
公路视频实时车辆检测分类与车流量统计算法*
2020-03-16 08:02查伟伟
网络安全与数据管理 2020年3期
查伟伟,白 天
(中国科学技术大学 软件学院,安徽 合肥 230000)
0 引言
公路视频的车辆分类与车流量统计是运动物体目标检测识别与跟踪问题,可以通过传统图像方法和现代深度网络实现。传统图像方法由于计算量较小,因此实时性相对较高。现代深度网络在背景分割、目标分类的准确度上有着压倒性的优势。
传统方法进行运动物体检测一般是在图像连续的帧之间做差分,进行背景去除或者对每个像素进行前景背景建模。经典的方法如帧差法[1]、光流法[2]、背景减除法[3]、高斯背景建模[4],这些方法实时性高,但弊端也显而易见:对高速和低速运动物体检测效果差,抗背景扰动性差,对光照度变化敏感,切割出的物体有较大的背景边缘。这些弊端不利于后续的分类和统计。文献[5]给出了背景建模的难点并构建了合成数据库用以评价其他方法。
深度卷积神经网络[6](Deep Convolutional Neural Network,DCNN)应用之后,给类似于图像的网格计算带来了福音。从RCNN[7]、Fast RCNN[8]到Faster RCNN[9]以及后续的Mask RCNN[10]等一系列深度网络在目标检测和分类准确率上有了极大的提升。其中Mask RCNN甚至可以将目标沿着边缘直接切割出来。特征金字塔FPN[11]的提出更是对细小物体轮廓检测的精确度产生了极大影响,可以在低层次特征图上获取小物体轮廓。RetinaNet提出用FocalLoss[12]代替原来的交叉熵损失,缓解了two-stage网络的类别不平衡问题,进一步提高了检测速度。与此同时,像YOLO[13]、SSD[14]、对SSD的改进RefineDet[15],以及对特征图融合的改进M2Det[16]这样的one-stage深度网络在提升准确度的同时,实时性上也有所提升。在经过YOLO网络和YOLO9000[17]算法的奠基之后,YOLOv3[18]已经可以对视频进行端到端的实时目标检测和分类,但如果将其直接用在公路视频上,研究发现由于车辆的由远及近,在远处捕捉的目标误差很大;夜间光照度弱的时候,背景常常被误判捕捉;甚至是摄像头视频左上角的时间变化都会被捕捉成运动物体。这不便于车流量统计。
基于以上问题和需要,本文提出一个基于修改后的YOLOv3和浅层网络的重构网络和后续的去重统计车流量算法。实验结果表明相比传统检测带法,该算法明显降低了复检和漏检率,相比于目前的目标跟踪方法降低了时间复杂度。
1 相关网络
1.1 YOLOv3检测网络
YOLOv3是一个端到端的one-stage目标检测网络。其端到端的特性是指可以直接从视频输入到视频输出。这依赖其one-stage的优势——实时性好,依据其官网提供的数据,YOLOv3-320可以达到45 f/s,YOLOv3-tiny可以达到220 f/s,可以实现在mAP和速率之间权衡。公路视频一般在25 f/s,可以满足实时性需要。但相对于two-stage网络,YOLOv3也有其明显的劣势,由于其候选anchor数目很多,而真正进行分类和坐标回归预测的只有少数真正含有目标物体的anchor。YOLOv3的损失包括了是否含有目标物体的置信度损失、分类损失以及坐标预测损失。大量的anchor预测的都是背景导致负例比例严重大于正例比例,而负例损失虽然没有计入分类损失和坐标预测损失,但是却会被计入是否含有目标物体的置信度损失中。通过实际预测较少的anchor提高了YOLOv3的速率但也降低了预测的准确度。
1.2 浅层分类网络
自Alexnet之后,人们自主设计的分类网络层出不穷。经典的如VGG、GoogleNet、Inception Network、ResNet。与这些网络相比,浅层网络层数少,时效高,准确率也不会丢失几个百分点。较之后动则上百层的分类网络,浅层网络可以仅有5层卷积层、3层池化层以及4个全连接层。外加一些ReLU、dropout等提高网络性能的手段。考虑到实时性的要求,本文采用这样一个层数较浅的分类网络去提高抗背景的扰动性,去除目标检测网络中错误切割出的运动目标以及变化的背景。
2 公路视频实时车辆检测分类与车流量统计
本文提出一种基于YOLOv3与浅层神经网络整合后的实时车辆检测与分类网络,在满足实时性的同时提高网络对公路视频的车辆检测和分类的准确性。之后根据两个网络的输出提出一种基于传统图像方法的车流量统计算法。
2.1 检测分类网络
检测网络采用YOLOv3,模型采用YOLOv3-416,根据官网提供数据,YOLOv3-416可达35 f/s。利用Darknet平台提供的detector demo API测试,可以实现公路视频的实时端到端输出。实测直接用YOLOv3训练自己的车辆数据集进行检测分类时,网络由于数据集的大小、公路视频的噪声干扰、环境光照度变化等因素导致分类效果不理想,甚至会错误分类一些类似模糊的背景以及摄像头上方变化的时间信息。实时性可以保证,准确性达不到实际需求。
针对以上问题,本文对YOLOv3网络的主体部分进行改造。改造后的网络如图1所示。
为保证分类的准确性不受公路视频噪声、光线变化等因素的干扰,应当先对图片数据进行一次筛选,不应当直接分类,所以改造YOLOv3主干网络输出层前的1×1网络通道数为3×7,3为每个grid预测3个尺寸的anchor;7包含x、y、w、h四个坐标,物体置信度prob以及iscar、notcar两个分类。两个分类中的notcar用来对采集的视频图片数据进行清洗,筛除行人、摄像头上角变化的数字等一系列运动的物体。考虑到车辆在刚进入摄像头画面时是不清晰的,不利于后续分类,所以希望捕捉到尽量大一些清晰些的车辆,同时进一步提高实时性。基于以上两点,在FPN(特征金字塔)中,只向上采样一次,在原有13×13的特征图中再得到26×26的融合特征输出,分别对应于图1中的output1和output2。对主干网络的输出进行坐标回归以及非极大值抑制后得到的输出为准车辆的boundingbox坐标(小目标物体由于多次特征提取导致坐标回归不精确,很大概率会在后续的初步根据置信度筛选目标框中被过滤)。根据坐标对原图进行裁剪,将目标裁剪出来,进一步排除背景变化对分类的干扰。为保证实时性,选择一个层数不深的浅层神经网络作为后继,浅层分类可并行。将裁剪后的目标图片resize成固定大小的图片作为浅层网络的输入。浅层网络输出为car、bus、motor、truck、none五个分类,其中none用来筛除误检测的背景等图片。考虑到自身公路视频车辆数据集的大小问题,为了防止过拟合,并不对车辆数据集进行去噪和手动筛选,仍然采用含有噪声扰动以及运动模糊的原公路视频车辆数据集进行训练。为了防止高偏差,浅层网络的特征提取层采用在ImageNet上的预训练参数,仅对4个全连接层用自身车辆数据集迁移学习。
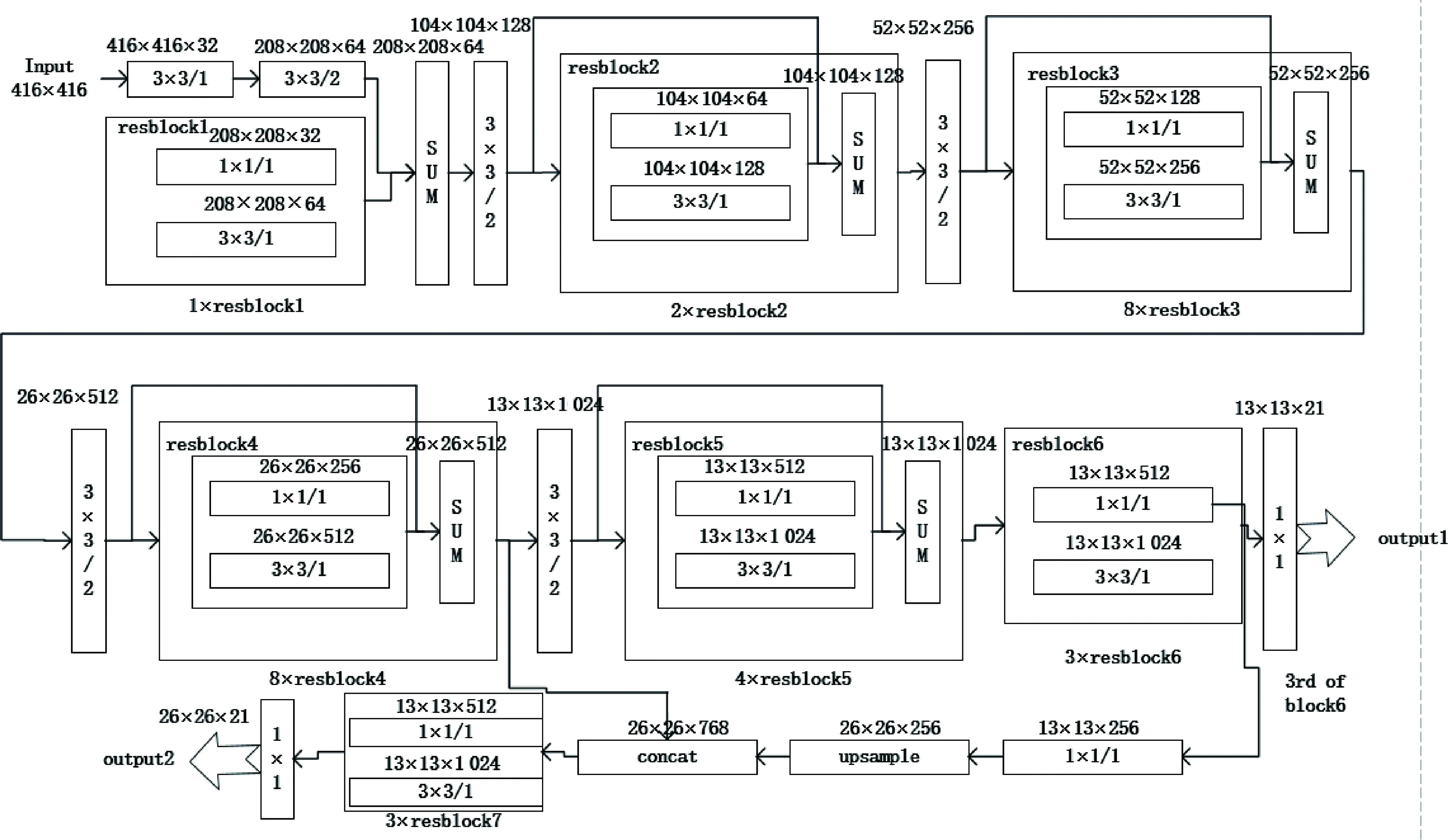
图1 改造后的darknet53
2.2 融合网络的训练
融合后的网络采取分开训练的方式,改造后的YOLOv3网络使用ImageNet进行初始权重的训练,初始学习率设置为 0.1,weight decay设置为0.000 5,momentum设置为0.9,batchsize设为 128。训练30个epochs。使用厦门公路局提供的车辆数据集制作成coco数据集在初始权重上再训练10个epochs。浅层分类网络的训练采取finetune的方式,初始权重在ImageNet上预训练得到,保存在npy文件中,将该文件中网络权重转化成tensorflow的ckpt格式。加载过后冻结最后的四个全连接层,将厦门公路局提供的车辆数据集通过改造的YOLOv3网络进行目标检测,裁剪出车辆目标以及一些none分类目标图片作为训练集,训练集比例car:bus:motor:truck:none为1∶1∶1∶1∶1。将该裁剪后的图片训练集对浅层网络进行finetune,得到最终的权重文件。
2.3 车流量统计算法
将浅层网络输出的4个车辆分类(none分类直接过滤)以及YOLOv3网络输出的对应目标坐标作为车流量统计算法的输入。因为YOLOv3网络在目标检测阶段对每一帧图片都实时地输出了目标的中心点坐标和长宽,可以充分利用帧与帧之间的大量重复信息,类似于帧差法求运动前景的轮廓,当物体运动过快或者选择不连续的帧进行差分的时候就会出现拖长的轮廓。同理,可以对每隔几帧的图片的anchor box中心点坐标以及长宽进行匹配。目标中心点坐标相差小于阈值,并且长宽变化小于阈值时判定为同一辆车。反之判定为新的车辆进入视野,车辆计数器加一。
算法流程如下:
(1)初始化车辆计数器Count=0。


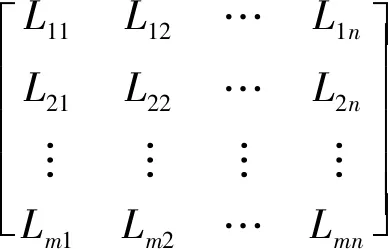
(1)
(5)计算矩阵每一行Li1,Li2,…,Lin(i=1,2,…,m),若存在Lij<ε(j=1,2,…,m),则Count不变;否则,Count++。
(6)提取交通视频剩余帧画面,重复步骤(3)~步骤(5),直至结束。
算法流程图如图2所示。

图2 车流量统计算法流程图
3 实验与分析
3.1 实验配置
实验用到两个数据集:ImageNet数据集和从厦门公路局提供的公路视频提取到的车辆数据集。其中公路视频数据集包括45 012张训练图片和13 587张测试图片。训练集和测试集均划分为5个类:car,truck,motor,bus,none。其中none代表非车辆分类的运动物体或背景。并且对该数据集只进行了人工打标签操作,并未进行任何数据集清洗,图片包含噪声,目标物体存在运动模糊,与摄像头存在距离变化。因此训练出的模型泛化能力好。
实验环境包括硬件设备和软件配置。硬件参数为:Intel(R) Xeon(R) Silver 4116 CPU @ 2.10 GHz;6条32 GB内存;Ubuntu16.04;Tesla V100 16 130 MB显存。软件参数为:TensorFlow 1.13.1;Keras 2.2.4;Python3.7.3;Jupyter Notebook。
实验模型参数分为两部分,第一部分YOLOv3网络采用YOLOv3-416改造后的模型,权重参数使用在ImageNet数据集和自身车辆数据集上训练得到的初始参数。该权重是在ImageNet数据集上分了几个阶段训练得到的,比直接使用公路视频提取的车辆数据集训练得到的权重在目标检测上效果好。第二部分浅层网络初始训练采用ImageNet数据集。初始训练过后使用车辆测试数据集进行测试,top1准确率为83.31%。初始训练和测试完毕后使用车辆训练数据集再次训练,冻结之前的所有特征提取层。训练10个epochs过后再次使用车辆测试数据集进行测试,top1准确率达到96.30%。
3.2 结果与分析
3.2.1 检测分类效果
由于公路视频车辆检测和分类难以找到具体的对照指标。为了体现本文重构模型的分类效果,将本文模型与直接用YOLOv3训练车辆数据集得到的模型的分类进行对比。将车辆数据集制作成YOLOv3官方要求的coco数据集进行训练YOLOv3网络,初始权重采用ImageNet上的预训练权重。设置上述5个分类,模型采用YOLOv3-416,Batchsize设置为与浅层网络同样的大小128,训练10个epoch。随机抽取测试集5个分类中车辆的分类结果和置信度大小,本文重构网络分类效果如图3所示。

图3 本文重构网络识别效果图
由图3第一行子图可见,本文重构网络对于夜间背景和光线昏暗的隧道等可见度低的背景筛除效果较好;由第二行第一个子图可见,对于特殊的箱式货车,模型可以正确给出分类结果,但分类置信度不高,后期可以通过对这种特殊的货车进行数据增强以提高分类置信度;由第三行和第四行可见,模型对于白天车型分类准确率和置信度很高,完全可以投入到实际应用中;由第五行前两张图片可见,模型对于夜间微小车辆分类具有鲁棒性,由最后一张图片可见运动模糊的车辆在切片过后分类效果较好。
由图4很容易看出夜间直接用YOLOv3网络训练自己的数据集已经不能检测公路视频中的车辆类型,还有噪声被当成目标错误地捕捉。由图3可以看出本文的重构网络夜间可以很好地去除YOLOv3错误捕捉的噪声构成的目标,去除大量噪声的错检。但对车辆检测的置信度也存在一定的下降,会存在漏检的情况,这时可以通过降低设置的置信度阈值来进行一定的补偿。但仍需后期进一步改进夜间的效果。

图4 YOLOv3网络识别效果图
综合上述对比图可以看出,基于one-stage的YOLOv3网络训练得到的模型直接用在公路视频车辆测试集上,分类存在一定的错误率,尤其是在存在运动模糊的小型物体如motor和较大背景周期噪声的truck上,错误率较高,而这些情况在公路视频上很常见。置信度的差距尤为明显。这体现出直接在车辆数据集上训练的泛化能力不足。后期可以考虑在YOLOv3上冻结某些层进行训练。
3.2.2 车流量统计效果
为验证本文车流量统计算法在掺杂光照强度和背景变化干扰下的效果,随机抽取3条道路,每条道路抽取2个视频,包含白天、夜晚。人工输出一定视频时长中车辆数目,具体如表1所示。

表1 车流量实际情况统计表
实验中采用匹配准确率作为指标:
(2)
其中,right代表正确检测并匹配对的机动车数量,error代表未检测到或者匹配出错导致误检漏检的机动车数量。为验证本文提出的算法效果,本文使用基于虚拟检测带的方法对实验视频数据进行处理并做对比,如表2所示。
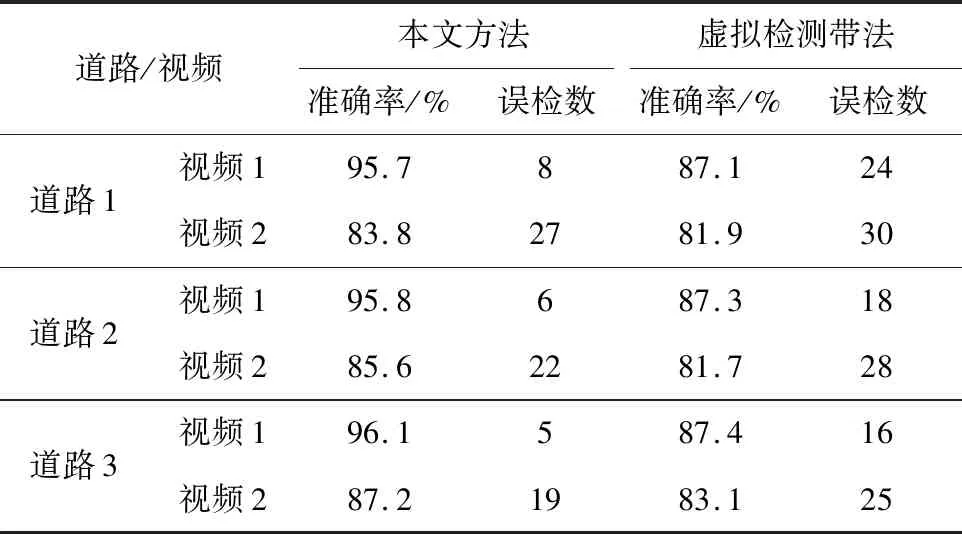
表2 车流量统计效果对照表
4 结束语
本文提出一种传统图像方法和深度学习方法相结合的基于公路视频的实时车辆检测分类和车流量统计算法,在保证实时性的同时提高了公路视频车辆分类的准确率。建立了基于YOLOv3网络和浅层网络的重构网络,当输入为有噪声污染的图像和公路实时视频时,分类置信度和准确率相较于原YOLOv3网络有明显的提高,对于夜间视频有一定的改善效果。基于逐帧匹配的车流量统计算法,相比于传统的检测带法,本文方法误检漏检率低、人工干预少。该方法还有很多可以提升的空间,其中检测网络还是会有一定的小目标物体被检测,导致后续的分类网络会分类一些在图像边缘就捕捉到的轮廓模糊的车辆,从而降低分类准确率;其次目前由于数据集的限制,没有对车辆具体类别再继续细化下去。后续研究会考虑对公路的具体每个车道进行车流量统计。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
水土保持学报(2022年5期)2022-10-10
小型微型计算机系统(2022年4期)2022-05-09
建材发展导向(2021年24期)2021-02-12
计算机应用(2018年5期)2018-07-25
中国科技纵横(2016年20期)2016-12-28
吉林农业(2016年4期)2016-05-14
数学教学通讯·初中版(2015年5期)2015-06-17
