
考虑共享单车再平衡的配送中心选址研究
2020-03-17 00:48吴家霞贵州大学管理学院贵州贵阳550025
物流科技 2020年2期
吴家霞 (贵州大学 管理学院,贵州 贵阳550025)
0 引 言
近年来,中国经济的迅速增长迫切需要一种交通方式来缓解由于汽车数量增长带来的交通压力,共享交通应运而生。共享单车在一定程度上起到了保护环境、节约资源的作用,减少了因为发展带来的城市交通压力。共享单车布局规划研究主要解决的问题是基于需求分析得到的候选点基础上,确定在哪些候选点建立设施。选址问题是一个长期战略性决策,在对共享单车选址问题进行研究时,主要由最优化方法和仿真[1]的方法得到选址方案。最优化方法包括单目标规划和双目标规划两种。单目标规划由最大需求覆盖[2-3]、总成本最小[4]、最小运输成本[2]等为目标建立模型;双目标规划则由以最大化收益—最小化旅行时间[5]、最小化成本—最大化安全[6]等为目标建立模型。本文基于物流中心三层选址—路径问题(LRP) 建立模型,在满足车载限制、最大行驶距离限制以及车辆数量平衡等条件下,建立以包括设施建立费用和运输费用的总费用最小的优化模型,LRP 问题属于NP-hard 问题,故而选择遗传算法对其求解,并通过案例证明算法的正确性和有效性。
1 模型建立
1.1 问题描述
本研究主要研究问题描述如下:某共享单车公司在某区域内已经建立好N个共享单车停放点,且各停放点地理位置已知,该公司内现有辆送货车,货车按照其载重和耗油量分为三种不同的类型,分别是大型货车(K1)、中型货车(K2)、小型货车(K3),其中K=K1∪K2∪K3,三种车型的载重分别是Q1、Q2、Q3,固定运输成本分别是g1、g2、g3。现该公司通过其他途径在该区域内选择个点作为共享单车配送中心候选点,则该共享单车所有点的集合S=N∪R,并且该系统中任意两点之间的运输成本为cij,同时该系统中共享单车停放点的需求di为随机变量且服从正态分布,其中:di>0 表示单车需从停放点取出放置到送货车中,di<0 表示单车需从送货车中拿入停放点。在配送中心候选点中选出部分点建立配送中心,其建立配送中心的固定成本为fi,从已经建立的配送中心出发,选择所需配送服务的停放点以及配送路径,最后回到配送中心,形成闭环环路,在此过程中要求车辆在运输过程中不会超过其最大载重Qkt以及最大行驶距离D。此次研究基于上述已知条件和流程,选择位置最优的配送中心和再平衡车辆路径实现总成本(包括建设成本和运输成本) 最低的目标。
1.2 变量设置
参数:
R为配送中心候选点的集合;
N为各停放点的集合;
S=R∪N为所有点的集合;
K为所有车辆的集合;
mk为车型为k的可用车辆的集合;
cij为i,j两点之间对应的运输成本;
fi为各配送中心建立的固定成本;
di为停放点i的需求,其中n-1 的停放点需求独立同分布,第n个停放点的需求不独立同分布,其中d1+d2+…+dn=0;
gk为车型为k k∈(K)的送货车从配送中心出发再回到配送中心这一过程发生的固定费用;
Qkt为车型为k(k∈K)的第t(t∈mk)辆送货车自身的最大载重量;
dij为共享单车系统内点i到点j之间的距离;
D为每辆车的最大行驶距离。
决策变量:
yi为在配送中心候选点i建立设施yi=1,否则为0,其中i∈R;
xijkt为使用车型为k的第t辆送货车从点i行驶到点j,则xijkt=1,否则为0,其中i∈S,j∈S,k∈K,t∈mk;
zij为在再平衡过程中,当停放点j由配送中心i提供服务时,zij=1,否则为0,其中i∈R,j∈N;
为车型为k的第t(t∈mk)辆送货车在离开点时的载货量,其中,当i为设施备选点时当i为客户点时,xijkt=1时,存在
1.3 选址路径模型
根据上述问题,建立选址路径模型如下:
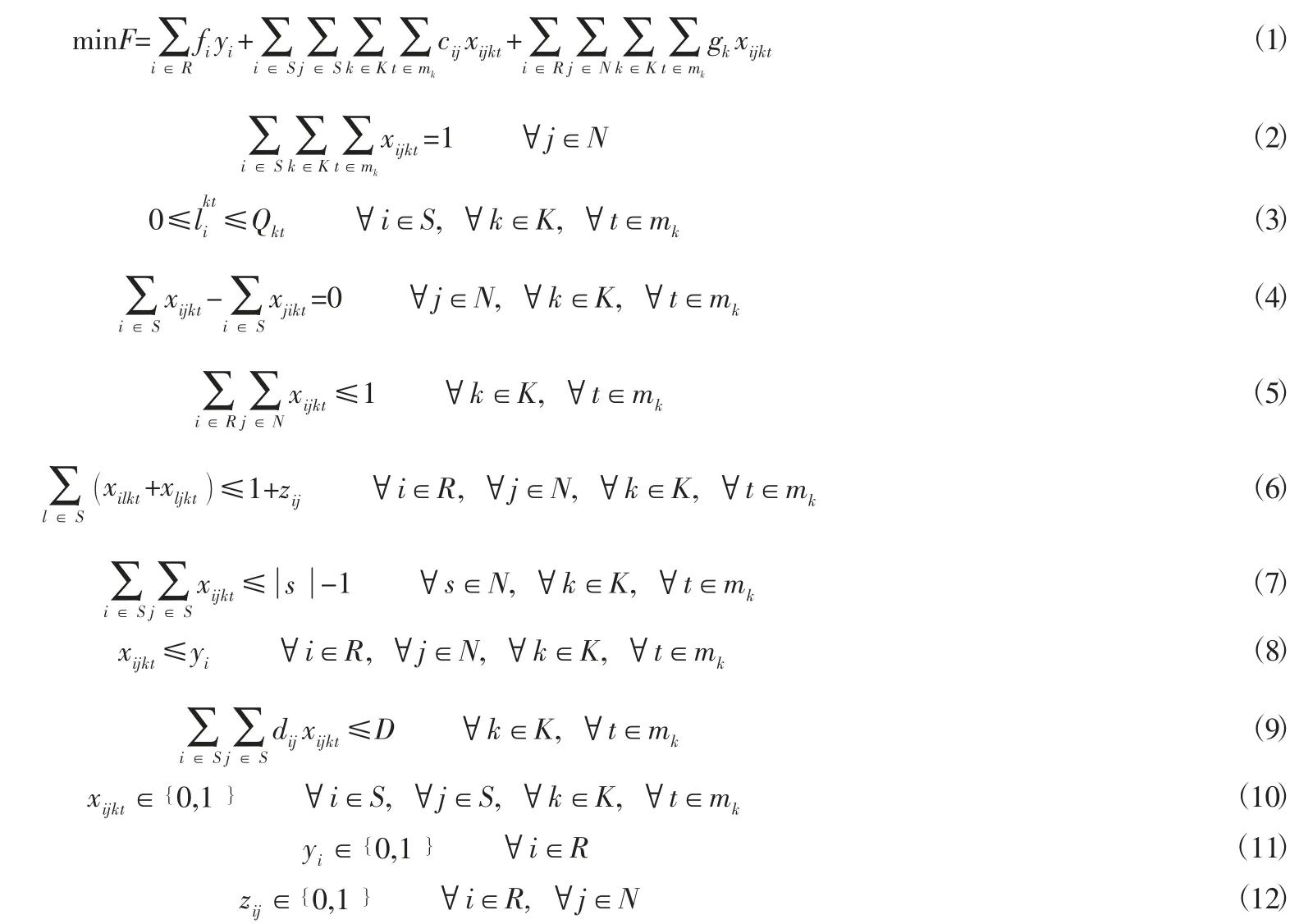
在上述模型中,式(1) 表示目标函数是总成本最小。总成本包括配送中心的建设成本、再平衡过程的运输成本以及车辆使用的固定成本;约束式(2) 保证每个停放点都有车辆提供服务;约束式(3) 每条路径上的车辆在服务了任意一点后的车辆载重必须在车辆额定载重范围内;约束式(4) 对任一停放点,货车进入和出去车辆平衡;约束式(5) 表示每条路线只能从一个配送中心出发;约束式(6) 表示停放点只能由选中的配送中心提供服务;约束式(7) 是子路径消除约束;约束式(8) 表示xijk与yi之间的逻辑关系;约束式(9) 表示每辆车在行驶过程中不应该超过最大行驶距离;约束式(10) 至式(12) 则是变量约束。
2 模型有效性验证
现有共享单车配送中心候选点1、2、3,以及5 个共享单车停放点4、5、6、7、8,则S= {1、2、3、4、5、6、7、8 },各点之间的直线距离及各停放点的需求di如表1。
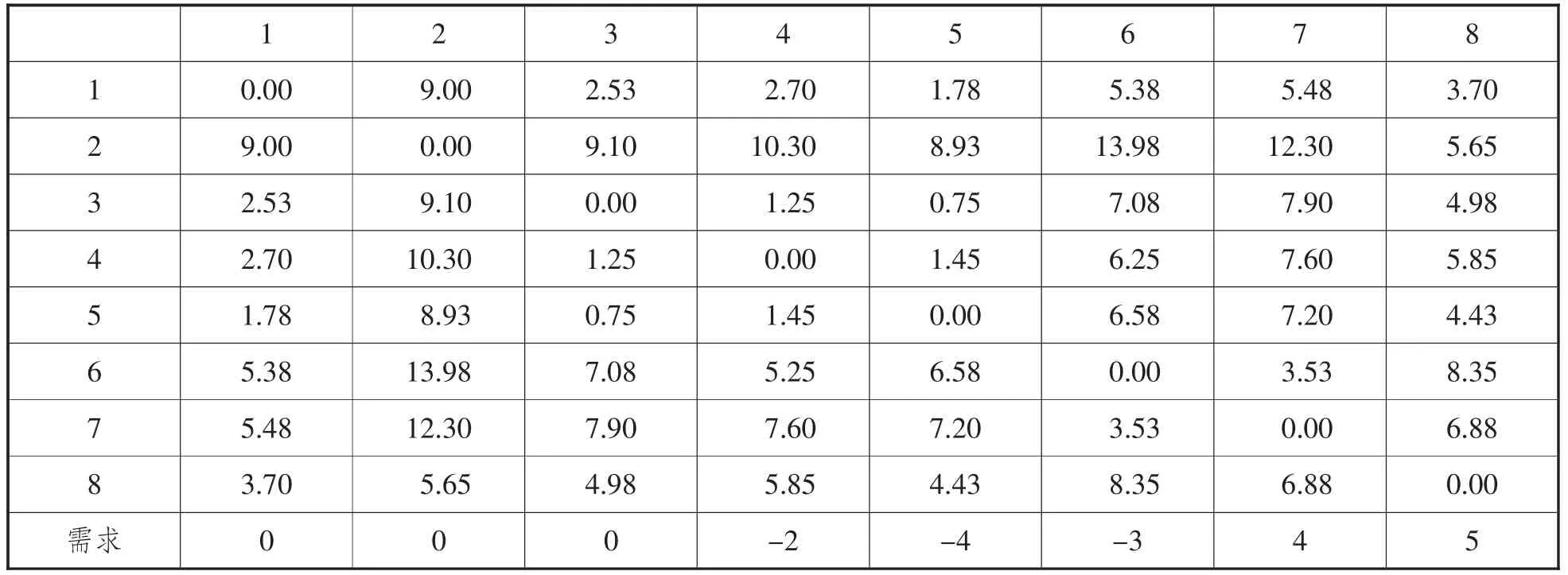
表1 各节点之间的直线距离以及停放点需求
现有两种送货车车型k1和k2,车型为k1的车辆载重为8 个单位,出行的固定成本为8 元,车型为k2的车辆载重为10 个单位,出行的固定成本为10 元,每辆车的最大行驶距离是20km。3 个共享单车配送中心候选点建立的固定成本相同,皆为f=300 元,车辆单位运输成本为1.5 元/km,根据相关数据计算出共享单车系统内所有点之间的运输成本,并验证模型的有效性,证明了该模型的可行域不是空集,即构造一个可行解,证明该解满足模型的约束条件,则证明该模型为有效。根据上述数据,构造一个可行解如下:
(1) 在候选点1 处建立配送中心,2、3 处不建立配送中心,即y1=1,y2=0,y3=0;
(2) 由配送中心出发的车辆路径为:k1: 1→6→7→1,k2:1→4→8→5→1。经计算上述给出的选址—路径方案是本文模型的一个可行解,故而本文模型有效。
3 遗传算法
3.1 染色体编码
在本次研究中,将采用特定的编码方式,实现对车辆载重限制等约束条件的控制,每一条染色体将代表所研究问题的一组可行解。
在本文中,每一条染色体由三部分组成。第一个字串有n个基因位,由n个1 到k的随机自然数组成,其中n是需要提供服务的停放点数量,k表示可供选择的最大车辆数。第二个字串有n个基因位,是由1 到n的自然数随机重排列生成,字串二和字串一是一一对应关系,代表了每条路径中车辆向停放点提供服务的先后顺序。第三个字串有k个基因位,是由k个1 到r的随机自然数组成,r表示配送中心候选点的数量,该字串与字串一、字串二相对应,该字串控制了由字串一和字串二形成的车辆路径属于哪一个配送中心候选点,若配送中心候选点与形成的路径相对应,则意味着建立设施。由此可知,本文中染色体长度为n+n+k。
3.2 初始种群和适应度函数
根据文章中提出的编码方式,将染色体分为三个字串来分别生成:在本文中,一个染色体的总的长度为n+n+k,其中n为停放点的数量,k为所能提供最大的车辆数。一个染色体分为三个字串,第一个字串有n个基因位,其中每个基因位都由1 到k的自然数中随机选取一个生成;第二个字串有n个基因位,这n个基因位都是由1 到n之间的自然数随机全排列生成,该字串没有重复的数值;第三个字串有k个基因位,其中每个基因位是由1 到r的自然数中随机抽取一个一个生成。
在求解目标函数的过程中,对于本文的模型,除了约束条件式(3) 之外的约束都通过编码的方式解决,但约束式(3) 属于车载容量约束,是必须满足的,故而对该约束条件,将不满足约束条件的那个染色体在计算其目标值函数时加上一个极大值,用以减小其适应度函数值。
由于本文中的目标函数值是求最小值,故而将目标函数值的倒数作为该染色体的适应度函数。
3.3 选择算子
本次研究一共采用了两种选择算子,轮盘法和精英法。在遗传算法过程中,选择部分主要是轮盘法,在每一个种群里,按照每一条染色体的适应度函数来分配轮盘面积,每条染色体在整个轮盘所占面积的比率代表被选中的比率,然后随机产生,根据其在轮盘上属于哪一条染色体则将该区域对应染色体复制给下一代,这样产生的种群里,存在有适应度较差的染色体,也存在相同的染色体。在交叉和变异过程皆采用了精英法,将通过交叉或者变异形成的种群和上一代种群放于同一个矩阵,对每条染色体的适应度函数排序,将染色体适应度较大的一半作为交叉或者变异的子代种群。
3.4 交叉算子
遗传算法中的交叉过程是通过交叉概率进行基因的重组,形成新个体。染色体的交叉是将两条父代染色体,随机生成一个或者多个交叉点,将两条父代染色体基因互换,形成新的一对染色体。本文中为了不使染色体出现乱码的情况,将每条染色体分为三个部分,第一个字串是第1 到第n位,使用单点交叉法进行交叉;第二个字串是第n+1 位到第n+n位,由于是n个不能重复的实数,根据这个特点选则顺序交叉法进行交叉;第三个字串是第n+n+1 到第n+n+k位,使用单点交叉法进行交叉。
3.5 变异算子
遗传算法中的变异过程的目的是为了防止求解过程陷入局部最优,故而设置变异概率,随机生成的概率值低于变异概率,就可以通过变异寻找新的搜寻区。同样,根据本文染色体的特点将染色体分为三个字串,由于本文的染色体基因位的数皆是大于零的自然数,且第二字串不能出现重复数值,故而三个字串皆用倒置的方法对其进行变异,过程如下:程序随机生成两个小于每一个字串长度的自然数,即对应基因位置,然后将两个位置之间的数值进行倒置,形成新的染色体,这个过程的变异概率需要多次的实验确定。
3.6 结束条件
遗传算法的求解过程是从初始种群出发,在可行域内一步一步搜索更好的解的过程,在程序语言中则是通过迭代来完成寻优过程。迭代过程结束一般可以通过设置迭代次数、迭代时间或者适应度函数值或者目标函数值无法进行下一次迭代这三种情况,本文研究选择迭代T次,结束迭代过程,然后取出最优目标函数值和最优染色体。
4 算例计算
(1) 基础数据
某共享单车企业现已建共享单车停放点20 个(编码1-20) 以及调查得出配送中心候选点3 个(编码21-23),建立设施的固定费用分别为127、158、142,根据武汉市公布的共享单车出行报告,90%的骑行都在15km/h,83%的骑行都在20 分钟以内,故而共享单车两个点之间的距离取1~5 公里之间的随机值,两个点之间的运输费用取2 元/km。公司现有5 辆同车型的送货车,每辆车最大载重150 辆该公司的单车,单辆车出行一次的固定费用为50 元,每辆车的最大行驶距离为20km。
(2) 模型求解
本次研究模型求解是使用Matlab 语言对遗传算法进行编码,各参数设置如下:交叉概率为0.8,变异概率设置为0.005,极大值M设置为100 000,染色体种群设置为300,染色体长度为45,迭代次数为1 000 次。最终计算出目标函数值为419.71 元。相对应的选址—路径方案为:在设施点21 处建立设施;车辆1 的行驶路径为:21-16-12-5-7-10-4-15-6-21;车辆2 的行驶路径为:21-1-8-20-17-19-14-21;车辆3 的行驶路径为:21-13-2-11-18-3-21;车辆4 的行驶路径为:21-9-21。目标函数值与迭代次数的关系如图1 所示。
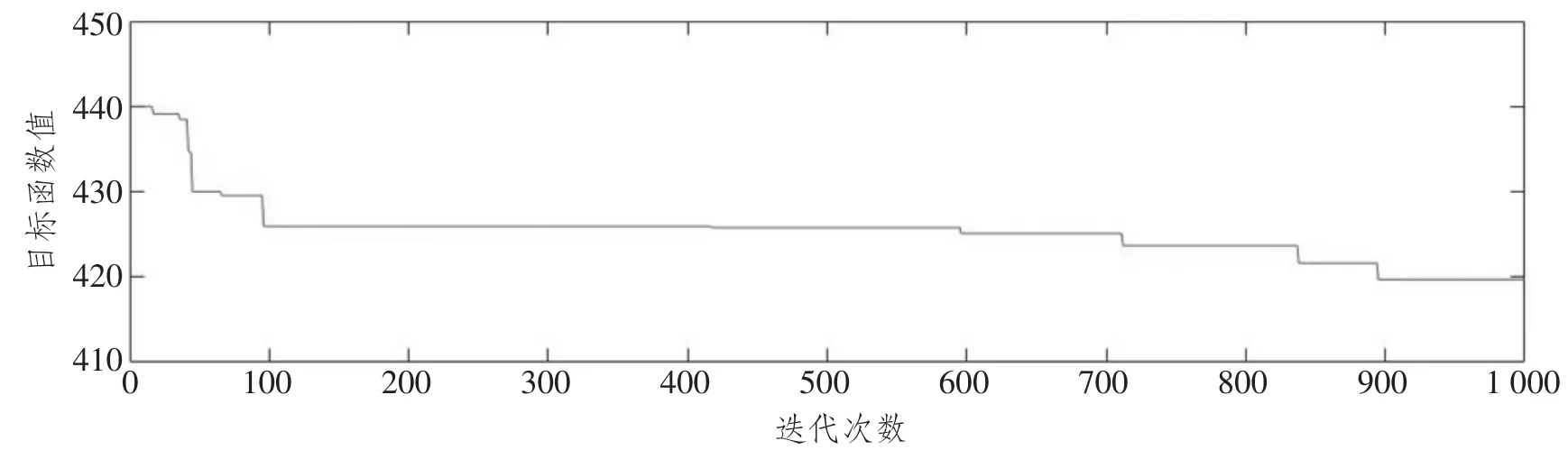
图1 目标函数值与迭代次数的关系
5 结 论
本文提出将共享单车再平衡过程纳入考虑,建立共享单车配送中心选址模型。模型中将车辆载重、车辆最大行驶距离以及车辆数量平衡等作为约束条件,以总成本最小建立模型。然后采用遗传算法对模型进行求解,根据模型的特点选择相适应的编码方式、交叉算子以及变异算子。当前无论国内外研究,共享单车系统选址的研究大都做的是停放点选址或者停放点选址+再平衡。受物流中心选址中三层LRP 问题启发,配送中心是停放点的上一层级,研究配送中心选址可以为以后研究配送中心选址+停放点选址+再平衡研究提供理论基础。同时,当前共享单车配送中心的选址研究缺乏研究成果,更需要深入研究,加深理论基础。
猜你喜欢
意林彩版(2022年1期)2022-05-03
读友·少年文学(清雅版)(2020年1期)2020-05-20
初中生世界·八年级(2019年6期)2019-08-13
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
小学生导刊(低年级)(2016年6期)2016-07-02
计算机工程(2015年8期)2015-07-03
