
基于因果规则的电力营销系统故障定位算法
2020-03-18 03:44周开东林细君麦晓辉肖建毅曾朝霖
计算机与现代化 2020年3期
彦 逸,周开东,林细君,麦晓辉,肖建毅,曾朝霖
(广东电网有限责任公司信息中心,广东 广州 510620)
0 引 言
随着电力营销业务和用户量的增长以及集中监控系统持续推广和实用化,电力营销系统产生了大量的事件、告警以及故障数据。为了减少故障排查的工作量以及系统故障的恢复时间,节约大量的人力、物力,提高电力营销系统的稳定性,快速、准确地对故障进行定位已经变得越来越重要。
故障定位(Fault Location),又称为根因分析(Root Cause Analysis),旨在系统中出现异常的表征时,如事件、告警等,迅速准确地定位故障原因。故障定位作为工业系统重要的工作,目前已有许多关于其算法的研究[1-5],根据模型大致可以分为基于分类模型的方法和基于概率图模型的方法[6]。
基于分类模型的方法通常依赖大量的训练样本,根据训练好的模型对发生的事件预测根因。Baraldi等人[7]使用K-近邻算法(K-Nearest Neighbors, KNN)进行多层次的分类实现故障定位。Wang等人[8]在利用相对主成分分析(Relative Principle Component Analysis, RPCA)对特征进行降维的基础上使用支持向量机(Support Vector Machine,SVM)进行故障分类。Aslan等人[9]根据发生事件的不同对故障类型进行判断,进而对不同故障类型使用不同的人工神经网络(Artificial Neural Network, ANN)进行定位来提高泛化能力。上述基于分类模型的方法对于故障和事件关系变化频繁的场景具有鲁棒性,然而这些方法的缺点也非常明显:1)单纯地对数据进行拟合,没有考虑事件和故障背后的因果机制;2)模型只返回预测的根因,可解释性很差;3)分类模型的方法很难与存在的专家领域知识相结合。
相反地,基于概率图模型的方法考虑了专家知识,构建故障传播模型(Fault Propagation Model,FPM)对故障和事件的关系进行描述,在此基础上采用决策算法得出对事件做出最佳解释的故障子集。例如Gharahbagheri等人[10]使用贝叶斯网络(Bayesian Network, BN)将不同的诊断知识集成并使用后验概率进行推理定位,Bennacer等人[11]基于BN和实例推理相结合。考虑到系统中数据的时效性,一些学者采用动态贝叶斯网络(Dynamic Bayesian Network,DBN)在BN的基础上对故障和事件的关系在时间维度上也进行建模,Hu等人[12]在DBN的基础上使用前向后向算法进行故障根因推断,Cai等人[13]基于DBN对不同来源的数据分别建模并通过多源信息融合进行定位。Zhang等人[14-16]将定性模型与定量概率结合,利用动态不确定因果图(Dynamic Uncertain Causality Graph, DUCG)进行故障定位。然而基于概率图模型的方法高度依赖专家先验知识,需要事前构建故障和事件之间的因果网络。对于采用负载均衡策略的电力营销系统来说,系统会根据当前运行的服务器压力等信息进行请求的分发调度,前端服务器对后端服务器的调用关系是频繁变动的,也就是故障和事件关系是无法确定的,也就无法对此构建FPM。
因此,针对这种场景本文提出一种基于因果规则的故障定位算法,对故障数据进行因果规则挖掘并进一步计算故障根因的概率。本文算法考虑了故障和事件的因果机制,并且能够柔性地加入专家知识;同时,不需要明确故障和事件之间因果图的结构并且无需学习FPM中复杂的参数。为了验证算法的有效性,本文选择真实生产环境下的数据集进行验证,实验结果表明该算法能够快速准确定位故障根因。
1 电力营销系统的基本结构
电力营销系统是一个需要大吞吐量、高并发的Web系统,为此采用了分布式部署方案[17]以及负载均衡策略[18]。它根据业务类型拆分为营销主应用、客服应用和个性化应用,进行垂直方式的分布式部署,每种应用构成一个相对独立的子模块,根据用户发出请求的业务类型分发到相应的模块(部分来自客服和个性化的前端请求可能被分发到主应用的后端,如图1)。为了进一步提高系统的性能,不同的模块内部的前端(Web)、后端(Java)均使用多台服务器,并且每个服务器上提供多个端口为该模块的业务提供服务。数据库层(DB)是不同业务模块共用的,仍然采用多服务器多端口的形式。为了对服务器资源进行合理分配,每一个模块的入口和前端、前端和后端之间采用了负载均衡策略,对请求进行集群分发。例如,图1(图中每个服务器如Web1都包含多个端口为功能请求提供服务)中的请求通过负载均衡,有可能被分发到该模块下的任一服务器。

图1 电力营销系统的简易拓扑结构示意图
定义1分布式部署。是一种通过在不同的服务器放置不同的逻辑组件(垂直分布)或者服务器在物理上分成逻辑上等效的部分,每个部分在其自己的完整数据集的共享上操作(水平分布),达到降低维护和部署难度、提高并发量、提高访问速度的部署方案[17]。
定义2负载均衡(Load Balancing)。是一种通过将用户请求在集群之间进行合理的调度分发,达到优化资源使用、最大化吞吐量、最小化响应时间,并避免任何单个资源过载的计算机技术[18]。
即使采用了上述提高系统稳定性与可用性的架构,电力营销系统中的服务器主机或服务器的端口发生故障,依然可能会导致为用户所提供的许多相关的功能出现资源不可用等事件。如表1,系统中不同层次的服务器主机或者主机上的端口均可能发生故障。需要在观测到事件发生时,准确有效地对故障原因定位到某服务器主机或服务器上某一端口。然而,在这个复杂的系统下,由于负载均衡策略的存在,无法得知请求被分发到具体主机的具体端口,大大加大了故障定位的难度。针对上述问题的特性,本文提出一种适用于自适应学习因果规则并进行定位的方法,即基于因果规则的故障定位算法。
表1 故障类别
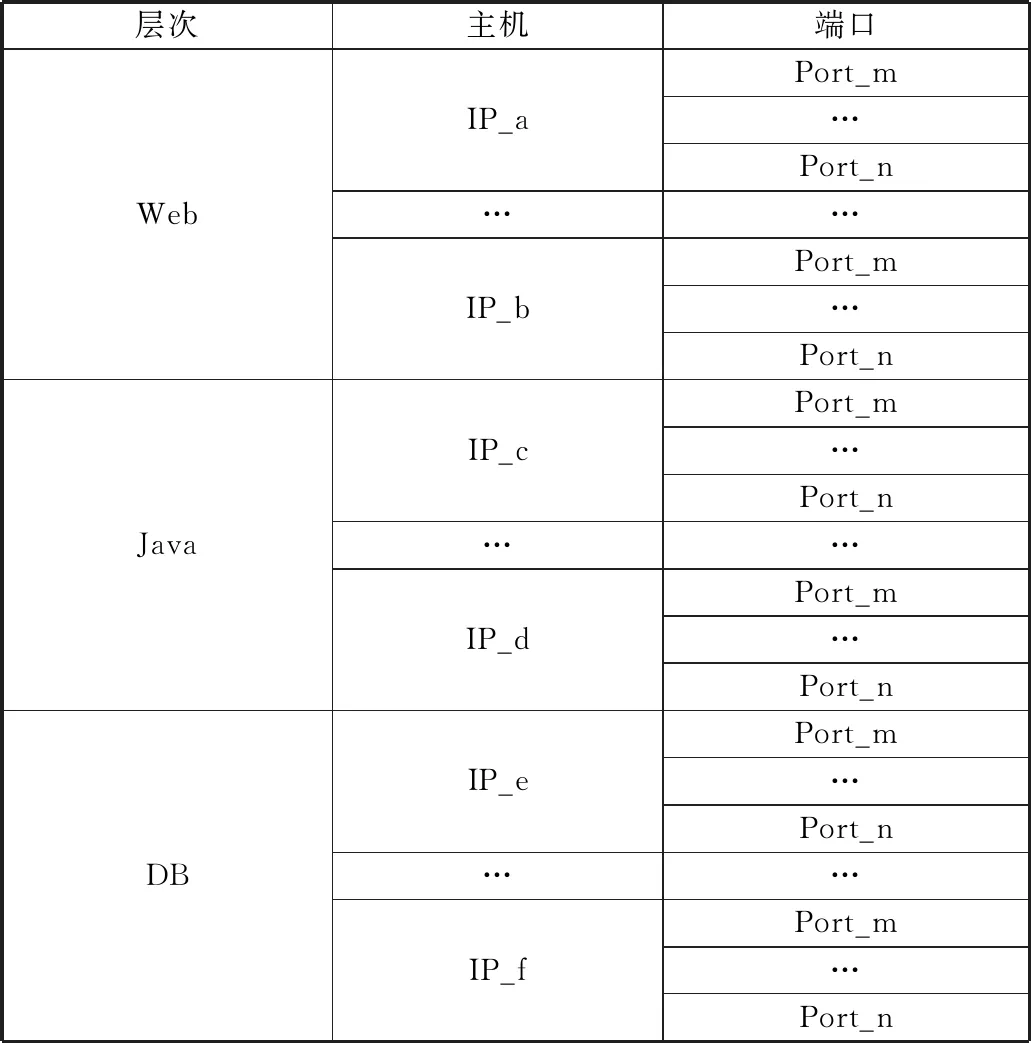
层次主机端口WebIP_a…IP_bPort_m…Port_n…Port_m…Port_nJavaIP_c…IP_dPort_m…Port_n…Port_m…Port_nDBIP_e…IP_fPort_m…Port_n…Port_m…Port_n
2 基于因果规则的故障定位算法
由于当前基于分类模型和基于概率图模型的方法无法准确有效地解决采用负载均衡、因果结构频繁变动的系统的故障定位问题,因此需要提出一种因果规则的故障定位算法。本章分2个主要阶段给出具体的细节,即如何学习因果规则和如何基于因果规则进行定位,最后给出整个算法(Causal Rules Fault Location Algorithm, CRFLA)的伪代码。
2.1 第一阶段:因果规则挖掘
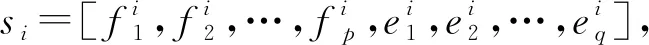
在因果关系发现中,常常对图2所示的典型的因果网络结构进行讨论。由于V-结构在统计学角度不等同于任何其他包含相同变量的结构,与其他马尔科夫等价类结构相比,V-结构在因果关系识别问题上更具有鲁棒性和可识别性[19]。事件和故障之间存在图2(b)的V-结构说明故障变量f1和f2共同影响事件变量y。因此,可以通过发现事件和故障之间存在的V-结构对事件发生的因果规则进行挖掘。基于V-结构的独立性性质,可以使用式(1)的因果关联兴趣度度量(Causal Association Interesting Measure, CAIM)[20]规则Ij1Ij2→Ee的可能性。

(a) 马尔科夫等价类
CAIM(Ij1Ij2→Ee)=N(f1,y)+N(f2,y)-
N(f1,f2)+N(f1,f2|y)
(1)
其中,N(f1,y)为f1和y的归一化互信息[21]。
对于先导变量只有一个的因果规则Ij1→Ee,CAIM计算如式(2):
CAIM(Ij1→Ee)=N(f1,y)
(2)
对于更加普遍的先导变量数大于等于3的因果规则I→Ee,其必定包含若干个子规则Ij1Ij2→Ee和Ij1→Ee,并且其兴趣度取决于最劣子规则。因此进一步得到对规则I→E的广义的兴趣度度量,如式(3)。
(3)
基于CAIM进行因果规则挖掘,可以得到每个事件e发生时可能的故障-事件规则集合Re。同时,在进行因果规则挖掘的搜索过程中,可以灵活地结合专家先验知识进行剪枝。为了进一步对系统进行根因定位,在下一节提出如何利用因果规则集合进行推断。
2.2 第二阶段:基于因果规则推断
上述得到的所有因果规则的先导变量的集合即为导致事件发生的可能原因的候选集,定义为I。接下来,将给出如何利用因果规则进行根因发现。笔者发现在系统中某个故障的发生常常导致许多相关事件发生,一些事件可能同时受到相同的原因节点影响,例如某数据库主机发生故障可能导致系统中许多功能无法使用。因此,认为若某个故障原因集I0在某段时间内,导致最多事件发生的即为根因C。根据故障原因集对发生事件集的影响程度,定义故障原因集I0是根因的可能性h(I0)的计算方式,如式(4):
(4)
其中,1为指示函数,表示规则集合Re0中是否存在I0→Ee0或者样本si是否包含I0和e0。ε0为某段时间内发生的所有事件集合,e0为其中发生的某个事件。
由此,进一步定义根故障原因集I0是根因的概率p(I0)以及事件的根因C,如式(5)和式(6):
(5)
(6)
因此,在第一阶段得到所有事件对应的故障原因集合R的基础上,使用式(4)~式(6)对原因进行评估并推断得到根因。
2.3 CRFLA伪代码
首先给出基本的流程。第一阶段:对于不同的事件e,其可能的故障原因I有多种,而每种故障原因I可能包含多个故障,共同影响事件e。于是,对每个事件的可能原因I进行增量式搜索。根据式(1)、式(2)和式(3)判断集合I中的所有故障是否同时是某个事件的原因节点,若是那么I有可能导致事件e,那么将规则加入可能的因果规则集Re,进而得到所有的因果规则集合R。另外,在对每个事件的原因进行搜索时,能够结合专家先验知识进行剪枝,如下的prior_rule_filter方法将与事件e无关的故障预先进行剔除。第二阶段:上一阶段得到R,其所有规则的先导I0的集合即为故障根因的候选集。因此,根据R和样本集S判断每个规则在该段时间内是否发生,使用式(4)和式(5)计算得到每个原因作为根因的概率,概率最大的原因集合即为根因。
详细伪代码如下:

算法 CRFLA输入:事件集ε,故障集F;可观测的事件-故障样本集S与待定位的事件发生集ε0={e1,e2,…,en};最小的CAIM阈值c;输出:故障根因集C;初始化:R=∅,C=∅;//第一阶段FOR each e in εRe=∅Fe=prior_rule_filter(e,F)FOR each item F in FeIF CAIM(F→Ee)⩾cR'=Re∪{F→Ee}ELSECONTINUEEND IF

FOR each rule I→Ee in ReNew Rule r=I∪{F}→EeIF CAIM(r)⩾cR'=R'∪{r}END IFEND FORRe=R'END FORR=R∪ReEND FOR//第二阶段FOR each e0 in ε0FOR each rule I0→Ee0 in Re0FOR each si in SIF I0→Ee0 NOT occurs in siCONTINUEELSE IF Count(I0→Ee0) EXISTCount(I0→Ee0)=Count(I0→Ee0)+1ELSE//初始化Count(I0→Ee0)=1END IFEND FOREND FOREND FORFOR each itemset I0 in Rh(I0)=Count(I0→Ee0)|ε0|END FORFOR each itemset I0 in Rp(I0)=h(I0)∑Il∈Ih(Il)END FORC=arg max I0∈R p(I0)返回:事件集ε0的故障根因集C
3 实验分析
为了评估本文提出的CRFLA算法的有效性,挑选了广东电网的电力营销系统中真实生产环境产生的事件和故障数据,采样频率为5 min/次,区间为2018年11月27日至2018年12月27日的间歇性故障[22]。实验环境:处理器为Xeon E5-2620 v4,内存64 GB,Linux 64位操作系统的Python语言。
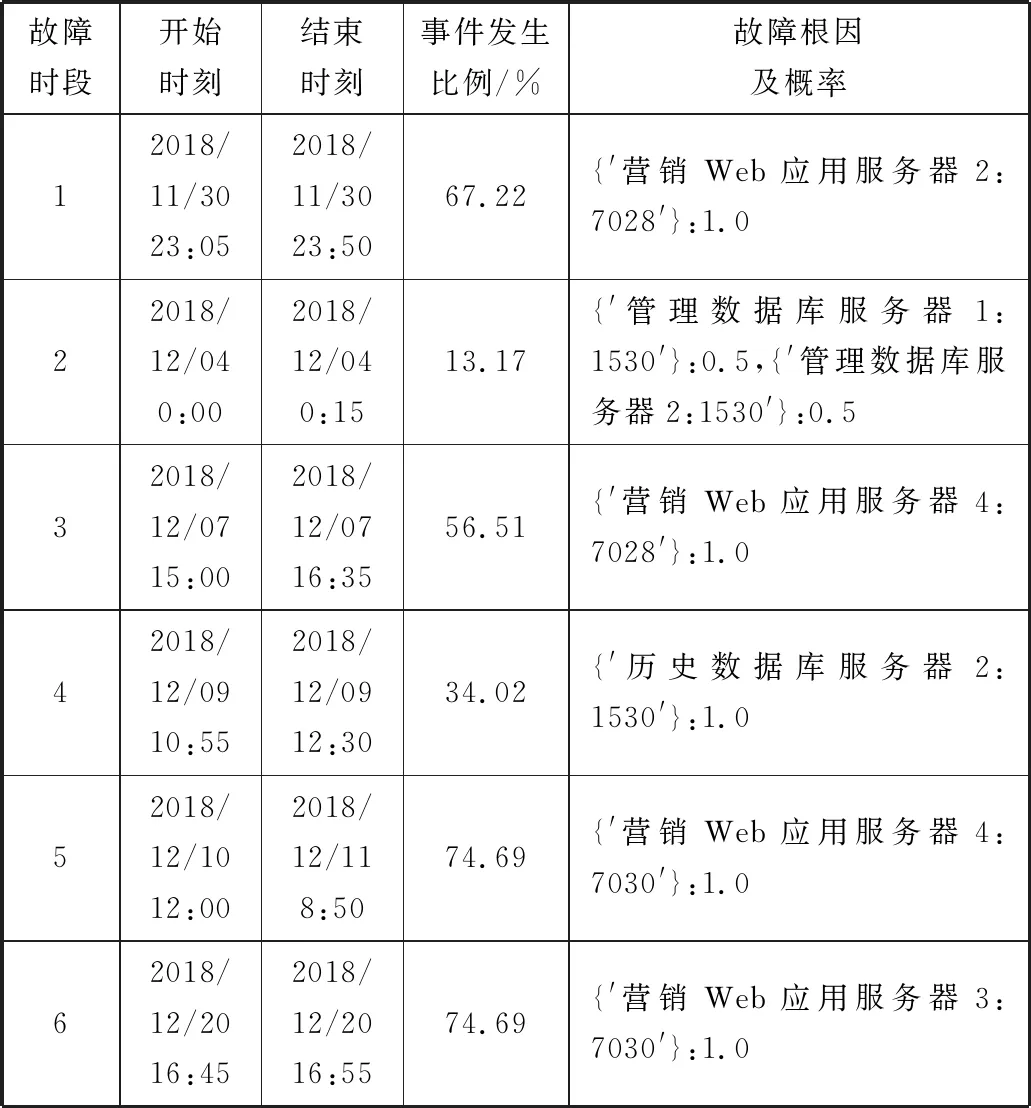
本实验中将CAIM阈值设为0.1,表2展示了CRFLA在本数据集上故障根因定位的结果。
表2 故障根因定位结果
故障时段开始时刻结束时刻事件发生比例/%故障根因及概率12018/11/3023:052018/11/3023:5067.22{'营销Web应用服务器2:7028'}:1.022018/12/040:002018/12/040:1513.17{'管理数据库服务器1:1530'}:0.5,{'管理数据库服务器2:1530'}:0.532018/12/0715:002018/12/0716:3556.51{'营销Web应用服务器4:7028'}:1.042018/12/0910:552018/12/0912:3034.02{'历史数据库服务器2:1530'}:1.052018/12/1012:002018/12/118:5074.69{'营销Web应用服务器4:7030'}:1.062018/12/2016:452018/12/2016:5574.69{'营销Web应用服务器3:7030'}:1.0
从表2结果可以看出,在不同时间段能准确地定位到服务器端口,并且得到的根因概率基本为1。例如,在2018/11/30 23:05至2018/11/30 23:50这段时间内,故障持续了45 min,平均有486个功能菜单无法正常使用,该故障导致了67.22%的功能不可用。CRFLA算法第一阶段通过因果规则挖掘得到:每个事件{′营销Web应用服务器2:7028′}→εe这一因果规则,这说明这段时间内每个事件的发生可能原因只有一个;第二阶段根据式(4)和式(5)计算得到{′营销Web应用服务器2:7028′}为根因的概率是1.0。
为了验证算法的正确性,实验结果交由运维工程师验证。同时,为了进行定量的对比实验,根据真实的故障原因集Ct,定义故障定位的准确率计算方式如式(7):
(7)
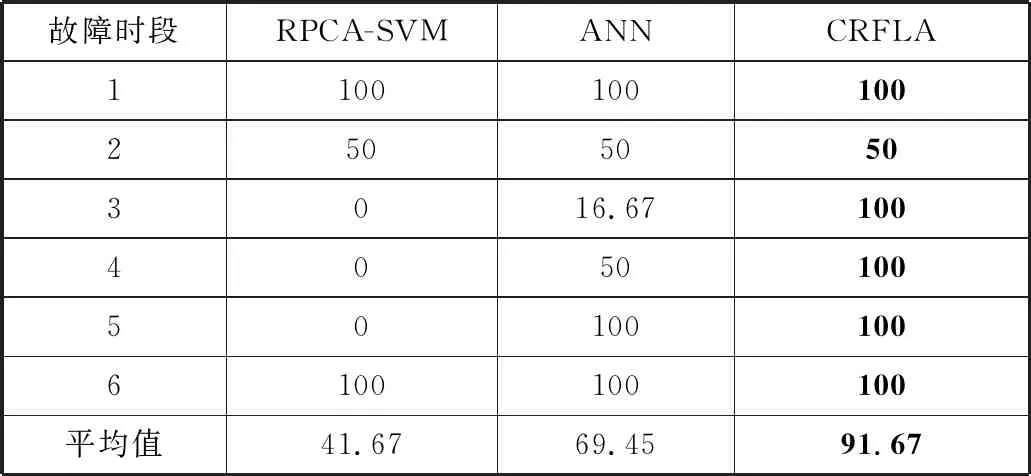
由于基于概率图模型的方法在因果关系频繁变动的系统下无法进行构图,因此与基于分类模型的方法RPCA-SVM[8]和ANN[9]进行对比实验,准确率结果如表3所示。
从表3中可以看到,CRFLA除了故障时段2,故障定位结果都得到了100%的准确率,在每个时间段的定位中均得到了最高的准确率。在本数据集中,CRFLA平均准确率为91.67%,和RPCA-SVM的41.67%以及ANN的69.45%相比,具有较大的提升。实验结果表明,CRFLA取得了最佳的效果,能够迅速、准确地定位故障根因。
表3 故障根因定位准确率/%
故障时段RPCA-SVMANNCRFLA110010010025050503016.671004050100501001006100100100平均值41.6769.4591.67
表4 不同故障类别的根因定位平均准确率/%

故障类别WebJavaDB平均准确率100-75
为了评估不同类别的故障定位准确率,进一步计算表1中3个层次的故障定位的平均准确率,结果如表4所示。根据电力营销系统的拓扑结构可知,上述3种类别的故障发生具有传递关系。Web类型的故障更加直接地导致事件发生,而Java和DB则具有更加复杂的关系。因此,可以得到Web类型的故障更容易进行定位,其准确率最高,达到100%,DB次之(注意,表4中,由于Java类别的故障在该数据中恰好没有发生,故用“-”表示)。
4 结束语
本文提出了一种基于因果规则的故障定位算法CRFLA,该方法能够解决负载均衡带来的故障因果关系频繁变动的复杂系统的故障定位问题,有效避免了根因无法解释和专家先验知识匮乏无法提前构建因果网络的问题,在考虑故障与事件的因果关系的同时可以灵活地结合专家先验知识。将算法应用在广东电网的电力营销系统的真实数据上,实验结果表明本文方法能够实现准确、高效的故障定位。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2019年8期)2019-08-28
中国交通信息化(2018年5期)2018-08-21
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
