
基于弱监督学习的图像语义分割方法综述
2020-03-13 08:11曾孟兰杨芯萍董学莲罗倩
科技创新与应用 2020年8期
关键词:评价指标
曾孟兰 杨芯萍 董学莲 罗倩

摘 要:为了解决全监督语义分割网络训练成本高的问题,研究者们提出了基于弱监督学习下的语义分割方法。文章对弱监督学习的语义分割方法进行综述,并介绍了语义分割领域常用的数据集和评价指标,最后提出了弱监督语义分割的发展方向。
关键词:弱监督学习;语义分割;数据集;评价指标
中图分类号:TP391 文献标志码:A 文章编号:2095-2945(2020)08-0007-04
Abstract: In order to solve the problem of high training cost of fully supervised semantic segmentation network, researchers proposed a semantic segmentation method based on weakly supervised learning. This paper summarizes the semantic segmentation methods of weakly supervised learning, introduces the data sets and evaluation indexes commonly used in the field of semantic segmentation, and finally puts forward the development direction of weakly supervised semantic segmentation.
Keywords: weakly supervised learning; semantic segmentation; dataset; evaluation index
引言
图像的语义分割技术就是利用神经网络模型对图像中的每一个像素点进行分类,进而得到对应目标的语义标签信息和位置信息。该技术可以使得智能机器人等对周围环境有更全面的理解,在无人驾驶、无人机和机器人导航工作领域扮演着重要角色。
早期的语义分割方法主要是基于全监督学习的图像语义分割,该方法首先需要专业人员对训练的数据集样本进行精准的像素级标注,然后利用标注好的数据对语义分割神经网络进行训练,最后将训练好的分割网络用于图像的分割。因为有精准的训练数据,所以基于全监督学习方法的图像语义分割能够得到较为准确的分割结果。但是,基于全监督学习方法的图像语义分割结果过度依赖于精准的数据集标注,而标注相对精准的数据集是一项需要消耗大量人力以及时间的任务,这无疑增加了科研工作的成本。一些研究者为了降低神经网络的训练成本,提出了基于弱监督学习的语义分割方法,实现通过使用一些低成本的训练数据,使神经网络达到相对精准的分割效果。
弱监督语义分割主要通过一些简单形式的标签信息进行图像学习,以此来降低神经网络的训练成本。但是因为弱监督语义分割学习仅仅依靠一些简单的图像标签进行学习,语义信息不强,所以分割精度并不高。如何提高弱监督语义分割的精度,成为了深度学习的研究热点。
1 基于弱监督学习的语义分割方法
为了解决全监督学习分割网络的高成本问题,研究者们提出了基于弱监督学习的语义分割方法,使用弱标签图像数据进行网络训练,减轻网络模型对精确数据的依赖,降低数据的标注成本。根据使用标签类型的不同,我们可以将弱监督学习的图像语义分割方法分为以下几类:基于边界框的语义分割法、基于图像级标签的语义分割法、基于点标签的语义分割法和基于涂鸦式标签的语义分割法。
1.1 基于边界框的方法
边界框标注方法是使用一个矩形框选取图像中的目标区域作为标签信息。于标注方面来说,边界框标注的操作是弱标注方法中最为复杂的一种。但是,边界框标签包含更多的图像信息,得到的分割效果也更令人满意。Dai[1]等人提出了基于边界框标注数据的BoxSup算法,该方法首先使用MCG[2]获得初始的图像目标候选区域,然后不断迭代对象目标的候选区并调整神经网络参数,提升分割网络的性能。Papandreou[3]提出使用期望最大化法,将边界框标签与像素级标签结合的方式对分割网络进行训练,达到与全监督方法接近的分割效果。Khoreva等人[4]提出把弱监督问题看作是输入标签的噪声问题,试图使用递归训练去除噪声,加入GrabCut算法提升语义分割效果。基于边界框标签数据训练的弱监督网络无需大量精准的数据,而它的分割效果却能达到全监督网络的分割水平。
1.2 基于图像级标签的方法
图像级标签是弱监督学习中最简单的一种标注形式,它只提供了图像中存在的类别,并没有明确给出对象的位置和形状等信息,所以使用图像级标签训练的分割網络在语义分割中,得到的分割结果并不理想。但是因为图像级标签数据比较容易获得,所以众多专业人士均致力于图像级标签的语义分割方法的研究。Pathak[5]等人在训练过程中使用图像级标签数据,并利用多示例学习MIL解决语义分割的问题。随后Pathak[6]等又提出约束型神经网络模型CCNN,在损失函数中为对象尺寸、背景、前景等设置约束项,用最优化解决分割问题。Pinheiro[7]等人通过多示例学习构建图像级标签和像素级标签之间的关联,且添加一些平滑先验获得较好的分割结果。Wei[8]等人提出了从简单到复杂的框架STC,首先检测图像的显著性,然后增强分割网络,最后强化型分割网络和预测标签得到最终分割网络。随后,Wei[9]提出了对抗性擦除的方法,该方法通过不断擦除神经网络识别的显著区域,然后组合擦除的信息生成伪标注,提升分割精度。但是提出的方法都需要对网络进行多次训练,操作复杂且训练时间长。Kolesnikov[10]提出了SEC框架,使用CAM[11]对目标种子进行定位,然后对稀疏的种子像素进行扩展并约束,最后使用条件随机场CRF优化后得到了较好的分割结果。Huang[12]针对于SEC框架的静态监督问题做出了改进,使用迭代扩展的方式提高了目标分割的完整性和准确性。Zhang[13]等人利用解耦空间神经网络生成高质量的图像伪标签,并达到较好的分割效果。Li[14]等人提出了使用网络产生的关注区域来引导学习,最终产生较为准确的结果。Lee[15]等人提出了FickleNet框架,使用简单的dropout方法发现图像的位置关系,并扩大激活区域。熊昌镇[16]等人利用不同特征训练2个带尺度的分割模型,并结合迁移学习的分割模型改善分割结果。
1.3 基于點标签的方法
弱监督中的点标签是在对象目标上标注一点作为标签信息,但是点所包含的信息量是非常少的,仅凭一点作为监督信息是不足以使网络推断出整个对象的区域范围,因此分割结果也不令人满意。与图像级标签相比,点标签可以明确图像中对象的位置信息,所以分割效果有所提升。Bearman[17]等人使用点标记图像中的对象目标,然后将该描点信息结合损失函数,并加入对象目标的先验信息用以推断对象范围,使得网络模型能更好地预测物体区域。
1.4 基于涂鸦式标签的方法
涂鸦式标签是在目标对象位置以涂鸦线条方式作标记,得到对象的位置和范围信息。涂鸦式标签作为点标签的一种改进方式,可以进一步获取对象的范围信息,获得更好的分割结果。Lin[18]等人利用图模型优化的方式训练分割网络,将标注信息与其外观信息、语义信息等传递到图像未标注的像素。该方法实现了自动完成图像的标注工作,并获得模型参数,最终训练得到的网络性能媲美于边界框标签训练的分割网络。
2 弱监督学习方法评估
2.1 语义分割评估数据集
在语义分割研究中,常常需要大量的图像数据集对分割网络进行训练和测试,本小节将介绍在分割任务中,具有代表性的公共数据集PASCAL VOC2012、ImageNet、MS COCO、Cityscapes。
PASCAL VOC是一个计算机视觉挑战赛,它为计算机视觉提供测试图像数据集。在计算机视觉中,最常用的数据集是PASCAL VOC 2012,它总共有21类,其中包含了背景、动物、交通工具、人类以及一些常见的室内物品等。图片标注质量高且没有统一图像。其中Train/val数据包含了11530张图像,其中包括27450 ROI目标标注和6929个分割物体。
ImageNet数据集共有14197122张图像,分为21841个类别,每一类大约1000张图片。许多图像分类、目标检测、语义分割等任务都是基于该数据集。
MS COCO 有91种常见类别,数据集有328000张训练图,其中包含了2500000个标注物体。2014年发布了82783张训练图像,40504张验证图像,40775张测试图像。2015年的数据包括165482张训练图像,81208张验证图像以及81434张测试图像。
Cityscapes数据集有5000张高质量的像素级图像和20000张弱标注图像,涵盖了50个城市中不同环境、不同时间的街道场景。
2.2 评价标准
在语义分割任务中,常用像素精度、平均像素精度、平均交并比来评估分割性能。具体公式如下所示,公式中的k+1表示包括背景在内的k+1类。Pij均表示像素原属于类i却被网络模型预测为类j的像素量。而Pji表示像素原属于类j却被预测为类i的像素量。Pii则表示网络模型预测的像素类别与真实类别一致的数量。
以上几种评价标准中,因为MIOU简单且具有较好的代表性,所以大多数语义分割分割方法均以此判别分割的性能。
3 结果分析
在本节内容中,将对上文提及的弱监督学习的语义分割网络在数据集上的表现进行分析。本文以PASCAL VOC 2012 数据集为测试数据,并以MIOU作为语义分割方法的评价指标。
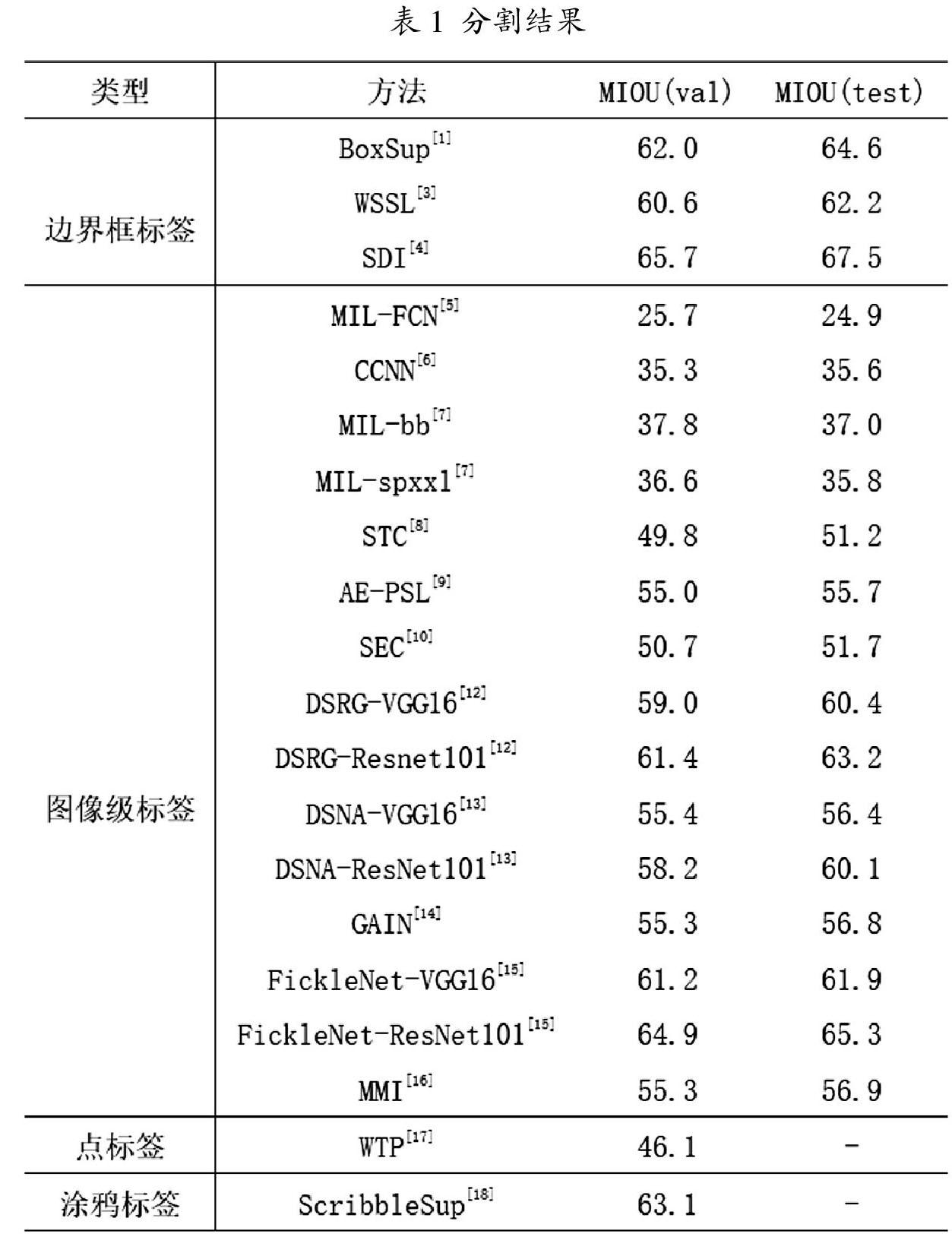
表1对弱监督学习下的语义分割方法进行了归类,比较了各种方法在PASCAL VOC 的验证集和测试集上的分割结果。从表中可以看出,虽然图像级标签比较容易获得,但是它包含的有用信息过少,不足以获得准确的分割结果。而边界框标签的形式虽然比较复杂,但是能够提供目标位置以及范围的监督信息,所以在弱监督学习方式中,具有较好的分割结果。
4 结束语
本文对基于弱监督学习的图像语义分割方法进行了综述,总结了不同方法在相同数据集上的分割效果。然后介绍了在语义分割领域常用的数据集和评价标准等。虽然现在弱监督的网络模型的分割结果依旧弱于全监督分割网络的结果,但是弱监督分割网络大大减少了数据集的标注要求,降低了研究成本,是未来语义分割的发展趋势。
基于现有的成果,提出今后可能的发展方向:
(1)构建稀疏的弱监督信息与像素之间的联系,使得网络能预测对象目标的精确位置和完整的范围,提升弱监督的分割精度。
(2)弱监督学习方式也可以考虑与其他学习方式的结合,解决弱监督学习中监督信息少而导致分割精度不高的问题。
参考文献:
[1]Dai, J, He K, Sun J. Boxsup: exploiting bounding boxes to supervise convolutional networks for semantic segmentation[A].Proceedings of the IEEE International Conference on Computer Vision[C].2015:1635-1643.
[2]Arbeláez P, Pont-Tuset J, Barron J, et al. Multiscale combinatorial grouping[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2014:328-335.
[3]Papandreou, G, Chen L C, Murphy K, et al. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation[A]. Proceedings of the IEEE International Conference on Computer Vision[C].2015:1742-1750.
[4]Khoreva A, Benenson R, Hosang J,et al. Simple does it: weakly supervised instance and semantic segmentation[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2017:876-885.
[5]Pathak D, Shelhamer E, Long J,et al. Fully convolutional multi-class multiple instance learning[A]. Proceeding of IEEE International Conference on Learning Representations[C].2015:1-4.
[6]Pathak D, Krahenbuhl P, Darrell T. Constrained convolutional neural networks for weakly supervised segmentation[A]. Proceedings of the IEEE International Conference on Computer Vision[C].2015:1796-1804.
[7]Pinheiro P O, Collobert R. From image-level to pixel-level labeling with convolutional networks[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2015:1713-1721.
[8]Wei Y, Liang X, Chen Y, et al. Stc: a simple to complex framework for weakly-supervised semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(11):2314-2320.
[9]Wei Y, Feng J, Liang X, et al. Object region mining with adversarial erasing: a simple classification to semantic segmentation approach[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2017: 1568-1576.
[10]Kolesnikov A, Lampert C H. Seed, expand and constrain: three principles for weaklysupervised image segmentation[A]. European Conference on Computer Vision[C].2016: 695-711.
[11]Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2016: 2921-2929.
[12]Huang Z, Wang X, Wang J, et al. Weakly-supervised semantic segmentation network with deep seeded region growing[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2018: 7014-7023.
[13]Zhang T, Lin G, Cai J, et al. Decoupled spatial neural attention for weakly supervised semantic segmentation[J]. IEEE Transactions on Multimedia, 2019,21(11):2930-2941.
[14]Li K, Wu Z, Peng K C, et al. Tell me where to look: guided attention inference network[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2018: 9215-9223.
[15]Lee J, Kim E, Lee S, et al. FickleNet: Weakly and Semi-supervised Semantic Image Segmentation Using Stochastic Inference[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2019:5267-5276.
[16]熊昌鎮,智慧.多模型集成的弱监督语义分割算法[J].计算机辅助设计与图形学学报,2019,31(05):800-807.
[17]Bearman A, Russakovsky O, Ferrari V, et al. What's the point: semantic segmentation with point supervision[A]. European Conference on Computer Vision[C].2016: 549-565.
[18]Lin D, Dai J, Jia J, et al. Scribblesup: scribble-supervised convolutional networks for semantic segmentation[A]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition[C].2016:3159-3167.
猜你喜欢
中国科技纵横(2016年20期)2016-12-28
经济研究导刊(2016年30期)2016-12-24
电脑知识与技术(2016年27期)2016-12-15
时代金融(2016年29期)2016-12-05
科学与管理(2016年5期)2016-12-01
中国市场(2016年40期)2016-11-28
商(2016年33期)2016-11-24
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
中国市场(2016年38期)2016-11-15
中国市场(2016年33期)2016-10-18
