
基于姿态机和卷积神经网络的手的关键点估计*
2020-03-04 05:13张风雷
计算机与数字工程 2020年1期
张风雷
(武汉邮电科学研究院 武汉 430074)
1 引言
现今主要的人机交互媒介为鼠标和触摸屏;在混合现实时代,主要的人机交互媒介将为手[1~2]。故而,学术界和产业界都在积极开展与手有关的计算机视觉研究,手的关键点估计也成为近年来的研究热点之一。所谓“手的关键点估计”是指根据一张包含手的RGB图像,估计手的关键点在图像上的位置。
姿态机[3](Pose Machine)是一种成熟的2D 人体姿态估计方法,其具有强大的对人体关键点间复杂的上下文关联的表示力(representation power)。卷积神经网络广泛应用于计算机视觉领域中,其具有出色的图像特征提取能力[4~5]。
本文提出了一种基于姿态机和卷积神经网络的手的关键点估计方法。该方法的要点如下:
1)鉴于手的关键点估计和2D人体姿态估计的相似性,将姿态机应用于手的关键点估计问题;
2)为了利用卷积神经网络的出色的图像特征提取能力,用卷积神经网络来实现姿态机的各个组件。
本文比较了该方法与目前先进的手的关键点估计方法Multiview Bootstrapping[6];测试表明,两者具有相当的预测性能。
2 推断机和姿态机
本节按照发展脉络,依序介绍推断机[7](Inference Machine)、姿态机。
2.1 推断机
概率图模型广泛应用于计算机视觉中,对其中的大多数来说,精确的推断难以实现,从而需要采用 MCMC(Markov Chain Monte Carlo)、置信传播(Belief Propagation)等近似推断算法。
推断机将消息传递(message-passing)类的概率图模型近似推断算法(如置信传播)视为依次在图模型中某些节点进行的分类过程的序列。
假定因子图G,令 x1,x2,…为G中的变量节点,a1,a2,…为G 中的因子节点;令 ne(d)为与节点d相邻的节点的集合,φa(Xa)为因子节点a的势函数。
置信传播算法中变量节点至因子节点、因子节点至变量节点的消息分别如式(1)、式(2)所示:

消息传递过程收敛后,变量节点的分布如式(3)所示:
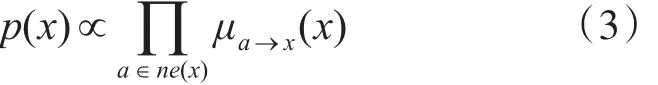
将式(2)分别代入式(1)、式(3),得到式(4)、式(5):

式(4)可 视 为 输 入 为 {μy→b|y∈ne(b)x,b∈ne(x)a},输出为 μx→a的分类过程;式(5)可视为输入为{μy→b|y∈ne(b)x,b∈ne(x)},输出为 p(x)的分类过程;如此,置信传播可视为依次在G中所有变量节点进行的分类过程的序列。
图1为置信传播中进行的两种分类过程的示意图。
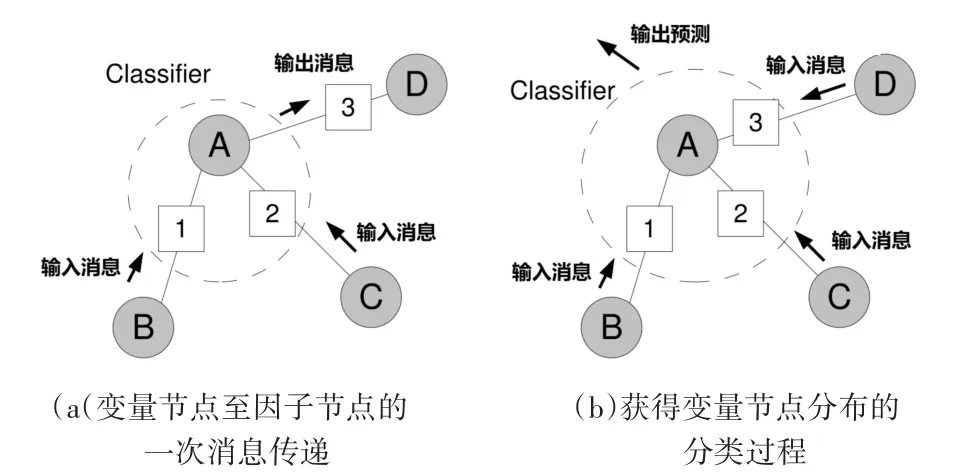
图1 置信传播中进行的两种分类过程的示意图
图2 为将概率图模型展开为分类过程的序列的一个例子。深色方块表示变量节点至因子节点的一次消息传递,如深色方块A1表示变量节点A至因子节点1的一次消息传递;浅色方块表示获得变量节点的分布的分类过程,如浅色方块A表示获得变量节点A的分布的分类过程;方块间的箭头表示过程间的依赖关系,如浅色方块A以C2、B1两者的输出为输入。

图2 将概率图模型展开为分类过程的序列的一个例子
于是,用置信传播算法训练一个概率图模型可视为训练一组分类器。
更进一步,不将分类器的形式局限于式(4)、式(5),就能使用Logistic回归、支持向量机等各种分类算法。
概率图模型大多显式地建模变量节点间的上下文关联;与之不同,在推断机中,变量节点间的上下文关联由分类器在训练过程中“习得”。事实上,推断机的(潜在的)表示力等价于一个变量节点间全连接的概率图模型。
在消息传递类的概率图模型近似推断算法中,消息的传递可以是同步的,也可以是异步的;对应地,推断机分为同步推断机和异步推断机两种。
2.2 姿态机
姿态机将推断机应用于人体姿态估计。推断机并不对概率图模型中的变量节点间的上下文关联显式地建模,而是让其由分类器在训练过程中“习得”,这使得姿态机在人体姿态估计中具有比概率图模型更强的表示力。
姿态机将人体姿态估计视为一个结构化预测问题:令输入图像的宽度、高度分别为W、H,令人体关键点的个数为 P ,令 Z={(x,y)|x∈[0,W),y∈ [0,H)},则输出为 Y=(Y1,…,YP),其中 Yp∈Z为第p个关键点在图像上的位置。
姿态机可视为一个同步推断机,其中的变量节点为Y1,…,YP。姿态机的推断过程分为T个阶段,每个阶段对应于一轮消息传递;对t=1,…,T,“多类”分类器gt根据输入图像的特征,以及前驱阶段的“多类”分类器的输出,得到Y1,…,YP的“置信图随着t的增大,分类器给出变量节点分布的渐进改善的估计,如式(6)所示。

图3为姿态机的示意图,图中只画出了前两个阶段。
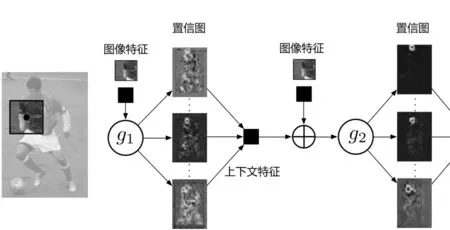
图3 姿态机的示意图
3 卷积神经网络的结构设计与训练
3.1 卷积神经网络的结构设计
鉴于手的关键点估计与2D人体姿态估计的相似性,本文将姿态机应用于手的关键点估计问题。用于手的关键点检测的卷积神经网络结构的设计思路如下:对姿态机的每个阶段,将其中的特征提取器和分类器用一个卷积神经网络来实现。经过反复实验、分析、改进,得到如表1所示的卷积神经网络结构。“Conv.”表示卷积层,“ks=3,nf=64”表示卷积核的尺寸为3×3,卷积核的个数为64;“max_pool”表示池化层,“池”的大小为2×2。

表1 用于手的关键点估计的卷积神经网络结构

名称 类型 参数 “尺寸”conv6_1 conv6_2 conv6_3 conv6_4 conv6_5 conv6_6 conv6_7 ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=1,nf=128 ks=1,nf=21(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,21)(32,32,149)conv7_1 conv7_1 conv7_1 conv7_1 conv7_1 conv7_1 conv7_1 Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Concat(conv4_7,conv6_7)Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU Conv.+ReLU ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=7,nf=128 ks=1,nf=128 ks=1,nf=21(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,128)(32,32,21)
表1所示的卷积神经网络由3个阶段组成。conv1_1至 conv5_2为阶段 1,其中 conv1_1至conv4_7用于提取图像特征;conv6_1至conv6_7为阶段2;conv7_1至conv7_7为阶段3。分别对conv5_2、conv6_7、conv7_7进行双线性插值,将其“尺寸”缩放为(256,256,21),得到手的21个关键点在图像中的位置的“得分图”score_maps5_2、score_maps6_7、score_maps7_7。
3.2 训练
训练数据来自数据集 Rendered Hand Pose[8]和数据集Stereo Hand Pose[9]。为了适配本课题的需求,分别对两者进行了简单的预处理,得到数据集R(包含43986个实例)、数据集S(包含36000个实例)。数据集R和数据集S中的实例包含的项如表2所示。
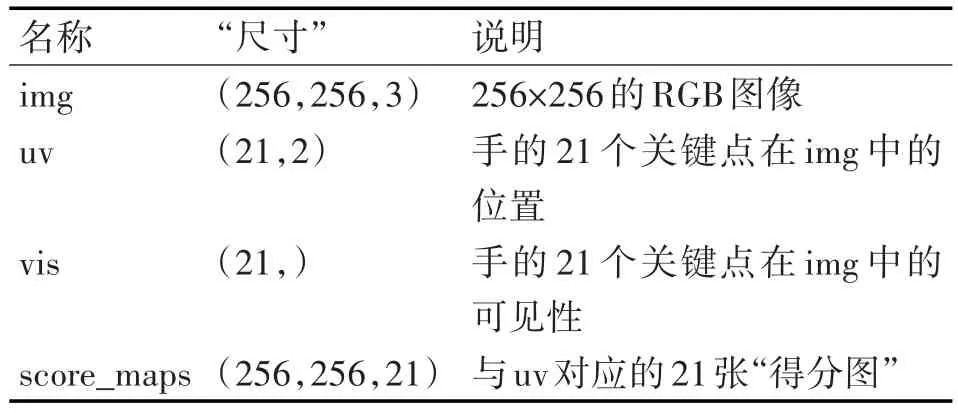
表2 数据集R和数据集S中的实例包含的项
损失函数定义为score_maps与score_maps5_2、score_maps6_7、score_maps7_7的“差异”之和。
具体的训练过程如下:
1)将数据集R按9∶1的比例划分为训练集R-train和验证集R-val,将数据集S按8∶2的比例划分为训练集S-train和验证集S-val;
2)用数据集R-train、S-train联合训练(交替地将数据集R-train、S-train的实例输入系统),说明如下:批的大小为8;优化方法为Adam;总共迭代30000次;学习率为中为n迭代次数。
对score_maps7_7—手的21个关键点在图像中的位置的“得分图”—中的每张“得分图”,取其中“亮度”最高的点的位置为其对应的手的关键点在图像中的位置。如此,便由score_maps7_7得到uv7_7—手的21个关键点在图像中的位置。
评估模型的预测性能的指标为其估计的手的关键点在图像中的位置的平均偏差ℱ。图4为训练时模型的ℱ曲线,横轴为迭代次数(单位为k),竖轴为ℱ的值(单位为像素)。

图4 训练时模型的ℱ曲线
4 测试及问题分析
4.1 测试
作者用若干张包含手的RGB图像测试了本文提出的手的关键点估计方法的预测性能。
图5是手的关键点估计成功的一个例子,输入图像为2018年1月作者拍摄的自己的右手。

图5 手的关键点估计成功的一个例子
图6 是手的关键点估计失败的一个例子,输入图像为2018年1月作者拍摄的自己的右手。
通常用PCK曲线来评估手的关键点估计方法的预测性能;若PCK曲线上有一点(6,0.10),则表示估计出的关键点中有百分之十与其真实位置的距离小于6像素。

图6 手的关键点估计失败的一个例子
作者比较了本文提出的方法与当前先进的手的关键点估计方法Multiview Bootstrapping的预测性能,图7为两者的PCK曲线,可以看出两者具有相当的预测性能。
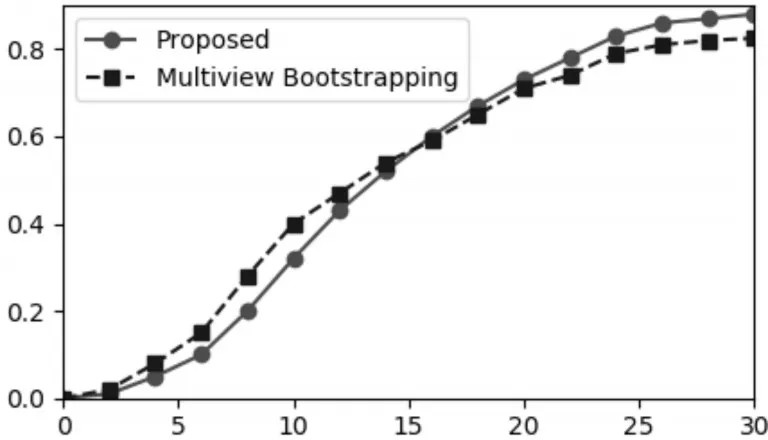
图7 本文提出的方法和Multiview Bootstrapping方法的PCK曲线
4.2 问题分析
本文提出的手的关键点估计方法是数据驱动的,这意味着训练数据的质量对其预测性能至关重要[10~12]。数据集R、S存在手势的多样性不够的问题,尤其是手指间有重叠的实例十分少见;这解释了图6中手的关键点估计的失败。
5 结语
本文提出了一种手的关键点估计方法,其将姿态机应用于手的关键点估计问题,并用卷积神经网络来实现姿态机的各个组件。测试表明,本文提出的方法具有与目前先进的手的关键点估计方法相当的预测性能。
进一步的研究应当着力于探讨如何获取高质量的训练数据。获取训练数据的方式有以下两种:1)利用3D建模软件(如Blender)和游戏引擎(如Unity),在“虚拟世界”中合成[13~15];2)通过摄像机等设备,在“真实世界”中采集,再由人工标注。方式1)成本低(绝大部分工作可自动化),且数据精度高;方式2)成本高(需要耗费大量人力),且数据精度低。通常用由方式1)获取的数据和由方式2)获取的数据联合训练,以利用后者补偿前者中“虚拟”与“真实”的差异,这对于保证系统在“真实世界”中的预测性能是十分重要的。用方式1)获取高质量的训练数据的关键是可编程的手的3D模型组件,通过将其设定成各种不同的手势,“融合”进各种不同的“虚拟场景”,以实现数据集的多样性,这可以作为进一步研究的一个课题。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
计算机系统应用(2021年2期)2021-02-23
学生天地(2020年3期)2020-08-25
广东教育·高中(2017年10期)2017-11-07
软件导刊(2017年4期)2017-06-20
诗选刊(2015年4期)2015-10-26
新高考·高一物理(2015年5期)2015-08-18
