
一种区块链实用拜占庭容错算法的改进
2020-03-11 12:51韩镇阳宫宁生任珈民
计算机应用与软件 2020年2期
韩镇阳 宫宁生 任珈民
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
0 引 言
Satoshi Nakamoto(中本聪)[1]在2008年初次提出了区块链技术概念,这一技术的产生实现了真正意义上的去中心化可信任的数字货币交易系统,其本质是分布式系统,具有去中心化与安全可信的特点。随着区块链技术不断发展,共识算法也逐渐被研究人员所重视,其中共识算法如何选择是区块链设计的核心部分[2]。共识算法的研究很早便已经开始,例如工作量证明(Proof of Work,POW)[3]、权益证明(Proof of Stake,POS)、实用性拜占庭容错算法[4]以及Raft算法[5]等。拜占庭共识算法起源于古罗马时代的拜占庭将军问题,简单来说这是分布式一致性的问题,拜占庭将领们必须所有人统一协商是否在某一时刻对敌人发起进攻。假如将领中存在背叛者,背叛者会发出虚假消息来迷惑其他将领们的进攻,将领们怎样在存在背叛者的前提下达成统一的决定,并最终攻下敌军正是问题的核心内容。拜占庭容错算法,在分布式系统领域可以阐述为:怎样在存在作恶节点的系统中确保系统运行状态良好以及数据信息的真实性、一致性和完整性,并且作出正确的决定。
20世纪80 年代,Leslie Lamport等通过拜占庭将军问题提出了著名的拜占庭容错(Byzantine Fault Tolerance, BFT)算法。与Bitcoin的“挖矿”工作量证明POW共识算法不同,BFT 类协议通过各个节点相互发送消息对提案和指令达成最终统一的共识结果,然而正是由于这些特点造成了节点之间消息递归传递呈指数级复杂度,加上节点的加入和退出这一步骤需要进行特殊处理,BFT算法并不太具有实际操作性。虽然这一算法存在很多缺点,但是它在解决拜占庭问题上给出了一种新型的思路,不像POW那样消耗大量的公共电力资源,为后来实用性拜占庭容错算法PBFT的出现作了铺垫。
1999年,Miguel Castro和Barbara Liskov等提出多项式级别的实用性拜占庭容错算法改进于拜占庭共识算法BFT,继承了它的优点,并且大规模降低了拜占庭协议的开销,因此拜占庭算法在区块链系统中能够被应用。PBFT算法是基于状态机副本复制的算法,每个状态机副本都能保存服务状态,满足用户的合法请求,不仅可以完成交易,还能够实现不同类型的操作。系统中最多可以满足f=(N-1)/3(N为节点总数)数量的作恶节点,这样仍能保持系统的安全性和活性[6],最终达成一致的分布式共识。
目前的PBFT算法还存在很多不足,随着大规模区块链系统的发展和兴起,研究人员逐渐着眼于怎样简化实用性拜占庭协议的设计,优化拜占庭协议的性能,用来提高容忍数据产生的多种错误。首先,PBFT算法采用C/S架构[7],不能动态感知节点数目的变化,更不能应用于P2P[8]网络模型,如果想要增加节点,系统必须重启,造成系统资源不必要的浪费,影响实用性和用户体验,尤其在某些应用中经常性的系统重启是非常致命的。在主节点选举上也没有对主节点的真伪性进行验证,因此很有可能选举出恶意节点并且具有非常高的危险性。三阶段协商中高强度的网络通信和网络传输开销同样需要进一步的改进优化。PBFT协议中的视图转换算法中存在漏洞,客户端重复请求会导致视图不停地进行变更,从而影响正常的服务,甚至陷入宕机,如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。
本文在比较分析一些已有的经典共识算法后,基于传统PBFT算法提出了一种能够减少开销、增大吞吐量的改进拜占庭共识算法IPBFT,实现了协商节点与执行节点分离。传统的实用性拜占庭容错算法需要3f+1个节点,但是如此多的节点会产生一定浪费,因为执行客户端请求的节点只需要很少一部分。因此,可以将协商与执行请求分开,一部分节点负责协商请求,一部分节点负责执行请求,对于执行时间较长的请求,降低执行请求的节点的数量能够提升系统吞吐率。IPBFT 算法中主节点的选举方式在依据节点编号选举方式的基础上改为心跳检测机制并结合最大视图号和最大编号请求的节点选举,也就是心跳检测以及最长链选举,使得主节点的选举方式更加合理,选举出的主节点更加具有稳定性和安全性。在一致性协议中,加入了自证机制,进一步减少了拜占庭节点的作恶几率,提高了系统的稳定性。为了解决PBFT在视图变更算法中存在的问题,IPBFT算法结合协商与执行分离原则,引入了怀疑-证明机制,IPBFT算法中的副本节点将主动检查每条消息序号的准确性。系统设置超时机制,如果主节点失效或者恶意节点不发送客户端的请求,向所有副本节点发送请求消息。当主节点被副本节点检测出失效或者是恶意节点时,系统将发起视图转换协议View Change。
1 相关工作
1.1 传统共识算法
在区块链系统中,共识算法如何选择非常重要,算法的核心是在区块链系统中利用共识算法来保证整个系统的一致性。目前,区块链中主流的算法主要包括工作量证明(PoW)、权益证明(PoS)[9]、实用拜占庭容错算法(PBFT)以及Paxos算法的变种算法Raft、Algorand算法等。不同的算法具有不同的优劣势,适用于不同的应用中。
1.1.1工作量证明
PoW是首个应用于区块链的共识算法,由Satoshi Nakamoto在他的论文中提出,用以创立分布式去中心化无信任共识的机制,并且能够解决双重花费的问题。PoW不是一个全新的理念,只是Nakamoto将工作量证明算法与Merkle Tree、数字签名和P2P网络等一些已知的技术联系起来,产生了一种具有实用性的分布式共识系统。Bitcoin采用的就是PoW共识算法来确定区块链网络的一致性,目前为止PoW被认为是最具有安全性的公有链共识算法。它的核心技术是根据节点的算力来竞争并使得数据能够达成一致,并且共识的安全性能够得到保证。在比特币中,矿工们根据计算机的性能算力竞争求解一个非常复杂的SHA256哈希函数,但是这个哈希函数很容易被验证,能够首先解决这个哈希函数的节点可以得到下一区块的记账权,以及系统自动生成的奖励——比特币。PoW 共识也有着明显的缺点,PoW算法所需要的强大算力造成的资源浪费是它最主要的问题。其次假设敌对者控制了全网51%以上的的节点,敌对者就能在系统中伪造区块信息,甚至不需要51%的节点区块链系统也会受到攻击。长达十分钟的交易确认时间过长,同样也不适用于商业应用。
1.1.2权益证明
2012年出现的点点币PPC第一次应用了PoS权益证明共识算法。在系统中拥有最高权益而不是最高算力的节点可以得到记账的所有权,PPC是PoW和PoS这两种算法结合的结果,刚开始时PoS算法使用的是PoW中的挖矿方式,这样Token将会被公正地分配给矿工,到了后期因为挖矿难度增加,PoS将接管整个系统的算法维护。相对于PoW算法,PoS减轻了资源的浪费问题,交易确认时间也大大减少,所以比特币产生之后,很多数字货币采用的都是PoS共识算法。PoS算法的缺点是核心权益掌控者在一定程度上违背了分布式账本去中心化的初衷。
1.1.3Raft算法
Paxos算法由Leslie Lamport在1990年提出,具有高度容错性,其复杂的原理和算法非常难懂也难以实现,于是就有了Paxos的简化版——Raft 算法。领导者、跟随者和候选人是Raft算法中的三种主要节点,随着时间和环境的变化它们能够相互转换。Raft算法主要有两个过程:日志复制和领导者选举。日志复制又被分为两个阶段:记录日志和提交数据。(N-1)/2是系统中能够承受的最大的故障节点数量(N为总节点数)。但是,Raft算法是面向数据而不是面向交易的,只支持容错故障节点,而不支持容错作恶节点,没有考虑到系统中作恶节点存在的情况,加入系统中的作恶节点发送恶意消息,整个系统将会存储恶意错误的信息。
1.1.4Algoand算法
Algorand[10]算法可以避免区块链分叉,确认交易的时间也将大大减少,算法的总流程主要由两个部分组成:BA*和块提议。拜占庭协议BA*是Algorand算法中的核心技术,具有很强的扩展性,用户只能够保留私钥。在块提议中,根据加密抽签选举的方式在普通节点中选择出委员会成员,接着从委员会成员中再次以加密抽签选举出提议者,每个提议者都拥有提议块的权利。然后连同哈希和证明一起传播到网络上。根据BA*协议,当所有委员会成员接到同样的消息后对块达成共识。
1.2 PBFT算法
PBFT算法旨在解决如何在整个系统中存在作恶节点的情况下依然能保证最终决策的一致性和正确性的问题,该算法给传输来的消息进行共识,得到一个全局的序。在恶意节点不高于总数1/3的情况下,该算法能够同时保证安全性(Safety)和活性(Liveness)[11],该算法首次将拜占庭容错算法复杂度从指数级降低到了多项式级O(N2)。PBFT算法中所有节点被分为客户端、主节点和副本节点三种类型,流程被分为一致性协议、视图变更协议和检查点协议。其中一致性协议又被分为三个阶段:预准备阶段(PRE-PREPARE)、准备阶段(PREPARE)和确认阶段(COMMIT)。具体过程如图1所示。
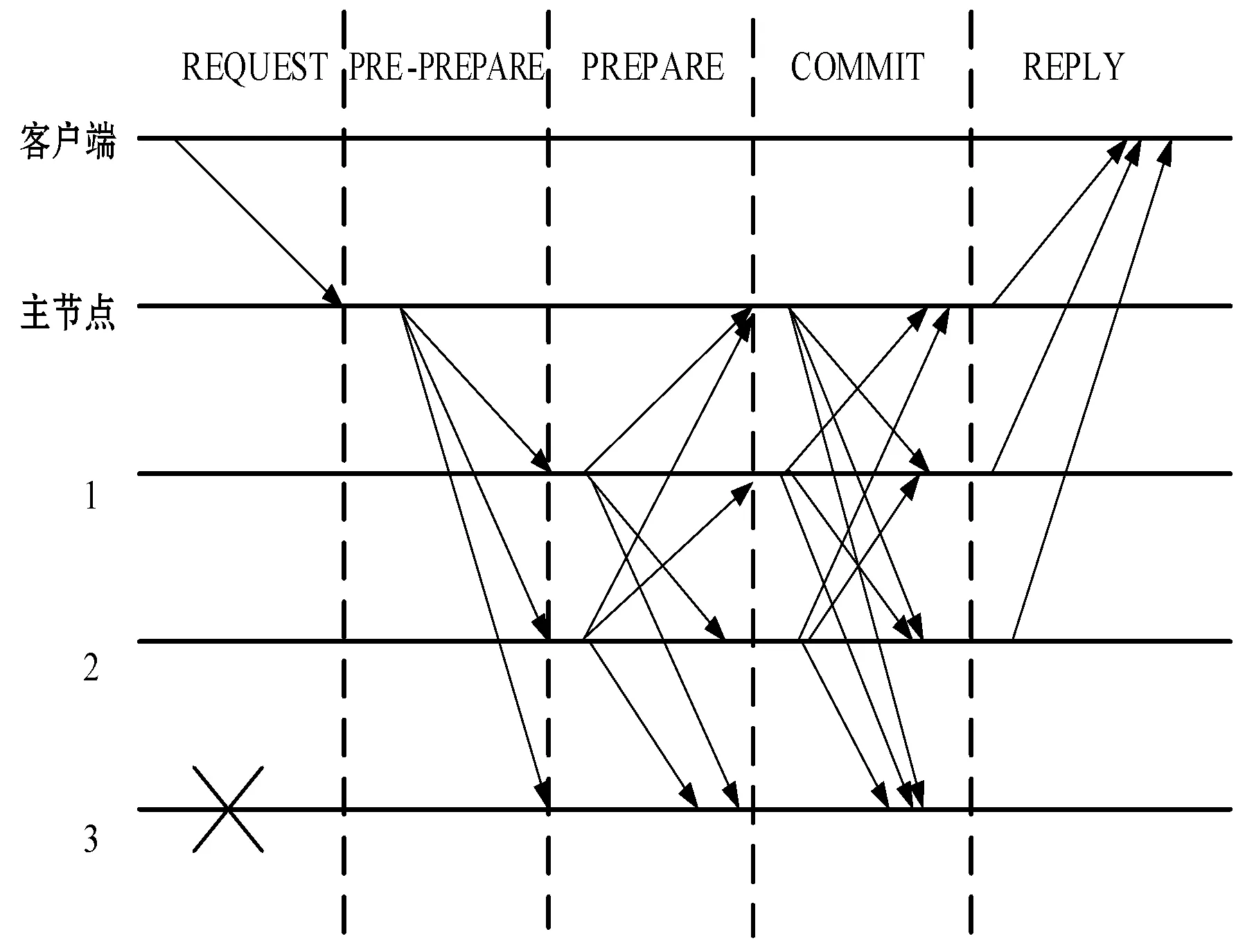
图1 PBFT一致性协议算法流程图
当客户端收到了至少N+1个节点的结果是相同的情况下,才认可最终结果有效。PBFT算法针对分布式系统并且按照系统中的指令顺序执行,其基于C/S架构。一致性协议的整个过程分为三个阶段,具有三次信息的广播,因此网络的带宽一定会有浪费,尤其是后两次的全节点广播,非常消耗网络带宽,在区块链系统中,若请求消息过于频繁很容易造成网络拥堵。在传统PBFT算法中完成一次三阶段共识过程共需要传递的消息次数M为:
M=2N2-2N
(1)
由式(1)可知,消息传递的次数随着集群中节点数目增大急剧增多。
客户端只可以向主节点发送信息,如果请求消息太多容易造成主节点负载过大,效率将大大降低。主节点的选取不具有安全性,假如连续选取的主节点都是恶意节点,将会导致系统资源的极大浪费并且降低系统安全性;在视图转换协议中PBFT算法存在被拒绝服务恶意攻击的可能,当发生客户端重复请求的恶意情况时,会使得视图不停地进行视图转换,影响正常的服务或者系统陷入宕机。如果主节点作恶,它可能会不去分配序号,为不同的请求编上相同的序号,或者产生本该相邻的序号不连续等情况影响系统的安全性。
2 IPBFT算法设计
2.1 协议常量定义
与传统拜占庭算法类似,改进的拜占庭算法IPBFT模型中视图view由编号v唯一标记某个视图,视图中的节点会被称为主节点或是领导节点(Primary),其余的节点都叫副本节点或是从节点(Backups)。
R是所有节点的集合,用一个整数来表示每一个节点,依次用{0,1,…,i,…,|R|-1}表示,集合R必须满足:
|R|=3f+1
(2)
式中:f是系统中可容忍的错误节点最大值。一个视图中的主节点为pi,主节点可表示为:
pi=vmod|R|
(3)
从0开始一直连续下去,当每次视图转换协议View Change发生时依次从主节点p0到主节点p|R|-1,来自客户端c的请求由主节点pi排序并根据序号发送给副本节点。
IPBFT算法结构一共分为三种:客户端、协商副本和执行副本。协商集群是协商副本的集合,执行集群是执行副本的集合。客户端的作用相当于转换端,可以与协商副本、执行副本同时进行交互,其中协商副本为传递来的请求分配序号,执行副本通过协商副本发来的指定序号执行请求,并且将结果返回客户端。
IPBFT算法由一致性协议、视图转换协议以及检查点协议三个子协议组成,其中:一致性协议组织各个群组执行请求;视图转换协议在当前的局部主节点发生错误时协调新的局部主节点;检查点协议能够减少视图转换协议执行的成本。
Lamport在1977年第一次描述了安全性(Security)与活性(Liveness)的概念,但目前传统拜占庭算法的安全性指整个系统在一定时间内所有已经完成的请求都不可能再被更改,但是它可以被后来的请求查询到,活性指的是系统可以执行非拜占庭客户端的请求,不会被任何因素影响而导致非拜占庭客户端[12]。
本文中安全性是指系统能够始终保持一致性并对任务进行长时间的原子操作,如果只依靠安全性并不能彻底解决拜占庭节点造成的损害,因为拜占庭节点没有限制的攻击会对任务本身造成影响,比如某个任务是在计算后对文件进行写入,而拜占庭节点通过向文件写入无意义的内容可能会导致任务失败。面对这种特殊情况,IBPFT算法把读写等敏感操作的权限交给节点完成,大大降低了风险。本文的活性指的是任务在一定的拜占庭节点数目的前提下,必会在规定时间内得出相同的一致性结果,即IPBFT算法会在有限时间内返回一个有效值。本协议对每个副本节点提出了两个限定条件:
(1) 非拜占庭服务器输入相同的信息,产生的结果一致。
(2) 当输入的信息正确,非拜占庭服务器接受信息并计算相应的结果。
2.2 算法流程
2.2.1一致性协议
(1) 主节点向客户端发送请求。客户端c请求系统执行操作o,客户端c向协商集群的每个副本节点广播请求消息〈REQUEST,o,t,c〉σc。在该消息中,o表示操作;t表示本地时间戳,可以保证该消息的时效性,时间戳是全序排列的,因为客户端发出的请求只有一次,后续比早先发出的请求时间戳序号更高;c为客户端。此时客户端设置2个计时器Timer1和Timer2并开始计时,Timer1用于收集执行副本j自证消息的返回时间,Timer2用于收集操作结果的返回时间。
(2) 主节点收到请求后向客户端发送自证消息。主节点p接收到请求消息〈REQUEST,o,t,c〉σc后,启动三阶段协商:包括FAST-PRE-PREPARE、FAST-PREPARE以及FAST-CONFIRM三阶段,并将其广播到剩余副本节点,执行副本j向客户端发送自证消息〈PRE-REPLY,v,t,n,j,r〉σj证明自己不是拜占庭节点,v是视图编号,n是消息序号,j是副本自身编号,r是请求执行后得到的结果response。
如果客户端c在Timer1范围内收到自证消息PRE-REPLY,客户端c将对收到的f+1个响应进行验证,首先验证消息签名、时间戳t和执行结果r是否一致,如果相同,r就被视为客户端的正确执行结果,失效的副本节点不超过f个,因此f+1个副本节点的一致响应保证结果是正确的。
如果客户端c没有在Timer1范围内收到自证消息,请求将向所有执行副本进行广播,如果该请求执行副本已经处理过,就向客户端重发一遍执行结果r。如果没有处理过,就把请求转发给主节点p要求重新发送请求。
(3) 快预准备阶段FAST-PRE-PREPARE。在快预准备阶段,主节点p分配一个序列号n给收到的请求REQUEST,然后协商副本k向执行副本j发送预准备消息,消息的格式为〈〈FAST-CONSULT,v,n,d,j,var〉σj,m〉,d是请求消息m的摘要,var是操作o的参数集,快预准备消息的序号n必须在水位(Watermark)上下限h和H之间,水位用于防止一个失效节点占用很大序号消耗空间资源,m是客户端发送的请求消息。该信息送达到各执行副本j后,首先验证m是否为一个完整的请求信息,n是否在水位之间,d是否为m的正确摘要,最大的n序列号是否增加1,v的序列号与自己所在的视图view编号是否一致,如果上述条件都满足,则表示执行副本接受了主节点p分配给该请求的这个编号n并将其加入日志中,它就会进入下面的FAST-PREPARE阶段。
(4) 快准备阶段FAST-PREPARE。在完成上述操作o后得到结果r,协商副本k开始向各执行副本j发送请求消息,内容为〈〈PREPARE,v,n,d,r〉σj,m〉。首先进行快协商阶段中的验证操作,在准备阶段,完成的标志为执行副本j将消息(m,v,n)记入其消息日志REQUEST-LOG,快协商消息m在视图v中的编号n,以及2f个从不同执行副本j收到的与快协商消息一致的准备消息。
只有在时间戳t大于tc的时候执行副本j才会接受请求并将请求加入到日志REQUEST-LOG中,tc为主节点p之前所接受过的最大时间戳。如果执行副本j在时间上限内未接收到请求消息,将向主节点p发送探测消息〈SEARCH-MES,v〉σj。如果主节点p回复探测消息,将再次激活计时器重新计时;否则触发视图转换协议。
(5) 快确认阶段FAST-CONFIRM 。当协商副本k发现有2f+1个执行副本同意编号分配时,协商副本就会广播出去一条确认信息〈〈FAST-CONFIRM,v,n,d,j,r〉σj,m〉到执行副本j,告知其产生了证书Prepared Certificate,执行副本j收到FAST-CONFIRM信息的节点达到2f条后进行验证,验证r是否与自己所得结果相同,m是否是一个完整的请求消息,d是否是m的正确摘要,v是否与自己保存的视图号相同。如果上述条件满足,则将该请求加入日志,该节点拥有确认证书Confirmed Certificate,表明执行副本j同意了编号n的分配,该请求就会被节点执行,接着广播发送〈REPLY,v,c,t,j,r〉σj到客户端c,如果不满足则拒绝,当执行副本j连续拒绝协商副本k两次时,启用视图转换协议。
(6) 主节点向客户端返回操作结果。正常情况下,如果客户端c接收到回复消息〈REPLY,v,t,c,r〉σj中f+1个结果是一致的,则表明结果r是正确的。
2.2.2主节点选举
主节点选举依据的是心跳检测机制和最长链原则,副本节点定期会向主节点发送一次Ping命令做一次心跳检测,规定在时间Down-After-Milliseconds内Ping连接成功,且在该集群中最后一个共识完成的拥有最大视图号且编号最大的节点作为主节点,视图号v与编号i存储的类型为long,视图v占据高32 位,编号i占据低32位,用vi表示选举过程:
系统初始化后,各节点都处于搜寻状态,并给自己投票,服务器收到所有其他节点投票后进行票选,更新自己的票数并广播出去,将其他节点广播来的选票信息存入选票日志中。票选可能产生以下有三种情况,分别是:(1) 收到的选票中最大vi小于自己当前的vi,忽略该选票。(2) 收到的选票中最大vi与当前vi相同,节点编号也一致,将选票信息存入选票日志中。如果编号不一致,则比较节点编号,如果当前节点编号较高,则忽略消息;否则清除选票日志,更新自己的票选信息并广播出去。(3) 收到的选票最大vi大于当前的vi,则直接清空选票日志并更新当前的vi,将自己的选票信息广播出去。
当选票日志中有不同节点的2f+1个目标相同的选票时,系统自动清除日志,向新的主节点发送确认信息。当主节点收到至少2f+1个来自不同节点的确认消息的节点成为准主节点进入待定状态。在选举完成后,副本节点要验证准主节点的合法性,发送验证请求消息〈SYN-ACK,v,vi,d,j〉σj,准主节点接收到消息后进行验证操作,首先检查视图号是否一致,对比区块编号尾部是否与vi一致,若一致则发送同步成功消息〈SYN-SYCCESS,v,d,j〉σj给该节点;否则将其丢弃,同时将来自其他节点的消息记录到日志中。当副本节点收到不同节点的2f+1个成功消息且消息中各项数据匹配后,验证成功,这样可以保证准主节点发送给每个副本节点的备份数据区块都是一致的,表示有足够的备份节点同意自己,这时准主节点正式成为主节点。
在票选的同时,副本节点会定期检测已经成为主节点的节点是否发生了故障,副本节点采用心跳检测机制,会在Down-After-Milliseconds时间内向主节点发送心跳Ping命令确认主节点是否存活,如果主节点在期间内不回应或者回复了一个错误的消息,那么这个副本节点会主观地认为这个主节点已经不可用,会要求其他副本节点确认该主节点是否丢失,如果超过2f+1个副本节点确认,则认为该主节点失效下线,重新进入选票阶段进行选举。
2.3 检查点协议
为了节省内存和系统安全性,系统需要删除日志中的无异议消息,而在执行副本删除消息日志前,必须保证至少有f+1个正确消息对应的请求,并且可以在视图变更时证明。如果执行副本错失部分请求消息而且这些消息已经被删除,要想实现同步就必须通过回滚部分甚至全部服务状态。
但是每一步都需要证明是十分损耗资源的,因此,证明过程只有在请求序号被检查点间隔Checkpoint_Interval整除的时候才会周期性地进行,例如:在传统的PBFT和zyzzyv等算法中,副本节点会收集2f+1个检查点消息作为证据,由于收集证据的计算成本太高,所以会在执行假设Checkpoint_Interval为100次的请求后进行证据计算,可以将这些请求执行后得到的状态称作检查点Checkpoint。
在本协议中,一旦执行副本j执行了主节点p发出的对n号请求的签名,它就会将自己的n号请求运算结果删除,主节点p在客户端收到了回复消息后也会将自己的n号请求运算结果删除。此外,如果执行副本j丢失了部分消息,也需要通过发送全部或部分服务状态来为其更新状态,这些状态由检查点提供,默认情况下,检查点创建间隔Checkpoint_Interval为200。
当协商副本k发现Checkpoint_Interval取余恒等于0时,触发检查点创建协议,按照如下步骤执行:协商副本k广播检查点消息:
〈〈CHECKPOINT,n′,d,j〉σj,〈SIGNATURE,v,n〉〉这里n′是上一个影响状态的请求序号,n为当前任务的序列号。执行副本j在各自的日志中收集并记录检查点消息,并且验证消息有效性,验证通过,添加到证书;否则,直接丢弃该消息。收到的来自2f+1个具有相同序号n和摘要d的消息组合成检查点的正确性证明,这些具有证明能力的检查点就是稳定检查点。之后开始状态回收,例如从日志中删除所有序号小于或等于n的快预准备、快准备和快确认消息,以及之前的检查点和检查点消息。检查点协议主要用于视图转换时为选取主节点提供依据,并且保持节点日志中的数据有序、有界。
2.4 视图转换协议
传统PBFT算法中的视图转换协议可能存在被拒绝服务的恶意攻击的问题,IPBFT算法针对这个问题对视图转换协议进行了改进,增加了验证机制,保证服务不会频繁地恶意启动视图变更算法。View Change确保系统在主节点错误的状态下仍然具有活性。当副本节点等待时间超过预设值时或协商副本被连续拒绝时,视图转换协议将启动以避免系统陷入死循环等待状态。发送请求的副本节点j在发送VIEW-CHANGE消息前,需要确认至少f+1个正确的副本向主节点发送过消息m,当副本节点j怀疑主节点发生了错误后,并不是马上向其他副本节点发送VIEW-CHANGE消息,而是先发送预准备消息〈PRE-VIEWCHANGE,v,d,j〉σj,当收到大于2f+1条相同的PRE-VIEWCHANGE消息后,这时正确的执行副本中向主节点p发送过消息m的最少有f+1个,接着发送视图转换请求消息VIEW-CHANGE。
IPBFT采用的视图转换协议能够处理作恶节点有选择的发送特定虚假信息造成主节点不断进行View Change并消耗资源的问题,下面详细介绍视图转换协议协议。
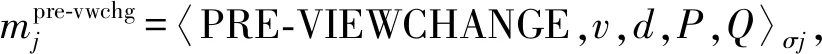
Step2执行副本j在有效时间内发送消息〈VIEW-CHANGE,v+1,n′,d,P,Q,j〉σj后,进入视图v+1,启动计时器,停止接收来自于前一个视图v的消息,在计时器超时前,执行副本j如果没有收到来自新的主节点pnew的NEW-VIEW消息,执行副本j将计时器重置,并进入视图v+2,重新进入Step1执行,直到在计时器时间内执行副本j收到新的主节点pnew发送的NEW-VIEW消息。
Step3进入视图v+2后,新的执行副本jnew收到消息〈VIEW-CHANGE,v+1,n′,d,P,Q〉σjnew,发送消息视图变换确认消息VIEW-CHANGE-ACK消息〈VIEW-CHANGE-ACK,v+1,j,jnew,d〉μjnew给新的主节点pnew。
Step4在新的主节点pnew收到2f+1条VIEW-CHANGE消息和至少2f-1条VIEW-CHANGE-ACK消息后,向所有的副本节点广播NEW-VIEW消息〈NEW-VIEW,v+1,Y,X〉σjnew,其中Y是由〈j,d〉组成的集合,X是主节点pnew的所有检查点的摘要和处于PREPARE状态的消息组成的集合。
Step5当新的副本节点jnew收到〈NEW-VIEW,v+1,Y,X〉σpnew后,对消息中的每个元素进行验证,验证NEW-VIEW与上一个视图的消息是否对应,视图编号v是否加1,Y集合是否一致,X中的检查点摘要和PREPARE消息组成的集合是否一致。若上述元素都正确,说明确认该消息来自于主节点pnew,然后进行Reply操作,执行节点回滚到Reply起始位置,协商节点重新协商Reply请求,pnew负责发送预准备PRE-PREPARE消息,而非主节点负责发送准备PREPARE消息,开始新的三阶段协议过程。
视图转换协议完成后,系统处于新的一致状态,并开始新的客户端请求处理。
3 实验分析
3.1 系统结构图
为了测试该改进算法的实用性和有效性,图2是改进算法的区块链系统结构图。该结构底层为区块链协议层,数据采用的是链式数据结构,网络结构为P2P,加密使用椭圆曲线非对称加密算法,整个系统是去中心化的。整个系统分为三个层面:协议层、扩展层和应用层,其中协议层又可以分为共识层和存储层。
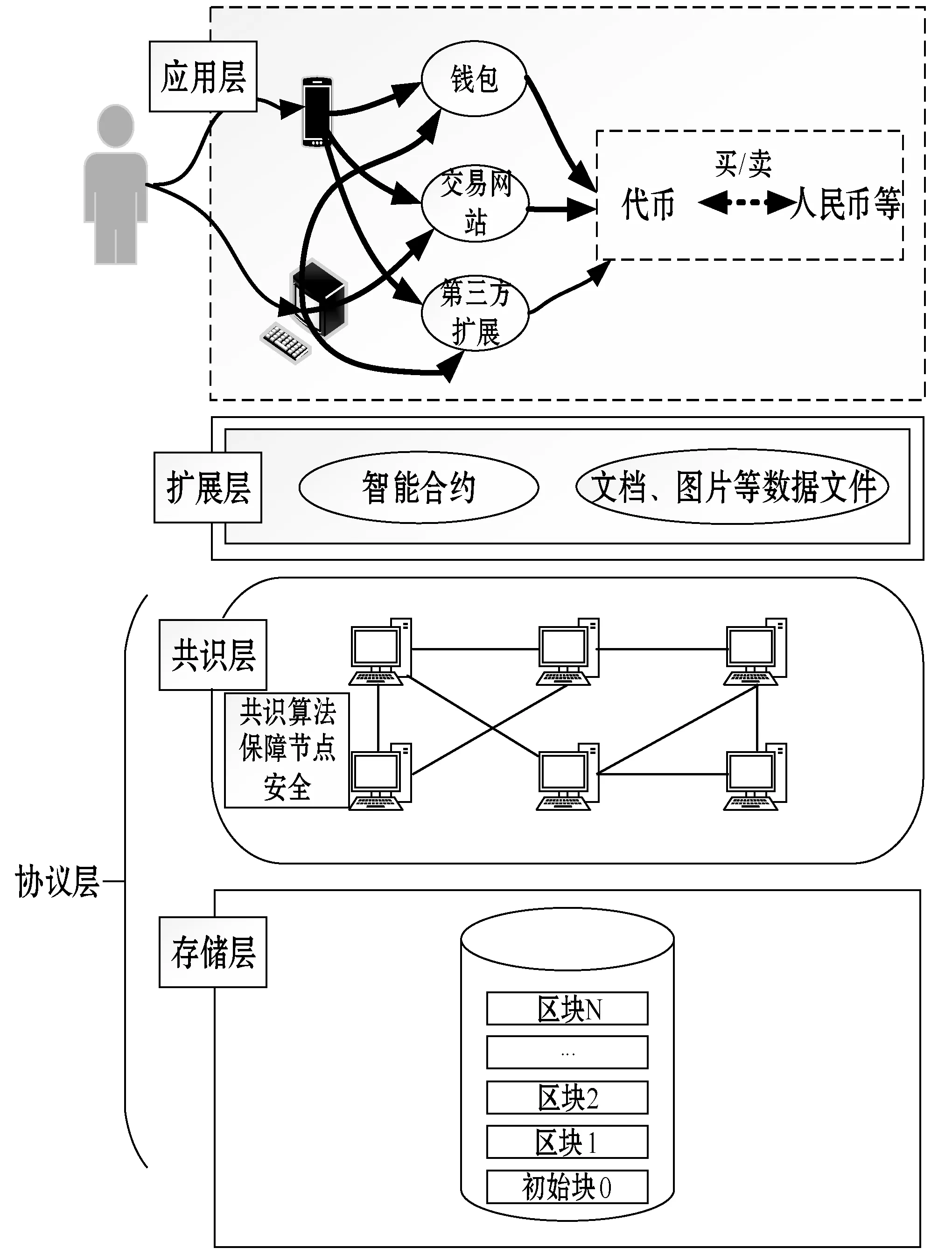
图2 系统结构图
应用层是客户可以直接接触的产品,本算法从协议层开始,把最终的目的指向应用层。扩展层类似于驱动程序,这个层面可以让区块链更为实用,智能合约就是典型的扩展层面的应用开发,这是区块链技术重要的发展方向,扩展层使用的技术有分布式存储、机器学习、物联网、大数据等,因为可以与协议层完全分离,所以可以选择更加自由的编程语言,具有很高的扩展性。协议层是整个区块链系统最底层的技术,这个层级维护网络节点,仅提供API供调用,协议层主要包括共识算法、网络编程、加密签名和数据存储技术等4个方面,共识层收到传递来的交易后,产生区块进行共识过程,是整个区块链系统的关键步骤。
共识采用的是IPBFT 算法,共识模块又分为一执行协议、主节点选举、检查点协议和视图转换等4个子模块。存储层负责将已经达成共识的区块存储起来,数据信息的同步验证过程保证了各个节点在视图变换协议启动后,能够存储当前完整的区块链数据。存储的数据信息能被查询,但不能被修改。
3.2 性能测试
本文提出的IPBFT算法,在能耗、吞吐量和容错性等方面也得到了进一步的改善,现通过基于IPBFT算法构建的区块链系统对这三个方面进行测试,并与传统的PBFT 算法和小蚁链中的dBFT算法进行比较,以此来验证算法的实用性和有效性。
此次仿区块链分布式系统的实验网络环境采用的是实验室的通信局域网,实验室中有5台配置为I7-7900X处理器、DDR4 16×2 GB内存、256 GB SSD固态硬盘和操作系统为Windows10的服务器,通过Docker容器每台服务器上设置40个虚拟IP地址模拟区块链环境,与传统虚拟机相比,Docker容器更轻便,运行速度更快,实验通过MATLAB R2016a对IPBFT算法、PBFT算法和dBFT算法的运行结果进行数学计算仿真。
3.2.1功耗性能
在区块链网络中,IPBFT、PBFT和dBFT三种算法都需要进行数据的传输和损耗,这些算法所使用的网络带宽可以表示为:
Bandwidth=N×(N-1)×Blocksize
(4)
式中:Bandwidth为所需要使用的网络带宽,N为网络中的节点数目,Blocksize是传输的数据大小,在区块链系统中,一个区块的大小约为1 MB。从式(4)中能够看出,在Blocksize固定不变时,三种算法的网络带宽都会随着N的增加而增加。IPBFT、PBFT和dBFT算法所使用的网络带宽如图3所示。
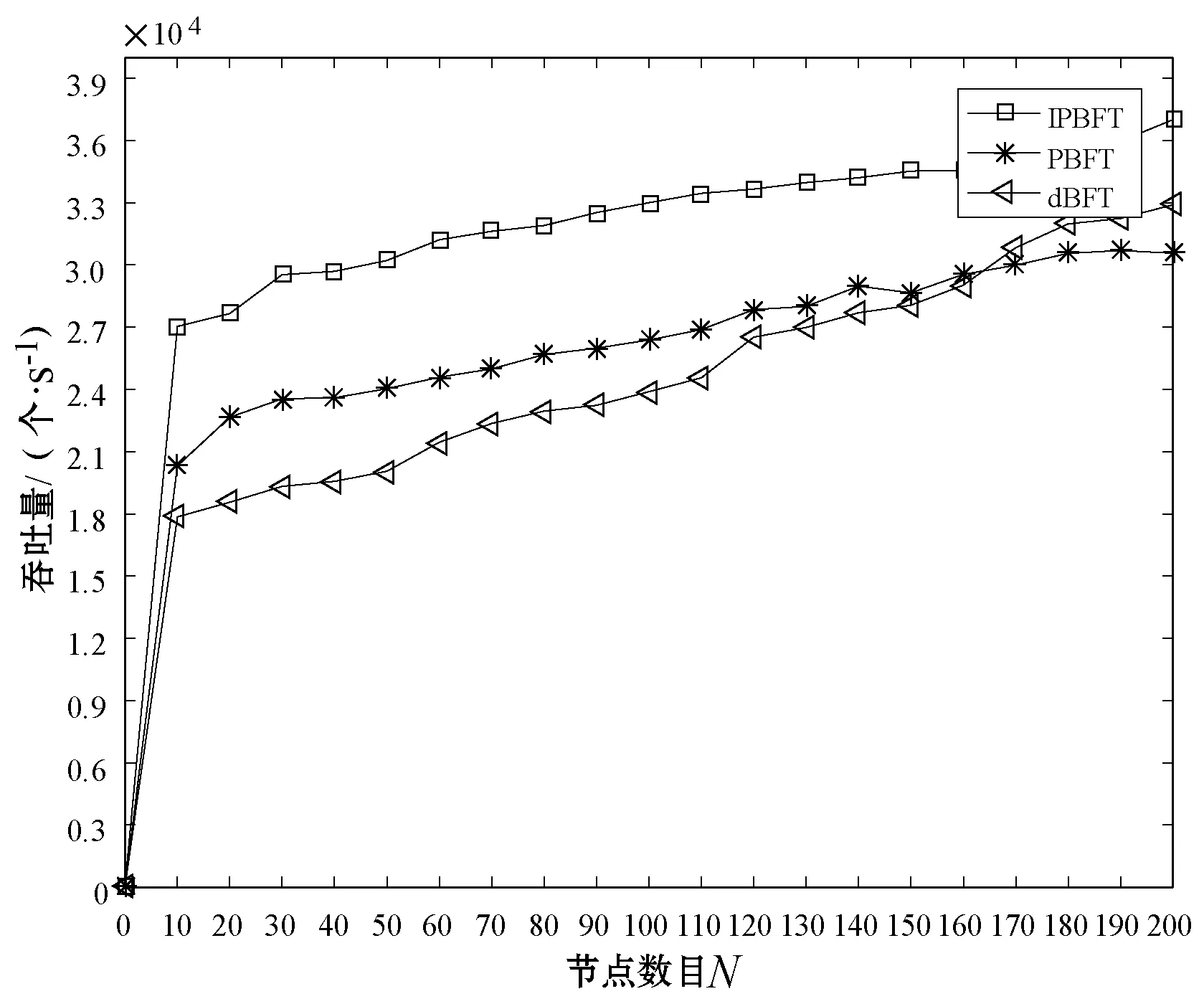
图3 IPBFT、PBFT算法以及dBFT算法的带宽消耗比较
从图3可以看出,在同一个网络环境下、节点数目都相同、传输的数据信息都一样的情况下,IPBFT算法的网络带宽消耗总体明显低于PBFT算法和dBFT算法,因此IPBFT算法具有更低的功耗。
3.2.2吞吐量
吞吐量的大小表示的是系统的负载承受能力,吞吐量的定义为单位时间内系统处理的事物总量,请求交易或者是处理事务的能力。在区块链系统中,通常使用每秒成功的交易数量TPS(Transaction PerSecond)来表示:
TPS=TransactionsΔt/Δt
(5)
式中:Δt为出块时间,其中TransactionΔt为出块单位时间内系统处理的交易总量,随着每个区块的节点数目N增大,吞吐量也会变大,但同时共识的处理时间会延长,网络负载的能力也会变大,所以当节点数目多到一定程度时吞吐总量会逐渐下降。
三种算法在相同条件下吞吐量对比如图4所示。可以看出,随着节点数量的增加,三种算法的吞吐量增长都趋近平稳,但是IPBFT算法的吞吐量明显高于其他两种算法,并且随着交易量的加大,吞吐量将会提升得更加明显。
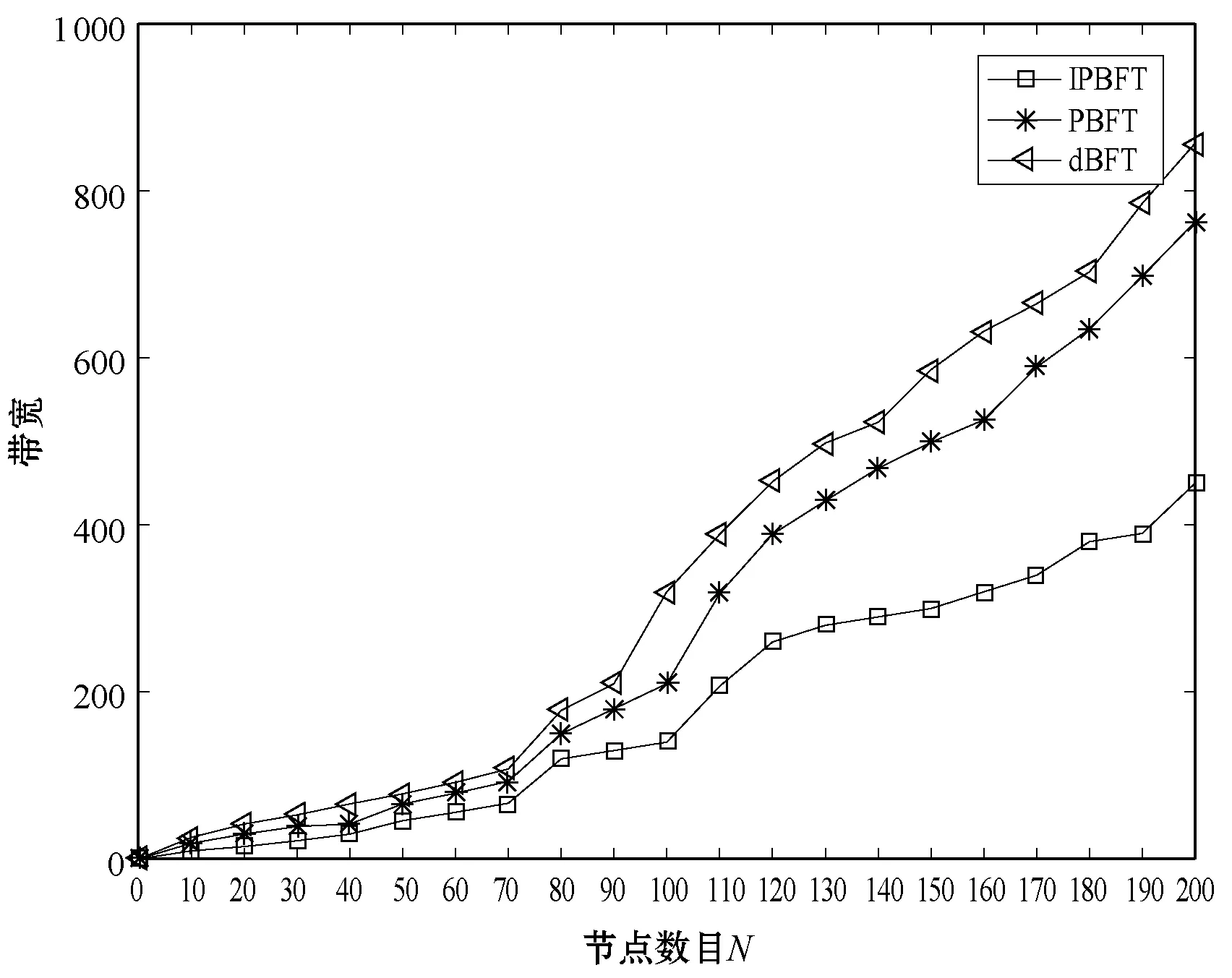
图4 IPBFT、PBFT算法以及dBFT算法的吞吐量比较
3.2.3时延性
共识算法的延时性是区块链运行速度的重要指标,低延时可以使得交易得到快速的确认,节省时间。在相同的网络环境下,三种算法都有延时逐渐递增的趋势,但起伏很小,传统的PBFT算法的延时最大。从图5中能看出IPBFT算法的延时性比dBFT算法略低,很明显比传统的PBFT算法低很多。在实验中还发现节点数目越多,表现出的延时性越小。因此可以得出结论,在这三种算法的延时比较中,时延性PBFT>dBFT>IPBFT,结果说明IPBFT共识算法在网络通信上具有更低的延时性。
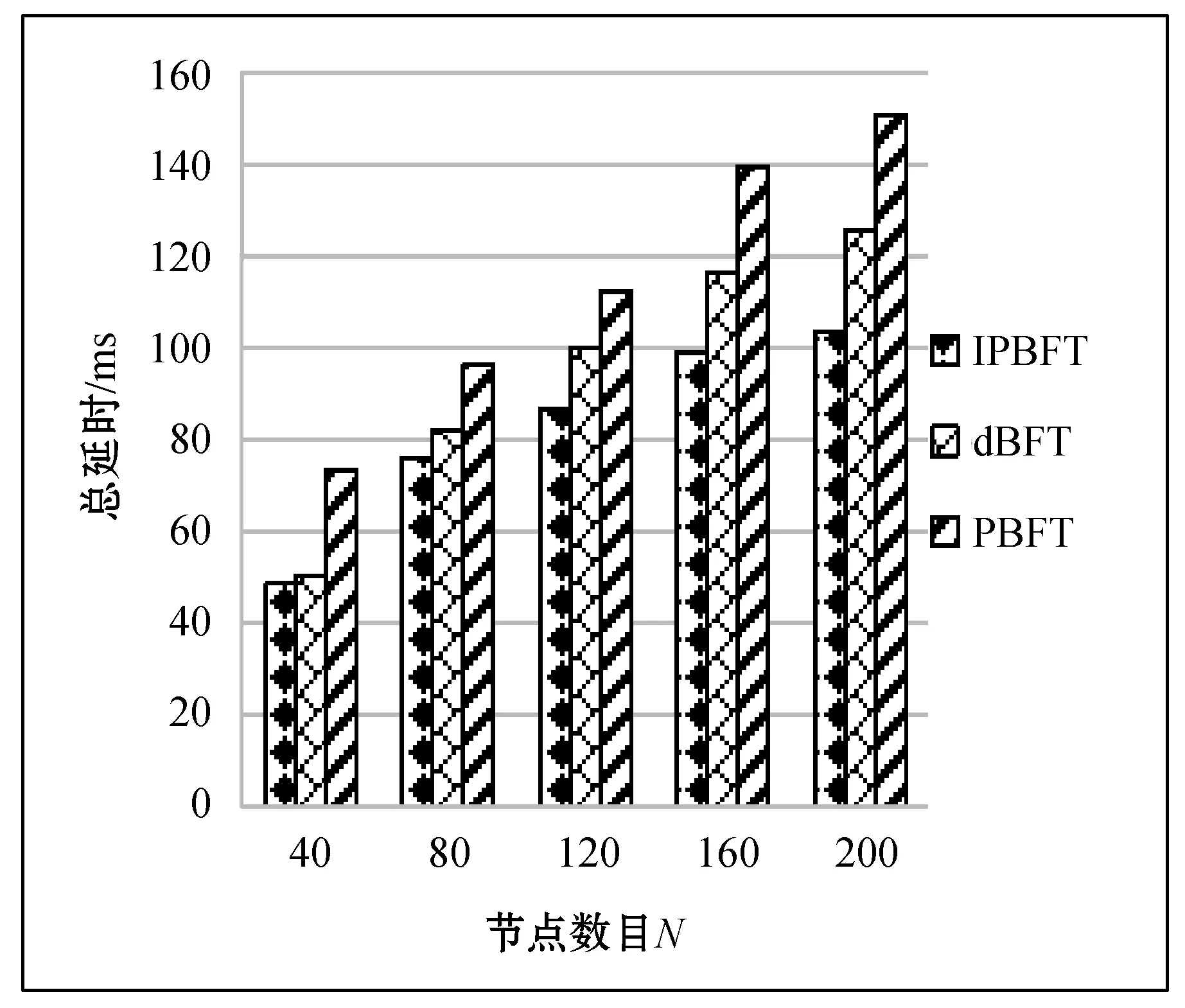
图5 IPBFT和PBFT以及dPBFT算法时延性的比较
4 结 语
本文首先介绍了拜占庭问题和一些传统的共识算法,如POW、POS、Paxos、Raft和Algorand等,并分析了这些算法存在的问题和不足。针对这些不足,在传统PBFT的基础上提出了优化改进的共识算法IPBFT,将协商与执行节点分离,对于执行时间较长的请求,减少执行请求的服务器数量可以较大程度地提升系统吞吐率。将主节点的选举方式改为心跳检测机制和最长链选举方式,进一步提高了主节点选举的安全性和实用性。在三阶段协商中加入了自证机制,进一步减少了作恶几率,提高了系统的稳定性。通过实验分析,IPBFT算法在通信消耗、吞吐率和延时性都有很大的提升,具有一定的可靠性。但IPBFT算法还存在一些问题,未来的工作重点将会在容错性和进一步优化算法细节以及降低网络通信量上,并将算法用于某一领域的实际区块链项目中,提高算法的实用性。
猜你喜欢
中国知识产权(2018年3期)2018-04-13
环球人文地理·评论版(2017年3期)2017-06-14
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
电脑知识与技术(2016年13期)2016-06-29
凤凰生活(2016年2期)2016-02-01
赤峰学院学报·哲学社会科学版(2014年4期)2014-06-06
古代文明(2014年1期)2014-01-16
电子竞技(2009年13期)2009-09-28
