
车联网中基于K均值聚类的拥塞控制方法
2020-03-07 12:47:40李国钦孙友伟柴永平
计算机工程与设计 2020年2期
李国钦,孙友伟,柴永平
(西安邮电大学 通信与信息工程学院,陕西 西安 710121)
0 引 言
在车联网运行中,车辆节点动态变化,路边设施(RSU)固定不动。在十字路口由于道路的时分复用,道路拥堵导致暂停车辆产生大量数据,迫使网络拥塞性能退化[1-4]。
近年来,业界有利用车辆发送信息的发射功率,公平性和优先性提出了静态D-FPAV方法和动态D-FPAV方法进行车联网拥塞控制方法,有基于车辆发送信息的发射速率的算法提高网络可靠性等方法,以及通过线性增加相邻车辆的数量来获得最小的争用窗口等算法。但上述算法均没有考虑信息的传输范围和网络冲突概率[5-8]。
针对上述问题,提出基于K-means聚类的车联网拥塞控制方法,在802.11p模型中引入拥塞控制模块同步处理高并发数据,通过K-means聚类算法对帧进行分类完成最优解决方案的计算。
1 车联网拥塞模型
1.1 车联网仿真系统架构
本文仿真实验中,MAC层和物理层的每个功能均以独立实现。由于每个车辆信息只是提取聚类算法所需的特征,所以利用多线程方法进行高并发模式下的特征提取,满足高密度车辆下的同步计算,改善了标准模型中因计算时延导致的通信拥塞情况,车辆模型架构如图1所示。信息在模型中的处理过程如下:
步骤1 物理层将接受到的信息经过地址过滤提供给MAC层接收模块;
步骤2 在MAC层查看帧间距,将帧间距不符的信息丢弃,完成分组交换到接收控制模块;
步骤3 接收控制模块将CTS和ACK帧发送到传输模块来响应接受到的RTS和DATA帧,并将CTS和ACK帧发送给传输控制模块;
步骤4 信道状态管理模块保持对信道的监听,接收帧的持续时间域和物理层信道状态,若监听到拥塞则触发拥塞控制模块的高并发数据处理模式;
步骤5 传输模块利用接收到的通信参数控制数据传输。
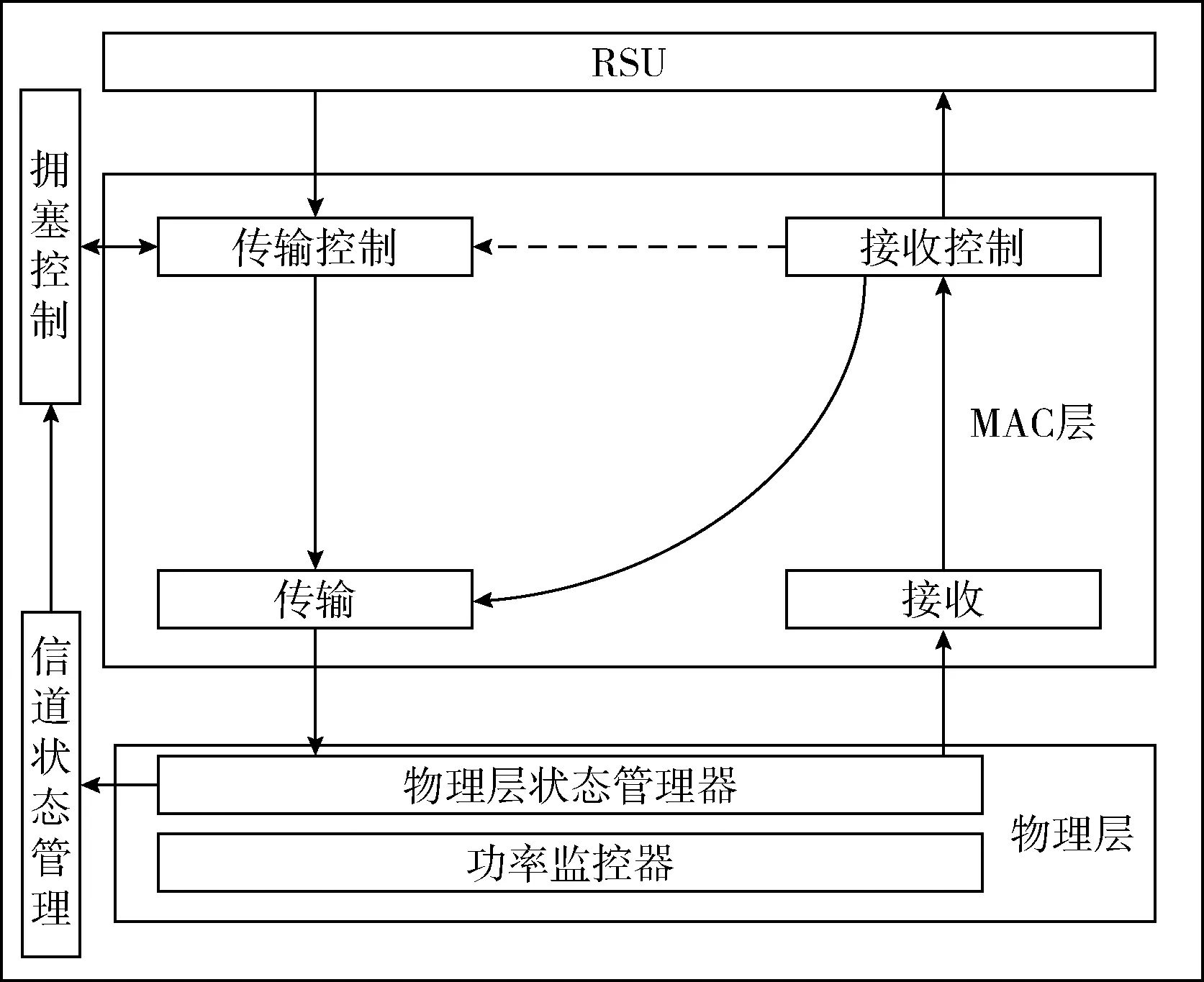
图1 车联网仿真系统架构
1.2 建立物理层模型
车联网节点r在每一时刻的累积噪声为
(1)
其中,Fr(t) 是所有在时间节点r相互干扰帧的集合。
节点接收帧时所处的SINR为
(2)
车联网广播传输满足Nakagami分布(m=3),则单跳广播分组的接收功率
(3)
其中,x表示发送者与接收者之间的距离,φ为距离表示的传输功率,单位为m。
在考虑通信密度的情况下,最终构造物理层经验模型如下
(4)
基于场景配置的拟合参数法则
(5)
其中,ε=φ·f·σ,i+k≤4。
根据上述两点,搭建十字路口下的车联网拥塞模型如图2所示。

图2 车联网拥塞模型
2 拥塞控制方法
本文提出的KCC策略包括拥塞检测,K-means均值分类和拥塞控制单元。在检测到信道发生拥塞后,利用K均值聚类算法对车辆节点进行分类,最后由拥塞控制单元将最优解决方案分发给各类节点。
2.1 拥塞检测
本文采用监控信道利用率来判断是否发生拥塞,当检测到的结果大于预先设定好的阈值时则认为信道发生拥塞,开始收集拥塞数据,本文中信道拥塞阈值为0.7[9]。
2.2 K-means聚类算法
在802.11p协议中的数据转发机制为通信范围内的节点信息先进行分簇,形成稳定的簇拓扑,再由簇头转发各簇中的节点信息。本文在网络层数据转发的过程中根据V2V的相对距离进行分簇,因此在MAC层使用K-means聚类算法进行帧分类,节省了计算车辆间的相对距离,提高了平均时延性能。
K-means聚类算法为了将车辆节点信息按照不同特征进行分类,划分为K个N={nk,i=1,2,…,k} 类,每个类nk的聚类中心ck通过N次循环迭代,使每一个节点xi到ck的相对距离欧氏距离和J(N)最小。K-means聚类算法分类过程如图3所示
(6)
(7)

图3 K-means聚类算法流程
2.2.1 数据采集
在检测到网络发生拥塞后,可以采用两种方法进行拥塞数据的收集,第一种是在检测到拥塞后100 μs内RSU收集到的所有车辆节点信息,第二种是红灯亮了以后RSU收集到的以及缓冲池中的所有数据,两种情况都会产生图2所示拥塞区域。将帧校验序列错误的信息过滤后进行聚类,在同一网络分别进行仿真,丢包率性能如图4所示,平均时延性能如图5所示。
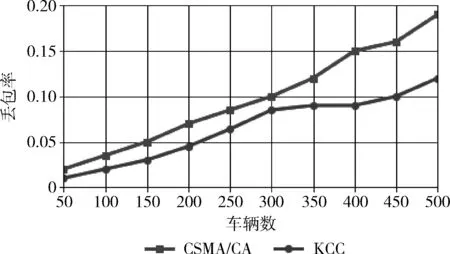
图4 不同状态的丢包率
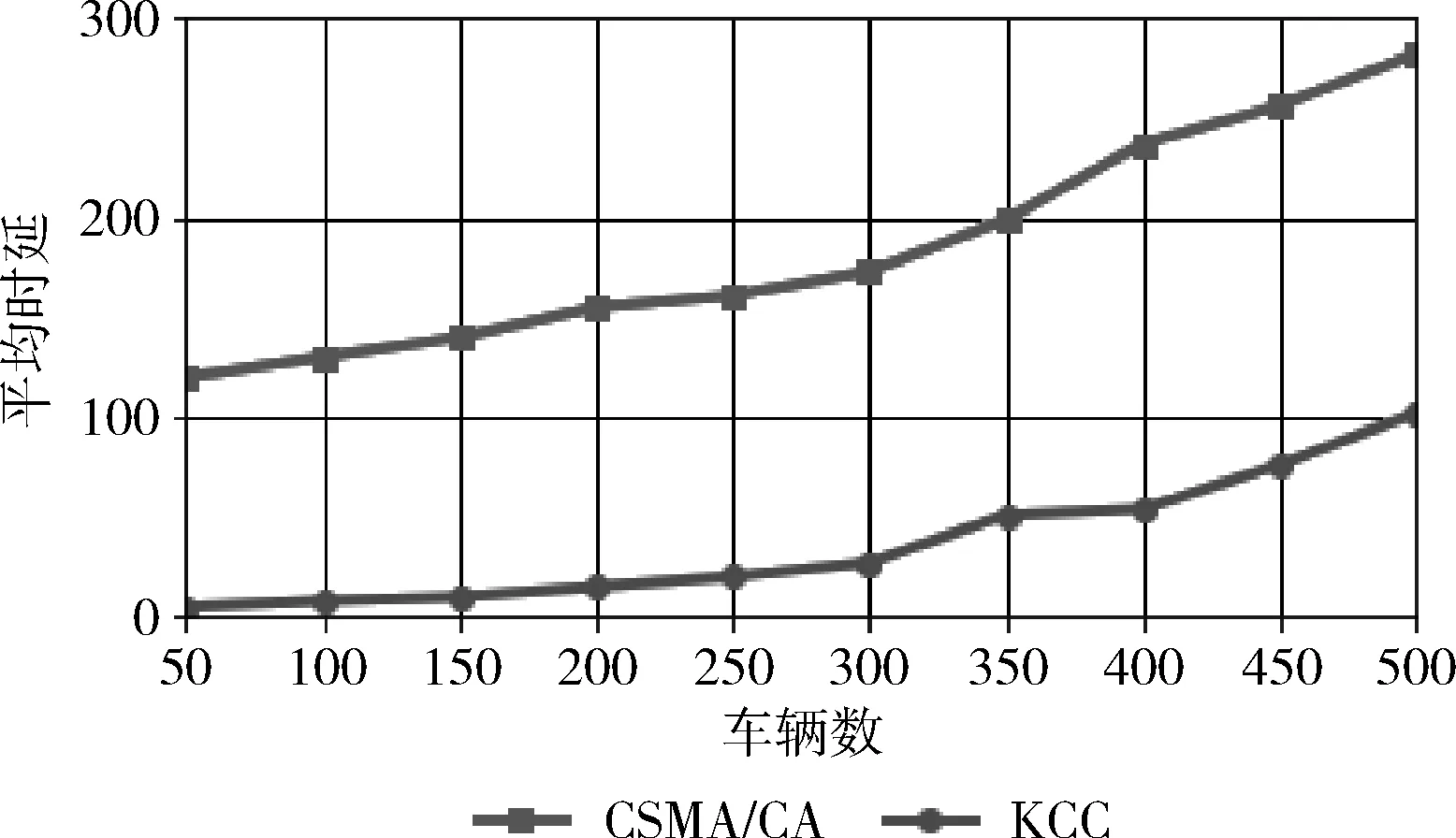
图5 不同状态的平均时延
根据上述仿真结果表明,红灯亮后的丢包率及平均时延较好,主要原因在于红灯亮后车辆处于有序的静止状态,数据转发时簇头稳定,所以本文采用红灯亮后采集到的车辆节点信息作为拥塞模型的数据。
2.2.2 特征选择
本文选择的特征为信息大小、信息种类、车辆和RSU之间的距离、信息有效性和发送端行驶方向。在车联网中,安全信息大小为300 bytes,信标信息大小为400 bytes,服务信息的大小可能为1000 bytes,1024 bytes,1400 bytes这3种情况[10]。信息有效性指在自组织网络中信息允许的最大跳数。车联网中发送的位置信息来自于GPS定位,精度为厘米级。本文进行仿真时,分别使用0001,0010和0100表示安全信息、信令信息和服务信息。使用0001,0010,0100,1000分别表示东、南、西、北4个不同行驶方向。
2.2.3 聚类种类个数
本文中对类别个数k使用贪婪准则进行选择。当网络产生冲突时最少为两类信息,所以初始化类别个数k最小为2,随着k的增大分别计算网络丢包率和平均时延,结果分别如表1和表2所示。
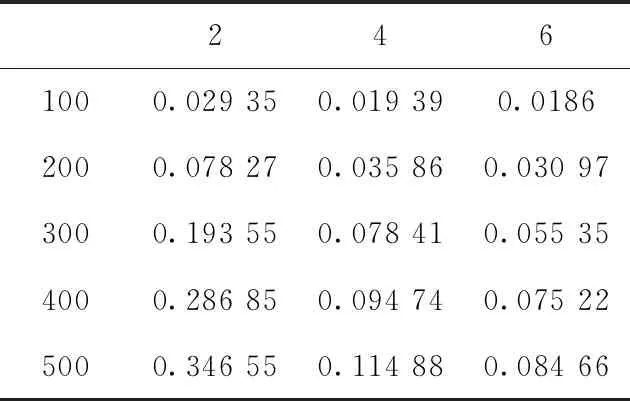
表1 系统丢包率与种类个数
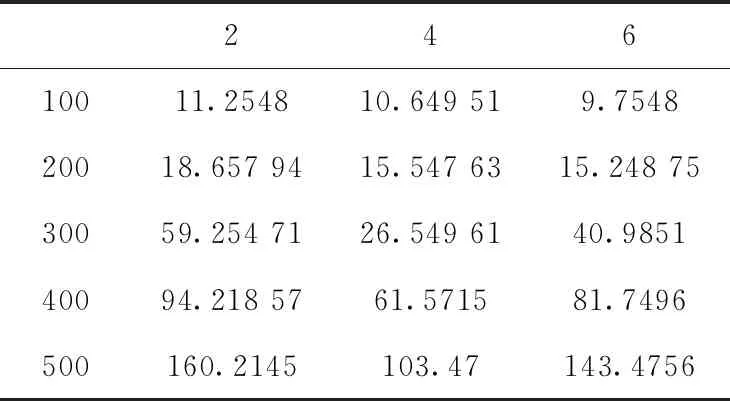
表2 系统平均时延/ms与种类个数
表1为丢包率与种类个数。结果表明,随着种类个数增加相同车辆个数下丢包率减小。表2为平均时延(ms)与种类个数。结果表明,当车辆数不大于200时,平均时延随着种类个数增加而减小,当车辆数大于200时,在种类个数为4时平均时延为最小值。因此,本文选取种类个数设置为4。
根据上述仿真结果表明,丢包率在相同数目的车辆节点下,随着种类个数的增加而减小。平均时延在大于300个车辆节点时,在种类个数为4时达到最优,主要原因为种类个数过小时,产生过多无效分组,导致多次迭代增加计算时延。种类个数过大时,计算车辆节点间的区分度复杂增加计算时延。因此,本文K-means聚类算法采用4个节点特征进行分类。
2.3 拥塞控制
本文中决定网络性能的参数为信息传输速率、传输范围、竞争窗口和仲裁帧间间隔(AIFS),其中,速率和范围是影响网络性能的主要因素。传输速率过大时使网络传输信道负载过大导致网络拥塞,传输速率过小时不能及时传递网络拓扑动态变化情况。传输范围过大时信道争用性增大且冲突概率增大影响网络可靠性,传输范围过小时导致网络边缘车辆收到的拥塞信息无效。另外,竞争窗口和AIFS的大小对网络性能也会产生影响。
根据IEEE802.11p的DSRC规定,传输速率标准值为3 Mb/s,4.5 Mb/s,6 Mb/s,9 Mb/s,12 Mb/s,18 Mb/s,24 Mb/s,27 Mb/s,传输范围的标准值为10 m,50 m,100 m,150 m,210 m,300 m,350 m,380 m,450 m,550 m,650 m,750 m,850 m,930 m,971 m,1000 m,竞争窗口标准值为(3,7),(7,15),(15,1023),AIFS标准值为1,2,3,7。
将上述4个通信参数的组合生成拥塞控制解决方案,对各类车辆节点选择最小时延和最小丢包率的解决方案,将最优方案与对应类别生成列表存入寄存器中,再次碰到相同种类节点信息直接分配最优方案。
3 仿真及结果分析
3.1 性能指标
采用平均时延,平均吞吐量,丢包数,丢包率与冲突概率综合评估本文提出的KCC方法的性能,平均时延和平均吞吐量评估算法的有效性,丢包数,丢包率和冲突概率评估算法的可靠性。
3.1.1 平均时延(T)
平均时延指从车辆开始发送数据算起,至另一车辆完全接收到该数据的时间
T=n(Tcl+Tpd+Tcs+Tcb)
(8)
其中,n为发送过程中的跳数,Tcl为处理时延,Tpd为排队时延,Tcs为传输时延,Tcb为传播时延。
3.1.2 平均吞吐量(AT)
平均吞吐量指车辆之间实际数据的传输速率,即单位时间内实际传输的数据量
(9)
其中,DATA_MAX为DATA帧中记录的数据大小。
3.1.3 丢包数和丢包率(PR)
丢包数指在车辆发送的数据中丢失的数据量。
丢包率指丢包数占车辆发送的所有数据包总数的比值
(10)
3.1.4 冲突概率(CP)
冲突概率指的是车辆发送的数据在传输过程中可能发生碰撞的概率
(11)
3.2 实验参数及参数设置
针对十字路口下的车联网拥塞场景,采用城市道路仿真软件SUMO构建曼哈顿道路模型及NS3网络仿真软件模拟交通状态,从而实现动态双向联动仿真,其中曼哈顿道路模型选取8个十字路口。表3是完整的仿真参数。
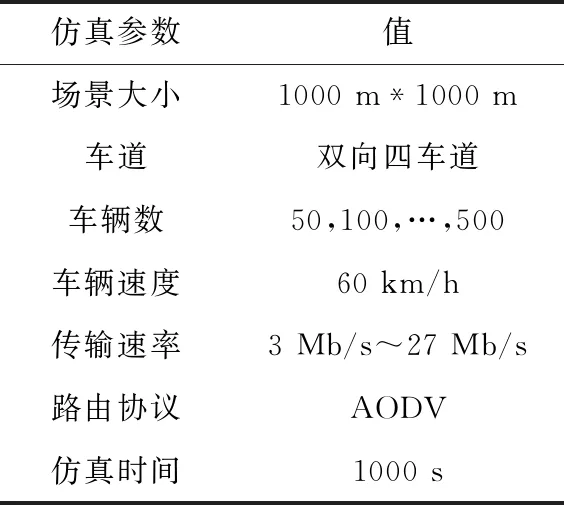
表3 仿真模型参数
为了更好地评估本文提出的策略性能,与 IEEE802.11p中的CSMA/CA进行比较,CSMA/CA的仿真实验中采用NS3提供的IEEE802.11p标准模型。
3.3 实验结果分析
图6为不同策略下平均时延性能。结果表明,当车辆从50增加到500辆的过程中,KCC策略的平均时延从 9.3 ms 增加到103.4 ms,而CSMA/CA相对应为19.4 ms增加到1054.7 ms,总体来看,KCC方法始终低于CSMA/CA的平均时延,主要因为K-means聚类算法分类时利用了网络层分簇时V2V的相对距离数据,减小了在MAC层的计算时延,从而使得网络的平均时延减小。

图6 不同策略的平均时延
图7为不同策略下平均吞吐量性能。结果表明,当车辆个数从50增加到500时,KCC策略平均吞吐量增加了27.9%,而CSMA/CA策略相对应增加了7.7%。总体来看,KCC方法平均吞吐量始终大于CSMA/CA策略,主要原因在于K-means聚类算法将相似度高的车辆节点分为一类,在拥塞控制阶段不用对每一个节点进行参数计算,增大了网络吞吐量。

图7 不同策略平均吞吐量
图8为不同策略下丢包率性能。结果表明,当500辆车时KCC策略丢包率为17.2%,而CSMA/CA策略的丢包率为57.4%,总体来看,KCC方法丢包率始终小于CSMA/CA策略,主要因为引入处理高并发数据的多线程方式,可以满足网络拓扑的动态性。
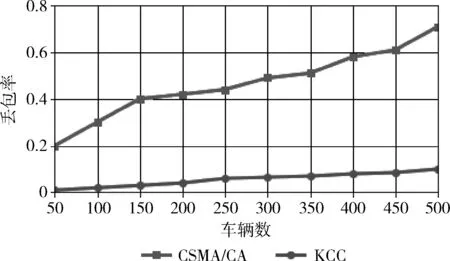
图8 不同策略丢包率
图9为不同策略下冲突概率性能。结果表明当500辆车时KCC策略冲突概率为0.18,而CSMA/CA策略的冲突概率为0.96,总体来看,KCC方法冲突概率始终小于CSMA/CA策略,多线程处理车辆节点信息的模式使得V2V之间信息交互同步,降低了因争用信道而产生冲突。
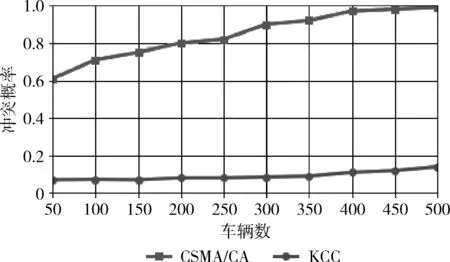
图9 不同策略冲突概率
4 结束语
本文提出基于K-means聚类的车联网拥塞控制方法,解决十字路口下车辆密度过大时造成的车联网拥塞问题。本文基于IEEE802.11P协议的车联网仿真架构在处理车联网拥塞发生时的大规模数据时引入多线程处理模式,使得V2V通信同步。拥塞检测单元根据信道的使用情况判断是否发生阻塞。K-means聚类时利用网络层分簇的相对距离数据减轻MAC层计算负载,降低网络的平均时延。拥塞控制单元确定各类网络拥塞参数:传输速率、传输范围、竞争窗口和仲裁帧间间隔形成最优解决方案存储在寄存器中,为同种类节点节省计算时延。综合NS3与SUMO的动态双向联动仿真实验结果,KCC策略的平均时延降低,吞吐量增大,丢包率减小,冲突概率减小。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17 06:27:42
计算机与数字工程(2022年1期)2022-02-16 08:32:54
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
电讯技术(2018年10期)2018-10-24 02:35:00
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
