
自然场景图像中的中文文本提取*
2020-03-04 05:13珂戴舜姜沫岐
计算机与数字工程 2020年1期
肖 珂戴 舜姜沫岐
(1.北方工业大学计算机学院 北京 100144)(2.北京控制工程研究所 北京 100190)
1 引言
智能手机的极大成功和基于内容的图像搜索或理解的庞大需求,使得自然场景图像中的文本检测最近备受关注,并且已经成为了一项关键性的任务。虽然已经提出了许多方法(例如文献[1~3]),但这个任务仍然未被解决。困难主要来自文本的多样性(例如语言,字体,大小,颜色,方向,噪声,照明,低对比度,遮挡等)以及背景的复杂性。
现有文本提取方法可以分为三种:基于滑动窗口的方法,基于连接分量(Connected Component,CC)的方法[1~2]和混合方法[3]。基于滑动窗口的方法[4]通常利用固定大小的滑动窗口来搜索图像中的单个候选字符或候选字词[5],然后使用机器学习技术来识别文本。尽管这样的方法对于噪声和模糊是鲁棒的,但是由于大的搜索空间使得它们的速度偏慢。基于CC的方法首先通过使用图像的局部属性(例如强度,颜色和笔画宽度)从图像中作为字符候选提取CC,然后通过使用字符或文本行的属性来去除非文本CC。Minetto等[6]提取对应于在Sobel边缘图中由基于梯度矢量流的方法识别的主像素的边缘分量作为候选文本。Epshtein等[7]在笔划宽度变换图上将具有相似笔划宽度的相邻像素分组为候选文本。Matas等[8]通过提取最大稳定极值区域作为候补文本,进而分类来解决文本检测问题。混合方法[9~10]试图组合滑动窗口和基于CC的方法的优点,以便实现高鲁棒性同时保持低计算量。
在这些方法中,基于CC拓展的方法针对英文的文本检测在ICDAR竞赛中已有很好表现[11]。而将该类方法针对中文的文本提取,并不能达到它们针对英文时的优越性能。由于中文的单个字符并不像英文那样以单个CC的形式,加上文本提取中的一些公开性问题,如光照不均和非文本的形状非常类似于文本字符,针对中文的文本提取很难达到满意的效果。为了针对上述问题,本文提出了一种基于ISODATA聚类和SVM结合的自然场景中文文本提取算法,先用基于ISODATA聚类提取候补文本CC,聚合候补文本CC得到中文候补文本域,再根据文本域的特征将其聚合成候补文本行,最后机器学习剔除非文本的行的方法。
2 自然场景图像中文本特征分析
自然场景中的文本,通常具有对场景中其他物体解释或提示的意义,为了让人眼易于观察,文本和背景的对比度通常是显着的,且每个字符具有均匀灰度或颜色。但由于视点和照明变化等外面因素的影响,造成了如图1(a)图像中文本的灰度不均匀。且在自然场景中,由于文本背景和场景元素的多样性,出现了如图1(b)图像中文本的背景边缘丰富,使得文本的边缘特征不显著,这样分割出候补文本会给之后的分类步骤带来很多的困难。

图1 含有文本的自然场景图像
3 文本提取算法
本文提出的文本提取算法的流程如图2所示。首先,使用改进的NiBlack算法从图像中初步的分割出前景,再以CIE Lab空间颜色信息和笔画宽度信息为特征,使用基于ISODATA聚类算法对图像进一步分割(3.1节)。对连通分量(CC)进行分析,并使用几何特征的约束(例如纵横比和孔洞数)对所得到的CC进行过滤(3.2节)。对于过滤后的CC进行中文聚合,由于图像中的中文文本往往会被分割成多个CC,使分散的笔画形成候选中文文本(3.3节)。候选文本形成文本行,其中拒绝笔划特征和空间特征不满足约束的候选文本(3.4节)。最后,对文本行进行SVM分类,得到正确的文本行及对应的正确文本(3.5节)。
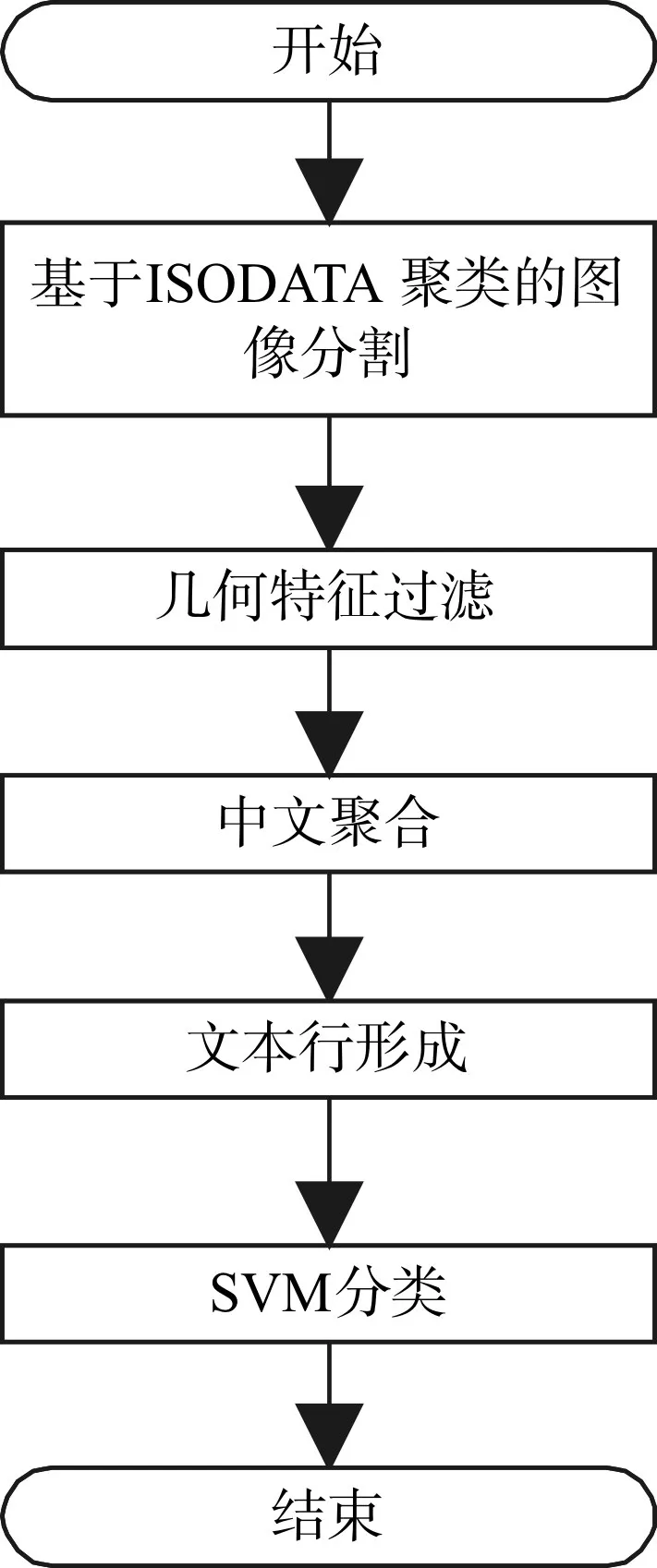
图2 算法流程图
3.1 基于ISODATA聚类的图像分割
3.1.1 ISODATA算法简介
ISODATA算法是一种无监督的动态聚类算法,它在K-means聚类算法的基础上,在聚类过程中增加了“分裂”和“合并”两个操作,使其能利用中间结果所取得的经验修正聚类类别数目,从而取得更好的聚类效果,弥补了K-means算法需要提前固定聚类类别数目的缺陷,具有更好的适应性。ISODATA聚类的目标函数与K-means聚类相同,如下:
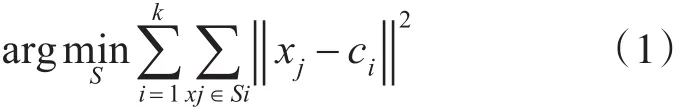
其中k代表最终得到的类别数,S为聚类的类别集合,xj是Si类的每一个样本,ci是Si的类别中心。而ISODATA聚类的“分裂”操作和“合并”操作具体原理如下:
1)“分裂”操作
首先,计算每个聚类类别中每一维特征的标准差,对每一个类别Si,用下列公式求标准差:

式中xjm是Si类中的第j个样本的第m个特征,cim是类别Si的第m个特征的值;σim是类别Si的第m个特征的标准差,m是样本的维数,Ni是类别Si中的样本数。找到每个特征中标准偏差最大的值:若对任一个σimax,存在 σimax>θs,θs为特征最大标准差。则把类别Si分裂为两个类,其中心对应为并取消原中心ci。的计算方法为,其中0<h≤1。
2)“合并”操作
计算所有聚类中心之间的距离:
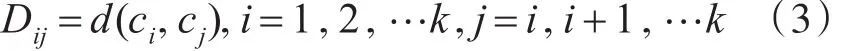
之后比较Dij和特征最小标准差θc,把小于θc的Dij按大小作升序排列,从最小的Dij开始,对于每个Dij合并两类ci和cj,聚类中心为

3.1.2 聚类样本裁剪
传统的基于聚类的图像分割方法,是以图像中所有的像素作为样本集,由于自然场景图像中背景的复杂性,大量背景像素存在样本集中,会使得样本间相似性测量困难,不利于类的形成,影响聚类的效果。考虑到提取图像的前景像素,本文改进了NiBlack算法,使得算法在原本对光照具有良好适应效果的同时,减少了噪点的影响。改进后,算法对图像的背景和前景进行了初步有效的分割,使聚类只需针对前景像素进行,减少了聚类的时间开销。公式定义如下:

式中 I为预处理后的图像,μ(I,w)是模板尺寸为W*W均值滤波器,σ(I,w)表示模板尺寸为w*w的标准差滤波器,模板宽度w为图像宽度的1/20。由于分割的目的是区分前景和背景,而前景的标准差相对较大,本文设k值为图像所有像素标准差的均值,通过该算法对图1(b)进行处理可以得到了存在两个前景层的图像,如图3所示。

图3 局部阈值分割后的效果展示
3.1.3 基于聚类的图像分割
考虑到场景图像中文本的颜色和笔画宽度的相似性,本文提出用ISODATA算法对改进的Ni-Black算法分割出前景像素点进行聚类,并利用像素点在CIE lab空间中颜色特征,以及笔画宽度变换图像中的笔画宽度特征作为聚类特征。
在最近的一些研究中强调了笔画宽度信息的重要性[12~13]。由 Epshtein 的关于笔画宽度变换(SWT)的工作,通过沿着梯度从边缘像素发射射线,并且仅当光线被具有相反梯度方向的另一边缘像素终止时保持光线,它提供了一种从边缘映射直接发现连接组件的方法。从前一个步骤初步过滤后的二值图像得到边缘图。不同于原方法中由原灰度图像产生边缘图像,这样做有两个优点,第一使已淘汰的非文本域的边缘不会再出现,从而减少了SWT的计算量,因为SWT局部算子会对每个边缘点进行运算。第二减少由于光照等原因,从原图像中提取出一些虚假的边缘。
利用上述方法得到的笔画宽度,以及从RGB空间图像转化得到的LAB分量值即可进行ISODATA聚类。ISODATA算法基本步骤如下:1)初始化控制参数值。2)用最小距离法对全体样本进行聚类。3)按给定的要求,将前一次获得的聚类集进行“分裂”操作或者“合并”操作,从而获得新的聚类中心。4)重新进行迭代运算,计算各项指标,判断聚类结果是否符合要求。经过多次迭代后,若结果收敛,算法结束。
本文以一个像素点的作为一个样本,特征值包括该像素点归一化之后的L、A、B分量值,以及笔画宽度值。以改进的NiBlack算法分割出所有前景像素点作为样本集进行ISODATA聚类。聚类后的结果如图4所示。

图4 ISODATA聚类后的图像
3.2 几何特征过滤
由前面的处理,获得聚类后的图像,对其进行连通域搜索,搜索过程中对相邻像素加上聚类类别的限制,即保证连通域中像素都属于同一类别。在这些CC中,有一部分虽然它们拥有和文本类似的灰度比及颜色特征等,但它们不具有和文本相似的几何特征,并且可以根据这样的特征,快速并简单地将它们过滤。
首先,面积以及长宽非常大和非常小的对象被拒绝,且笔画宽度标准差大于笔画宽度均值的一半的对象同样被拒绝。用area(CC)表示连通分量的面积,ImgWidth和ImgHeight分别代表被处理图像的宽和高,varSW(CC)和 meanSW(CC)代表连通分量笔画宽度标准差和笔画宽度均值,则不满足以下公式的将被过滤。
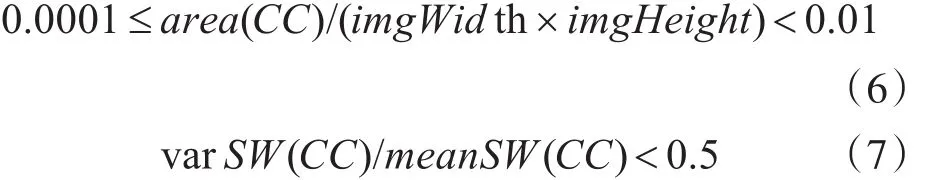
然后,由于大多数中文是由多个CC组成,分析中文的字体结构,拒绝具有非常大和非常小的宽高比的CC,以确保在过滤的同时,不丢弃诸如‘一’和‘引’的一些细长的部分。用W和H表示连通分量的宽和高,则不满足以下公式的将被过滤。

最后,消除包含大量孔洞的对象,中文的单个笔划和偏旁部首中不具有许多孔洞,因此这样的CC不可能是中文笔划或者部首的候选。初步过滤后的结果如图5所示。

图5 初步过滤后的效果
3.3 中文聚合
中文字符不同于英文字符的一笔而就,它通常是由多个连通分量组成,需要将图像分割后得到的连通分量聚合成候补的文本区域。对此,本文提出中心聚合的方法,步骤如下:
1)统计连通分量的属性,得到每个CC被包含的最小矩形,称为包围盒,它记录了CC的左上点的坐标以及宽和高。并得到每个CC的质心坐标。
2)约束合并范围,汉字被称为“方块字”,是由于单个汉字通常拥有相近的高和宽,除了“一”等特殊的汉字。由此,对合并加上一个空间约束,即每个待处理的CC只考虑以它的质心,上下和向右延伸m倍的平均笔画宽度的范围内的CC,作为备选的合并结构。为了避免背景的类似结构误入,添加了另外两个约束,颜色和平均笔画宽度,因为在场景图像中,方便人们辨识文字,字体的各个结构会具有相似的笔画宽度和颜色。
3)初步相交合并,由于中文的特性,无论是书写还是印刷体,为了不让汉字的偏旁部首,被误判成相邻汉字的一部分,相邻字体之间会有一定距离,而这个距离会比字体的部首结构之间距离大很多。这个距离的差距对将字体的结构合并成一个完整的字体很重要,因为它有利于将正确的笔画结构归并到字体中。在合并判断时,我将所有情况分为两种,相交和相邻。遍历被处理的CC的合并范围内的CC,首先根据以下公式判断两个CC的包围盒之间是否相交:

其中,W和H表示连通域的宽和高。CC_t,CC_l,CC_b,CC_r分别表示连通域包围盒的左上角和右下角的横纵坐标。如果满足式(9)就进行合并操作,将已经合并的CC标记。
察尔汗地区的盐岩中大都以层状似层状产出,但其的杂质含量不一,泥质夹层分布不均匀[12],得到的试件中的夹层也不能保证夹层大小一致且分布均匀。在试验中选取试样时从同一块岩石中钻取岩芯,这样得到试验结果只能表明试样表面的泥质夹层的含量及厚度大致一样。且目前的技术手段很难判别试样内部夹层的具体分布[13-14],无法研究夹层厚度对盐岩力学特性的影响程度,这也是目前研究的难点所在,因此本文假定内部泥质夹层是均匀分布的。通过对野外采集的两类盐岩进行单轴压缩试验,天然和卤水饱和两种状态下盐岩的破坏过程、全应变-应力曲线、强度特性、质量差与强度的关系等方面研究与分析,得到主要结论如下:
4)遍历完合并范围内的CC后,如果合并范围的CC没有全部被标记,则对未被标记CC再次进行相交判断,相交即合并,并标记。因为第一次相交合并时,被处理的CC被扩大,可能造成与原本未相交的CC开始出现相交。
5)此时如果合并范围内的CC仍未被完全标记,则进行相邻合并,当CCi和CCj满足:
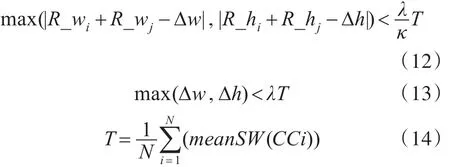
其中N表示约束范围内连通域的总个数,经试验k和l设置为2.5和10效果最佳。通过限制合并集合的宽和高,避免邻近的包含完整字符的CC被合并。中文聚合的效果如图6所示,由于不同类别的CC 不会并相互合并,所以图 6(a)、(b)展示了具有代表性的某一类别CC的中文聚合情况。


图6 中文聚合的效果展示
3.4 文本行形成
大多数类文本对象具有与真实文本对象类似的局部结构,因此难以仅通过字符级的过滤器来区分。而文本行是文本存在的重要提示,因为文本几乎总是以直线或轻微曲线的形式出现。为了检测这些行,本文参考类似于文献[8]中的过程,首先使用以下规则将上述中文聚合后候选字符配对成组。由于属于同一文本行的字符被假定为具有相似的笔划宽度和字符宽度(不同于英文利用高度,中文存在“一”等特殊字体),如果它们的笔划宽度中值的比率小于1.5,并且它们的宽度比率小于1.2,则两个让两个候选者配对成组。另外,如果两个候补字符平均颜色相差很大的不配对。
随后,将成对连接的字符候选的聚类形成文本行。将直线拟合到每个聚类内的字符候选对的质心得到候选对的斜率,将距离相近,斜率、颜色和笔划宽度相近似的候选对分配到具有最大数目的文本候选对中,从而形成文本行,连接效果如图7所示。

图7 文本行连接的效果展示
3.5 SVM分类
在形成文本行后,一些非文本的行也可具有文本行与相似的属性或纹理,因此需要进行验证。在这里,本文提出用文本行级的一些特征描述符,进一步用SVM分类出这些类似文本的离群体。几何特征和空间分布是用于生成文本行的高级表示的关键信息。此外,由于每个分量由一组像素组成,所以它还可以为文本行提供有意义的统计特性。在获取特征时,将文本行中的字符分量看作最小的单位来计算出不同类型的分量特征。用N表示文本行中候选字符分量的个数,相关特征如下所述:
1)LAB颜色空间下文本行颜色方差。类似灰度值,候选字符的平均颜色分量,则颜色方差实际上分别是三个通道下对应值的方差;
2)笔划宽度方差。由每个候选字符的平均笔画宽度得到;
3)平均密度。文本行中候选字符分量中的笔画像素的占用百分比的平均值;
4)分量尺寸方差。文本行中的字符应具有相似宽度,它可以由文本行的高度归一化,因为中文字符近似正方形;
5)相邻分量中心夹角余弦值的方差。夹角是通过从当前分量到下一个的中心的方向进行测定,最后一个组件的值设置为与之前相同的值;
6)平均结构相似度。文本行中的字符彼此具有相似的结构,而类文本行通常具有几乎相同的结构,结构相似度为两个坐标分量的链码形状描述符的相似度;
7)相邻分量之间的水平距离的方差。从当前分量到下一分量,由两个分量中心的水平坐标归一化测量。
经过分类,去除标记出的非文本行。最后得到效果如图8所示。

图8 SVM分类后的效果展示
4 实验结果
现有的研究者公认的数据集为ICDAR竞赛的数据集,但它针对的是英文文本,而本文针对的是中文。为此在分析ICDAR数据集之后,参照其难易程度,建立了一个包含300幅针对中文文本的自然场景图像的数据库,图像分辨率的范围从860×640至2048×1536,包涵了真实环境下各种不同的场景和不同的条件。并采用ICDAR竞赛的评估标准,对本文中提出的算法进行测试和评估。图9是算法的一些有代表性的实验结果。
本文的实验平台为戴尔台式计算机,其CPU为Intel core i5的处理器,运行内存为8G,实验开发工具为Matlab 2015b。

图9 算法效果展示
对自建的数据集进行测试和评估,利用评估标准的三个参数,即精确率(Precision)、召回率(Recall)和综合评价指标f来评估本文的方法,它们的表达式为

其中NP表示提取出总的字符数,TP表示提取出正确的字符数,TM表示图像中正确的字符数。精确率和召回率的相对权重由参数α控制,其被设置为0.5。将本文的算法与近几年前人针对中文文本的算法进行对比,且这些针对的自建库与本文中提及的库难度相似,结果如表1所示。

表1 算法在自建库上的对比
由上表可以看出,本文的算法在自建库上具有较好的提取效果,精准率和召回率比前人的算法有一定程度的提高。
5 结语
本文针对现有算法的中文提取效率不足的问题,提出了一种新的结合局部灰度和颜色特征和机器学习的文本提取方法。首先通过改进局部分割算法与基于ISODATA聚类算法,分割出类文本区别,并减少了光照对字符提取的影响。其次,通过分析中文结构特点,提出了高效的中心点中文聚合的方法得到中文字符后,对字符候补链成文本行后,利用文本行级的特征属性,经过SVM分类后实现中文文本的提取。通过对算法性能的测试和评估,结果表明,本文提出的算法具有较高的精准率和召回率,且综合性能较高。
猜你喜欢
电脑报(2021年41期)2021-11-04
读者·校园版(2020年19期)2020-09-16
电脑知识与技术(2019年29期)2019-12-16
当代陕西(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
人生十六七(2015年5期)2015-02-28
农机使用与维修(2014年10期)2014-10-23
销售与市场·管理版(2009年21期)2009-09-03
