
基于服务质量和恶意结点消除的云计算环境信任模型分析*
2020-03-04 05:12余永红赵卫滨
计算机与数字工程 2020年1期
蒋 晶 余永红 赵卫滨
(南京邮电大学通达学院 扬州 225127)
1 引言
云计算是近年来国内外计算机业研究的热点,是构筑在因特网上的一种新兴技术,它可为计算机用户提供更多的资源、功能和交互性。为了使云计算更安全、更具吸引力,用户实体间的互信问题显得格外重要。然而,在云计算环境中,采用认证中心建立实体间的信任关系存在一定难度[1],因此,在云计算环境中建立一种新的分布式信任机制是十分必要的。
在社会网络中,信任关系是人际关系的核心,个体间的信任度取决于其他个体的推荐,这种互相依赖的信任关系组成了一个信任网络。在人类社会建立信任关系的过程中,存在许多不确定的因素,云计算环境中结点之间的信任关系也是如此,因此可以借鉴能够描述证据信息中不确定因素的理论建立云计算环境下的信任模型。
本文借助社会学的人际关系推荐信任模型,构造一个基于主观逻辑理论的云计算环境结点之间信任模型,并给出该模型的表述和实现方法,最后通过分析和仿真实验表明模型的有效性。
2 相关研究
目前针对网络环境下信任模型已经开展了很多方面研究,信任模型涉及的评估指标、评估方法选取是整个信任评估系统的核心,也是研究的热点[2~4]。Azzedin.F.等认为如果计算任务被分配到信任级别低的网格结点上执行时,为了维护它们的顺利执行,必然会增加额外的安全开销。因此他们提出了将安全信任模型集成到网格资源管理框架中的全局信任模型,在任务分配的同时考虑资源与任务之间安全信任关系[5~7];文献[8]提出了一种感知安全的云体系结构,采用新人协商和数据着色技术保障云服务提供商安全,云服务用户端安全则采用新人覆盖网络,实现基于名誉的信任管理;文献[9]提出了一种基于服务质量参数的云服务信誉评估技术,引入可信性评级/历史评级以及个人评估经验作为评估度量策略。文献[10]提出了一种基于服务等级协议的云计算信任模型,引入了系统信任,使得云服务商综合信誉获得更加全面和准确。Wang.Y等提出了一种基于贝叶斯网络的信任模型建立方法[11~12],认为结点之间的信任关系与结点提供的服务类型有关。但是他们的信任模型都是基于P2P环境下的,在该环境下结点是无法保证服务质量的,因此在建立信任模型过程中,都没有考虑结点提供服务质量属性。当前云计算服务信任评估模型大多是在所收集到的以往服务使用者对服务的反馈评价基础上进行的信任评估,没有考虑不确定的历史信息而且云计算服务的动态性和反馈评价的时间滞后性增加了信任评估的难度,实际上,有些历史信息并不能提供有价值的参考;另外,在融合不同结点推荐信息时,需要区分恶意结点,避免恶意推荐导致某些结点信任度计算偏高或偏低,影响最终的服务选择结果。过去常见的方法是在服务失效后降低恶意推荐结点的信誉度以达到区分目的,但是这是以服务选择的失败为代价的,因此如果在服务选择过程中区分恶意结点,保证正确的选择服务提供方是一个关键问题。
主观逻辑[14~15]描述了人类对世界的感知信任程度,它在部分概念上与证据理论相似,因为它们在判断某件事情发生与否的时候,都引入了不确定(uncertain)的推理过程。它采用事实空间(option)定义人类对某件事情发生的主观判断,类似于人类社会中的意见评估系统,它包含了对某件事情发生的不确定性判断,并提供了一套主观逻辑算子,用于信任度之间的运算。其主要的算子有合并(cojunction)、合意(consensus)和推荐(recommendation)。其中合并用于不同信任内容的信任度综合计算。合意根据参与运算的观念(信任度)之间的关系分为独立观念间的合意、依赖观念间的合意和部分依赖观念间的合意类。所谓观念依赖是指观念是否部分或全部由观察相同的事件所形成。合意主要用于对多个相同信任内容的信任度综合计算。但是该理论无法有效地消除恶意推荐带来的影响;而且,建立在融合不同结点之间的推荐意见时,需要定义识别框架的基本可信度函数。下面将首先提出一种基于服务质量的基本可信度函数建立方法,然后介绍如何借助三角模糊数消除恶意推荐结点。
3 基于主观逻辑的信任模型建立
本文假设云计算环境由多个可以提供有QoS保证的云计算结点和若干无法提供QoS保证的P2P服务结点构成[10]。其中云计算结点通常是可信的高性能计算节点,拥有丰富的资源,能够提供有QoS保障的计算服务;而下层的服务提供者是普通的计算结点或其它服务提供者,由普通计算机构成,无法保证服务的QoS。为了保证服务质量,在选择普通服务节点提供云计算服务时,需要对每个节点评定可信任度,选择信任度相对较高的结点。在确定普通结点的信任度时,一方面需要借鉴自身与普通结点交互的直接经验,另一方面需要接收来自其他结点的推荐信任度,因此不可避免地接触到一些不确定信息。如何合理地融合云计算结点之间的推荐信任度信息是十分关键的。本文假设服务提供方提供的服务质量均能通过认证中心量化[16]并为服务消费者所知,在已知应用程序对云计算提供服务的QoS请求的前提下,提出基于服务质量约束关系建立基本可信度函数,并基于主观逻辑理论描述不确定的推荐信息,同时引入两种逻辑算子:衰减算子和结合算子融合来自云计算结点的推荐信任度信息。由于主观逻辑理论无法消除恶意推荐结点带来的负面影响,因此本文提出基于三角模糊数对推荐结点分类,并采用信任衰减算子对不同分类中的结点进行“信任衰减”,以达到降低恶意结点负面影响的目的。
3.1 基于服务质量约束关心的可信度函数构建
在选择服务提供的结点时,需要考虑使用结点和服务结点之间交互的历史经验。对于不同的应用,所关心的服务质量程度不同,对云计算服务会提出不同程度的服务质量要求。因此需要区分不同的交互行为提出的质量要求,并选择有用的历史经验作为下一次交互的信任评估的参考。本文提出在参考历史交互经验的同时引入约束关系。通过约束关系,将应用提出的服务质量请求与历史交互记录进行比较,判断历史交互记录是否有参考价值。
3.1.1 约束关系
假设服务S可以提供n种QoS属性,用向量S(p1,p2,…,pn)表示。当应用程序需要申请服务S时,会提出服务质量要求,用向量 A(q1,q2,…,qn)表示。不同的应用对服务S关注的服务质量程度不同,因此对于不同的服务请求,其服务请求向量A不会完全一样。如果该申请没有对服务属性 pi提供服务质量要求,则规定该qi=0。
定义1 约束关系o(op1,op2)是一个二元关系符,表示op1受到op2的约束。规定约束关系有≺(小于)、≻(大于)和=(等于)。
如果实体A向服务S提出请求r1,其服务质量请求向量为 r1(q11,q12,…,q1n)。假设集合R为GP结点A与P2P结点B直接交互的历史记录,令r2∈R ,并规定 r2的服务质量向量为 r2(q21,q22,…,q2n)。设r1和r2对服务S提供的服务质量属性pi的请求分别为q1i和q2i,如果r1对属性 pi的要求比r2低,则认为服务属性q1i和q2i存在约束关系,并记为 q1i≺q2i。反之则为 q1i≻q2i或者q1i=q2i。如果 ∀pi,满足 q1i≺q2i,则认为行为 r1与行为r2之间存在约束关系,记为r1≺r2。
由约束关系的定义可以看出,如果行为r1与r2之间存在约束关系r1≺r2,即使服务S成功满足了r1的要求,当r2申请服务S时,服务S也无法根据r1成功执行的历史经验判断r2能成功执行。也就是说,服务S成功满足r1要求的历史信息对服务S能否成功满足r2的要求不能提供有价值的参考,即该历史信息是不确定的参考信息。反之,当r1≻r2成立时,即使行为r1成功执行服务S,当r2申请服务S时,r1成功执行说明服务S有能力满足r2提出的服务质量要求,即可以提供确定的成功信息。
前面介绍的信任评估方法中都是假设云计算服务处在理想情况下,所有云计算服务提供的服务质量属性完全相同。但是,两个不同的云计算服务不可能提供完全相同的服务质量,因此需要对不同服务之间的相似性进行比较,这样可以将所有交互历史记录作为参考集合,丰富建立直接信任度时的参考信息。可以将不同服务请求的QoS属性分为几种关系:1)包容关系;2)交集关系;3)空集关系。假设存在服务S1和服务S2,如果S1和S2满足包容关系,不妨设为S1包容S2,记为S1⊃S2,则说明S2所提供的QoS属性集合是S1提供的QoS属性集合的子集。如果S1和S2满足交集关系,则说明两个服务提供的服务质量属性之间存在共同的属性,同时也存在不同的。如果S1和S2满足空集关系,则说明两个服务提供的服务质量属性集合相交为空集。如果两个服务之间满足包容关系,设为S1⊃S2,在计算关于服务S2的直接信任度时,对于该结点与服务S1的直接交互记录可以充分考虑,反过来不成立。当两个服务之间满足交集关系时,无法直接判断与服务S1的交互记录是否能够对服务S2的信任程度提供有价值的参考意见。为了衡量两个服务之间相似度,可以用语义对不同的服务质量属性加以描述,并根据定义的语义相似度,使用Clard Distance计算方法。如果两个服务属性集合之间的的距离小,表明结点的相似性高,距离大说明相似性低,用距离大小描述服务之间的相似性。由于本文重点不是服务质量属性之间的相似性,因此不做重点介绍。下面假设所有请求的服务质量属性都相同。下面将介绍在建立基本信度函数时,如何引入约束关系。
3.1.2 基本可信度函数
设结点A和结点B,A与B的交互记录记为HA,B,交互记录 Ri∈HA,B,且 Ri的服务质量请求为Ri(qi1,qi2,…,qin)。设结点A提出的服务请求质量首先,根据A提出的服务质量请求向量将历史信息分为确定失败、确定成功和不确定信息三类。分类方法如下:
1)确定成功记录集合:BHA,B={Ri|Ri≻Ra};
2)确定失败记录集合:DHA,B={Ri|Ri执行失败};
3)不确定记录集合:UHA,B=HA,B-BHA,BDHA,B。
基于以上历史交互记录的三种分类,给出识别框架Θ={T,¬T}上的基本可信度函数如下:
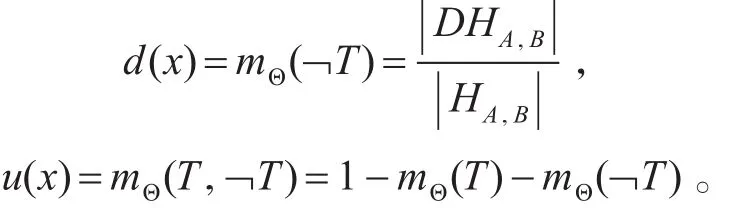
由函数建立过程可知,b(T)、d(T)和u(T)三者满足b(T)+d(T)+u(T)=1。
3.2 信任演算
信任演算提供了计算信任路径信任值的算子,描述用信任演算获取信任路径的信任值。主观逻辑定义了许多算子,一些算子表示二元逻辑和概率演算的概括,而由于其他的一些算子依赖于信任,是信任理论特有的。我们只考虑折扣(discounting)和合意(consensus)算子。折扣算子用来从推荐云计算结点中获取信任,合意算子用来综合多个云计算结点的推荐信任度。
当结点A向结点B申请服务时,除了考虑A和B之间的直接信任度外,A还可以从其他的实体获取服务提供者B的推荐信任信息。当A向其他GP结点C咨询关于B的可信任程度时,必须考虑推荐结点C的可信任程度,这里用信誉度表示。信誉度表示了推荐结点C推荐的关于服务提供方的信任度的可信任程度,这里可以用偏好意见表示。这里定义一个推荐算子计算来自推荐结点C的推荐信息的可信度[15]。用符号“”表示推荐算子,定义,有下面的计算公式。
状态x指结点B成功提供某种云计算服务的行为的可信度。由定义可以看出,可以理解为云计算结点A有选择采纳云计算结点B提供的关于状态结点B成功提供服务的偏好意见,从而形成A对状态集合x的偏好意见。
结点B对结点A的推荐信誉度可以通过两者之间交互记录确定,如果B结点推荐的服务结点均能成功满足A的服务要求,则信誉度高;反之,则信誉度较低。由于偏好意见可以通过beta函数表示,因此ωAB可以采用beta函数计算。假设r为B向A成功提供偏好意见的次数,s为失败的次数,则

当交互次数越多时,不确信的因素就越少。初始条件下,r=1,s=0。
结点A通过衰减算子得到其他与结点B有过直接交互的结点的推荐偏好意见后,如何融合得到多个关于结点B的偏好意见ω是关键问题。常见的方法有证据理论中的Dempster法则。但是该法则对于融合的证据有限制,参与融合的偏好证据不能出现相互矛盾的现象,但是在实际的云计算环境中由于一些恶意结点的参与,出现矛盾的证据是无法可避免的,因此为了避免矛盾证据的影响,本文采用主观逻辑中的偏好融合算子[14](consensus operator)可以有效地解决证据互相矛盾的问题。融合算子等价于静态的贝叶斯更新。两个有可能发生冲突的观点的合意成为一个公平同等地反映两个观点的一个观点。用符号“⊕”表示推荐算子,定义有下面的计算公式。
当k≠0时

当k=0时

通过采用融合算子,可以方便地综合来自多个结点的推荐意见。融合后偏好意见的相对粒子度实际上是反映了意见融合双方的原状态空间和融合后状态空间之间的关系。在实际的应用中,由于来自不同云计算结点的偏好意见都是建立在二值识别框架Θ={T,¬T}上,其a均为0.5,因此在进行计算融合后的偏好意见的相对粒子度可以简化为
3.3 恶意结点消除
在云计算环境中,某些结点为了达到某种目的,虚报自己的信誉度或者直接信任经验,诋毁被推荐结点或者抬高被推荐结点,最终导致服务消费者选择错误的服务提供方。以前的信任评估模型都没有考虑到恶意推荐的现象,大都采用服务失败后降低提供服务的结点的信任度,直到消费者不选择为止,但是这实际上是以服务的失败为代价的。如果在融合多个推荐信息的时候,对推荐信息进行预处理,尽可能地不考虑一些可疑的推荐信息,则可以有效地避免服务的选择失败。下面将介绍一种基于方差和三角模糊数的方法评判推荐信息可信度的方法。基本思想是首先计算每个结点推荐的信任度期望,并计算信任期望的均值和方差;然后计算每个结点推荐的信任期望与期望均值之间差值的绝对值,最后根据该差值和预先定义的三角模糊数计算每个结点属于不同结点分类的隶属度,选择隶属度最高的分类和相应的信任衰减算子,最后通过衰减算子计算衰减后的信任空间。
3.3.1 结点分类
得到每个推荐结点推荐的推荐主观意见后,首先计算每个推荐结点的推荐期望值;然后计算所有结点的平均推荐期望其中R(x)表示推荐结点的集合,最后计算结点信任期望的方差
对于正常的推荐结点,它们对同一个结点的评价一般不会相差过大;而对于恶意结点,由于它们出于自身利益,它们的评价信任空间信息会与大多数结点有较大偏差,因此可以通过每个结点的推荐期望与所有结点的平均期望值的差的绝对值判断。如果该数值相差越大,则说明该推荐信息属于恶意信息的可能性越大。而偏差的大或者小是一个模糊的概念,因此采用三角模糊函数对其进行评估。这里将推荐结点推荐的信息分成五类三角模糊数:非常可信、比较可信、一般可信、比较不可信、非常不可信,对应关系如图1所示。

图1 不同分类对应的三角模糊数
3.3.2 三角模糊数
定义2 若A=(a,b,c),其中,0<a≤b≤c,称A为一个三角模糊数,如其特征函数(隶属函数)可表示为
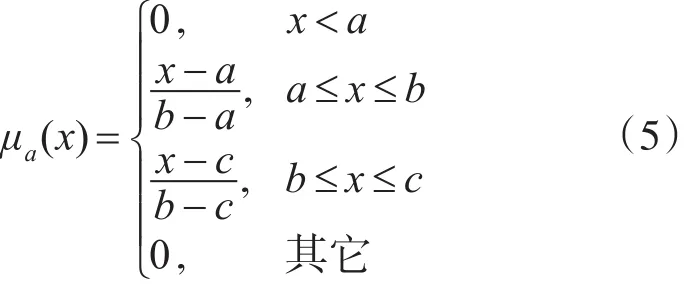
其中,a表示最悲观的估计,b表示最可能的估计,c表示最乐观的估计。
在定义2中,前提条件是变量x满足“越大越好”,因此结点的乐观估计大于结点的悲观估计;而在这里,实际上,每个结点的信任期望与信任期望均值的差值越小越好,结点的乐观估计小于结点的悲观估计,因此需要对式进行无量纲化,这里选择的无量纲化函数为x′=1-arctgx;无量钢化后计算每个结点的推荐信任期望值对不同三角模糊数中的隶属度。其中x表示该结点的信任期望值。
3.3.3 信任意见衰减算子
在计算得到每个推荐结点的三角模糊隶属值后,这里通过建立一个模糊评判标准,对每个推荐结点的隶属度进行分类,并根据评判规则得到一个衰减算子。衰减算子根据评判的结果对每个结点的推荐主观信任度进行信任度的衰减处理,衰减算子也是一个主观信任空间,由一个四元组构成。对应关系见表1。获取每个推荐结点的对应的衰减算子后,采用主观逻辑理论中的推荐算子对每个推荐结点推荐的主观信任度进行衰减处理,得到一个屏蔽恶意结点后的推荐意见。然后通过融合算子对所有推荐结点的推荐信任值综合得到一个最终的信任期望,计算公式如下,其中表示结点A对应的衰减算子,ωAR x表示经过衰减后的结点A推荐的关于x的信任空间。得到每个结点衰减后的信任空间后,就可以采用式(3)或式(4)进行信任空间融合计算,得到最终的信任期望。

表1 隶属函数-衰减信任空间对应关系
4 实验及结果分析
下面通过一个局域网内的云计算环境下载服务验证本模型,包括两个提供文件下载服务的云计算结点,其中一个是有带宽限制,最大为10M,记为结点A。另一个则没有带宽限制,最大可达到100M,记为结点B。我们在客户端调用文件下载服务。初始条件下,两个云计算文件服务器的信任度相等。为了验证基于QoS信任模型的有效性,提高结点A的信任度,首先应用层使结点A成功满足100次带宽为[1M,5M]之间的文件下载服务请求。然后开始向两个结点同时申请文件下载服务,这里分别采用基于贝叶斯模型的信任模型[9]和本文基于服务质量的信任模型计算两个结点的信任度。由于每次应用层请求的服务质量均为带宽,因此贝叶斯模型将会考虑所有的交互记录,并根据成功下载次数计算结点的信任度。而本文的服务质量模型将区分不同服务质量请求计算结点的信任度。图2、3给出了当请求带宽均小于10M时,根据两个不同模型计算得到的两个结点的信任期望曲线,而图4、5给出了当请求带宽大于50M时,根据两个不同模型计算得到的两个结点的信任期望曲线。由图2、3中可以看出,当下载请求对服务质量要求不高时,两种模型都会选择A类结点,这是因为请求带宽均小于10M,A类结点与B类结点都能提供相同的确定信息,而由于初始条件下A类结点信任期望较大,因此会选择它,最终它的信任期望也随着服务成功而递增。而当带宽请求大于10M时,采用贝叶斯模型计算得到的A点信任期望依然高于B结点,但是由于A点无法满足下载的带宽要求,因此服务失败,反而降低其信任期望,直到其信任期望小于B结点时,才会选择B结点,这是以服务失败为代价的;如果采用本文模型,如图5,由于A类结点开始的下载请求均小于10M,因此都是一些不确定信息,而B类结点由于它们能够提供较高的下载带宽,因此它们都是确定信息,尽管它们初始信任度较低,但是根据本文模型得到的信任期望仍高于A类结点。

图2 10M条件下贝叶斯模型计算信任度

图4 高带宽条件下贝叶斯信任模型

图5 高带宽条件下本文信任模型
我们通过仿真实验比较了基于三角模糊数区分恶意结点和不区分恶意结点的影响。假定云计算环境中有100个结点,其中包括10个GP结点和100普通的P2P结点。P2P结点分为两类,一类能够提供服务质量较好的下载服务,另一类只能提供带宽有限的文件下载服务。假设GP结点之间的信任路径已知,且在GP结点中存在恶意推荐结点。这里将恶意推荐节点进一步分为以下两类:1)诋毁节点。这类节点诋毁所有与之交易过其他P2P结点。2)夸大节点。这类节点夸大同伙的恶意节点。
规定GP结点有意诋毁服务质量高的P2P结点,夸大服务质量低的P2P结点。我们同时假定文件共享网络是理想的,任意用户可以找到任意文件并从所有声称拥有其所需文件的节点中选择可信度最高的节点下载文件。每次假设至少存在结点A、B同时满足提供云计算服务时,且结点A提供的服务质量较高,但是会存在一定比例的恶意GP结点抬高结点B和贬低结点A。我们进行了100次实验,分别采用基于三角模糊数和不采用三角模糊数的方法计算两个结点的信任期望。计算结果如图6和图7所示,如果不采用三角模糊数对结点进行分类,则在100次实验中,会多次选择错误的结点B。而如果采用基于三角模糊数对结点进行分类,则都可以成功地选择正确的结点A。

图6 没有采用三角模糊数计算得到的信任度
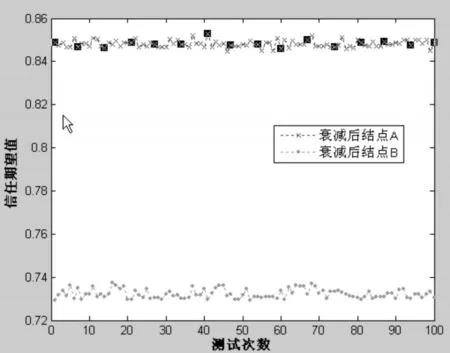
图7 采用三角模糊数计算得到的信任度
5 结语
本文针对云计算环境中服务选择时的结点实体间的信任问题,提出了基于QoS约束和偏序关系建立基本可信度函数的方法,引入服务提供的质量之间的约束关系,将历史交互记录分为三类。并参考人类社会的活动规律,采用基于主观逻辑理论的方法建立GP结点和P2P结点之间信任关系模型。为了解决服务选择时可能发生的热点现象,采用遗传算法中常用的轮盘赌方法在若干个合适的服务提供方选择,既避免了服务的过分集中,又保证信任度高的结点有更高的优先权提供服务。
在本文中,对于一个服务,在建立服务质量约束关系的时候没有考虑属性之间的关联,实际上对于一些服务质量属性是存在因果关系的,因此在以后的研究工作中深入。另一方面,本文假设结点交互的历史记录权值相等,而实际上,时间相对较近的记录反映了两个结点近期的服务情况,应当赋予更高的权值,在以后的研究中考虑。
猜你喜欢
云南大学学报(自然科学版)(2022年1期)2022-02-21
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
校园英语·上旬(2020年1期)2020-05-09
环球时报(2018-01-23)2018-01-23
卷宗(2017年16期)2017-08-30
IT经理世界(2014年5期)2014-03-19
