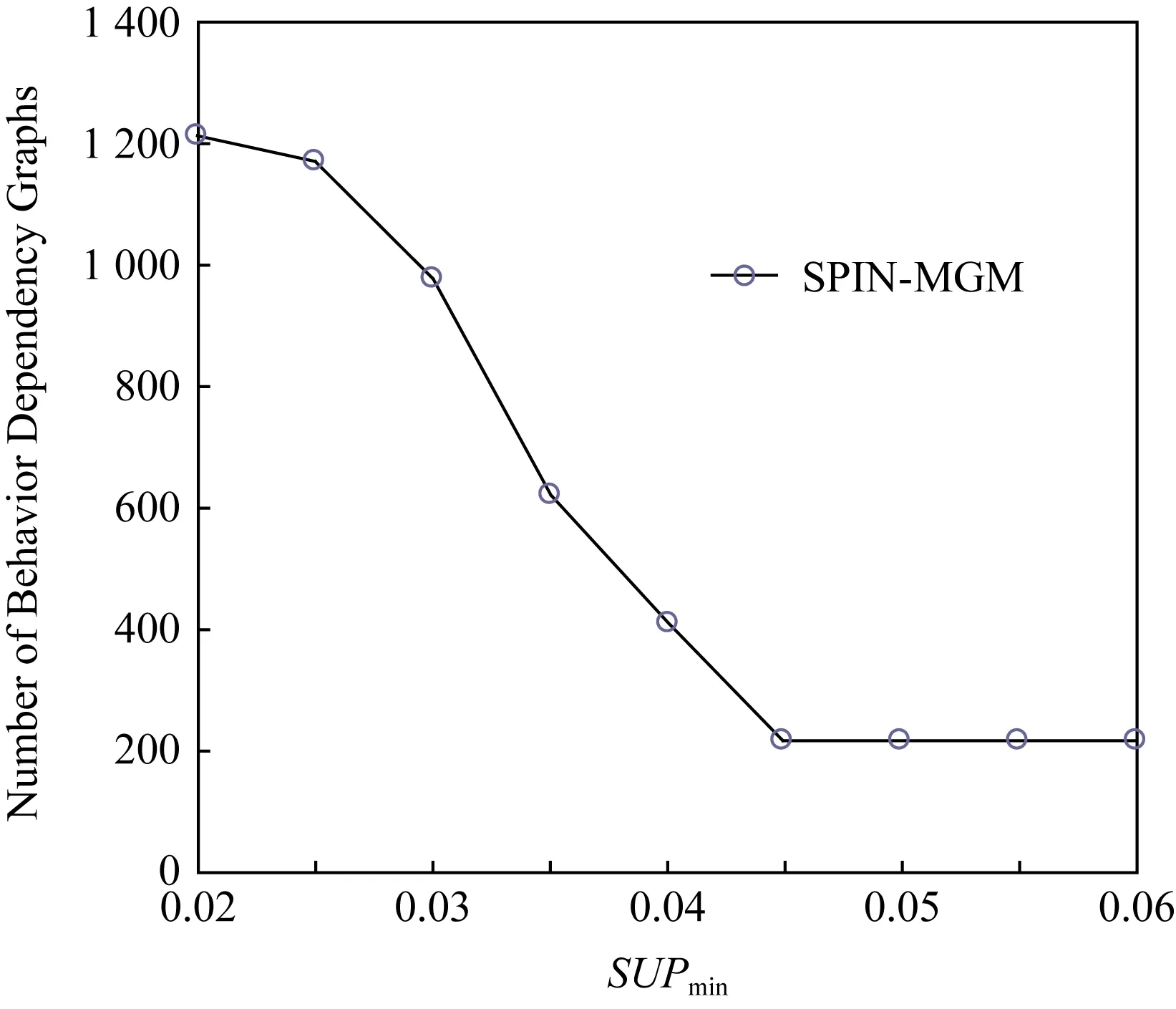
Fig.2 Number of behavior dependency graphs varies with SUPmin图2 行为依赖图数量随SUPmin变化情况

Fig.3 Recognition time varies with SUPmin图3 识别时间随SUPmin变化情况
传统基于动态污点分析技术的恶意代码识别方法,以跟踪API参数的传播路径,找出API之间的依赖关系,挖掘出恶意代码的行为为目的,生成行为依赖图,对恶意代码进行分类.即使用API函数参数提取和基于函数参数的污点分析方法.但是,由于需要与恶意代码家族进行频繁的比对,导致这种传统的方法识别时间过长,识别效率较低.从图2可以看出当SUPmin=0.045时,SPIN-MGM方法特征库中的行为依赖图数量减少到216个.但是,传统行为依赖图污点分析方法中的行为依赖图始终为1 210个左右.因此,SPIN-MGM方法也解决了文献[9,16]中传统动态污点分析方法存储空间消耗过大的问题.
此外,就准确率、误报率和漏报率把提出的SPIN-MGM方法与文献[9,16]中提到的一些恶意代码识别方法进行了性能对比,如图4~6所示.Access-Miner[9]是1个以系统为中心的行为恶意软件检测器,提供了1个通用的检测解决方案,不需要对恶意样本进行训练,因此它的准确率不及SPIN-MGM.Chi-Squared[16]将隐Markov模型与卡方检验的统计框架相结合,用来检测变形恶意代码.SVM[20]是一种常见的分类学习方法,但是这种方法对变种恶意代码的识别准确率相对较差,因为该方法通过样本训练模型,一旦出现一种新型变种恶意代码,它的识别准确率就会降低.
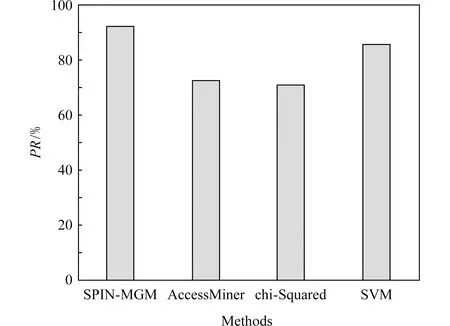
Fig.4 Comparison of recognition accuracy PR offour analysis methods图4 4种分析方法的识别准确率对比

Fig.5 Comparison of alarm failure FPR of four analysis methods图5 4种分析方法漏报率FPR对比
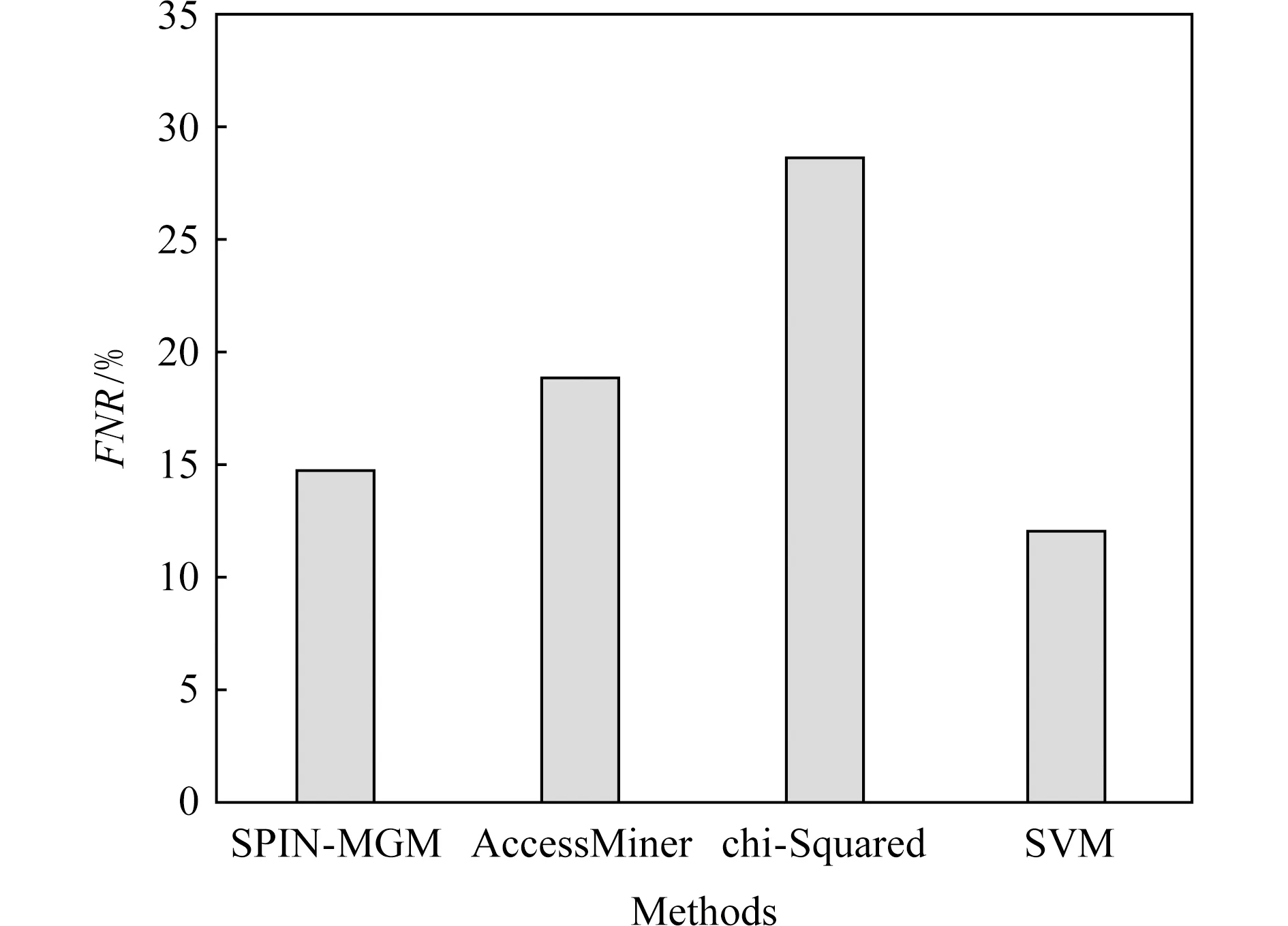
Fig.6 Comparison of false alarm rate FNR offour analysis methods图6 4种分析方法误报率FNR对比
从图4~6中可以看出,SPIN-MGM方法在准确率、误报率上相比于AccessMiner,Chi-Squared,SVM方法达到了更好的效果,在漏报率上优于AccessMiner和Chi-Squared方法.SVM在漏报率上低于SPIN-MGM方法.
4 结 论
恶意代码识别方法是抵御恶意代码攻击的重要方法.动态污点分析方法是现阶段研究的热点,但存在依赖图数量大的问题.据此,本文提出了基于最大频繁子图挖掘的动态污点分析方法,减少了行为依赖图的数量,解决了上述问题,提高了识别速度.1)SUPmin越大,满足该支持度的最大频繁子图越少,即特征库中行为依赖图越少,识别样本集时间也随之变短;2)支持度越大,SPIN-MGM方法挖掘出的行为依赖图越能代表恶意代码家族间的共性特征;3)在本文的实验中,当最小支持度SUPmin=0.045时,行为依赖图数量减少了82%,识别效率提高了81.7%,准确率PR达到92.15%,误报率FPR达到5.64%、漏报率FNR为14.67%.下一步的工作将采用更多类型的恶意代码,进一步提升识别准确率.
猜你喜欢
计算机技术与发展(2022年5期)2022-05-30
小型微型计算机系统(2021年10期)2021-02-28
科学中国人·上半月(2020年4期)2020-06-03
电子竞技(2019年16期)2019-11-11
科技风(2019年13期)2019-06-11
哈尔滨理工大学学报(2017年2期)2017-06-10
现代农业科技(2017年5期)2017-04-19
现代农业科技(2017年1期)2017-03-06
现代经济信息(2016年4期)2016-06-20
科普童话·百科探秘(2016年5期)2016-05-14
