
基于聚类算法的数字图书馆知识推送原理
2020-03-18 16:34宋爱香
江苏科技信息 2020年1期
宋爱香,吴 丹,马 冲
(1.西安工程大学网络与信息化管理处,陕西西安 710048;2.西安工程大学图书馆,陕西西安 710048)
0 引言
信息通信技术的快速发展为信息获取与服务创造了有利条件,使受众可以方便快捷地获取多渠道的信息[1-2]。但在这个信息来源纷繁复杂的时代,如何直接跳过一些与目标信息关联性较差的信息,直接得到关联性强的目标信息便显得尤为重要。否则,源源不断的信息将变成“信息骚扰”,影响用户体验[3]。而现在大多数字图书馆的推送服务存在推送内容单一、推送内容关联度低、推送内容针对性较差等局限性,未对学科资源和用户进行深度开发和关联,不了解高校师生的真实需求,推送模式较简单层次较低[4-5]。因此提高高校数字图书馆推送信息的准确性,有着十分重要的意义。
1 数字图书馆推送满意度调研
了解用户的需求是改善数字图书馆推送服务的关键环节。2019年4月至2019年6月,本文通过网上发布问卷的方式对西安工程大学在校师生进行图书馆推送服务满意度调研。
问卷通过问卷星进行发布与调研,采用5分量化,越接近5分说明期望值越大。调研期间共发出问卷400份,收回问卷388份。通过第一题“你使用过西安工程大学数字图书馆吗?”进行问卷过滤,将答案为“否”的50份问卷予以删除,最终确定338份有效问卷,其中本科生136人、硕士生103人、博士生12人、教职工87人。
利用LibQUAl+TM模型对用户的满意度进行调查。计算公式包括:平均期望值=Σ期望值/问卷份数,平均感受值=Σ感受值/问卷份数,平均最低接受值=Σ最低接受值/问卷份数。从表1可以看出,阅读推荐服务和个人数字图书馆推送服务的用户实际感受明显小于期望值。通过校园随机的走访调查发现,用户一致认为图书馆的阅读推荐仅仅凭借热度,缺乏智能化。对于学生而言,更多的是获取与科研和教学相关的书籍,并非新上架热度高的书籍。针对西安工程大学图书馆用户的需求,本文展开了基于聚类算法的数字图书馆知识推送原理研究。
2 用户聚合类算法分析
由于读者身份、专业以及目的不同,导致读者的属性不同,而在以往的高校数字图书馆推荐系统中,仅向用户推送目前热度较高的书,并没有考虑读者的身份以及需求,这便会造成借阅需求与资源推荐不匹配[6-7],如向理工科学生推荐文学类书籍的现象。本文通过用户信息进行聚类的方式解决这一问题,其流程图如图1所示。首先对不同用户的身份信息进行识别,并进行聚类处理。其次将具有多数相同特征的用户归为一类。另外根据用户的需求构建需求数据库,并将数据库进行细化,使有同类型需求用户的归入一个子需求数据库。紧接着对每个子需求数据库进行关联计算,使得每个关联规则数据库只包含同类型用户的规则。最后向用户推荐借阅资源时,仅限于在包含该用户的关联规则数据库中进行匹配操作。

表1 被调查者对知识推送服务的满意度
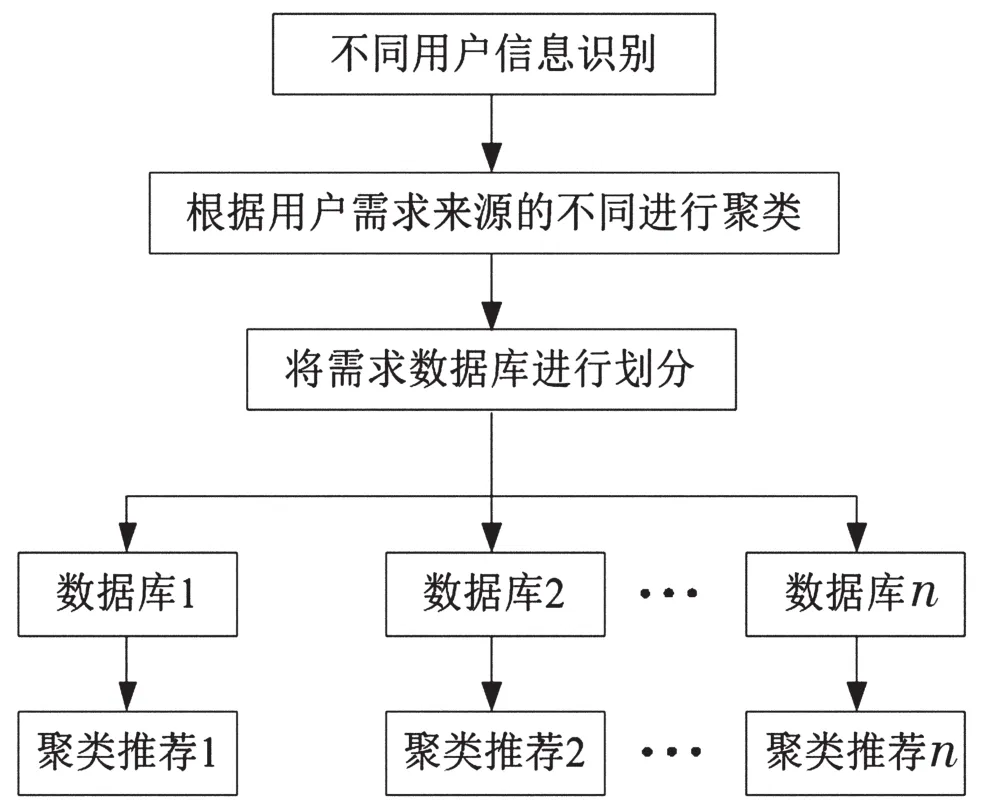
图1 用户聚类流程
2.1 k-means算法对用户特征属性进行划分
用户特征属性的划分是实现多信息聚类的关键,本文采用k-means算法用户特征属性进行划分。将用户的特征属性分别划分为身份、专业和目的。其中,身份属性为顺序关系,将不同用户按照身份顺序排列,进行数字转换计算;而专业和目的属性为符号关系。在距离函数中,可以将身份属性转化为对应的数值关系。当定义不同用户身份为status1和status2时,就可以计算年纪差值为:

用户的专业如“电气工程”是一个字符串定义为符号关系。要计算不同专业之间的距离关系时,将不同专业中不同的字符去除,利用剩余相同字符计算距离:

目的关系的定义过程与专业关系类似,目的串的距离计算公式被定义为:
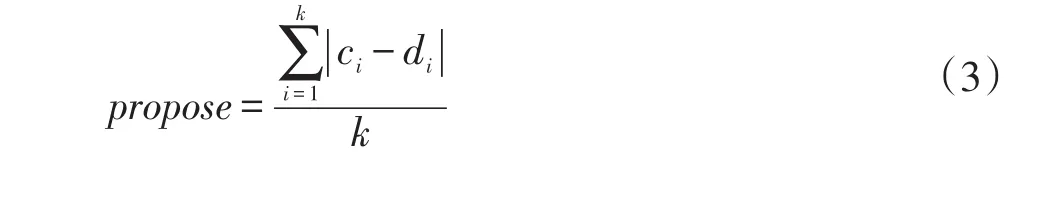
为了实现多信息的聚类分析,需要将用户的年级、专业和目的都应用到一个距离模型中,为此采用下式进行计算。
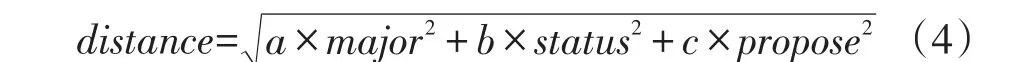
2.2 用户推荐系统聚类分析
本文将用户分为不同的k类,使每一类特征用户都具有较高的相似性。确定聚类个数为k,在被蕨类的n个用户里面,选择k个特征用户作为一开始的聚类中心,其聚类中心选择如图2所示。将每一个特征用户分别与各聚类中心值进行距离计算,寻找用户与初始中心值的最小距离,并将其划入该类。直至将所有特征用户划分完毕后,再重新计算新的中心值。然后重复上述步骤,进行第二次划分,直到算法终止。

图2 聚类中心选择示意
3 用户聚类算法的实现

图3 用户聚类算法的实现示意
用户聚类算法的实现的流程图如图3所示,首先输入各类用户的信息,并设定循环次数以及用户分组变化数的阈值。聚类算法开始后,如果循环次数大于设定值或户分组变化数超过阈值时,聚类算法结束。反之则进行下一步分析,判断所有用户是否完成遍历。如果没有完成,更新聚类中心值,直到遍历完成为止。否则进入属性距离函数进行求解,得到聚类中心的最小值,并将具有相同特征的归入统一聚类中。之后更新目的串、年纪的累加值、专业串、用户数量及聚类中心,进行下一次循环,直至聚类结束。
4 结语
本文采用k-means聚合算法,建立了多信息的距离模型。考虑到高校数字图书馆受众的特殊性,并将其特殊属性关系加入距离函数的计算中,对用户进行有效聚类,使用户在按照对应的年纪信息、专业信息及目的信息所划分的数据库中得到有效的推荐信息,使原有相似信息对用户的模糊推荐得到有效解决。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
财经(2017年2期)2017-03-10
中国建筑装饰装修(2017年1期)2017-02-13
财经(2016年15期)2016-06-03
互联网天地(2016年1期)2016-05-04
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
智能系统学报(2015年4期)2015-12-27
创新作文·初中版(2015年1期)2015-03-11
