
基于卷积神经网络特征融合的人脸识别算法*
2020-03-04 05:12王卫民张轶秋
计算机与数字工程 2020年1期
王卫民 唐 洋 张 健 张轶秋
(江苏科技大学计算机学院 镇江 212003)
1 引言
在过去的几年中,CNN模型取得了巨大的突破。2012年,AlexNet[1]问世,提出了 RELU非线性函数和Dropout,并使用多GPU来加速,使CNN模型可以处理大数据量和区分复杂物体。2014年,VGG[2]通过降低filter的大小(VGG的filter大小为3*3)和加深网络层(网络层深度提高到了16、19层)来取得更好的效果。同年,GoogleNet[3]将层级提升到22层,并提出新的结构Inception,主要思路是用密集成分来近似最优的局部稀疏结构。随着模型深度增加,SGD的优化变得更加困难,针对此问题,ResNet[4]将层级提到了 152 层,提出了用于学习残差函数的Residual结构,在没有增加参数和计算量的前提下提高了模型的训练速度和训练效果,并改善了退化的问题。为了达到更好的识别精度,本文将上述模型提取到的特征进行融合。并将融合后的特征应用到人脸识别中。
2 相关工作
在 2004 年,Sanderson 和 Pailwal[5]总结了特征融合思想,他们根据信息融合发生在分类器(classi-fier)处理前后把信息融合划分为先映射融合(pre-mapping fusion)和后映射融合(post-mapping fusion)。通常数据级融合(data level fusion)和特征级融合(feature level fusion)被称之为先映射融合,如袁海聪[6]等把Gabor小波特征、局部二值图特征和像素特征融合成最终特征进行人脸欺诈检测。分值级融合(score level fusion)和决策级融合(decision level fusion)被称之为后映射融合,如梁锐[7]等利用加权平均等特征融合算法进行深度视频的自然语言描述。
深度学习的特征融合思想在卷积神经网络中运用十分普遍[8,15]。空间特征融合算法[9]可以对多个卷积层输出的特征进行融合,从而把多个卷积神经网络模型连接在一起。融合函数定义为
其中:xa和xb表示图片分别经过不同卷积神经网络得到的特征。y表示融合后的特征。xa、xb和y∈RH×W×D,H、W和D分别表示特征向量的长度、宽度和通道数。
空间特征融合算法的几种融合函数:
1)加性融合函数。
加性融合函数是对两个特征向量对应位置元素的值进行相加,公式为

2)最大融合函数。
最大融合函数是将两个特征向量对应位置元素最大的值作为融合后的值。
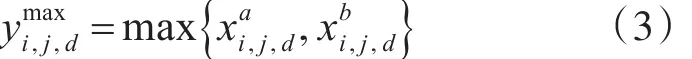
3)级联融合函数。

级联融合函数保留了两个特征图的结果,并将融合后的特征图的通道数变为原始特征图的两倍。

其中 y∈RH×W×2D。
基于这些理论,本文对现有的多种CNN模型提取特征,并构建新的模型把提取的单特征融合并进行训练,使多种CNN模型提取出的单特征融合,从而形成新的融合特征。
3 多CNN特征融合方法
不同模型提取出的图片特征具有互补性[10],因此,融合不同模型提取出的图片特征可以提高对图片的识别精度[19~20]。据此,本文提出两种多CNN特征融合方法,包括算法1多CNN特征融合算法和算法2多CNN特征降维融合算法。本文采用的三种CNN模型VGG19、IceptionV3和 ResNet,在数据集(在6.1节介绍)上都迭代训练1000次,训练出网络参数。
3.1 多CNN特征融合算法
多CNN特征融合算法是把三种预训练CNN模型在数据集上去除最后的分类层,提取出图片的单特征向量,然后进行特征融合。VGG19、IceptionV3和ResNet提取出的特征向量分别记为FV∈R512、FI∈R2048和 FR∈R2048。融合函数选用 concatenate函数,因为concatenate函数能将单特征的全部信息保留并融合。接着用Dense层把融合特征降维成长度为128的特征向量,其过程见算法1。其中Dense层的参数针对不同问题构建具体神经网络模型进行训练。
算法1:多CNN特征融合过程
输入:单张图片image
输出:融合特征fuse_feature
步骤:
用VGG19提取image特征记为FV∈R512
用IceptionV3提取image特征记为FI∈R2048
用ResNet提取image特征记为FR∈R2048
CF=concatenate(FV,FI,FR)∈R4608
fuse_feature=Dense(CF)∈R128
3.2 多CNN特征降维融合算法
算法2在提取出单特征后,先用Dense层对三种不同特征进行降维处理,再用融合函数融合,最后用Dense层把融合特征降维成长度为128的特征向量,其过程见算法2。同样,构建具体模型运用上述算法训练出Dense层的参数。
算法2:多CNN特征降维融合过程
输入:单张图片image
输出:融合特征fuse_feature
步骤:
用VGG19提取image特征记为FV∈R512
用IceptionV3提取image特征记为FI∈R2048
用ResNet提取image特征记为FR∈R2048
DFV=Dense(FV)∈R128
DFI=Dense(FI)∈ R128
DFR=Dense(FR)∈R128
CF=Concatenate(DFV,DFI,DFR)∈R384
fuse_feature=Dense(CF)∈R128
4 方法在人脸识别中的应用
特征融合在人脸识别中也有广泛应用[16~18],但大多基于人工提取的特征如LBP(局部二值图)特征,HOG梯度方向直方图特征和DCT(离散余弦变换)特征等再进行特征融合[11~12]。本文的两种特征融合算法基于三种卷积神经网络模型,自动提取图片特征并应用于人脸识别中。
4.1 线下特征提取
在特征融合算法使用过程中,需要用VGG19、InceptionV3和ResNet模型提取图片的特征,这一环节耗时长,资源利用率低。本文利用上述模型线下提取单特征然后进行特征融合,此步骤对算法结果没有影响,但是提高了特征的复用性,缩短了训练时间,节约了计算资源,其过程见算法3。
算法3:线下特征提取过程
输入:人脸数据集Images{Image1,Image2,Image3… Imagen}
输出:FSV,FSI,FSR
初始化:创建特征文件 FSV,FSI,FSR
For each Image∈Images do
For each i∈Image do
face=detection(i)
//用Dlib库中训练好的人脸关键点检测器从图片中检测出人脸
FSV=save(VGG19(face))
FSI=save(IceptionV3(face))
FSR=save(ResNet(face))
//用 VGG19、IceptionV3和ResNet提取 i特征向量记为FVi∈R512、FIi∈R2048和 FRi∈R2048并保存。
End for
End for
4.2 人脸识别模型
用Keras建模框架把多CNN特征融合方法建模并用数据集训练。得到的融合特征用于人脸识别的对比。多CNN特征融合算法人脸识别模型如图1所示。
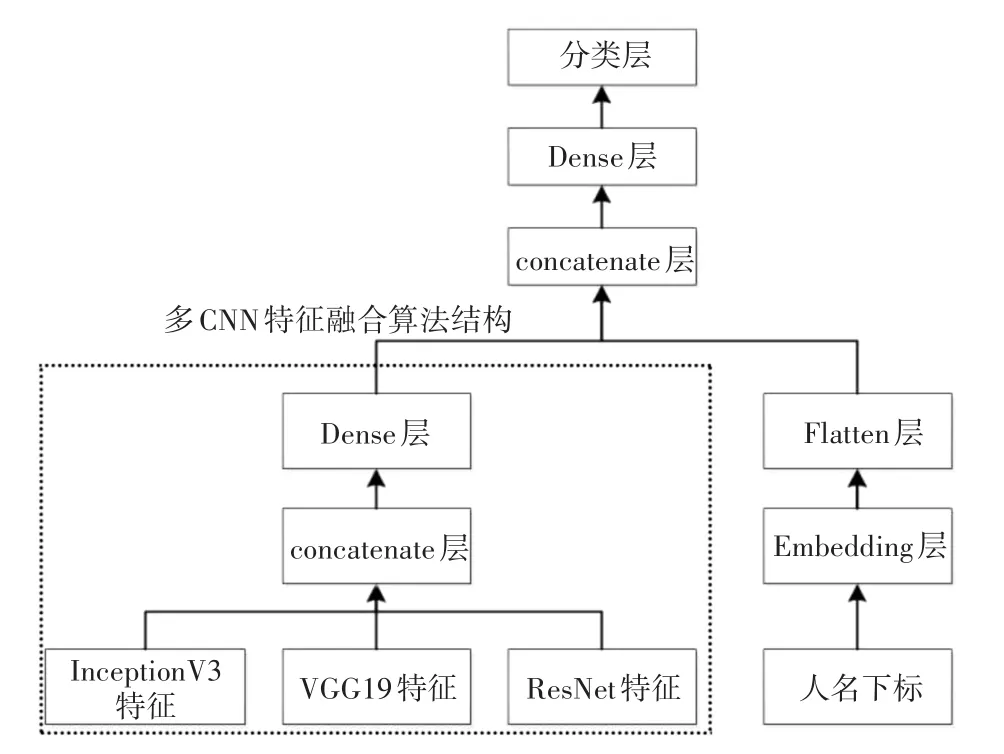
图1 多CNN特征融合算法人脸识别模型
相比于多CNN特征融合算法人脸识别模型,多CNN特征降维融合算法人脸识别模型层数增加,参数更多。最终由实验得出的识别精度也更高,模型如图2。

图2 多CNN特征降维融合算法人脸识别模型
4.3 人脸识别模型训练过程
人脸识别模型的训练过程是把线下提取好的三种特征作为输入X1、X2和X3,把对应人名的词典下标作为输入Y,并设标签L为1。再用算法1或算法2把多个特征向量融合;接着和Embedding层降维的输入Y连接起来,然后用Dense层降维融合特征,最后用sigmoid激活函数得出最终结果P。用数据集通过迭代训练从而把多特征融合模型中的参数训练出来。
4.4 人脸识别模型预测过程
输入两张人脸图像记为image1、image2,用特征融合模型预测后,提取多CNN特征融合算法结构中最后一层Dense层输出作为融合特征,函数记为get_feature;dist为计算两个特征在欧式空间上的距离记为D(精确到小数点后三位);由阈值λ(在第5节介绍)判断出预测值。若两张人脸图片为同一人则记为1,否则为0。过程见算法4。
算法4:人脸识别过程
输入:测试人脸图片image1,测试人脸图片image2
输出:0或1
步骤:
Face1=detection(image1)
Face2=detection(image2)
F1=get_feature(Face1)
F2=get_feature(Face2)
D=dist(F1,F2)
If D <λ then
return 1
Else
return 0
end if
5 阈值计算
人脸识别模型训练完成后,随机从测试数据集中抽取两张人脸图像进行预测,得两张人脸图片融合特征的欧式距离记为x,真实值为y(相同人的人脸图片真实值记为1,不同的记为0)。重复此过程n次,则测试数据结果可表示为

满足:
1)xi∈[0,1](1≤i≤n)
2)yi=0 or 1(1≤i≤n)
则阈值λ的求取过程可形式化为以下问题:

在阈值算法计算中,精度P初始值为1000,abs函数是用来计算绝对值(欧式空间距离),过程见算法5。
算法5:阈值计算
输入:(X,Y),P
输出:λ
初始化:sum1=P,sum2=0,z=0
For each(xi,yi)∈(X,Y)do
xi=xi×P
yi=yi×P
end for
//把每一个欧氏距离xi,和真实值yi都乘以精度P,使得xi∈
[0,1000],yi=0 or 1000。
For each i∈[0,1000]do
For each(xi,yi)∈(X,Y)do
If xi>i:
z=1000
Else:
z=0
T=abs(z-yi)
sum2=sum2+T
end if
end for
if sum2<sum1then
sum1=sum2
λ=i
end if
end for
//i从0开始遍历到1000,求出定义1函数F(λ)的最小值,同时也求出阈值λ
6 实验与分析
6.1 数据集与评估标准
本文实验采用LFW(Labeled Faces in the Wild)数据库来评估本文算法的性能。硬件配置为:Intel(R)Core(TM)i7-7700HQ CPU@2.80GHz,16.00GB内存,1050显卡。
LFW数据库用于研究非受限情形下的人脸识别问题。图像大小为250×250像素,其中有5749人,共计13233张图片。本文的实验节选其中部分数据:1496人,共4108张图像。具体图片如图3所示。

图3 LFW人脸图像数据
人脸存放在文件夹Images中代表训练集,其中:
Images中包含多个文件夹 Image1,Image2,Image3…Imagen。
imagei代表:第i个人的人名,其中:
imagei中包含文件imagei1,imagei2,…imageim;
imageij代表第i个人的第j张图。
6.2 数据集设定
从全部数据4108张图片中取出3108张作为训练数据进行训练;1000张作为测试数据。
6.3 现有模型与多CNN特征融合模型精度对比
模型训练完成后,各现有的神经网络模型及本文的两种融合特征神经网络模型(迭代训练1000次)在测试数据集上测试1000次。各模型识别精度比较如表1所示。可以看出,本文的两种融合特征神经网络模型在识别精度上有一定的提升。
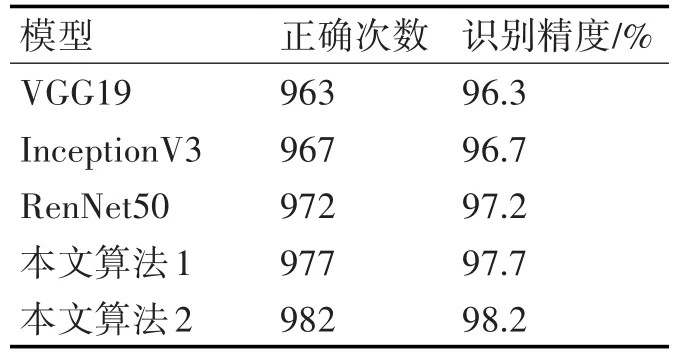
表1 不同模型识别精度比较
6.4 迭代次数对比
本文还对比了训练的迭代次数,实验结果如图4。多CNN特征降维融合模型在精度上略好于多CNN特征融合模型,而随着迭代次数的提高,两个模型的测试精度都有提升。
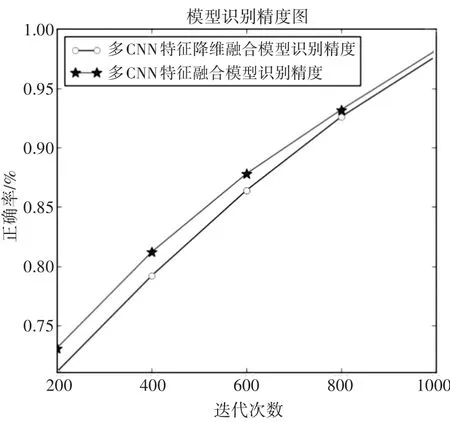
图4 模型迭代次数识别精度图
6.5 和现有的特征融合算法精度的比对
本文的模型都用训练集迭代1000次。由表2可以看出本文的两种模型识别精度都高于传统的特征融合算法,见文献[13~14]。
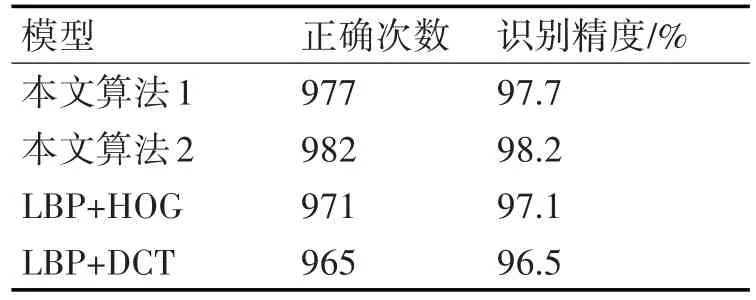
表2 与现有特征融合算法比较
7 结语
本文在现有的多个CNN模型基础上,进行特征融合并设阈值来提高人脸识别精度。以上技术的运用使得本文算法具有较强的泛化能力和优异的性能。本文的主要贡献是用现有的多种CNN模型提取特征,融合出更具有鉴别性的特征,阈值的设置使人脸识别精度进一步提高。其在数据集上的测试结果也证明了本文方法的有效性。在下一步的工作中我们将融合特征运用于视频中人脸的识别,期望取得较好的表现。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
文萃报·周五版(2021年17期)2021-05-31
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
通信产业报(2018年10期)2018-04-13
米娜·女性大世界(2016年8期)2016-08-17
发明与创新·大科技(2016年1期)2016-02-01
