
融合敏感词规则和字符级RCNN模型的用户意图识别
2020-03-13 10:56刘全明
计算机应用与软件 2020年3期
王 冲 张 虎 王 鑫 刘全明
(山西大学计算机与信息技术学院 山西 太原 030006)
0 引 言
近年来,随着自然语言理解和深度学习技术的快速发展和广泛应用,人机对话已成为自然语言处理领域的一项重要研究任务,已引起学术界和企业界的广泛关注。目前国内外相关学术会议例如SIGIR2018、ICTIR2017、EMNLP2018和SMP2018等都开展了人机对话研究的分组研讨或公开评测,专门就人机对话技术和应用展开了深入交流,这些会议促进了人机对话技术的发展,推动了语音识别、信息检索和自动问答等技术在人机对话系统的深入应用。当前很多公司也专门开展了人机对话的应用研究,将人机对话技术应用到企业客服、个人事务助理、虚拟情感陪护机器人以及娱乐性聊天机器人等产品,典型的产品有Amazon Echo、Google Home、Microsoft Cortana、百度小度、阿里的天猫精灵等。
经典的人机对话系统一般包括三个主要部分:用户意图识别、用户对话管理和自然语言生成。其中用户意图识别是人机交互系统能否进行准确、有效对话的一个首要基础环节[1]。然而,由于人机对话中对话环境的复杂性及用户输入方式的多性样,对话系统经常对用户意图识别出错,大大影响了交互的体验。因此迫切需要针对人机对话中的用户意图识别任务提出更有效的解决办法。
目前意图识别的典型方法是将意图识别任务转化为意图的自动分类任务。即在给定意图类别体系的情况下,通过提取特征、训练分类模型来实现对意图的自动识别[2]。例如用户输入“你好啊,很高兴见到你!”,系统将其分到闲聊类;输入“我想订一张去北京的机票”,系统将其分到“订机票”类;对于“我想找一家五道口附近便宜干净的快捷酒店”,将其分为“订酒店”类。
国外的研究人员早期曾提出使用句子相似度进行用户意图的识别[3]。国内研究人员将特征扩展思想引入意图识别研究中,即引入额外的信息挖掘文本所表达的含义来辅助分类[4]。这些研究都在特定数据集上取得了有效的结果,然而由于这些意图识别方法大都基于模板匹配或人工特征集合,不仅费时费力、扩展性差[5],还经常由于意图识别错误出现答非所问的情形。
针对上述方法的不足,本文考虑了人机对话文本的长度短、噪声大和容易出现分词错误等特点,构建了融合敏感词规则和字符级RCNN的双层意图识别模型。首先基于部分对话文本类别词明显的特点构建了敏感句子及敏感词词典,并通过规则及相似度匹配策略对特征明显的对话进行了意图识别;然后针对类别特征不明显的对话提出了深层语义分类模型,该模型以单字符串作为输入序列,利用RCNN模型构建了意图分类框架,既可以避免分词结果不准确带来的错误传导问题,同时利用字符的分布向量表示方法还可以获取句子的深层语义信息。
1 相关工作
1.1 意图识别
意图识别是人机对话系统中一项重要的研究内容,其任务本质是对用户输入的语句自动标注一个预先定义好的类别标签[6]。以往针对用户意图识别的研究主要集中在利用支持向量机(Support vector machine,SVM)、条件随机场(Conditional random field,CRF)等传统机器学习技术,并结合n-gram等语言模型的方法[7-8]对用户意图进行分类,这些方法都是采用较为复杂的人工特征,如语法信息、韵律信息和词汇信息等,较难捕捉文本的深层语义信息。
随着深度学习技术的不断发展,越来越多的研究者开始利用深度学习方法解决自然语言处理领域中的问题,基于深度学习技术的用户意图识别任务也开启了新的发展阶段。Liu等[9]使用基于注意力的循环神经网络进行意图识别,用户语句中每个词在RNN中都有对应的隐藏状态,利用这些隐藏状态生成最后的意图类别。Ding等[10]受Collober等[11]提出的CNN网络结构的启发提出了基于卷积神经网络(CNN)的消费意图挖掘模型(CIMM)来识别用户的消费意图。CIMM模型首先用一个卷积层将一个上下文窗口中的每个词映射成相应的上下文特征向量,接着用一个最大池化层提取上下文特征向量中的最大值,将池化之后的向量拼接形成句子级的特征向量,最后将句子级特征向量作为前馈神经网络的输入进行一系列的非线性变换,进而实现了消费意图分类。此外,还有一些学者尝试使用深度置信网络(deep belief network,DBN)及深度凸网络(deep convex network,DCN)[12-13]进行了用户意图识别。
1.2 字符级神经网络
相关研究表明,在文本分类任务中可以通过字符嵌入来得到更加丰富的文本语义表示[14]。一种方法是利用外部词汇如WordNet来丰富单词嵌入,另一种方法是将字符嵌入融入到词嵌入中。Zhang等[15]设计了字符级文本分类的卷积神经网络模型,与传统的基于词的卷积神经网络模型及循环神经网络相比取得了更好的效果。Kim等[16]于2015年也提出使用字符级卷积神经网络提取字词信息,其输出被用作循环神经网络语言模型(RNN-LM)的输入,在词法更丰富的西班牙语数据集上,性能优于传统的词级LSTM,同时参数也减少了60%。Santos等[17]用英文短文字符序列作为处理单元,分别学习文字的单词和句子特征,以此提高短文分类的准确性。显然,从字符层面进行文本嵌入提取出抽象的文本表示的好处是不需要使用预训练好的词向量等信息,可以尽可能保存原文信息,自然地学习诸如拼写错误和表情符号之类的异常字符组合。此外,字符级神经网络还可以较容易地推广到其他语言。
2 意图识别模型
2.1 意图识别框架
本文提出的意图识别方法主要分为两个层次:基于敏感词规则的意图识别和基于字符级RCNN模型的意图识别。具体的意图识别流程如图1所示。
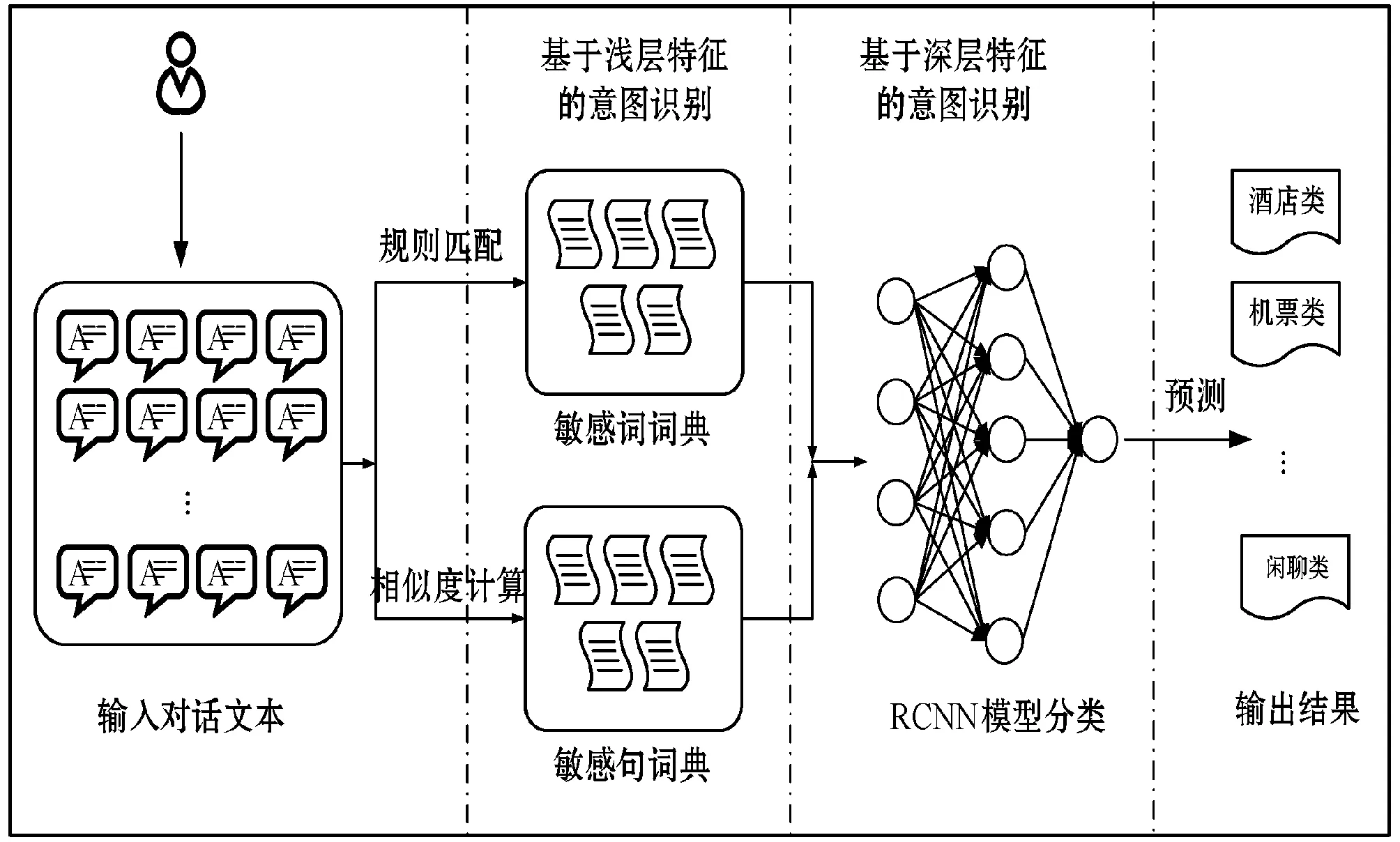
图1 意图识别流程图
1) 基于敏感词规则的意图识别。利用句子类别词比较明显的数据集统计分析各个类别的敏感词,结合外部网络资源,搜集个别类别的常见关键词,如邮件类、机票类、股票类等,经人工筛选后构建敏感词词典,具体数据样例如表1所示;同时还可以针对每个类别构建敏感句词典。意图识别过程首先利用敏感词典,并通过规则及相似度匹配策略对特征明显的对话进行意图识别。
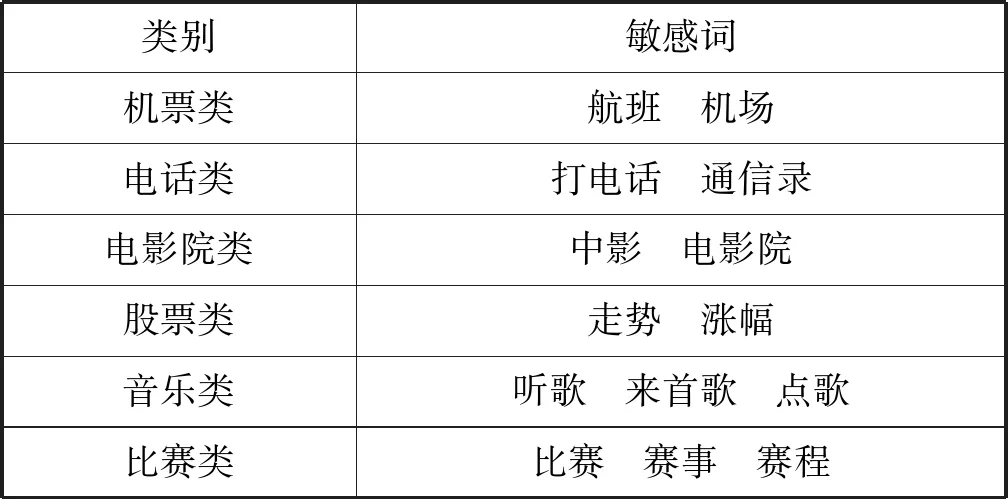
表1 敏感词表
例如用户输入“给张三打电话”、“帮我查询下午去北京的航班”,通过敏感词表中的敏感词“打电话”、“航班”,可以将其归属到电话类及机票类。
2) 基于字符级RCNN模型的意图识别。将前一层未能识别的类别特征不明显的对话输入到字符级RCNN模型进行分析,得到最终的意图识别结果。
2.2 字符级RCNN模型
对用户意图进行分类,首先要对数据进行预处理,包括字词切分、停用词去除等步骤。传统的分类模型通常选择文本自动分词后的词特征,而基于分词的词语集合构建的文本分类词特征集经常由于分词出错,容易导致模型学习到错误的特征,会大大降低模型的准确率。
例如使用分词工具对“宫保鸡丁怎么做”和“富春山居图电影”这两句话进行分词,分词结果为“宫保鸡/丁/怎么/做”和“富春山/居图/电影”,其中“宫保鸡丁”错误分成“宫保鸡/丁”,“富春山居图”错误分成“富春山/居图”。以上例子采用传统的1-gram分词结果进行特征选择时,候选特征会从{宫保鸡,丁,怎么,做}、{富春山,居图,电影}这些结果选择,显然此时分类器基于这个词语集合会学习出错误的关键词特征,并最终影响模型的实验结果。
因此,本文进一步提出基于字符级的RCNN模型。使用神经网络处理数据时需要将其表示为分布式向量,因此模型首先输入用户语句的字符嵌入,通过LSTM层后将其输出加入到卷积层,然后卷积层的输出通过最大池化层及全连接层汇集到较小的维度,输出类别标签,模型具体结构如图2所示。
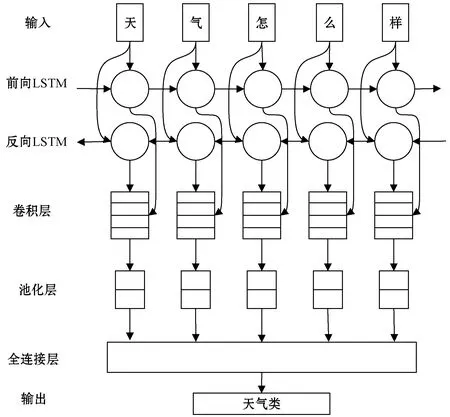
图2 字符级RCNN模型图
1) LSTM层不仅保存当前的信息,还可以存储任何以前的信息,所以LSTM层可以为原始输入生成新的编码。它由一系列重复的时间模块组成,每个模块包含:遗忘门、输入门、输出门和一个记忆细胞结构Ct∈R。输出是ht、ct,wf、wg、wo、wi为LSTM权重矩阵,bf、bg、bo、bi为LSTM的偏置,σ为激活函数sigmoid,⊙为点乘操作。在LSTM层中的更新方式如下:
it=σ(wixt+uiht-1+bi)
(1)
ft=σ(wfxt+ufht-1+bf)
(2)
ot=σ(woxt+uoht-1+bo)
(3)
gt=tanh(wgxt+ught-1+bg)
(4)
ct=ft⊙ct-1+it⊙gt
(5)
ht-1=ot⊙tanh(ct)
(6)
2) 卷积层的目的是应用卷积运算,提取任意输入矩阵W隐含高阶特征的过程。通过不同高度卷积核Cl,a在W上滑动计算,得到不同卷积核的卷积序列,卷积序列构成特征面hl,a,其中l表示卷积核高度,a表示文本向量维度。hl,a实际是利用输入矩阵W与Cl,a进行内卷积的结果集,再加上偏置bl,a得到的结果,表示为:
hl,a=f(X×Cl,a+bl,a)
(7)
式中:f是激活函数tanh,用于对卷积结果作平滑。其目的在于为神经网络引入非线性,确保输入与输出之前的曲线关系。
3) 池化层就是对高维的特征面集合进行降采样操作,进行特征的二次提取。池化操作一般有两种:平均池化和最大池化。本文采用的是最大池化,也就是选取每个特征中的最大值,将池化得到的所有最大值拼接起来,得到一个特征向量。
4) Dropout是防止神经网络过拟合的技巧,其主要思想是在训练过程中临时从网络结构中以概率p随机移除部分神经元以及对应的输入输出权重。
最后使用softmax函数进行分类得到意图识别结果。
3 实验及结果分析
为了验证所提方法在用户意图识别中的可靠性,本文分别在两个数据集上进行了多组对比实验,并对实验结果进行了错误分析。
3.1 数据集
针对用户意图识别研究,目前没有标注好大规模数据集,因此本文选取的两组数据集分别为SMP2017(中国社会媒体处理大会)人机对话技术评测中用户意图分类的数据和从百度知道上抓取的问答数据。Broder[18]曾提出根据用户行为对用户的意图进行分类,分为导航类、事务类、信息类。在此基础上,SMP2017所标注的类别将其进行细分为31类,基本可以涵盖用户的所有意图。因此,可以使用用户行为类别对用户意图进行表示。数据的样例如表2所示,两种数据集规模如表3所示。
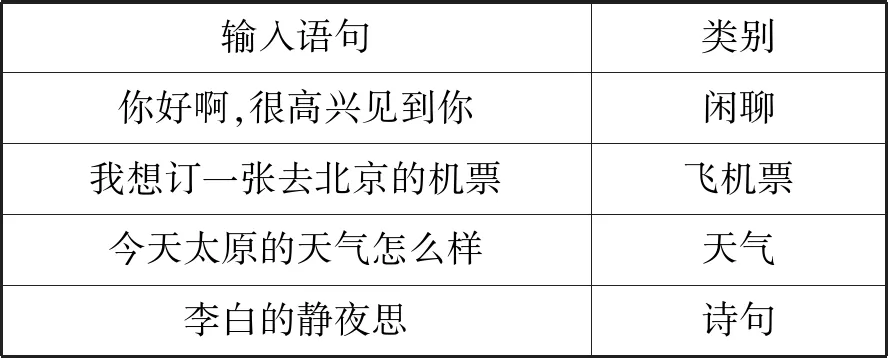
表2 数据样例
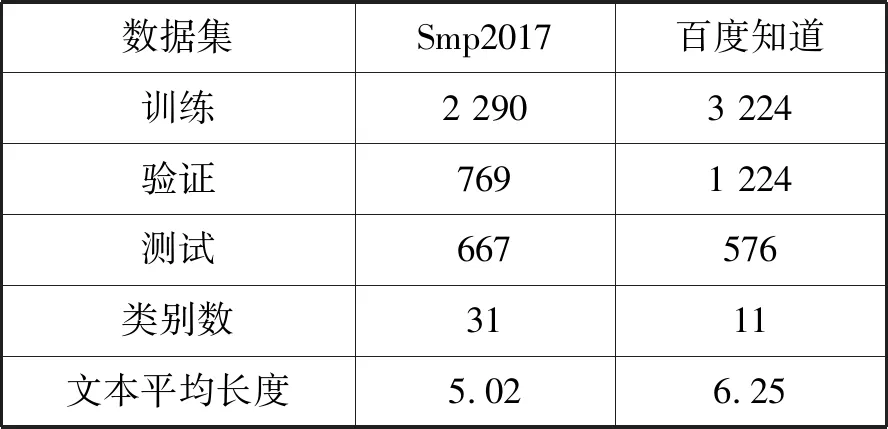
表3 数据集规模
3.2 基线模型
为了从不同的角度来验证本文提出的模型在用户意图识别任务中的适用性和有效性。实验采用了几个典型文本分类模型作为基线。
N-gram+SVM:使用n-gram来提取输入特征,并使用SVM作为分类器,得到意图识别结果。
Char-CNN:使用字符级特征作为神经网络模型的输入,通过CNN作为分类模型得到意图识别结果。
CNN-LSTM:使用词级特征作为卷积神经网络输入,提取局部代表性特征,然后按照卷积先后顺序重新组合,再依次输入LSTM中进行上下文学习,得到意图识别结果。
Text-GCN[19]:在整个语料集上构建图,将词及文档作为图中的节点,利用共现信息重构边,将用户意图识别看作节点分类,以此得到预测结果。
3.3 评价指标
本文采用准确率(Precision,P)、召回率(Recall,R)和F值(F-measure,F)作为实验评价指标。假定a表示被正确分到某类的文档数,b表示错分到该类的文档数,c表示属于该类但被错分的文档数。则准确率、召回率和F值可分别按照如下公式计算:
(8)
(9)
(10)
3.4 实验设置及结果
基于SVM的意图识别模型选取1-gram、2-gram和3-gram的组合作为特征集。
对于其他基于深度学习的意图识别模型,采用skip-gram模型预先训练嵌入大小为64的字嵌入,将LSTM的隐藏状态大小设置为100,CNN的过滤器宽度设置为(2,3,4,5),每个过滤器大小为25。使用Adam作为优化器,并将学习率设置为0.01,丢失率为0.5,批量大小为64。
从表4可以看出,本文提出的融合敏感词规则和字符级RCNN模型的意图识别方法优于所有基线,在两个数据集上的F值分别达到了91.2%和90.7%,可以较好地实现用户意图识别任务。在没有使用分词、句法分析等辅助标注工具下,模型能够自动抽取出文本深层次特征,在实际应用中不仅可以简化繁琐的特征抽取过程,而且避免了词法、句法分析的错误传导,减轻了特征选择对识别结果的影响。
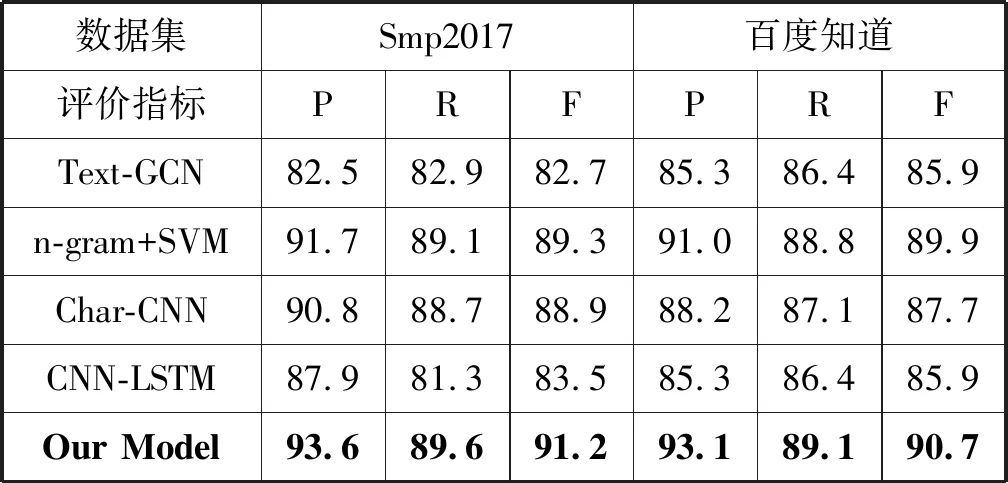
表4 基于两种数据集的实验结果 %
3.5 错误分析
在实验过程中发现,在对SMP2017数据进行分词处理时,切分正确率为80%,且存在较多未登录词切分错误,从而一定程度干扰最后对用户意图的分类效果,因此基于词级的CNN-LSTM模型结果低于本文模型,同时是可见的。Text-GCN表现不好的原因可能在于本任务中短文本较多,导致GCN构图时文档-词、词-词之间边比较少,同时GCN忽略词的顺序,导致学习的文档向量及词向量区分度不大。
为了进一步分析本文模型的性能,将其预测结果输出进行错误分析,列出了部分具有代表性的分类错误样本,如表5所示。
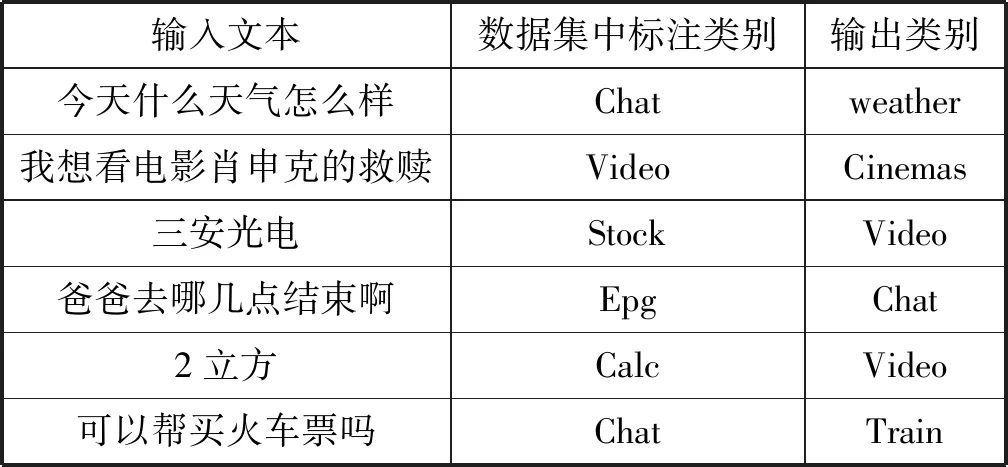
表5 意图识别错误的部分样本
经过统计将预测错误样本分为三类:
1) 测试数据样本类别标注错误导致预测错误。表4中“今天什么天气”、“可以帮买火车票吗”等属于样本类别标注有误。结合训练数据与类别真实含义来看,模型输出的意图识别结果更准确一些。
2) 样本语义多样性导致预测错误。例如“我想看电影肖申克的救赎”、“爸爸去哪几点结束啊”等样本属于多个类别。
对于“我想看电影肖申克的救赎”,如用户本意是想在线播放,则前一句应属于video;若是想去影院看,则应属于cinemas。在这种情况下,仅根据文本的信息无法做出可靠的正确分类。因此对于类似对话语句,在实际应用中需结合额外的场景信息或用户的上下文信息来作出判断。
3) 数据集过少导致预测错误。由于训练样本数据规模较小,而某些类别有大量的领域相关词汇,给定的训练样本无法覆盖该类别的所有语义场景。因而导致模型无法分清“三安光电”是股票还是视频,“2立方”是数学知识还是视频。
针对这类错误,提升训练样本的数量是一种有效的方法,在此基础上还可以引入类别相关知识,通过构建股票名表、常见数学名词表等知识库可以达到精确的意图识别。
4 结 语
针对人机对话系统中用户对话常为短文本的特点,本文将用户意图识别任务转化为短文本分类任务,并在此基础上提出了融合敏感词规则和字符级RCNN模型的用户意图识别方法,分别利用多个基线模型在两类数据集上进行了对比实验,验证了本文提出方法的有效性。接下来我们将在更加开放的领域和更大规模的数据集上进行测试,同时考虑attention机制在其中的影响,并扩展基于字符级特征的思想,探索在其他问题上的应用。
猜你喜欢
法律方法(2022年2期)2022-10-20
汽车实用技术(2022年14期)2022-07-30
福建基础教育研究(2022年4期)2022-05-16
少儿画王(3-6岁)(2020年4期)2020-09-13
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
东方教育(2018年20期)2018-08-22
农机使用与维修(2014年10期)2014-10-23
延河(下半月)(2014年3期)2014-02-28
