
基于BiGRU和贝叶斯分类器的文本分类
2020-03-07 12:47梁志剑谢红宇安卫钢
计算机工程与设计 2020年2期
梁志剑,谢红宇,安卫钢
(1.中北大学 大数据学院,山西 太原 030051;2.中北大学 研究生院,山西 太原 030051)
0 引 言
文本分类作为自然语言处理中的经典任务,主要包括文本预处理[1]、文本特征的提取及分类器的设计等过程。在众多的机器学习算法中,朴素贝叶斯算法是最为经典的分类算法之一,在文本分类的任务中经常会被用到。文献[2]中利用贝叶斯分类器对文化旅游文本进行相关主题分类,通过对比实验发现它在处理文本分类时的效率很高,但如果数据量比较大时,该方法的准确率不高。为了能够使计算机挖掘出文本之间的联系,一种基于词向量特征表示方法被提出,将深度学习算法引入到自然语言处理领域。文献[3]中利用LSTM神经网络模型对金融新闻文本分类,提高了文本的准确率。文献[4]中将卷积神经网络和GRU神经网络相结合,并引入attention机制用于提取文本特征,虽然特征提取较好,但对短文本的分类效果不好。文献[5]中利用双向GRU神经网络和attention来进行特征提取,但模型复杂度较高,训练时间较长。通过以上方法的研究分析,本文提出的基于双向的GRU神经网络和贝叶斯分类器的方法与传统的神经网络相比,其优势在于利用其双向神经网络结构能够充分考虑到文本上下文的信息和语序的关系,捕捉其更加重要的特征,极大优化了特征提取的过程,同时贝叶斯分类器具有结构简单,执行效率高的特点,两者结合更加提高了文本分类的效率和准确率。对比仿真结果表明,该模型具有很好的分类效果。
1 相关工作
1.1 门控循环单元网络GRU
随着科学水平的不断提高,人们的生活方式发生了巨大的变化,越来越多的人开始去追求智能化的生活,因而也致使许多科研工作者投身于智能产业的研发。于是深度学习作为一把重要的利器被迅速推广开来。
循环神经网络[6](recurrent neural networks,RNN)作为一种很重要的深度学习模型,广泛应用于机器翻译,语音识别等领域。该模型在每个时刻利用当前时刻的输入数据以及之前时刻的输出数据,在同一个神经元产生当前时刻的输出数据,从而经常被用来解决一些带时序的问题。然而RNN却无法很好处理远距离依赖的问题,于是就需要改进神经元的结构从而利用其门控原理来选择性地遗忘以前的信息并加入新的信息。所以RNN产生了很多变体,最常用且最为经典的就是长短时记忆网络(long short-term memory networks,LSTM),而门控循环单元网络[7](gated recurrent unit neural networks,GRU)相较LSTM,不仅继承了LSTM的门控制原理,而且又简化了神经元的结构,减少了模型的复杂度,使得该模型得到了更广泛的应用。
尽管GRU是LSTM的一个变体,不过两者之间差别还是比较大的。它将LSTM的忘记门和输入门合成了单一的更新门,从而GRU变成了双控门结构。同时还将细胞状态和隐藏状态混合在了一起,很大程度简化了模型结构,当训练数据很大时,GRU能节省很多时间。同时GRU的双控门结构也对信息起到了选择性的作用,更新门是用来对上一时刻的信息做出选择性的接收,而重置门则是对上一时刻信息做出选择性的拒绝,因而GRU对文本特征的提取会更加准确。图1是GRU单元门结构。
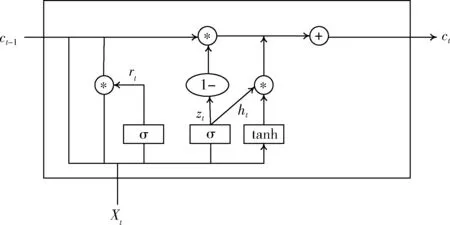
图1 GRU单元门结构
图1中Xt表示t时刻的输入文本数据,ct-1为上一时刻的输入文本数据,rt表示为重置门,zt为更新门,ht为待激活状态,ct是当前时刻的输出,其计算公式如下所示
zt=σ(Wz·[ct-1,xt])
(1)
rt=σ(Wr·[ct-1,xt])
(2)
ht=tanh(W·[rt*ct-1,xt])
(3)
ct=(1-zt)*ct-1+zt*ht
(4)
式中,σ为sigmoid函数,W为权重矩阵,从式(4)可以看出,t时刻的输出与当前时刻的输入数据有关,还与上一时刻的输入数据有关。GRU神经网络的参数比传统的RNN,LSTM都少,因此其计算量相对较小,模型训练时间较短。
1.2 双向的GRU神经网络模型
在传统的循环神经网络中,信息的传播过程往往是单向的,而这种单向的网络结构在处理文本信息时就会出现一些弊端。因为有时要预测的文本的信息是由前面的一些输入文本信息和后面的一些输入文本信息共同作用的,这样能使文本的语义理解更加清晰明确。这时双向RNN[8](bi-direction recurrent neural network,BiRNN)的网络模型结构特点就能发挥其更大的优势。例如要预测一句话“我出生在__,所以我会说山西方言。”中空白的部分时,不仅需要知道缺失地方前面的内容信息,也要知道后面的内容信息,这样才能更好地理解语义,预测出缺失部分的内容,如果仅知道前面的信息内容或后面的信息内容,那么要预测的空缺处词语的可能性就会很多,准确率就会降低。
双向 GRU 神经网络(bi-direction gated recurrent unit neural network,BiGRU)模型结合双向 RNN和LSTM两个模型的优点并做进一步改进形成的模型,通俗地说就是用GRU的神经元替换掉双向RNN模型中的循环神经元。图2展示了一个沿着时间轴展开的双向GRU神经网络结构。
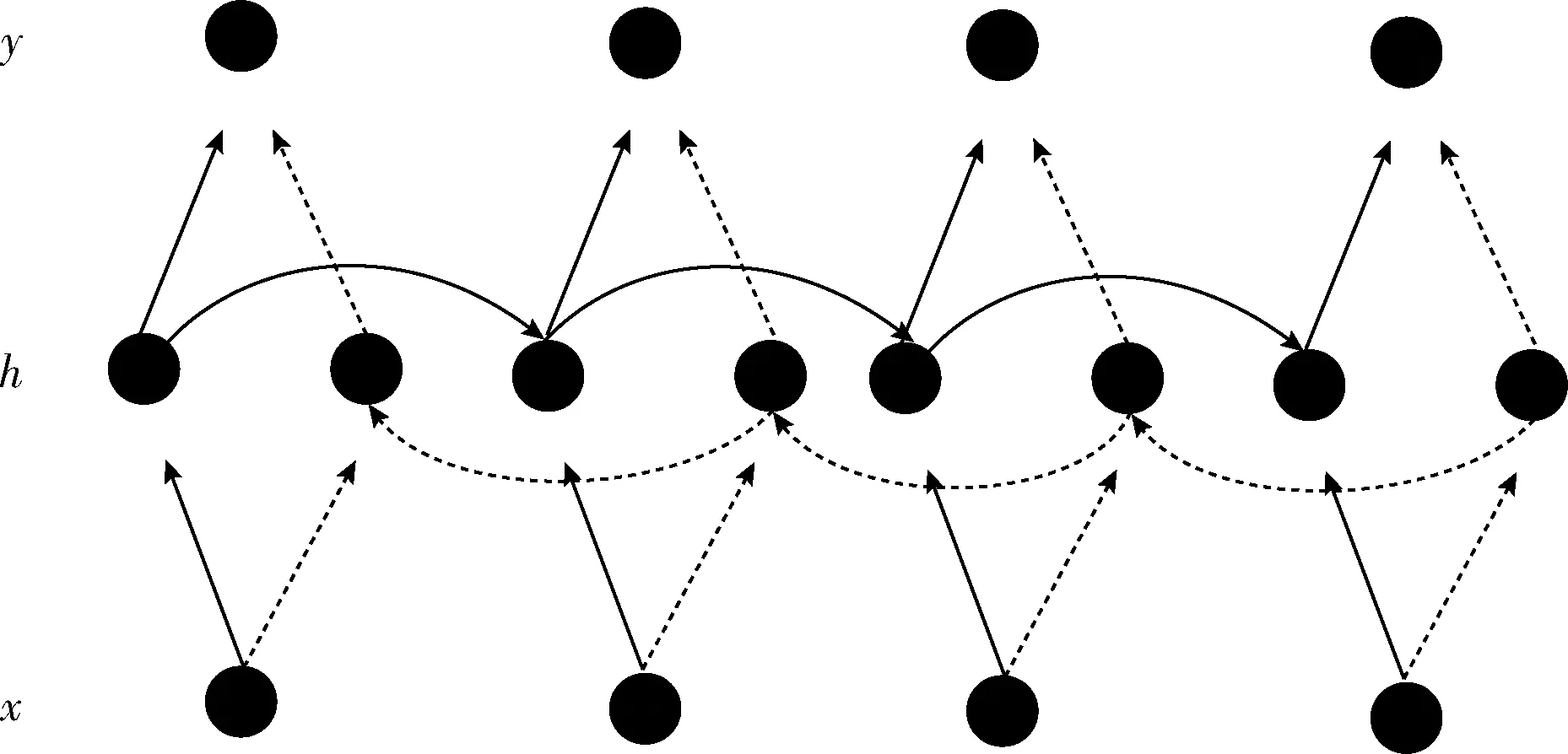
图2 双向GRU神经网络结构
图2中从左向右循环神经网络层的更新公式为
(5)
从右向左循环神经网络层的更新公式为
(6)
双向GRU神经网络最终输出的计算公式为
(7)
式中:W,V,U为权重矩阵,b,c为偏执矩阵。
1.3 TF-IDF算法的特征加权
TF-IDF[9]是一种特征加权的算法,经常被用于数据检索等领域。它采用统计的方法,通过计算某个字或词在某篇文章中出现的次数或者在包含所有文章的语料库中出现的次数来判断这个词或字的重要程度。并且它由TF和IDF两部分组成。
TF表示某个词在整篇文章中出现的概率。其计算公式为
(8)
其中,nij为特征词在文本中出现的次数, ∑knkj则是文本中所有特征词的个数。计算的结果即为某个特征词的词频。
IDF表示逆向文本频率,用来衡量某个词在整个语料库中的频率,为剔除掉文档中一些经常遇到但却不重要的词语同时也能够保留一些特征明显的词语。其计算公式为
(9)
N表示语料库中全部文章的数量, 1+Nmi表示文章中具有明显特征的词语mi的数量。为防止该词语在语料库中不存在,即分母为0,使用1+Nmi作为分母。
TF-IDF算法的主要目的在于如果某个字或词在某篇文章中出现的次数很高,而在其它文章中出现的次数很低,则说明该字或者词具有明显的特征,那么该字或者词就能够作为分类的依据。
其计算公式为
TF-IDFij=TFij*IDFij
(10)
TF-IDF的值是由词频TFij和逆向文本词频IDFij的乘积得到的。TF-IDF值越大,表示该特征词对这个文本的重要性越大。
1.4 朴素贝叶斯分类器
朴素贝叶斯算法[10]作为经典的机器学习算法之一,在信息检索领域有着极为重要的地位。朴素贝叶斯是一种基于贝叶斯定理的分类算法。然而在求解贝叶斯定理过程中经常会出现一些棘手问题。诸如组合爆炸和样本稀疏等,为更好解决这些问题,在朴素贝叶斯分类器中,前提假设各个属性变量之间都是相互独立的。然而这种前提假设在很多具体应用场景中都不能成立,但是却能使该分类器在很多情况下会表现出不错的性能。如果能对贝叶斯定理[11]进行近似的求解,那么就会对文本分类器的设计有更深的理解。
假设某个文本有n项特征,分别是e1,e2,…,en。 文本类别有k个,分别为m1,m2,…,mk。 求式(11)的最大值也就是贝叶斯分类器最终得到的结果
(11)
式中:p(e1,e2,…,en) 的计算过程不涉及类别bi, 可以忽略此项,不对它进行计算。因此如果要使p(mi|e1,e2,…,en) 的值最大化,那么就相当于求出p(mi|e1,e2,…,en)p(mi) 的最大值。朴素贝叶斯分类器所引入的属性条件独立性假设可用如下公式表示
p(mi|e1,e2,…,en)p(mi)=p(e1|mi)p(e2|mi)…p(en|mi)p(mi)
(12)
个体最可能属于的类别是最大后验估计,如下式
(13)
式中:等号右端的每个概率值都能从已知的条件中很容易地求出,因而就可以求出文本属于每个类别对应的概率大小,然后将概率最大的类别作为最终的分类结果。
2 双向GRU和贝叶斯分类器混合模型
2.1 混合模型框架
该模型由4部分组成,第一部分由word2vec模型[12]对待分类的文本进行词向量的训练得到文本向量,第二部分将得到的文本向量输入双向GRU神经网络进行特征提取,第三部分通过利用TF-IDF算法对所有提取到的特征进行赋值权重,选出权重高的特征向量,第四部分将这些选出特征向量输入贝叶斯分类器中进行训练并根据输出概率的大小得出最后分类结果。该混合模型结构如图3所示。
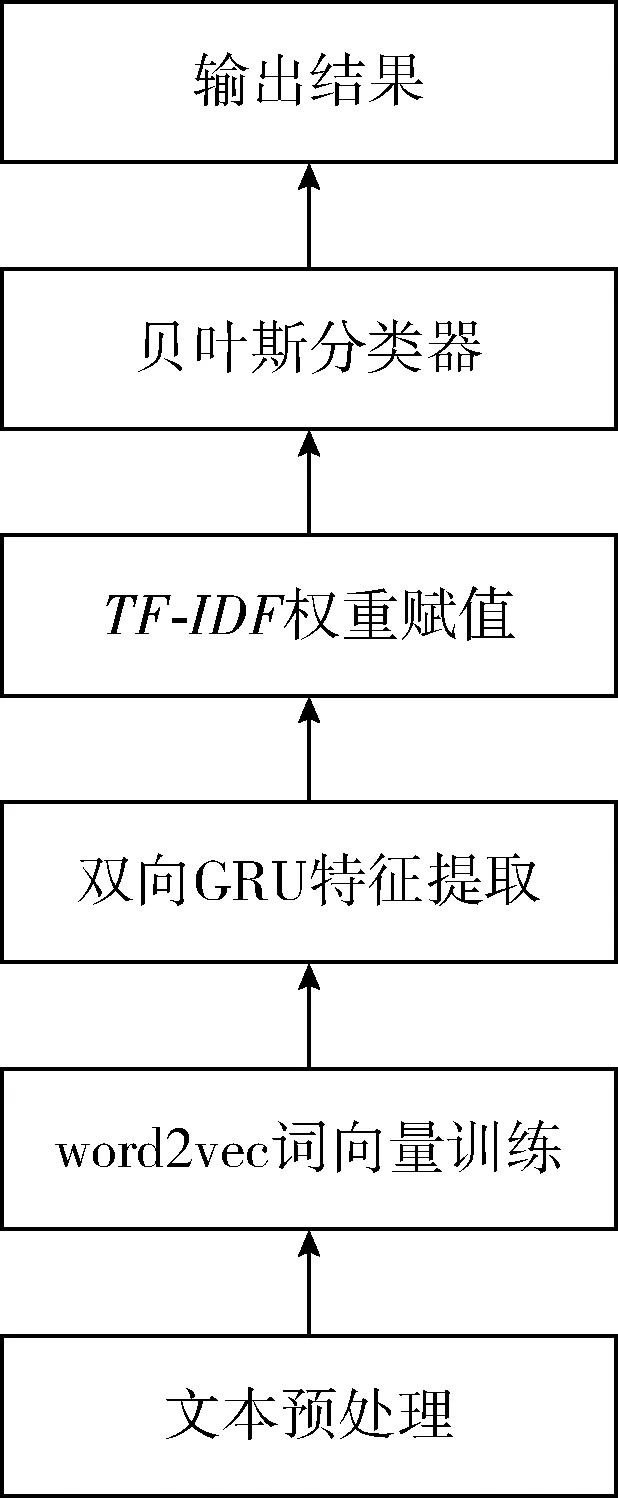
图3 混合模型框架结构
在文本分类的任务中使用该混合模型时主要包含训练,验证,测试3个过程。训练过程:首先对原始的中文文本数据集先进行文本预处理,将文本转化为适合于分类的干净的词序列后利用word2vec模型对数据集进行词向量的训练,从而将原始数据集被转化为计算机能读懂的向量形式,并计算出了各个词之间的相似程度。然后将其中用于训练的数据集对双向GRU神经网络模型进行训练,然后用训练好的网络模型提取训练集所有样本的特征,通过TF-IDF算法权重赋值后,用高权重的特征集训练贝叶斯分类器。验证过程:利用验证集中的数据对已经训练好的模型进行反复的验证和修改,使模型的分类效果更优。测试阶段:对测试集中的样本数据,通过已经训练好的双向GRU神经网络提取文本特征,利用TF-IDF权重赋值,最后将高权重的特征送入贝叶斯分类器,将模型输出的结果与文本正确的结果进行比较来判断模型的优劣。
2.2 数据预处理
在做文本分类任务时,数据预处理[13]的好坏直接影响分类结果准确率高低,由于其重要性,往往需要投入很长时间进行数据预处理。数据预处理主要包括以下内容。
(1)分词。本文用到的数据集都是中文文本,而中文文本与英文文本有很大的不同,没有明显的空格,一般都需要调用中文分词库来进行分词。
(2)去除停用词。中文文本中含有很多没有意义的虚词,例如“着”“的”,这类词称为停用词。去除掉这些词有利于提高文本分类的效率。
(3)去除低频词。在中文文本中还有一些词虽然有一定的意义,但是只有很少的文本中出现过,相对于整个文本语料库来说,这些词就没有什么实际的意义,因此这类词也要去除掉。
3 实验部分
本文所用实验环境的主要参数为处理器:Intel(R)Core(TM)i5-3230M CPU@2.60 GHz;图形加速卡:NVIDIA GeForce GT 720 M;内存:8 GB;操作系统:windows 10 企业版(64 bit);使用Google 开源深度学习框架TensorFlow构建所有神经网络模型并在anaconda软件平台上运行python程序进行训练和测试。
3.1 实验数据
本文的实验分别在主题分类和情感分类这两类文本分类任务上对提出的模型进行测试,采用的第一种数据集是在腾讯新闻上通过网络爬虫获取的,共分为科技、汽车、娱乐、军事、运动5类文本数据,共计50万条。第二种数据集是在豆瓣上爬取电影的评论,共计50万条,分为积极,中性和消极3大类。同时将数据集按照比例6∶2∶2分为训练集,验证集和测试集。实验数据见表1。

表1 实验数据
3.2 实验评价指标
在做文本分类任务时,判断文本分类结果的优劣经常会用到准确率P(Precision)、召回率R(Recall)和F1这3种评价指标。
准确率P(Precision)是衡量类别的查准率,其公式如下
(14)
式中:TP表示分类正确的文本数量;Sum表示实际分类的文本数量。
召回率R(Recall)是衡量类别的查全率,其公式如下
(15)
式中:TS表示属于该类别的文本数量。
F1值是衡量查全率和查准率的综合,以及对它们的偏向程度,因此它是由准确率和召回率计算而来,其公式如下
(16)
3.3 实验方法
在实验刚开始前,首先要对刚获取的原始数据集进行合理化的整理,其中包括剔除其中的一些噪音数据和数据预处理操作,然后将整理后的数据在通过word2vec将所有的词转化为100维的词向量用于后续模型的训练。
在实验过程中,为了能使本文提出的模型的准确率达到最优,经反复数次实验并不断调整参数,并记录每次实验结果,最终把模型效果最优情况下的各部分参数设置如下:其中隐藏层的层数为3层,隐层的节点数量为100,学习率设置为0.05,训练的迭代步数为100,迭代轮次为1000。为了防止神经网络过拟合,采用了Dropout机制,并设置了Dropout的丢弃率为0.3。同时将本文提出的模型与传统的RNN模型,LSTM模型,GRU做对比实验并且各个模型参数设置与本文的模型设置一样来验证本文模型的有效性。
3.4 实验结果与分析
实验结果见表2,表3。

表2 主题分类数据集测试结果
表2是将新闻文本进行主题分类,表3则是将电影评论文本进行情感分类,分别将本文提出的混合模型与对比模型在不同评价指标的值作对比。实验结果表明,在两类数据集上,本文方法与传统单向的神经网络相比,在准确率和F1值都有明显提高,平均高出3-4个百分点。与双向
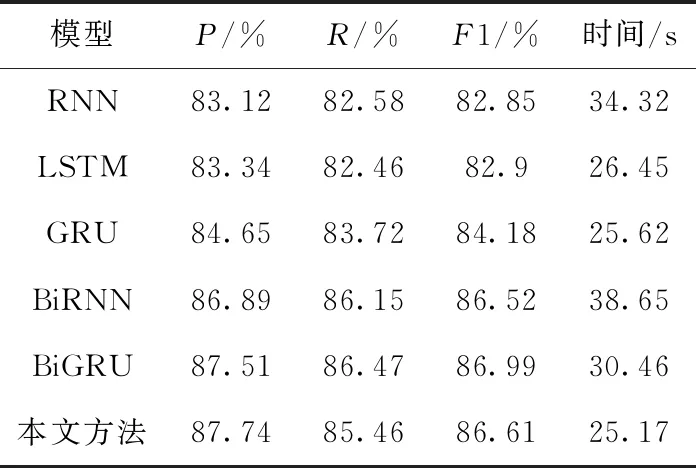
表3 情感分类数据集测试结果
的神经网络相比,虽然在准确率上差别不大,但是在模型训练的时间上,本文提出的方法也占有明显优势。这说明单向深度学习模型 CNN,LSTM 或GRU的学习能力有所欠缺导致泛化能力不高,而双向的深度模型结构复杂需要花费更长的时间训练模型。尤其在数据量比较大时模型的训练时间往往会比较长,而本文提出的模型对这些问题做了进一步的改进,并取得了不错的效果。
4 结束语
本文主要的工作是为了解决传统的神经网络模型在做文本分类任务时的准确率不高、训练时间长等问题,提出了一种基于双向GRU神经网络模型与贝叶斯分类器相混合的文本分类算法,并通过对比实验得出本文方法无论是在准确率还是运行效率上都优于单一传统的神经网络模型,说明双向GRU神经网络具有更强的提取特征的能力,再利用TF-IDF算法加权赋值,通过贝叶斯分类器分类,提高了文本的分类效率,从而表现出了该模型的优势。另外对于文本分类任务来说,文本特征提取很重要,虽然本文方法较传统方法有明显提升,但仍然有些不足之处,在今后的工作学习中,笔者将进一步优化文本特征提取的效率,争取进一步提升时间效率。
猜你喜欢
出版人(2022年11期)2022-11-15
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
法律方法(2021年4期)2021-03-16
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
铁道通信信号(2016年6期)2016-06-01
通信电源技术(2016年5期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
航天返回与遥感(2014年5期)2014-07-31
