
汉语分级阅读的词汇影响因素研究
2020-03-17 10:33:56赵凤娇
语文学刊 2020年1期
○ 赵凤娇
(北京语言大学 汉语国际教育研究院,北京 100083)
一、引 言
分级阅读指根据不同年龄层的生理、心理和认知能力的发展情况,对阅读材料进行分级,为不同年龄段的阅读主体提供适合的阅读材料。美国分级阅读研究最早,也相当成熟,应用范围较广的阅读分级方法有蓝思分级法、A-Z分级法等。蓝思分级法是针对儿童语言能力发展设计的。较之其他分级方法,该方法更注重对文本中的语言要素的测量,操作步骤为首先对文本中的词频、词长以及句长等要素进行量化统计,然后将量化数值带入公式计算出蓝思值,再与难度等级对应,就能得知读物的蓝思等级。汉语与英语不同,张博教授在“面向可读性测评的汉语文本语言特征分析”项目论证中指出:“英语的词长富有弹性,词长类型多样,短则一两个音节,长则近二十个音节,而汉语的词长较短且类型有限,单音节词和双音节词占绝对优势,词长对词义的可理解性及文本可读性的影响不可能像英语那样明显。”因此, 汉语分级阅读研究不可照搬国外分级阅读的评测因素。
目前,汉语分级阅读研究集中在南方分级阅读中心以及接力儿童分级阅读研究中心,它们分别提出分级阅读的标准以及参考书目[1]。就目前研究而言,分级标准并未形成完整的科学的体系,没有国家统一的标准,现有的阅读分级标准侧重于经验,从儿童个体出发,把儿童读者的年龄、学习阶段和身心发展作为分级的标准[2],而语言要素作为影响文本理解的重要因素,在分级读物研究中很少提及。文本在语言要素上所呈现出来的复杂程度一般被称为可读性(Readability)。
以往汉语可读性的研究集中在汉语二语分级阅读研究中,影响因素可以归纳为汉字、词汇和句法三大语言要素。与拼音文字相比,汉字是表意文字,具有鲜明的特点;句法层面的结论也比较单一,句长对可读性具有显著的预测作用。相较于汉字和句法,词汇层面因素较为复杂,考察维度不尽相同,结论也不一致。如有的研究着重于词汇多样和词频维度[3],有的研究仅关注词频维度[4]等;在结论上,有的学者认为虚词数、虚实比是重要的词汇影响因素[5],有的则指出词次比在词汇层面起决定性作用[3]。台湾学者曾对台湾中小学语文教材中的文本难度进行分析,发现难词数、实词频率对数的平均值、人称代名词数等因素影响文本可读性。[6][7][8]那么影响汉语文本可读性的词汇因素有哪些?哪些因素起主要作用?还需要进一步深入研究。鉴于此,本文从词汇多样性、词频、词汇密度和词长等四个维度考察可能影响文本难度分级的主要词汇因素,以及这些因素的有效性。
二、文本来源和处理
(一)文本的来源
张博教授在项目论证中提出:“由于要在比较不同难度汉语文本语言特征的基础上分析提炼影响可读性的主要参数及其权重,因此,选取难度梯级分明的系列汉语文本至关重要。”温儒敏指出“部编本”语文教材是由教育部出面聘请主编和编写专家,调集了全国最强的编写队伍,有条件在总体质量和水平上超越现有各种版本的教材。[9]因此,我们选取部编版二年级、七年级和十二年级①《语文》中的课文②建立了低难度、中难度和高难度三个难度等级的文本库,如表1所示。
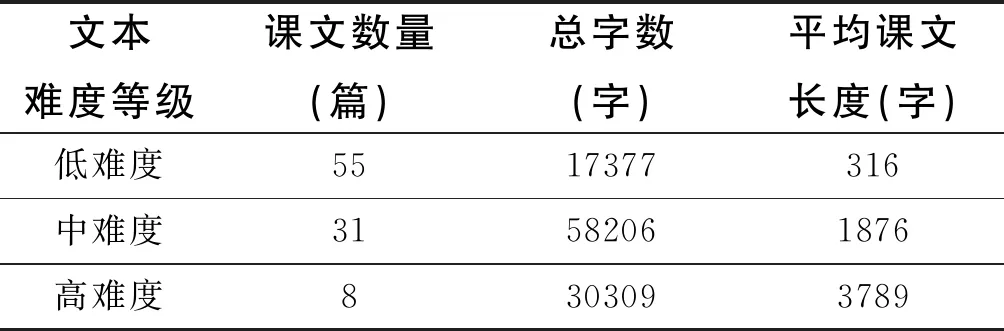
表1 部编人教版不同难度等级课文数量、总字数、平均课文长度分布
(二)切词结果处理
本文使用NLPIR-ICTCLAS汉语分词系统对文本进行词语切分。之后对切词结果进行逐一校对和处理。校对工作以《现代汉语词典》(第7版)为主,以百度百科搜索引擎(https://baike.baidu.com/)为辅。
(三)文本的划分方法和范围
与汉语不同,英文文本是由一个个单词“word”所构成的,而汉语中的字和词是不同的概念,二者并不等同。汉语文本长度多采用字来统计,因此本文按照字数来划分文本长度,每个划分的文本称作一个文本块。为了避免文本大小对统计结果的影响,我们分别以500字和1000字的长度来划分③。
三、不同词汇因素与文本难度等级的相关性
(一)词汇多样性与文本难度等级相关性
词汇多样性由样本中的不同词的数量来表示,在英语中一般通过比较不同单词的数量与总单词数来衡量,即类符-形符比(Type-Token Ratio,简称TTR)。[10]8TTR是样本大小的函数,受文本长度的影响,如较大样本的TTR值比较低,较小样本的TTR值比较高,因此TTR公式的信度饱受质疑。Johnson提出了改善TTR的方法,即平均节段类符-形符比(Mean Segmental TTR,简称MSTTR)。[11]该方法通过将样本分成给定长度的连续段来控制文本长度,然后计算所有段的平均节段类符-形符比来得到TTR。Torruella & Capsada基于不同类型的文本考察了七种测量词汇多样性的公式对文本长度的依赖性,研究发现MSTTR对文本长度的依赖不显著。[12]故本文选用MSTTR的测量方法,将文本先按500字数分成大致相等的文本块,根据每个文本块计算TTR,最后统计TTR的平均值获得MSTTR。本文拟采用词数、词种数和MSTTR值来衡量词汇的多样性。如表2所示。

表2 不同难度等级文本的词汇多样性的统计结果
由表2可以看出,词数随难度等级的升高而减少;词种数也基本随难度等级的升高而增加,不过高难度文本的词种数略微下降。MSTTR随文本难度等级的升高而增加。
通过使用SPSS21.0计算词数、词种数以及MSTTR与文本难度等级的Spearman相关系数,结果如表3所示。

表3 不同难度等级文本的词汇多样性与文本难度等级的Spearman相关系数
注:*代表Spearman相关系数的显著程度,*越多,相关性越显著,下文同。
统计结果表明,词数、词种数和MSTTR与文本难度均呈显著相关,词数与文本难度等级呈显著负相关,词种数呈显著正相关,MSTTR呈显著正相关,相关性由高到低为:MSTTR(0.487)>词种数(0.376)>词数(|-0.351|)。
通过独立样本T检验来验证这三个因素对不同难度文本的预测效用,我们发现,在词数、词种数和MSTTR因素上,低难度与中难度、高难度文本均存在显著差异(p<
0.05);而中难度和高难度文本均不存在显著差异(p>0.05)。也就是说,词数、词种数和MSTTR能显著区分低难度与中、高难度文本,但并不能显著区分中难度和高难度文本。
综上,通过Spearman相关系数和独立样本T检验我们发现,词数、词种数、MSTTR与文本难度等级呈显著相关,词数随文本难度等级的升高而减少,词种数和MSTTR随文本难度等级的升高而升高,三个因素均能显著区分低难度与中、高难度等级文本。但是中难度与高难度文本在三个因素上并不存在显著差异,即词数、词种数、MSTTR不能区分中难度和高难度文本。
(二)词频与文本难度等级的相关性
词频(Lexical Frequency)具有两种含义,一是指在特定文本或语料库中词语重复的频率,也就是通常所说的词次数或频数;二是指词频概貌(Lexical Frequency Profile),指词语在词表的不同词汇频率等级上的分布情况。苏新春和顾江萍全面考察了四套语文教材中的词语分布情况,对比了频率法(词次数)与分布法(词频概貌),发现分布法更容易体现出语文词语的稳定性与通用性。[13]比如对于科技文等特定文本,虽然某些词语在文本中出现次数较高,但对于非专业人士来说却较难理解,这样通过词次数来描述就不准确。相反,这类词在词表中可能属于低分布词,从而通过词表可以较好地反映词的属性。因此,我们采用词频概貌来进行研究。
《现代汉语常用词表》(草案)是基于2.5亿字大规模语料,对现当代社会生活中使用频率较高的56008个汉语普通话词语做出词频排序,并给出了每个词语的词性,是目前最具权威性的词频统计数据。因此,本文将该词表作为词频概貌的划分依据。将该词表按照使用频率由高到低的顺序划分为六个区间,每个区间范围包含10000个词,分别为最常用词([1,10000])、常用词([10001,20000])、次常用词([20001,30000])、较不常用词([30001,40000])、不常用词([40001,50000])、罕用词④([50001,+∞))。词频分布如表4所示。

表4 不同难度等级文本的词频分布情况
由表4可以看出,不同难度等级文本的词数在最常用词区间数量最多,占比均高于80%;罕用词区间占比次高,基本上随文本难度等级的升高而升高,这说明《语文》教材文本均以前10000常用词为主,同时会设置一些生词,这在一定程度上关照了学生的认知规律,即既要保障学生理解文义,也要增加学生的词汇量。

表5 词频与不同难度等级文本之间的Spearman相关系数
由表5可以看出,最常用词和常用词区间与文本难度显著相关(p<0.05),其他区间的相关性均不显著(p>0.05)。
通过独立样本T检验我们发现,低难度文本和中难度文本在常用词区间、次常用词区间上存在显著差异(p<0.05),低难度文本和高难度文本在最常用词区间、常用词区间上存在显著差异(p<0.05)。中难度和高难度文本在各区间上都不存在显著差异(p>0.05)。
综上所知,常用词区间能显著区分低难度与中、高难度文本,而中难度和高难度文本在各区间并无显著差异。
(三)词汇密度与文本难度等级的相关性
词汇密度指具有词汇属性的词(即具有实际意义的词,包括名词、动词、形容词等)的数量与总词数的比率,即实词在总词数中所占的比重。Vajjala & Meurers认为实词比是测量英语文本难度的有效因素。[14]本文借鉴朱德熙的词语分类标准,将名词(包括时间词和方位词、处所词)、动词(包括助动词和趋向动词)、形容词(包括属性词和状态词、区别词)、数词、量词、代词(包括人称代词、指示代词和疑问代词)归为实词,将副词、介词、连词、助词(包括语气词)、叹词、拟声词等归为虚词。[15]46-50本文拟采用实词数、实词比来衡量词汇密度。实词数、实词比在不同难度文本中的分布如表6所示。

表6 实词数、实词比在不同难度文本中的分布
从表6可以看出,实词数随文本难度等级的升高而下降,在词汇密度中,低难度比重最高,高难度文本次之,中难度文本比重最低。

表7 实词数、实词比与文本难度等级的Spearman相关系数
由表7可知,实词数和实词比均与文本难度等级呈显著负相关(p<0.05),其中实词数的相关性最显著。通过独立样本T检验发现,低难度与中、高难度文本在实词数、实词数比上存在显著差异(p<0.05),而中难度与高难度文本均不存在显著差异(p>0.05)。
总之,在词汇密度中,实词数与实词数比显著影响低难度与中、高难度文本等级,而中难度与高难度等级文本之间并无显著差异。
(四)词汇长度与文本难度等级的相关性
词汇长度(word length)一般用于英语文本的测量,指一个词语所包含的音节或字母数。在英语可读性公式中,词长作为文本可读性测量的主要因素,汉语与英语不同,汉语的词长较短且类型有限,单音节词和双音节词占绝对优势。汉语词长对文本可读性的影响是否像英语那样明显还需进一步研究和验证。不同难度等级的文本的词长分布如表8所示。

表8 不同难度等级的文本的词长统计
由表8可以看出,单音节词的词长及其比重随文本难度等级的升高而下降,双音节词长及其比重随文本难度等级的升高而升高,而其他音节的词长并无明显规律。

表9 词长与不同难度等级文本的Spearman相关系数
通过表9可知,单音节词长与文本难度均呈显著负相关(p<0.05),双音节词与文本难度均呈显著正相关(p<0.05),其他音节的词长与文本难度的相关性均不显著(p>0.05)。
通过独立样本T检验我们进一步发现,在单音节词、双音节词长上,低难度与中、高难度文本存在显著差异(p<0.05)。中难度与高难度文本仅在双音节词上存在显著差异(p<0.05)。
总之,单音节和双音节词能显著区分低难度与中、高难度文本,中难度与高难度仅在双音节词上存在显著差异。
四、结 语
本文从词汇多样性、词频概貌、词汇密度和词汇长度等四个维度考察影响文本可读性的词汇因素,发现在500字文本块中,词数、词种数、MSTTR、常用词区间词频、实词数、实词比以及单音节和双音节词长能够显著区分低难度与中、高难度文本,影响力由高到低均为:MSTTR>常用词区间词频>实词数>词种数>单音节词长>词数>双音节词长>实词比,但对中、高难度文本的区分并不明显。本文还按照1000字对文本长度进行划分,发现结果与500字文本块划分中对文本难度等级的影响基本一致。
本文的研究结果契合了目前我国义务教育《语文》课程的总教学目标,也遵循了儿童的认知发展规律。义务教育阶段总教学目标规定初中阶段的任务是全面普及九年义务教育,语文课程侧重要求学生识字与写字、阅读、写作、口语交际、综合性学习;而高中阶段的任务是面向高等教育,为社会培养及输送合格人才,语文课程标准的要求是积累·整合、感受·鉴赏、思考·领悟、应用·拓展、发现·创造。因此从这个意义上来说,义务教育阶段的语文学习更加重视学生语言知识的阶段性的掌握与积累,而高中阶段的语文学习则是重视学生如何正确地将学习到的语文知识运用到具体的实践中。根据皮亚杰的认知发展理论的四个阶段可知,小学阶段为第三阶段,即具体运算阶段(7~11岁),该阶段儿童只能利用具体的事物、物体或过程来进行思维或运算,不能利用语言、文字陈述的事物和过程为基础来运算,也就是说该阶段学生的语言知识还比较低,处于学习阶段;初中阶段为第四阶段,即形式运算阶段(11~15岁),该阶段儿童的思维不必从具体事物和过程开始,可以利用语言文字,在头脑中想象和思维,重建事物和过程来解决问题,也就是说学生在该阶段的语言知识水平已经初步形成。皮亚杰认为15岁之后的人的认知水平在形式运算阶段基础上更加成熟。所以从语言方面来看,低难度文本与中、高难度文本等级区分比较明显,而中、高难度文本等级不太明显。本研究从词汇多样性、词频、词汇密度和词长等四个维度全面考察了影响文本难度分级的主要词汇因素及其在文本难度分级中的有效性,在一定程度上为分级阅读文本的选材和编写提供些许参考。
【 注 释 】
①由于目前“部编本”未涉及高中教材的编写,故十二年级《语文》教材选用正在使用的经全国中小学教材审定委员会2004年初审通过的普通高中课程标准实验教科书《语文》(必修)5。
②课文中排除文言文、诗歌(古代和现代)、戏剧等,主要选取记叙文、议论文、应用文和说明文。
③通过SPSS21.0的配对样本T检验,检验同一难度等级文本的顺序和乱序划分是否存在差异。结果表明,两种长度划分方式中,三种难度等级的顺序划分与乱序划分在词数和词种数上均不存在显著差异(p>0.05)。因此,我们选取顺序划分作为文本的分块方式。
④罕用词不仅包含《现代汉语常用词表(草案)》中的50000以上的词语,还包括词表中未收录的词语,我们将罕用词视为更为低频的词。
猜你喜欢
汉字汉语研究(2021年1期)2021-06-11 01:14:56
新世纪智能(语文备考)(2019年1期)2019-05-31 10:04:50
新世纪智能(语文备考)(2018年11期)2018-12-29 12:31:00
数理化解题研究(2018年34期)2018-12-27 08:30:04
新世纪智能(语文备考)(2018年9期)2018-11-08 11:03:44
数理化解题研究(2018年16期)2018-07-12 02:46:56
西昌学院学报(社会科学版)(2015年1期)2015-12-23 12:19:40
语文知识(2014年2期)2014-02-28 21:59:27
中国期刊年鉴(2014年0期)2014-02-15 03:03:56
中国期刊年鉴(2014年0期)2014-02-15 03:03:54
