
基于机器学习结合植被指数阈值的水稻关键生育期识别
2020-03-17 08:50:20杨振忠方圣辉
中国农业大学学报 2020年1期
杨振忠 方圣辉 彭 漪 龚 龑 王 东
(武汉大学 遥感信息工程学院,武汉 430079)
精准农业和智慧农业是农业发展的重要方向,农作物物候期识别是精准农业和智慧农业的重要应用[1]。它不仅可以帮助农田管理者及时规划田间管理活动(如灌溉和施肥等),还可以为作物长势评估及估产提供重要的时间参考[2-3],此外,长时间的物候期识别还可以从侧面反映出环境变化的规律[4]。
水稻是我国的主要粮食作物之一,水稻的生育期监测是根据水稻生育过程中的形态变化,对各生长发育时期进行记载的过程,反映了水稻的生长状态信息。根据水稻移栽之后在田间的生长形态,水稻生育期分为分蘖期、拔节孕穗期、抽穗扬花期和灌浆成熟期。其中,分蘖期主要以生长根、叶和分蘖等营养器官为主,是水稻一生中根系生长最旺盛和大量发展的时期;拔节孕穗期是水稻由营养生长转化为生殖生长的过程;抽穗扬花期是指水稻完全发育的幼穗从剑叶鞘内伸出,然后开花授粉受精的过程;灌浆成熟期是指稻穗谷粒开始营养物质的积累,谷粒逐渐变硬,壳色由绿变黄的过程。
传统的作物生育期观测方法以野外实地观察为主,直接在野外对个体或群体生育期进行观测,这种方法具有客观准确的特点;但是,该方法费时费力,无法满足实时、快速的监测需求。遥感近实时、大面积和快速无损的优势为农作物物候期识别提供了新的技术手段。基于遥感监测农作物的生育期,国内外学者做了大量的研究,常见的方法主要有以下几种:1)植被指数阈值法,设定植被指数阈值作为生育期的节点,宋春桥等[5]利用动态阈值法提取了藏北高原过去10年间的植被物候信息;2)折点法,将滤波后的时序植被指数曲线的极值点或折点作为生育期节点,Sakamoto等[6]利用增强型植被指数的折点识别水稻的分蘖前期、抽穗期和收割期;3)求导法,对时序植被指数曲线求一阶导或二阶导,将一阶导或二阶导的极值点或折点作为生育期节点,孙华生等[7]利用增强型植被指数通过转折点的方法识别水稻的移栽器和抽穗期,采用植被指数的相对变化阈值法判断分蘖初期,采用最大变化斜率法识别成熟期;4)机器学习法,机器学习具有自主学习训练、泛化能力强的特点,Almeida等[8]利用机器学习的分类算法,基于草原植被叶片的数字图像检测物候。
植被指数阈值法虽然计算准确,但是阈值存在适用性较差的缺陷;而折点法、求导法都是基于时序植被指数曲线实现的,主要存在2个缺陷:一是时间分辨率较低的数据通过插值的方法构建时间序列,无疑带来一定的误差;二是需要时序数据才能对生育期进行划分,不能满足实时监测的要求。
机器学习近年来被广泛应用到分类问题中,也逐渐被用于农作物生育期识别。单一学习器算法包括K近邻(KNN)[9]、决策树[10]和支持向量机(SVM)[11],集成学习算法包括随机森林(RF)[12]和梯度提升决策树(Gradient boosted decision trees, GBDT)[13]。基于以上分析,本研究首先以四波段辐射计获取水稻每日冠层反射率为数据源,开展基于K近邻、决策树、支持向量机、随机森林和梯度提升决策树共5种机器学习方法的水稻生育期识别研究;然后将其推广至无人机影像,评价模型的泛化能力,进而通过植被指数阈值的方法完善模型。本研究旨在通过地面高时间分辨率的光谱数据对水稻生育期的精准划分,推广应用至无人机数据,以期获得不依赖时序数据针对不同平台的水稻生育期识别模型。
1 研究区与数据
1.1 研究区
研究区位于海南省陵水黎族自治县文官村(110°03′35″E,18°31′47″N),如图1,为武汉大学陵水多品种杂交水稻实验基地中的部分试验田。于2018年1月12日在试验田不同小区移栽了不同品种水稻,小区面积约30 m2,行列间距40 cm,移栽密度为30万株/hm2,于2018年4月30日收割,水稻品种为珞优9348、丰两优4号。
1.2 数据获取
试验数据包括由四波段辐射计SKYE(SKR 1860, SKYE Instruments Ltd, Llandrindod Wells, UK)获取的时序的水稻冠层多光谱反射率、由无人机(Unmanned aerial vehicle,UAV)搭载的多光谱相机获取的水稻冠层多光谱影像,以及地面实地的水稻生育期观测记录。其中,SKYE数据用于水稻生育期识别的机器学习模型研究,UAV数据作为测试集,用于评估模型的泛化能力,实地生育期观测记录包括分蘖期、拔节孕穗期、抽穗扬花期和灌浆成熟期的实际观测日期,作为模型训练和精度评价的标签。
图1 研究区域地理位置
Fig.1 Geographical location of the study area
1.2.1SKYE四波段光谱数据
SKYE辐射计有上下2个,每个辐射计测量的4个光谱波段范围是绿(530.6~569.2 nm)、红(636.9~672.9 nm)、红边(705.8~729.6 nm)和近红外(850.9~880.5 nm)。上方的辐射计镜头带有余弦矫正器,能够接收镜头上方180°半球的太阳光,对应测量太阳光在4个波段的下行辐照度。下面的辐射计镜头测量25°视角的上行辐照度,也就是植被的反射信息。共有3台SKYE仪器,分别架设在试验田的不同小区,其中2台SKYE分别观测珞优9348的2个施氮肥水平:120 kg/hm2(N120)和240 kg/hm2(N240),另一台SKYE观测丰两优4号的一个施氮肥水平:120 kg/hm2(N120)。每台SKYE架设高度约距离地面3 m,同时镜头指向南方向,保证在测量过程中不受支撑架和太阳能电池板的阴影干扰。3台SKYE共采集了珞优9348(N120和N240)和丰两优4号(N120)自1月13日—4月30日共108 d的水稻冠层光谱数据。
SKYE仪器配置安装了太阳能电池板和蓄电池,能够采集每一秒的数据,为了消除数据中由于辐照度快速变化和辐射计受污染物(鸟等)影响导致的扰动,4个光谱波段的辐射计响应设计为取30 min内的平均值,设置为每天7:30—18:30分观测记录数据。波段i为30 min内的反射率平均值,ρi为下方辐射计测量的上行的30 min辐亮度[RUW(λ)]和上方辐射计测量的下行的30 min辐照度[IDW(λ)]比值,计算式如式(1)。
ρi=[RUW(λ)×CCUW(λ)]/[IDW(λ)×CCDW(λ)]
(1)
式中:CCUW(λ)是在λ波段对于UW(mV)的校准系数,CCDW(λ)是对于DW(mV)的校准系数。
1.2.2UAV多光谱数据
本研究使用大疆创新科技有限公司生产的八旋翼无人机,搭载由12个微型相机组成的MCA相机(MCA12, Terracam Inc., Chatsworth, CA, USA)。相机的中心波长分别为800、490、520、550、570、670、680、700、720、850、900和950 nm,前10个波段每个波段的波段宽度均为10 nm,900 nm波段的波段宽度为20 nm,950 nm波段的波段宽度为40 nm。对MCA相机的镜头进行几何校正,使得12个波段的多光谱影像位于同一坐标系,并消除影像的镜头畸变。利用地面标准反射板,采用线性模型对影像进行辐射定标,将影像的像元亮度值(Digital number,DN值)转化成反射率[14]。在海南水稻试验田获取水稻在分蘖期(2018年2月2、7和20日)、拔节孕穗期(2018年3月3、18和25日)、抽穗期(2018年4月1日)和成熟期(2018年4月15和26日)的无人机多光谱影像,利用ENVI软件在影像上对每块小区避开边缘随机采集2个感兴趣区域(Region of Interest,ROI),取每个ROI分别在550、670、720和850 nm的光谱均值作为模型的测试数据集,共计480条光谱数据。
1.3 预处理
SKYE辐射计观测记录了每天7:30—18:30的数据。当太阳的天顶角>70°时,由于更高的镜面反射率对二向反射系数的贡献,4个波段的冠层反射率会剧烈的变化,影响反射率的计算,因此需要选择合适时间段的稳定的光谱反射率数据。按照SKYE数据预处理的惯用方法[15],统计发现冠层反射率在10:30—12:00 趋于稳定,因此,选择每天10:30—12:00 的反射率作为4个波段冠层反射率的有效数据。在此基础上,剔除仪器波动异常严重的数据,获得用于机器学习建模的SKYE数据。在水稻完整的生育期内,不同生育期持续天数差别较大,所以不同生育期内的数据量不同,全生育期共 1 200 条光谱数据。
2 方 法
试验整体设计方案如图2所示,SKYE仪器只能监测获取一块田区的光谱,但是具有高时间分辨率的特点,适合进行生育期识别建模试验,所以首先通过常见的5种机器学习算法对SKYE数据进行建模,对比分析5种算法模型的精度表现;而无人机拍摄多光谱影像具有范围大,可输出影像展示的优势,适合模型推广应用,所以进一步将SKYE数据建立的水稻生育期识别模型应用至UAV数据,评价模型算法对UAV数据适用性,如果适用性较差,在机器学习算法的基础上,通过植被指数阈值的方法对容易混淆的生育期进行区分,最终获得适用于UAV数据的水稻生育期识别模型。
试验取SKYE每天10:30—12:00的各个波段的反射率中值作为当天的水稻冠层光谱反射率,根据实地生育期观测的记录进行不同时期的划分,得到SKYE获取的珞优9348(N240)水稻从分蘖期至灌浆成熟期间4个波段的每日反射率(图3)。另外2个SKYE获取的珞优9348(N120)和丰两优4号(N120)的冠层反射率和变化趋势与图3接近。冠层反射率随日期的变化反映出水稻不同生育期的特征。

图2 水稻生育期识别研究试验方案
Fig.2 Experimental plan of rice growth stage recognition

图3 水稻生育期内每天反射率和冠层变化
Fig.3 Daily reflectance and canopy changes during the whole growing stage of rice
水稻在分蘖期初期时,秧苗小,冠层光谱特征与水接近,4个波段的反射率都较低,随着水稻不断分蘖,植株高,叶片增多增大,叶绿素和叶面积指数增加,光谱特征渐渐与植被更加接近,近红外波段反射率不断增加,红边波段反射率变化不大,绿波段和红波段反射率在逐渐下降;在拔节孕穗期阶段,水稻拔节长高,植株增大,冠层更加茂密,所以近红外波段反射率略有升高,当水稻进入幼穗分化阶段,从营养生长阶段过渡到生殖生长阶段,水稻叶片大小不会再有明显变化,近红外波段反射率略有下降,其他3个波段没有明显变化;水稻进入抽穗扬花期时,绿色的稻穗从剑叶的叶鞘中抽出,水稻冠层结构发生变化,对冠层结构比较敏感的红边波段反射率逐渐上升,绿波段和红波段的反射率也有微弱的升高;水稻在抽穗扬花期经过授粉受精过程后,进入灌浆成熟期,稻穗逐渐成熟,逐渐向下弯曲,颜色由绿变黄,部分品种的水稻叶片也会变黄,近红外波段反射率明显下降,稻穗向下弯曲导致冠层结构明显变化,所以红边波段反射率呈现上升趋势,绿波段和红波段的反射率都略微升高。水稻在不同生育期内4个波段的光谱反射率变化明显,因此利用水稻生育期内4个波段的光谱反射率数据作为学习数据,探究利用机器学习方法识别水稻生育期的可行性。
基于KNN算法的分类是一种基于实例的学习,它不试图构建一个通用的内部模型,而是简单地存储培训数据的实例。KNN实际上利用训练数据集对特征向量空间进行划分,分类是由距离每个点最近的K个点的种类简单多数投票计算出来的,也就是一个查询点被分配到数据类中,这个类在最近的邻居中拥有最多的代表。
分类决策树模型是一种描述对实例进行分类的树形结构。其本质上是从训练数据集中归纳出一组分类规则,学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。递归结束的条件是直至所有训练数据子集被基本正确分类或者没有合适的特征为止。
SVM的基本模型是定义在特征空间上的间隔最大的线性分割器,支持向量机还包括核技巧,这使它成为实质上的非线性分类器,常见的核函数有多项式核函数(Polynomial kernel function)和径向基核函数(Radial basis function, RBF)等。
随机森林是在以决策树为基学习器的基础上构建的集成学习器,每个基学习器的训练数据集是在总的训练数据集中采样获得的,获得若干个训练数据子集,就对应得到数量相等的基学习器。此外,在决策树的训练过程中引入了随机属性选择,当在树的构造过程中分割一个节点时,所选择的分割不再是所有特性中最好的分割,而是特性的随机子集中的最佳分割。随机森林简单容易实现,计算开销小,被誉为“代表集成学习技术水平的方法[16]。
GBDT是一种常见的Boosting算法。算法每次迭代都是在之前模型损失函数的梯度下降方向去建立新的决策树模型,同时一步一步地修复残差而靠近最优的模型,最后对弱分类器进行组合得到最终的模型,具有较好的泛化误差。
将SKYE数据分为训练集和验证集,UAV数据作为测试集,基于K近邻、决策树、支持向量机、随机森林和梯度提升决策树5种机器学习算法,通过10折交叉验证在训练集中学习、在验证集进行最优参数的选择,通过测试集评估模型的泛化能力。如果模型对于测试集的精度较好,说明模型的泛化能力较好,能够适用于UAV数据;如果精度较差,统计UAV数据在水稻各个生育期的植被指数的差异,在SKYE数据建立的机器学习水稻生育期识别模型的基础上,通过植被指数阈值的方法区分在UAV数据识别过程中容易混淆的生育期。
试验中使用的常见的4种植被指数包括归一化差值植被指数(Normalized difference vegetation index,NDVI)、绿波段归一化植被指数(Normalized difference vegetation index green,NDVIgreen)[17]、归一化差值红边指数(Normalized difference red edge index, NDRE)[18]和可见光大气修正指数(Visible atmospherically resistant index,VARI)[19],4种植被指数的计算方法见式(2)~(5)。
NDVI=(ρNIR-ρred)/(ρNIR+ρred)
(2)
NDVIgreen=(ρNIR-ρgreen)/(ρNIR+ρgreen)
(3)
NDRE=(ρrededge-ρred)/(ρrededge+ρred)
(4)
VARI=(ρgreen-ρred)/(ρgreen+ρred)
(5)
式中:ρNIR,ρred,ρgreen,ρrededge分别表示近红外波段、红波段、绿波段和红边波段的光谱反射率。
3 结果与讨论
3.1 基于SKYE反射率的生育期识别模型
基于SKYE数据通过10折交叉验证利用KNN、决策树、SVM、RF和GBDT共5种算法进行学习训练,在最优参数下,各个算法训练结果见表1,几种算法的水稻生育期识别精度比较接近,其中RF算法和GBDT算法识别水稻生育期精度最高,分别为93.00%和92.25%,决策树算法的精度最低,为90.42%,把简单的决策树算法作为基学习器,通过集成学习,RF和GBDT算法的识别精度都得到了提升。

表1 基于SKYE数据的不同算法识别水稻生育期Table 1 Accuracy for recognizing rice growing stage using different classifier model and SKYE data
RF算法识别水稻生育期模型的混淆矩阵见表2,对水稻每个生育期的识别精度均超过70%,试验建立的水稻生育期识别模型对分蘖期、拔节孕穗期和灌浆成熟期的识别精度较高,而对抽穗扬花期的识别精度偏低。拔节孕穗期和抽穗扬花期互相错分的情况偏多,这主要是因为在抽穗过程是水稻稻穗从剑叶叶鞘中逐渐抽出,试验中实地观察以田间水稻10%抽出稻穗作为抽穗期开始,而刚刚抽出的绿色稻穗对水稻冠层光谱的影响较小,从而水稻在抽穗扬花期初期的冠层光谱与抽穗扬花期之前的冠层光谱相比没有明显变化,这一现象从图4也可以看出,所以这2个时期混淆的情况较多,区分这2个生育期的主要特征波段为红边波段,红边波段对冠层结构比较敏感,在稻穗抽出后红边波段的反射率有逐渐增加的趋势。原理较为简单的KNN算法识别水稻生育期的精度表现同样较好,其混淆矩阵见表3,与表2中展现出的拔节孕穗期和抽穗扬花期更容易互相错分的情况一致。

表2 基于SKYE数据的RF水稻生育期识别混淆矩阵Table 2 Confusion matrix of rice growing stage recognition using SKYE data and RF algorithm
3.2 模型应用至无人机数据的适用性评价与模型完善
SKYE光谱数据具有时间分辨率高的特点,建立的生育期识别模型能够精准的划分水稻的生育期,但是相比于地面平台采集数据,无人机获取数据具有范围大、方便省时、可输出影像展示的优点,所以有必要将全部SKYE数据建立的水稻生育期识别机器学习模型推广至UAV数据,评估模型的泛化能力,获得能够适用于UAV数据的水稻生育期识别模型。本研究利用以上算法模型对SKYE全部数据进行训练,然后利用UAV数据进行测试,不同算法的精度如表4所示。试验结果表明SVM算法的精度最差,对于无人机平台数据适用性较差,而KNN算法的表现仍旧较好,精度达到了83.54%,优于其他的几个算法的表现。通过全部SKYE数据建立的KNN模型对UAV数据识别的混淆矩阵见表5。结果表明,模型对水稻分蘖期和灌浆成熟期的识别准确率非常高,没有出现混淆的情况,而把抽穗扬花期大部分的数据错误地识别为拔节孕穗期。其主要原因有2点:一是水稻抽穗扬花期的冠层光谱与拔节孕穗期相似,不容易区分;另一个原因是2种仪器的传感器观测原理不同,同时无人机搭载的多光谱相机的波段范围和中心波长与SKYE的也不完全一致,所以UAV端的光谱数据与SKYE的光谱数据存在差异。同时,GBDT算法对UAV数据的识别精度也较高,其生育期识别混淆矩阵见表6,错误识别的情况相对KNN算法较为复杂,不能依靠单一植被指数进行区分。
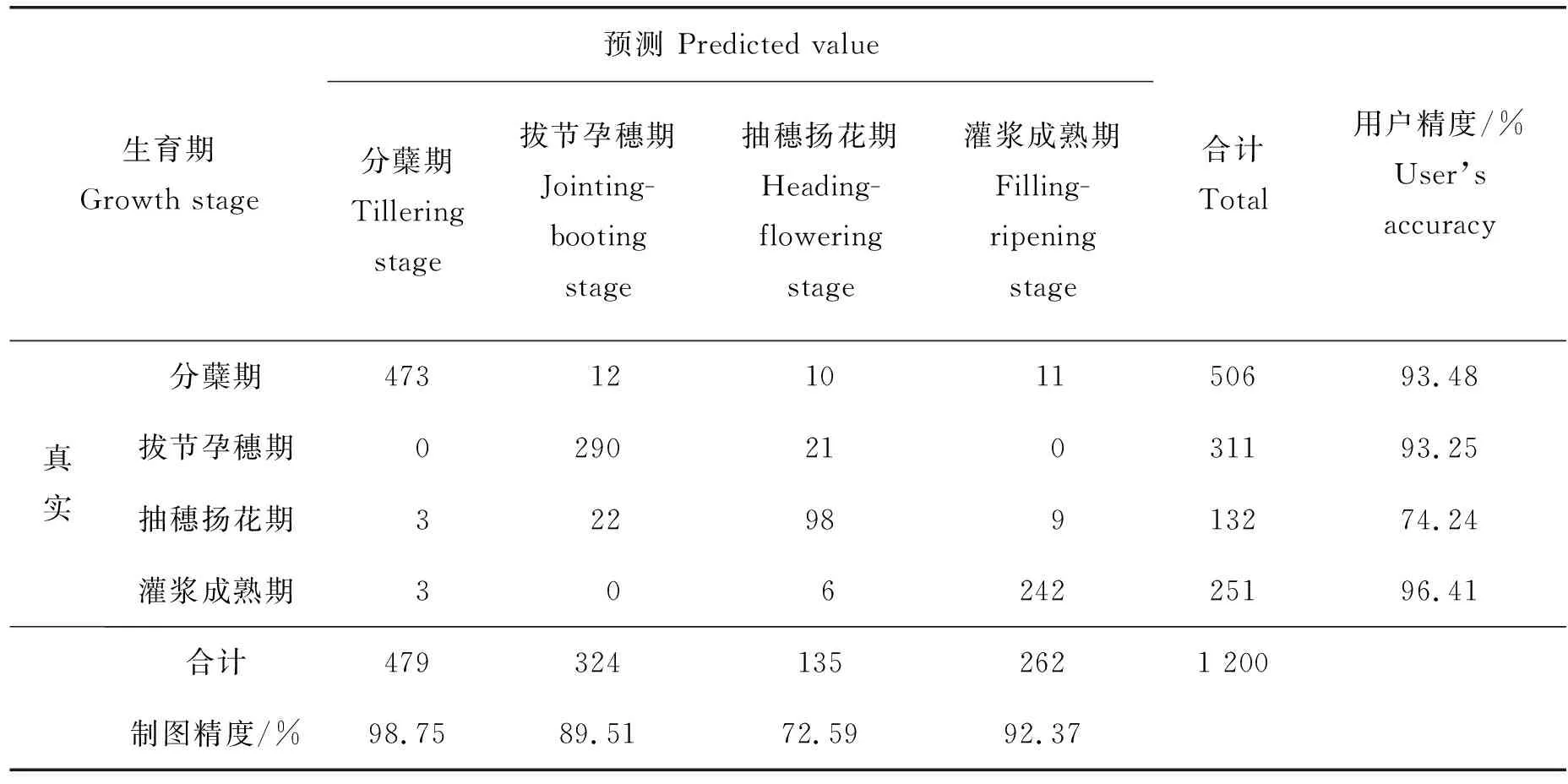
表3 基于SKYE数据的KNN水稻生育期识别混淆矩阵Table 3 Confusion matrix of rice growing stage recognition using SKYE data and KNN algorithm

表4 基于UAV数据的不同算法水稻生育期识别Table 4 Accuracy for recognizing rice growing stage using different model and aerial-collected data

表5 基于UAV数据的KNN水稻生育期识别混淆矩阵Table 5 Confusion matrix of KNN algorithm recognizing rice growing stage using aerial-collected data
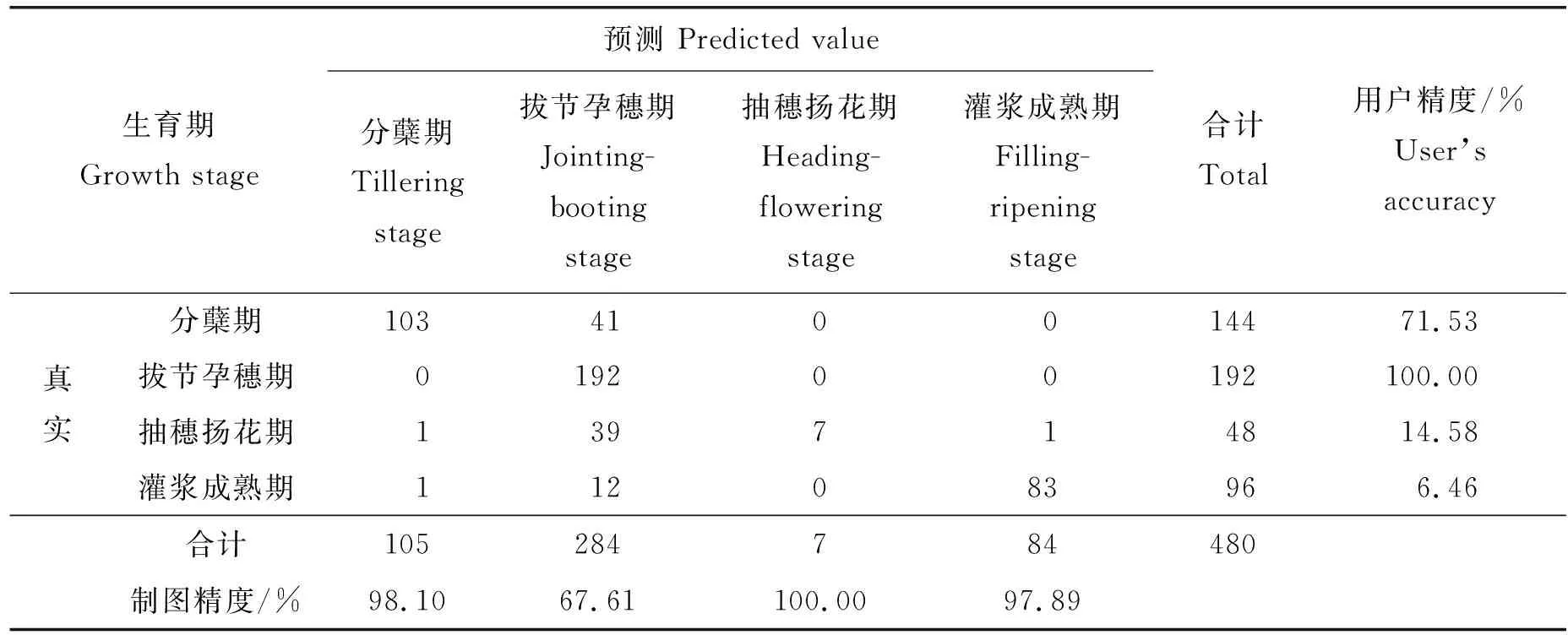
表6 基于UAV数据的GBDT水稻生育期识别混淆矩阵Table 6 Confusion matrix of GBDT algorithm recognizing rice growing stage using aerial-collected data
虽然水稻在拔节孕穗期和抽穗扬花期的冠层光谱特征较为相似,但是在数值上还是存在差别,在抽穗扬花期,绿波段、红波段和红边波段的冠层反射率逐渐升高。统计UAV数据中水稻在拔节孕穗期和抽穗扬花器的各个指数数值的频率分布,如图4所示,结果表明VARI的频率分布在2个时期具有较好的区分,在水稻的拔节孕穗期有超过90%的VARI>0.73,同时水稻在抽穗扬花期有超过70%的VARI<0.73,于是选定VARI=0.73作为区分水稻拔节孕穗期和抽穗扬花期的阈值,当VARI≥0.73时,认为水稻处于拔节孕穗期;当VARI<0.73时,认为水稻处于抽穗扬花期。
图4 水稻4种植被指数在2个生育期的频率分布图
Fig.4 Frequency distribution of rice four kinds of vegetation index in two growing stages
结合了植被指数VARI的KNN算法对UAV数据的水稻生育期识别混淆矩阵见表7,对比表5发现对水稻抽穗扬花期的识别更加准确,大幅度提高了抽穗扬花期识别的用户精度,但是使用阈值方法使得拔节孕穗期被错误的识别为抽穗扬花期的数据少量的增加,整体来看,KNN算法结合VARI对UAV数据的识别精度达到了86.04%。相比于单独使用KNN算法对各个生育期的识别精度更加均衡。
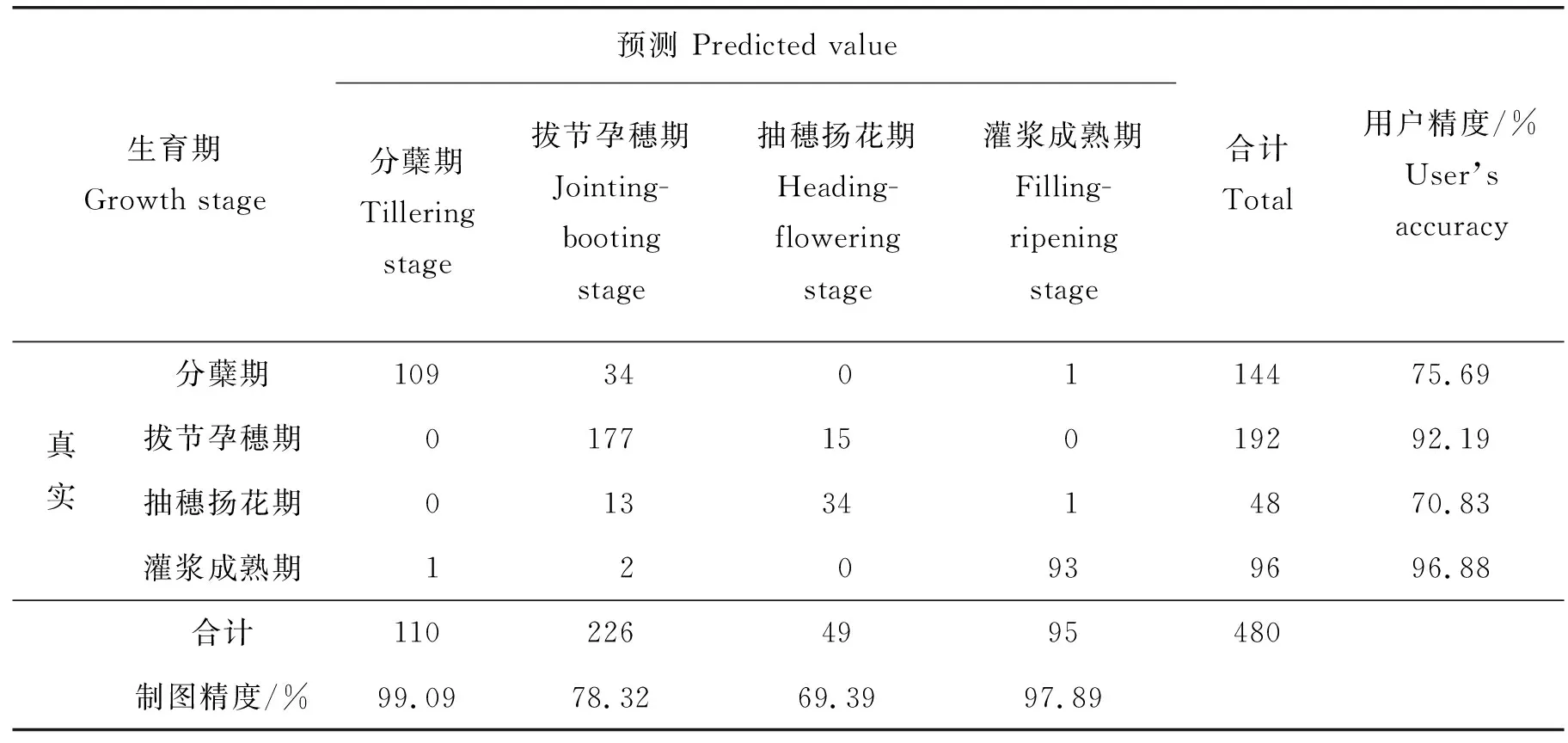
表7 基于UAV数据的KNN结合VARI 水稻生育期识别混淆矩阵Table 7 Confusion matrix of KNN combined with VARI recognizing rice growing stage using aerial-collected data
4 结 论
利用机器学习方法识别水稻生育期,基于高时间分辨率的SKYE数据建立了识别水稻生育期的机器学习模型,并将其推广应用于无人机影像以评价模型的泛化能力。结果表明:各机器学习方法对于SKYE数据均具有较好的识别精度,其中KNN算法精度为91.92%。将其推广至无人机时,KNN算法的适应性最好,识别准确率为83.54%,但容易将抽穗扬花期误识别为拔节孕穗期;进而提出了一种KNN算法结合VARI阈值筛选的方法进行无人机平台的水稻生育期识别,改进后识别准确率为86.04%,相比单独的KNN算法整体识别精度略有提高,同时对各个生育期的识别精度更加均衡。
本研究基于绿、红、红边、近红外的冠层光谱反射率数据,最终获得了针对SKYE平台的KNN水稻生育期识别模型,以及针对UAV平台的KNN结合VARI阈值的水稻生育期识别模型,能够不依赖时序光谱数据识别水稻的关键生育期。提出的水稻生育期识别模型能够辅助精准农业,为水稻的田间管理、长势评估和估产提供参考依据。可进一步将本研究提出的生育期识别模型推广应用至卫星影像,评估模型泛化能力,获取大面积水稻的生育期信息,探索更大尺度的农作物物候,有助于分析大范围内物候的时间波动特征。
猜你喜欢
印制电路信息(2022年11期)2022-11-30 03:40:58
海洋通报(2022年4期)2022-10-10 07:40:26
中国农业信息(2022年1期)2022-05-25 13:31:46
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
农业机械学报(2021年11期)2021-12-07 05:36:44
大气科学(2021年1期)2021-04-16 07:34:18
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
电子器件(2017年2期)2017-04-25 08:58:37
农业环境科学学报(2017年2期)2017-03-20 14:57:37
