
一种应用半监督学习的计量装置运行状态辨识方法
2020-03-18 03:44马吉科祝永晋豆龙龙
计算机与现代化 2020年3期
马吉科,尹 飞,祝永晋,豆龙龙,李 剑
(江苏方天电力技术有限公司,江苏 南京 210096)
0 引 言
随着电力用户的日益增多,电能表计量的准确性涉及广大用户的切身利益。计量装置出厂前经过了计量检定,但在使用过程中可能因为某些原因会出现异常现象,影响了计量的准确性,因此,加强计量装置异常运行状态的监测非常重要。目前计量装置对异常运行状态进行分析、检查和诊断大多通过用电信息采集系统中相关功能进行,这有效避免了人工现场操作带来的麻烦,但是其分析过程中数据量较大,对数据的结果筛查是一项繁琐而艰巨的工作[1-3]。应用深度学习的人工智能技术可以有效减免这些弊端,发挥大电网数据量大、处理速度快、数据类型多、价值大、精准性高的特点,主动深入地钻取数据特性,通过数据关联关系挖掘数据价值,并且随着数据量的增长,迭代式地进行机器学习,自动优化模型参数,修正电能计量装置运行状态判定规则,高效地锁定电能计量装置运行异常用户,准确识别电能计量装置运行的异常状况,真正意义上做到让数据说话,从而提高计量装置运行状态辨识效率[4-7]。
1 计量异常及其原因
计量异常指因某种原因引起的计量装置所计量的电能与计量点实际流过的电能量值不符,其偏差超出了计量装置原本设置的允许误差范围。引起计量异常的原因主要分为:
1)计量装置故障。
电力计量装置存在故障,属于造成电力计量装置异常运行的主要原因[8]。例如电力计量装置经常运行在低标准的环境下,或者计量装置的配置、生产质量不符合相关规定,久而久之电力计量装置将不能正常运行,常见问题主要为PT/CT参数劣化超差、二次回路断路、短路、压降过大、负载不匹配、计量仪表故障或误差超限。一旦计量装置不能正常运行,将可能造成明显的误差,因此对最终的结算造成巨大影响,还可能埋下其他安全隐患,造成不可预估的损失。
2)计量装置安装操作失误。
目前在电力企业中广泛应用的电能计量装置是由电能表、负荷管理终端、智能计量终端、集中抄表数据采集终端以及计算柜等构成[9-14]。现在电力计量装置安装的主要问题是施工人员能力不足以及欠缺责任感,这是最直接的电力计量装置施工缺陷,其中主要包括:PT/CT参数选型和安装位置不当、二次回路接线错误/连接不到位、检验后未恢复,导致电能计量装置的计量准确性受到了极大的影响。
3)计量装置被人为破坏。
几乎所有的窃电用户的目的是为了少缴甚至不缴电费,窃电行为的本质是人为破坏或者改装电力计量装置使其不能够正常运行,以此让计量的电量数据低于实际中使用的电量来降低电费[15-18]。科技的更新与发展催生了更多的窃电手段,常见的人为破坏方式是周期性、长期性、永久性地人为变造或破坏PT/CT、二次回路、计量仪表。
4)计量装置负荷异常。
特殊的用电设备其负荷存在无功、谐波、三相不平衡、越计量极限(超表额定容量50%)用电等因素,影响计量装置的计量准确性。
2 计量装置运行状态辨识及输入特征
如前所述,计量异常的主要原因有计量装置故障、计量装置安装操作失误、计量装置被人为破坏、计量装置负荷异常。计量装置运行状态辨识中,可以通过一些计量数据的表现来进行辨识,这些计量数据的客观表现决定了计量装置运行状态是正常或异常。采用什么计量数据进行计量装置运行状态辨识是此类方法的关键问题。文献[4]对采样电压和电流信号进行处理并相乘转换成与电能成正比的脉冲,以此作为计量装置运行状态辨识的输入特征。文献[5]从某省用户的用电信息记录中抽取某些用户的档案信息(用电地址、是否为专变用户)及每天电量信息,作为计量装置运行状态辨识的输入特征。文献[6]从电信息采集系统采集的数据中选取一天中不同时刻采集的分相电压、电流、功率因数,作为计量装置运行状态辨识的输入特征。本文基于抄表系统持续、在线远程读取电能表的计量数据,从以下5个方面辨识计量异常:
1)电气参量的物理关联性:检查电压、电流、功率、电量之间的逻辑及对应的电网运行方式。
2)某个电气参量的日、周、月、季的历史周期性变化规律与常规行业分类用户的生产特性的一致性。
3)比较同行业同类型生产方式下的用户用电负荷规律一致性。
4)生产运营合理性,比较同行业用户用电量与平均电价、需量利用率、容量利用率、变损率等的合理性。
5)闭环回路的计量电量平衡检查,损失电量的相关性检查。
将辨识计量异常的5个方面中的12个变量(电压、电流、功率、电量、生产特性一致性系数、周期性变化系数、同行业平均电价、需量利用率、容量利用率、变损率、电量平衡系数以及损失电量)以及对应的日、月、季度、年数据共48个维度构成输入特征。
3 基于半监督学习的计量装置运行状态辨识
图1为基于半监督学习的计量装置运行状态辨识模型构建方法。其构建方法使用了协同学习的半监督学习思想。
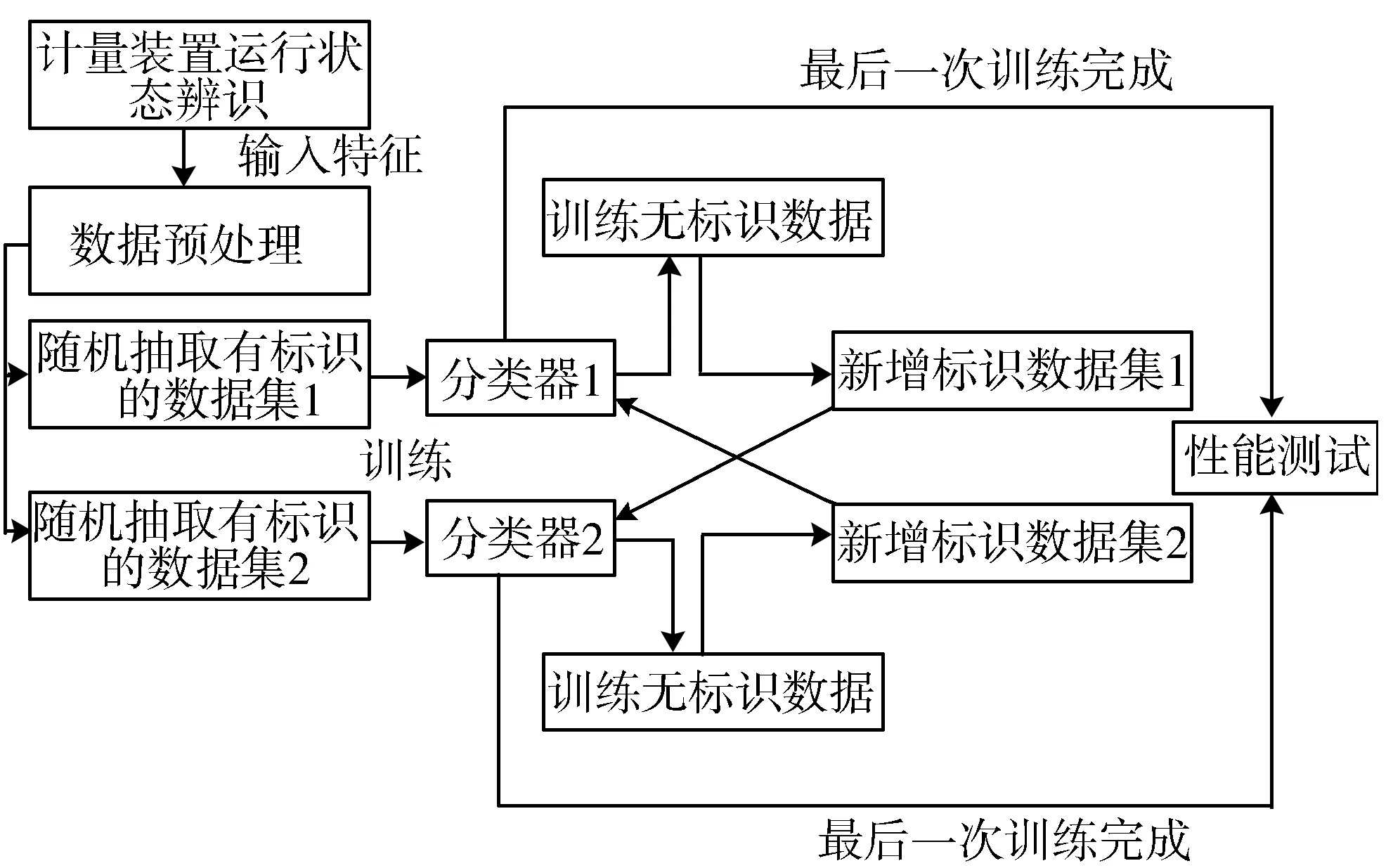
图1 计量装置运行状态辨识模型构建方法
本文采用的协同训练(Co-training)算法步骤如下:
Step1对原始数据进行预处理,将标记数据集L划分为x1和x2;
Step2从未标记数据集U中随机地选取u个示例,放入集合U′中;
Step3用L的x1部分训练出一个分类器h1;
Step4用L的x2部分训练出一个分类器h2;
Step5用h1对U′中所有元素进行标记,从中选出p个正标记和n个负标记;
Step6用h2对U′中所有元素进行标记,从中选出p个正标记和n个负标记;
Step7将上面选出的2p+2n个标记加入L中;
Step8随机从U中选取2p+2n个数据补充到U′中;
Step9重复Step3~Step8k次。
本文采用主成分分析法来做数据降维,在尽可能多地保证原始信息的情况下降低特征数量,原理[7]如下:
设x1,x2,…,xD是D维度的原始特征,记作X=(x1,x2,…,xD)T,μ=E(X)=(μ1,μ2,…,μD)T是平均值,σ=(σij)D×D=E[X-μ][X-μ]T是一个D阶半正定的协方差矩阵。
设li=(l1i,l2i,…,lDi)T,i=1,2,…,D,为D个常数向量,则有:
可得:
其中,Var(yi)是方差,Cov(yi,yj)是协方差。
以yi替代原式中D个变量x1,x2,…,xD,即期望Var(yi)尽量大,使用约束:
求l1,使Var(y1)最大。y1称为x1,x2,…,xD的第一主成分。若第一主成分y1不能表达D个变量的原始信息,使用约束:
求li,使Var(yi)最大,yi称为第i个主成分。

此外,计量装置运行状态辨识模型构建还需要依靠分类器。分类器h1和h2可以使用的技术包括:多层感知机(MLP)[19]、决策树(DT)、支持向量机(SVM)[20-21]、k最近邻法(KNN)[22]和随机森林(RFA)。
4 算例分析
将辨识计量异常的48维特征作为输入的原始信息,通过贡献率对48维原始信息降维,结果见表1。
其中分类器采用SVM,核函数为高斯核函数(RBF),即:
K(xi,xj)=exp(-γ‖xi-xj‖2),γ>0
表1 不同PCA特征子集和原始特征集的测试参数

特征集合βmCγnPCA特征子集0.8010000840.8510001670.9010016100.9510008131.0010000441原始特征———10000448
最佳模型是在训练集上进行五折交叉验证与网格搜索后产生的,参数C作为SVM的惩罚系数,C越高越不能容忍出现误差,容易过拟合,C越小,容易欠拟合,C的值为:10-1、100、101、102、103、104;γ选择RBF函数作为核后,决定了数据映射到新的特征空间后的分布,γ越大,支持向量越少,γ越小,支持向量越多,γ的值为:2-1、20、21、23、24、25。η评估平均指标的计算方法为:
表2 主成分分析测试结果

特征集合βma/%krηPCA特征子集0.8091.320.9130.9640.9300.8592.930.9220.9690.9400.9094.110.9320.9740.9490.9597.150.9510.9810.9681.0097.230.9540.9820.969原始特征———97.230.9540.9820.969
表2是主成分分析测试结果,a表示测试正确率,k表示卡巴统计量,r表示曲线下面积。从表1、表2可知,SVM在βm=1的情况下分类能力没有损失。当βm=0.95时,主成分分析将48维降成13维,减少了大量原始特征,且η只减少了0.001。所以将βm=0.95的13维主成分分析特征子集作为计量装置运行状态辨识模型输入。
本文采用周期为1年且有计量装置运行状态标识的400户数据作为分类器h1与h2的初始训练数据,周期为3年且没有计量装置运行状态标识的4000户数据作为Co-training的训练数据,周期为1年且有计量装置运行状态标识的400户数据为测试数据。以上数据均不重复。将上述13维PCA特征子集作为其他暂态稳定评估模型的输入,包括MLP、DT、KNN、RFA、SVM评估模型(Co-training使用两两组合训练共10种训练组合)。其中多层感知器使用反向传播训练模型参数,学习速率和动量因子分别为0.8和0.6;决策树使用经典的C4.5算法,在绝大多数场合其置信因子的默认值为0.25[14]。k最近邻法中k为3的初始值进行训练。这些评估模型执行2000次后的测试结果如表3所示。
表3 Co-training 10组评估模型的测试结果

评估模型训练轮数测试准确率/%MLP+DT200087.61MLP+SVM200084.25MLP+KNN200086.03MLP+RFA200071.25DT+SVM200076.55DT+KNN200081.93DT+RFA200085.62SVM+KNN200091.34SVM+RFA200096.52KNN+RFA200085.40
同样的评估模型及参数,在不使用Co-training而单独训练并测试后的分类性能如表4所示。
表4 单评估模型的测试结果

评估模型训练轮数测试准确率/%MLP200061.33RFA200069.93DT200071.40SVM200063.41KNN200061.24
从表3可观测到,利用13维整体特征在选用SVM+KNN模型时描述本文计量装置运行状态辨识特征时测试的分类性能比单个评估模型更好,说明相较单个模型,组合模型的效果性能更佳。通过对比表3和表4可知,本文提出的计量装置运行状态辨识模型在较大数据量的用电数据上分类性能较好,说明这种应用半监督学习的计量装置运行状态辨识方法可有效地辨识计量装置运行状态。
5 结束语
本文使用5种计量异常辨识方法得到原始特征数据,然后利用主成分分析法对48维的计量装置运行状态辨识原始特征进行降维。并在4800个用电用户学习测试上,利用Co-training对机器学习算法进行组队协同训练,体现了Co-training的有效性,得到如下结论:
1)综合5种计量异常辨识模型能有效地辨识计量装置的运行状态。
2)基于计量异常辨识方法的特征子集能代替原始特征有效表征计量装置的状态,有利于简化计量异常状态的复杂度。
3)综合用电用户在计量装置异常数据上的体现,Co-training半监督学习比传统单模型的监督学习更加有效。
猜你喜欢
军事文摘(2022年16期)2022-08-24
煤气与热力(2021年9期)2021-11-06
计测技术(2020年6期)2020-06-09
特别健康(2018年4期)2018-07-03
消费导刊(2017年24期)2018-01-31
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
铁道通信信号(2016年8期)2016-06-01
现代企业(2015年2期)2015-02-28
航天返回与遥感(2014年5期)2014-07-31
