
结合自注意力机制的神经网络文本分类算法研究
2020-03-11 12:51贾红雨王宇涵丛日晴
计算机应用与软件 2020年2期
贾红雨 王宇涵 丛日晴 林 岩
(大连海事大学航运经济与管理学院 辽宁 大连 116026)
0 引 言
互联网在21世纪以指数级的速度发展,产生了海量的文本信息数据,包括社交评论、新闻媒体、政府公文、企业文书、电商评论信息等文本数据。自然语言处理(Natural Language Processing,NLP)的任务之一就是对这些文本数据进行有效的文本分类、文本挖掘,发现文本背后的隐藏价值,这一直是NLP领域学术前沿的研究课题。采用深度学习技术,在文本分类任务中有效提升分类器性能,对开发和利用文本信息具有很大推动作用。
1 相关工作
文本分类一直是NLP领域长期活跃的前沿课题,并在大数据时代有着广泛的应用,传统机器学习方法在处理文本分类任务上已经有诸多研究。文献[1]基于LDA[2](隐狄利克雷分布)主题模型对科技视频的关键字进行建模,通过关键字文本分类的方式对视频内容进行分类。文献[3]提出了一种基于LDA特征扩展的短文本分类方法,使用LDA模型对短文本进行了主题模型的特征扩展,最后使用SVM作为分类器对文本进行分类。文献[4]基于KNN构建主题模型,利用该模型实现主题信息的分类。文献[5]使用TF-IDF[6]作为文本特征,证明多项式SVM在短文本处理问题上,性能优于KNN。尽管传统方法在一些实验中已经取得了不错的效果,但是单纯以词频来衡量词的重要程度不够全面,容易忽略一些低频关键词信息,无法体现词的位置信息,且没有考虑词性问题。其次,这些方法无法表示词语之间的内在联系。
在深度学习领域,针对传统文本处理方法不能有效处理词之间联系与位置信息的问题,文献[7]提出了基于LSTM[8]和GRU[9]的递归神经网络结构,以LSTM或GRU作为计算单元的递归神经网络在处理文本等序列数据时可以记住序列中远距离的依赖关系,侧面映射了文本数据中的单词之间的语义关系。Kim[10]则使用考虑上下文信息的卷积神经网络对句子序列进行卷积操作,通过不同大小的卷积窗口获得不同大小的信息量,最后通过融合各个卷积层的输出进入全连接层映射出分类结果。文献[11]结合CNN与KNN,使用CNN进行抽象的特征提取,对提取特征使用KNN进行短文本分类,融合CNN特征抽取准确与KNN简单高效,在短文本分类问题中表现较好。文献[12]提出了一种融合了RNN和CNN的文本分类模型结构RCNN,主要变化是使用RNN替代CNN中的卷积层。
针对传统文本分类算法存在的特征维度高、特征数据稀疏,且传统方法并不能有效识别文本句子的前后语义关系与关键词信息。针对上问题,本文使用预训练词嵌入为文本特征表示,提出了一种引入注意力机制的RCNN_A文本分类算法。
2 结合自注意力的RCNN_A模型
2.1 文本的特征表示
词的表示方法决定了文本数据的表示方法。传统的词表示方法,也是最早的词向量表示法,即One-Hot表示法(独热编码表示)。One-Hot表示法在理解与使用时非常简单,但是其缺陷也是十分明显的,当遇到较大数量级的文本数据时,向量矩阵非常稀疏、计算效率极低。且这种向量表示方法无法表示词语的语义信息,也无法表现词语之间的联系,因而在实际应用中的效果表现也比较差。
针对传统方法的问题缺陷,Bengio[13]提出用神经网络概率语言模型来处理文本信息。Mikolov[14-15]基于NNLP提出利用Word2Vec中CBOW和Skip-Gram两种模型构建词向量,如图1所示。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出是这特定的一个词的词向量。Skip-Gram模型则与CBOW相反,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
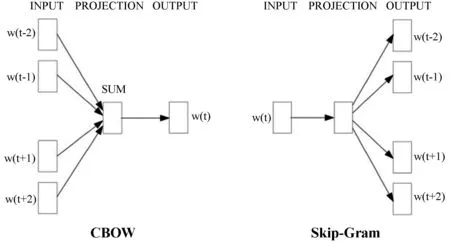
图1 CBOW和Skip-Gram
这种向量表示技术通过神经网络对上下文、上下文和目标词汇之间的关系进行建模。在无监督的大规模预料上进行词的分布式表示,这种方法可以将文本映射到较低纬度的向量空间中去,解决了词袋模型的高纬度、高稀疏性的缺点,避免了维数灾难,同时也保留了文本数据上下文之间的关系性质。并且这种分布式表示适合神经网络的输入。
2.2 注意力机制
深度学习中的注意力机制(Attention Mechanism)很早就被应用于图像处理领域,并取得了非常好的应用效果。而Bahdanau等[16]则首次将Attention机制应用于NLP领域中来,并在机器翻译任务上将翻译与对齐同时进行。随后Attention被广泛用在基于RNN/CNN等神经网络模型的各种NLP任务中来。Google机器翻译团队[17]用Attention代替了RNN搭建了整个模型框架,并提出了多头注意力(Multi-headed attention)机制方法,在编码器和解码器中大量使用多头自注意力机制(Multi-headed self-attention),在WMT2014语料中的英德、英法翻译任务上取得了优秀的效果表现和优于主流模型的训练速度。
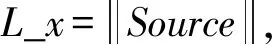
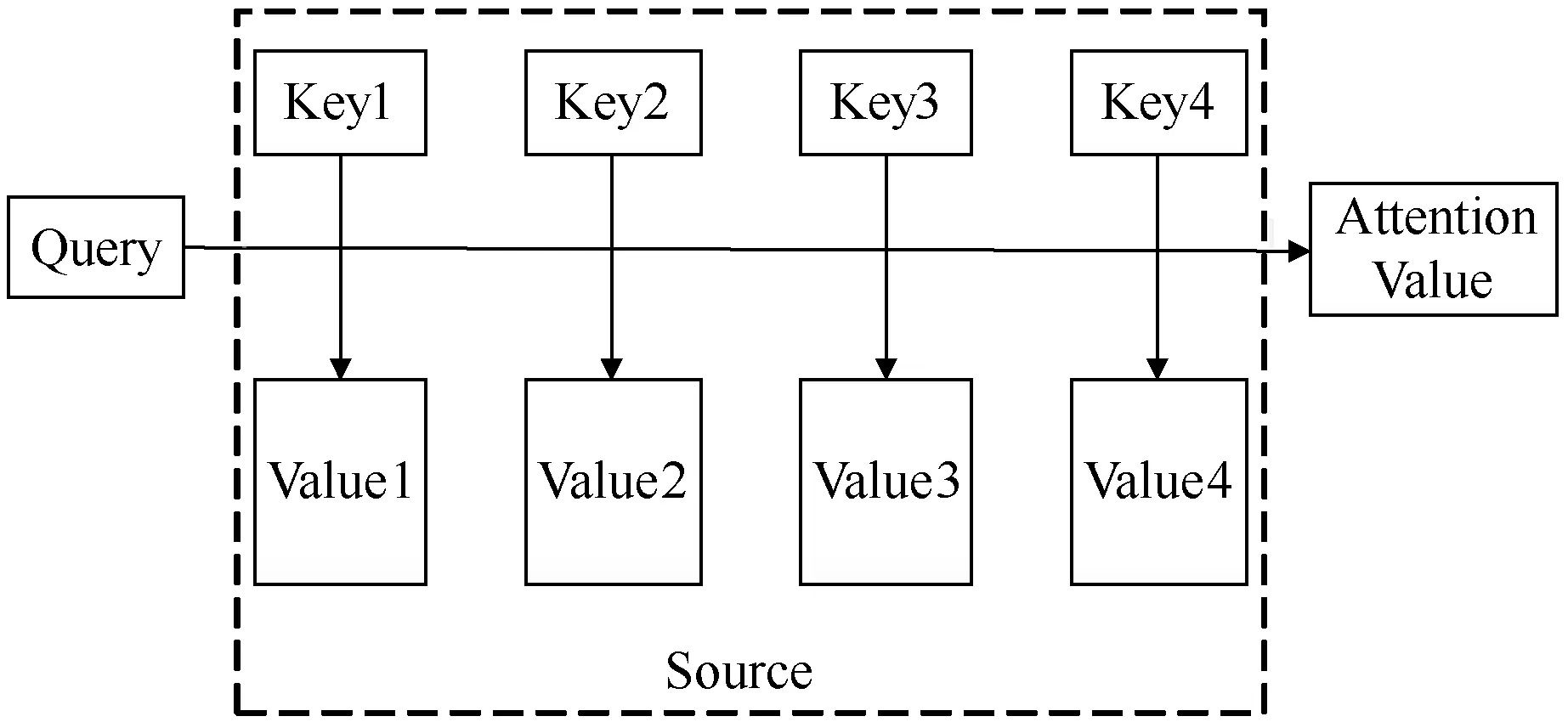
图2 查询到键值对映射
首先计算Query与每个Key的相似性,常用的相似性计算函数有点积公式、cosine相似性公式和感知器网络公式,分别如下:
Sim(Query,Keyi)=Query·Keyi
(1)
(2)
Sim(Query,Keyi)=MLP(Query,Keyi)
(3)
然后使用Softmax进行归一化处理得到概率分布:
(4)
最后根据权重系数对Value进行加权求和:
(5)
通过上述Attention机制计算过程的描述,可以更方便地理解Self-Attention机制。通常在一般的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,如翻译任务中,输入是一种语言的文本句子,而输出则是另外一种语言句子,在这种框架中Attention机制发生在Target和Source之间。而在自注意力机制中,注意力的计算不是发生在输入与输出中,而是Source自身内部的元素与元素之间发生注意力计算。其计算过程与上述过程相同。
2.3 RCNN_A模型
RCNN与普通RNN不同的是,输入层将每一个词分别和左右两边的词进行融合。左右的词文本分别先经过一层LSTM(长短期记忆),将该词左侧的词正向输入得到一个词向量,将右侧反向输入得到一个词向量,然后再结合三种词向量(等同于卷积窗口为3的卷积层),生成组合向量输入到全连接层,紧接着使用Max-Pooling进行降维、Dropout防止过拟合,最后通过全连接与Softmax进行分类。
结合自注意力机制的循环卷积神经网络结构(Recurrent Convolutional Neural Network with self-Attention,RCNN_A)由3个词输入层(Left_Context、Context、Right_Context)、词嵌入层(Embedder)、循环卷积层(Recurrent Convolutional Layer)、注意力机制层(Attention Layer)、合并层(Concatenate)、全连接层(FC,Fully Connected Layer)、Dropout层、最大池化层(MaxPooling)及最后的Softmax层与输出层(Output)组成,结构图如图3所示。
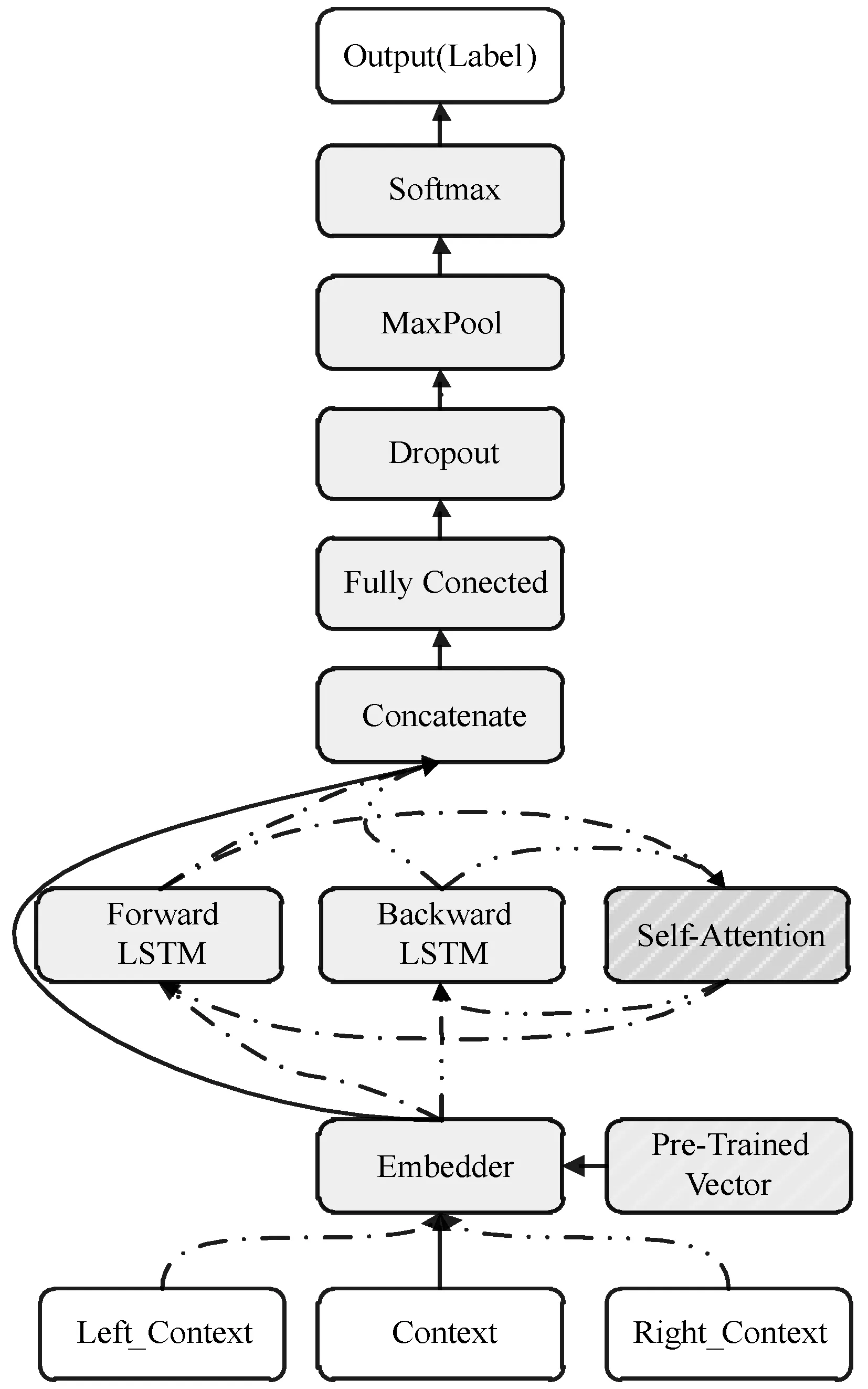
图3 RCNN_A模型结构图
2.3.1输入层
输入层有3个输入内容,分别为左文本(Left_Context)、文本(Context)和右文本(Right_Context),其中左文本为Context中所有词索引值减去1,右文本为Context中所有词索引值加上1,分别得到由词索引值组成的输出。
2.3.2词嵌入层
在词嵌入层Embedder中引入Skip-Gram模型预训练的词向量。并设置嵌入层词向量不可再训练。
2.3.3循环卷积层
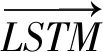
左、右文本的上下文信息表示如下[10]:
Cl(wi)=f(W(l)Cl(wi-1)+W(sl)e(wi-1))
(6)
Cr(wi)=f(W(r)Cr(wi+1)+W(sr)e(wi+1))
(7)
式中:wi为文本序列中第i个词的词嵌入,wi-1为其左侧上下文词嵌入,wi+1为其右侧上下文词嵌入,Cl(wi-1)为词wi-1的左文本上下文信息表示,W(l)为转换前后词汇的权重矩阵,W(sl)为被用于融合当前词汇与下一个左侧词汇语义信息的权重矩阵,f则是一个非线性的激活函数。
2.3.4注意力机制层
自注意力机制使用自注意力关注句子本身进而从句子中抽取相关信息,由循环卷积层得到的左文本表示序列输入到Attention层进行计算注意力权重。本文引入的注意力机制相似度计算函数为MLP,即式(3)。这里设:输入序列Cl(wi)经过全连接层得到[h1,h2,…,hn],然后进行Softmax归一化得到一个概率分布,即注意力矩阵SAMl。然后再将SAMl返回到循环卷积层,与原输出进行注意力加权,⊗为乘积符号,最后将加权后的值Cla(wi)输出到合并层进行融合。同理右文本信息序列做同样操作处理。
SAMl=Softmax(WhlCl(wi)+bhl)
(8)
Cla(wi)=SAMl⊗Cl(wi)
(9)
SAMr=Softmax(WhrCr(wi)+bhr)
(10)
Cra(wi)=SAMr⊗Cr(wi)
(11)
2.3.5合并层
通过词嵌入层得到文本词嵌入Cc(wi),通过循环卷积层和Attention层得到经过注意力矩阵加权后的所有左文本上下文信息Cla(wi)和右文本上下文信息Cra(wi),则得到词wi及其上下文信息,通过式(12)将所有向量进行合并,得到最终的词wi的信息表示xi,即每条文本第i个词的信息表示。
xi=[Cla(wi);Cc(wi);Cra(wi)]
(12)
2.3.6全连接层
(13)
2.3.7Dropout与最大池化层
在FC层后,设置一个Dropout层,并以概率p来丢弃神经元,让别的神经元则以概率q=1-p进行保留操作,其中在FC层中的每一个神经元都有相同的概率进行丢弃和保留。通过添加Dropout层,本文模型设置p=0.1,来降低过拟合的风险。
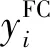
(14)
2.3.8Softmax与输出层
从池化层得到本层的输入,同常规神经网络一样,本层被定义为:
yO=WOyMax+bO
(15)
式中:yO为本层神经元的输出。然后Softmax分类器对yO进行如下计算:
(16)
并将数字输出转换为概率输出pi,最后通过argmax函数对pi计算得到输出标签值,即文本所属类别l*:
(17)
3 实验结果与分析
3.1 实验数据集
本文采用搜狗实验室(Sougou Labs)发布的新闻数据(SougouCS)完成RCNN_A模型文本分类的性能测试。
本次使用的数据为SougouCS发布时长间隔一个月的搜狐新闻网站上抓取下来的各类新闻文本。对原始数据进行预处理操作,文本仅进行去除非中文字符及去除重复及无效数据。最终使用10类新闻文本数据共20 000条,训练集与验证集划分比例为9∶1。数据样本的类别分布如表1所示,样本数据示例如表2所示。
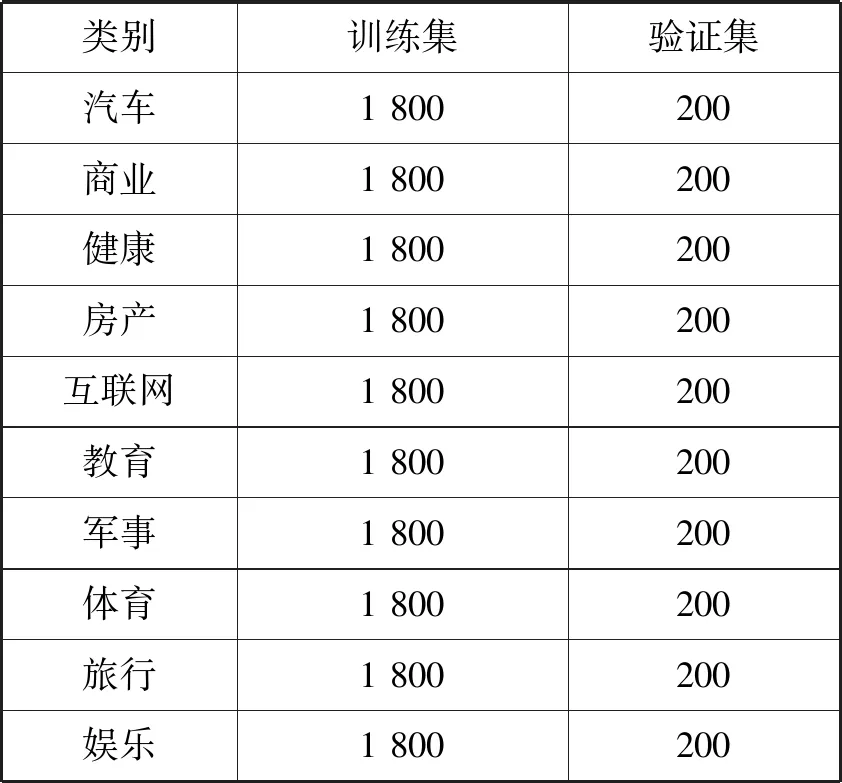
表1 数据样本集
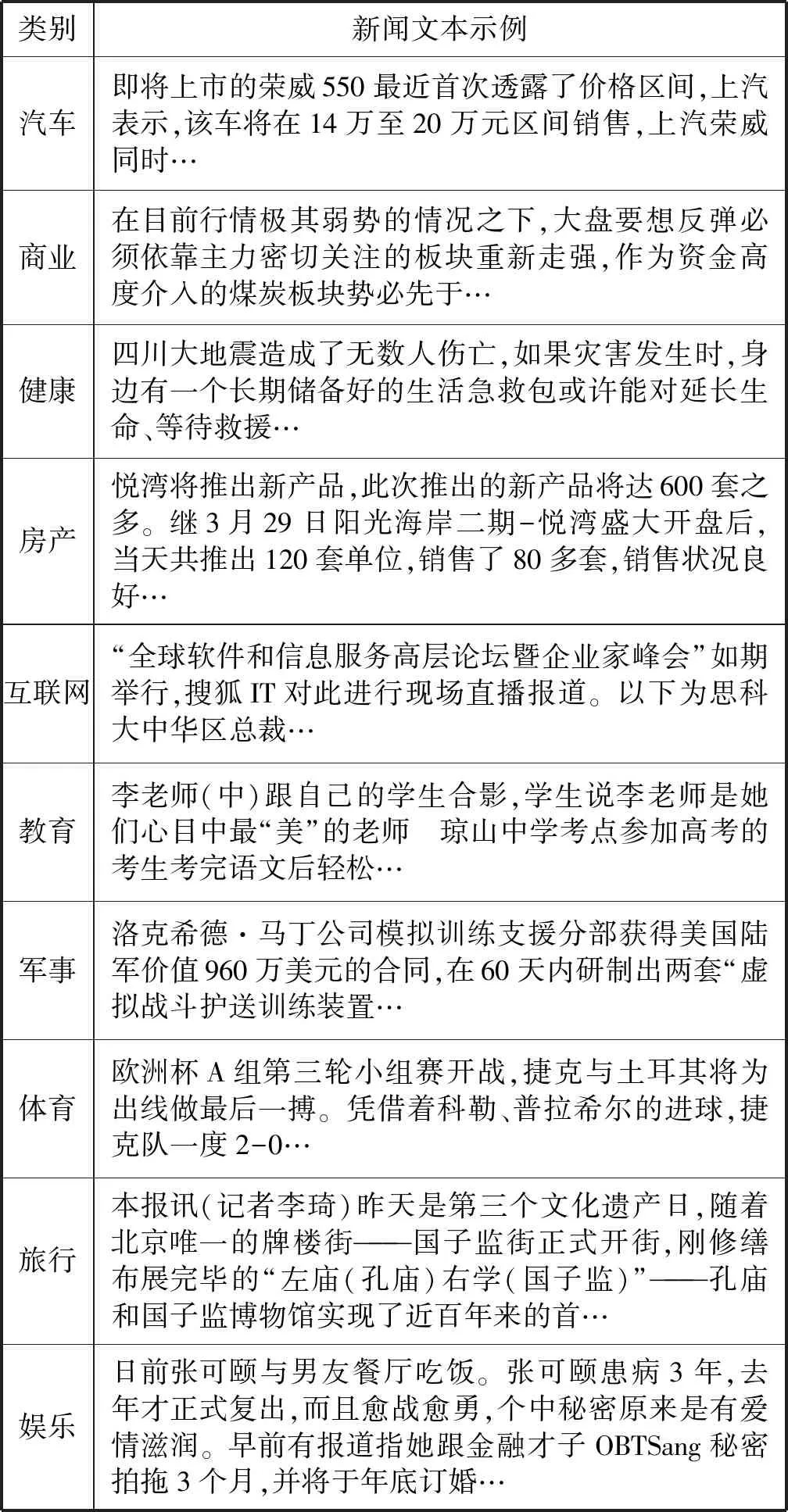
表2 数据样本示例
3.2 实验设置
本文模型通过Keras深度学习框架(后端基于Tensorflow)进行网络搭建并完成模型验证实验。本文物理实验环境如表3所示。
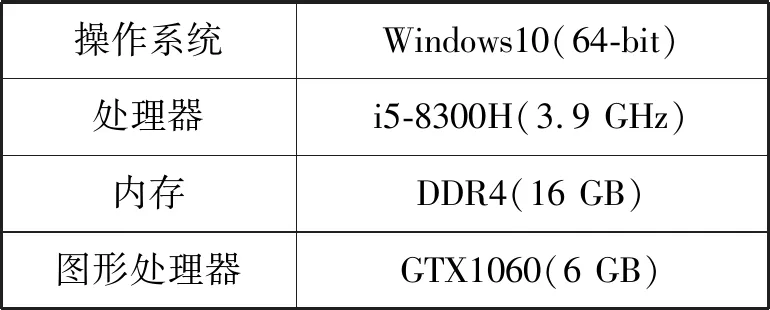
表3 实验环境
3.3 词向量预训练
预训练词向量使用Google开源的词向量训练工具Word2Vec,本文使用负采样模型(Skip-Gram with Negative Sampling)训练词向量。模型训练的窗口大小为5(当前词与目标词之间的最大距离),最小过滤词频为5(词频小于5的单词训练时被忽视),学习速率设为0.05,迭代数量为5。词向量预训练参数如表4所示。词向量的预训练语料为搜狗实验室发布的新闻数据集(间隔一个月,约10万条新闻数据)。预训练词向量词语相似性示例如表5所示。
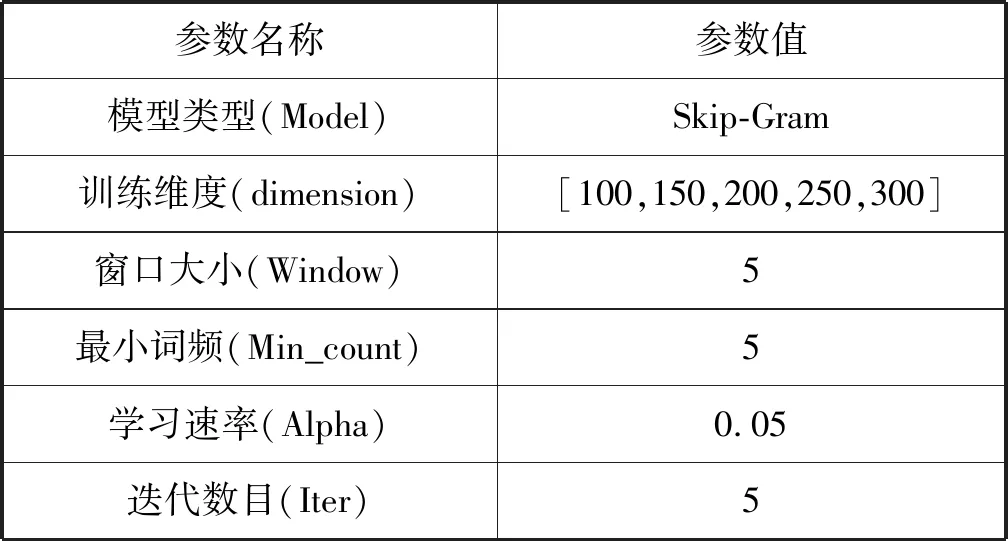
表4 词向量训练参数
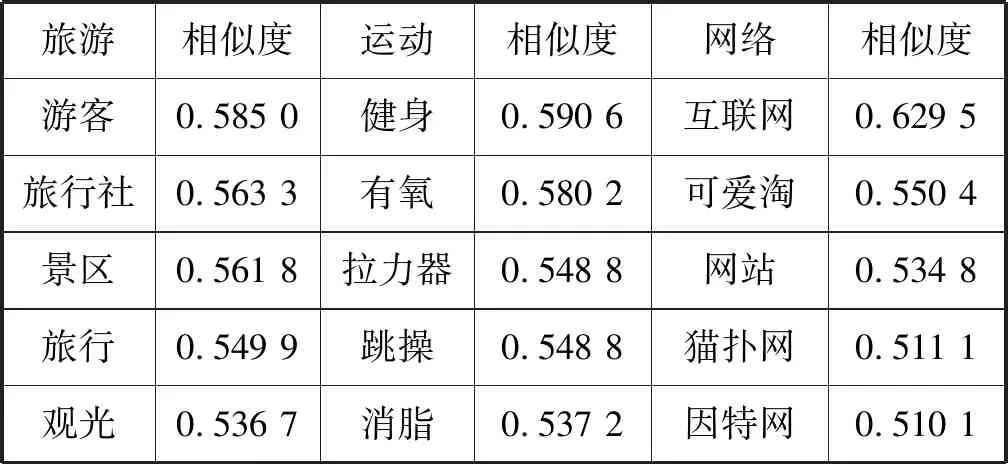
表5 预训练词向量相似度示例
3.4 实验设计
为了验证本文提出的RCNN_A模型文本分类的有效性,同时构建了文献[8]的Bi-LSTM、文献[7]的Bi-GRU、文献[10]的TextCNN和文献[12]的RCNN作为参照模型进行分类性能对比。各模型超参数对比如表6所示。
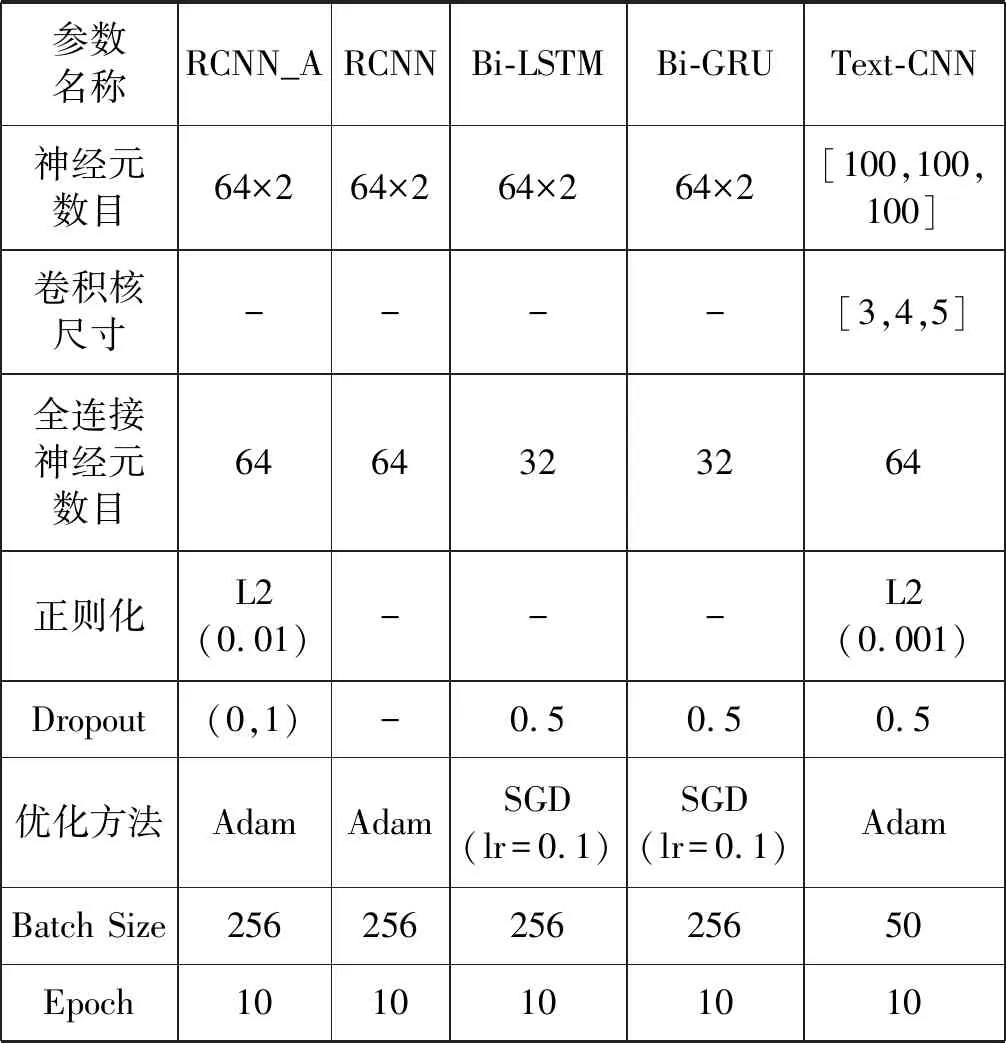
表6 参照模型超参数设置
3.5 结果分析
实验结果如表7所示。
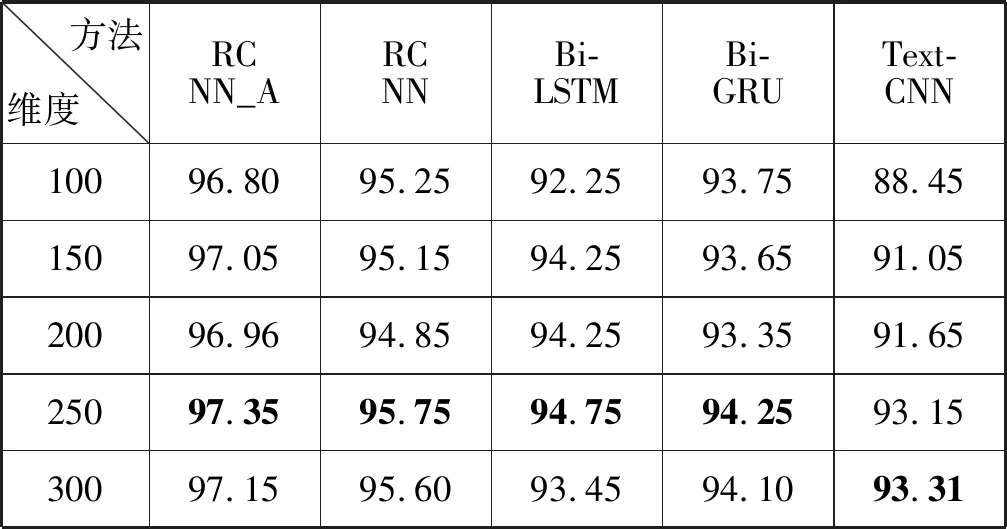
表7 各参照模型不同维度准确率 %
各分类器性能在不同词向量维度下的表现变化情况如图4所示。
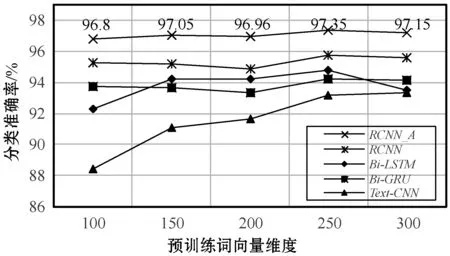
图4 词向量维度对分类性能的影响
RCNN_A在不同Dropout取值中的表现如图5所示(以250维为例)。
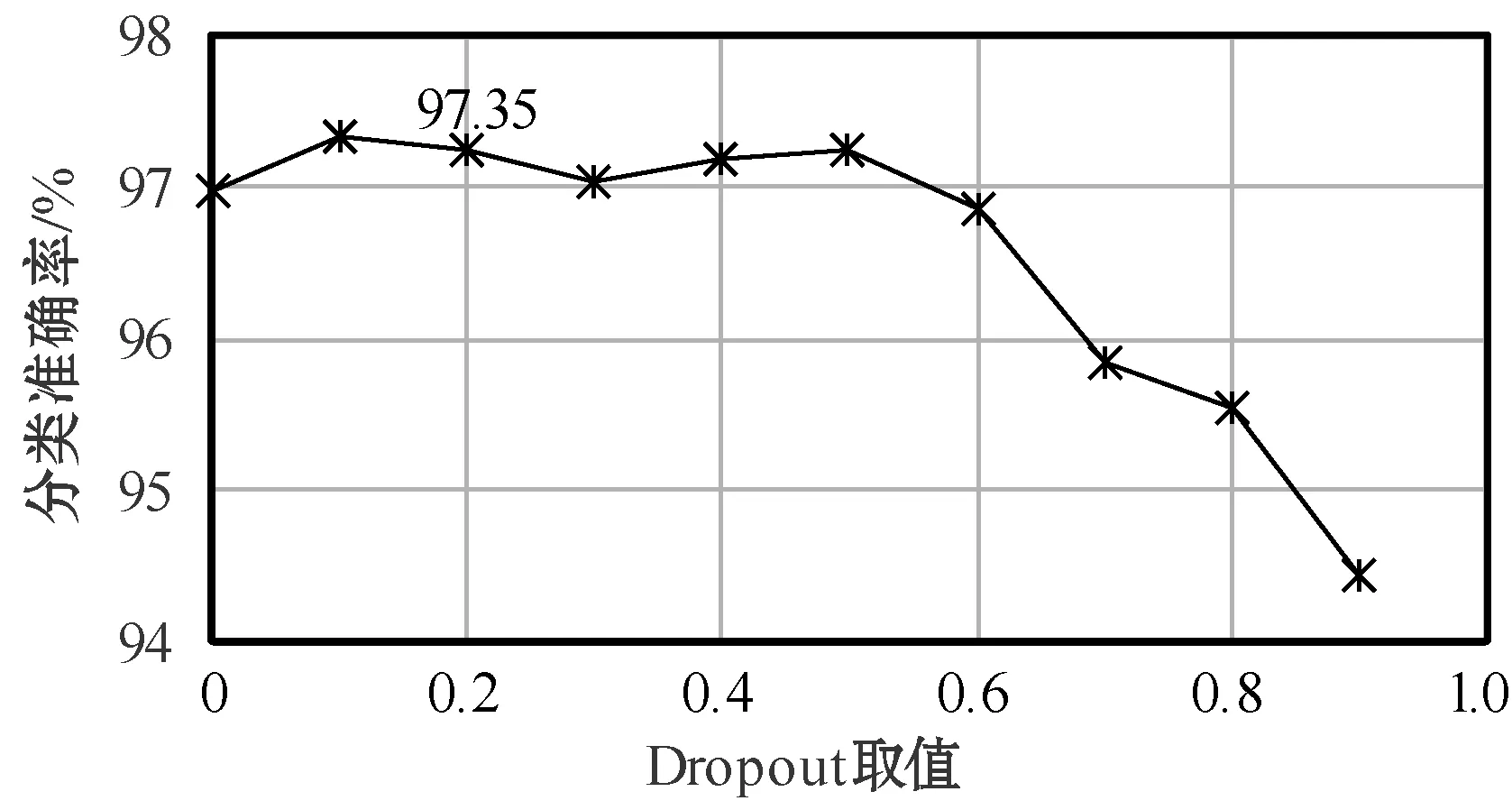
图5 Dropout取值对分类性能的影响
从图4中可以看出,各个分类模型都与预训练词向量的维度大小成正比关系。且在低维度区间处,随着词向量维度增加,训练模型可以明显地提升分类性能,但维度到达一定高度时,变化程度开始减缓。其中,在词向量维度为300维时,除了TextCNN模型外,其余均有小幅度下滑波动,可能是语料数据预训练出的300维度词向量质量不佳导致。但从整体趋势波动上来看,仍为正比趋势。图5为不同Dropout取值下的分类器性能表现,在Dropout=0.1处取得最佳性能表现,并在(0,0.5)区间中没有明显的起伏波动。
由表7及图4可知,对于中长文本分类任务(搜狗新闻数据集)中,表现最好的分类模型为本文提出的RCNN_A模型,并在词向量维度为250时,达到了最高97.35%的分类准确率,参照组模型分别得到最高95.75%(RCNN)、94.75%(Bi-LSTM)、94.25%(Bi-GRU)、93.31%(TextCNN)的分类结果。
在没有引入注意力的时候,所有的语义都通过一个中间语义词向量来表示,如果输入的语句过长,关键词汇便会逐渐消失其独特的语义信息,损失很多语义细节。本文提出的结合自注意力机制的RCNN_A文本分类方法,通过注意力机制层生成“焦点”词汇(增强句中关键词汇的语义信息),并为“焦点”词汇的向量分配不同的权值。使用这种处理方法为文本的词向量序列引入了新的语义信息,从而在文本分类的应用场景中获得更好的性能表现。
4 结 语
注意力机制在处理输入词向量序列时,通过一层隐层神经网络单元来学习序列的注意力权重矩阵,这使得输出的序列向量的关键词向量得到更强的语义特征信息,从而使网络在多层的合成计算之后能够更高效地保留文本序列的主要语义关系信息。本文通过对文本中的字词序列信息注意力加权处理,得到注意力权重矩阵,并与前后向的LSTM层输出相乘得到矩阵加权处理后的文本序列向量,增强了在全连接层文本映射分类的性能,得到了更准确的文本分类效果。
但本文的模型直接将词嵌入层输出作为自注意力层的输入,仍是对原序列的简单处理。在不同文本处理任务中,根据具体的分类问题,还需要具体研究注意力机制的设计。其次,本文的实验数据集文本数据多数为中长度文本。而在某些文本分类任务中的文本长度非常简短(如微博、推特的推文等),其文本有效长度也非常短,增加了文本分类的难度。本文下一步的工作就是尝试在短文本分类问题中应用注意力机制进行验证研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
