
精准识贫的顶层设计与调适性执行
——贫困识别的中国经验
2020-03-01 07:51:08王中原
中国农业大学学报(社会科学版) 2020年6期
王中原
贫困治理不仅仅是一项经济工作,还涉及到诸多领域的体制和机制建设。自党的十八大以来,中国在“精准扶贫”的各个环节和领域积累了丰富的制度经验。其中,贫困人口的精准识别是整个脱贫攻坚工作的基础,是精准扶贫的“第一颗扣子”,也是“扶真贫、真扶贫”的根本要义所在。贫困识别的方式方法是否科学、识别的过程是否规范、识别的结果是否准确是决定整个扶贫工作能否成功的关键,同时也会影响新时期脱贫攻坚工程的综合社会评价和整体政治效果。
国家统计局数据显示,2013年底中国农村贫困人口的总体规模达8 249万人,且具有地域分布差异大、致贫原因多样复杂等特征。要在14亿人口中准确识别出需要帮扶的贫困家庭无疑是一项极具挑战性的工作。与此同时,此次精准识别是中国扶贫开发历史上首次将贫困识别精准到人,以往的贫困治理多以贫困县为单位,对具体贫困人口的识别缺乏经验。此外,在2020年全面建成小康社会的总体目标压力下,各级政府部门在贫困识别工作中还面临时间短、任务重、人手缺等现实困难。面对这些挑战和困难,中国是如何实现对超大规模贫困人口的精准识别的呢?
自精准扶贫工作开展以来,经过国家层面的统筹规划和各个地方的创新实践,中国在精准识别领域积累了诸多行之有效的制度经验。整体来说,新时期的扶贫开发工作中,中国构建起“顶层设计与调试性执行相结合”的贫困人口识别模式。本文将运用实证材料剖析该制度经验的生成逻辑、运行机制以及治理绩效。
一、如何识别贫困
贫困识别(poverty identification)是指在非普惠型扶贫项目的实施过程中按照一定的标准、通过规范的程序和方法,鉴别和选定受益对象的过程,又称贫困瞄准(poverty targeting)[1-2]。贫困识别机制包括识别的主体、对象、内容、标准、程序和结果评估等。识别的精准程度取决于多大程度上让目标群体获益,理想的状态是能够让所有符合标准的目标群体获得应有的帮扶。如果发生符合条件的群体未能获益(弃真型误差)或者不符合条件的群体享受帮扶(存伪型误差),则出现瞄准偏差,进而影响扶贫政策的绩效[3]。
贫困识别政策的设计和执行是各个国家与国际社会反贫困议程的核心内容。贫困识别需要首先明确(1)什么是贫困;(2)哪些指标可以用于测量贫困程度;(3)如何获取贫困信息。根据对这些问题的回答不同,国际上常用的贫困识别方法可划分为四类[4]:(1)指标瞄准法(indicator targeting),即根据某些容易识别的特定指标(例如人口学指标、地域属性、疾病、灾难等)来清晰、直观、快捷地识别受益对象;(2)自我瞄准法(self-targeting),即通过设计一些扶贫参与项目(例如社区服务),要求帮扶对象付出一定成本,从而让真正有需求的人自我显露,同时排斥虚假贫困者;(3)基于社区的瞄准法(community-based targeting),即通过社区内部的信息共享和协商评议来选定受益者,因为社区成员之间信息较为对称,对贫困的理解相近,熟人社会的沟通成本少;(4)代理家计调查法(proxy means testing,PMT)[5-6],即通过设计一套能够反映贫困状况的评估指标体系,对申请者进行精细的量化测评,然后划定统一的贫困线,最后根据得分情况与贫困线的距离来确定受益者。上述这些识别方法在不同国家的不同扶贫项目中得到运用,各具优势和局限,同时受到不同扶贫政策目标和社会政治情境的影响,从而产生不同的政治效果[7-9]。
新时期中国的贫困治理经历了从“粗放”到“精准”的历史性转变,其首先体现在“精准识别”。在此前的粗放扶贫阶段,政府对贫困人口基数把握不准,缺少规范化的识别程序,扶贫对象通常由基层干部分配。人情扶贫、面子扶贫、关系扶贫等现象较多,影响了扶贫绩效[10],甚至滋生腐败,造成应扶未扶、扶富不扶穷等社会不公,违背了党和政府扶贫工作的初衷。新时期的精准扶贫首先提出“对象要精准”,要求先解决好“扶持谁”的关键问题,分析致贫原因,摸清帮扶需求,为精准帮扶和精准管理奠定基础,力求实现“扶真贫,真扶贫”。
二、中国精准识贫政策的设计与执行
脱贫攻坚是新时期的“四大攻坚战”之一,是近年来政府投入力度最大、动员范围最广、治理绩效最为显著的公共政策领域。中国的公共政策过程一直是学术研究关注的重要议题,围绕公共政策的议程设定、政策设计、政策执行、政策评估等环节中不同主体的纵向和横向互动关系,学术界已经发展出不同的理论概念和解释框架。
早期的研究关注中央和地方不同部门之间的利益分殊和博弈,就此李侃如(Kenneth Lieberthal)等学者提出了“碎片化威权”的分析模型[11-12]。虽然该模型在改革开放早期具有一定解释力,但正如马骏和林慕华所指出的,其忽略了社会参与者和“政策企业家”的角色[13]。与此呼应,毛学峰(Andrew Mertha)提出了“碎片化威权的2.0版本”,用于解释21世纪以来中国公共过程中的社会参与和游说机制[14]。类似地,王绍光根据议程提出者的身份与民众参与的程度划分出六种政策议程设置模式,即“关门模式”“动员模式”“内参模式”“借力模式”“上书模式”“外压模式”,并指出在今日中国的政策议程设定过程中专家、传媒、利益相关群体和人民大众发挥的影响力越来越大[15]。此外,中国政策过程的多元性还体现在地方政府的自主性、策略性、能动性和创新力等方面。例如,欧博文和李连江指出受到干部考核指标的影响,地方政府对中央政策存在“选择性执行”[16]。类似地,舒耕德(Gunter Schuber)和安娜·阿勒斯(Anna L.Ahlers)将中国地方干部界定为“策略行动者”(strategic actors),并认为他们的策略性行为推动了公共政策的有效执行[17]。韩博天(Sebastian Heilmann)发现地方政府的政策试点以及“由点到面”的政策推广是中国政策经验的重要方面,由此构建起的央地关系互动模式甚至可以解释中国为何能成为“红天鹅”[18]。以上各项研究都呈现出中国公共政策制定和执行过程的复杂性和多元性,有利于打破外界“一元化”的刻板印象。然而,过度强调利益博弈和多元参与忽略了中国政策过程的整合性以及国家和政党的权威角色。
关于中国国家治理过程的整合性和中央权威,荣立本等学者早在20世纪90年代就提出著名的“压力型体制”理论[19],在该体制下政策压力从上到下层层传导,通过目标责任制、签订责任状、绩效考核和奖惩等机制来推进国家政策落地,该过程通常伴随着大规模的政治动员。周黎安、周飞舟等学者进一步研究指出,在政策压力的指挥棒下,地方政府之间会围绕绩效考核指标展开的横向竞争,形成“锦标赛体制”[20-22]。类似地,贺东航和孔繁斌提出“政治势能”概念来强调公共政策执行过程的集中统一领导和政治权威的运行,认为“高位推动”是保证公共政策良性落地的重要前提[23]。面对新的治理模式,柏思德(KjeldE.Brødsgaard)认为原有的“碎片化威权”概念未能充分考量中国政策过程的源动力和协调性,由此提出“整合式的碎片”(integrated fragmentation),试图解释如何从多元参与走向政策整合[24]。最近,舒耕德和安小波(Björn Alpermann)观察到党的十八大以来中国公共政策领域的新变化,并借用德国学界的“政治掌舵理论”(political steering theory)来解释中国顶层设计下的政策运行过程[25]。
本文将整合上述两条学术脉络,探讨中国公共政策的顶层设计和调试性执行,结合高层的政策引领和权威供给与地方的自主创新和动态调试,分析新时期脱贫攻坚中的精准识别政策从顶层设计到基层落地的过程和机制。该政策机制即不同于“摸着石头过河”,又不同于刚性的政策计划,其旨在寻求政策规范性与政策韧性之间的某种良性平衡。与以往研究要么注重碎片化的政策博弈和多元参与,要么强调政策压力和一元化领导不同,新时期的精准识别政策过程同时呈现出“总体设计性”和“动态调试性”。一方面,精准识别贫困人口作为一项国家整体工程,需要党和国家从宏观政策架构和长期政策目标上给予顶层设计;另一方面,精准识别政策的落地见效需要地方政府的创新调试和社会力量的能动参与。精准识别是新时期脱贫攻坚的“第一颗扣子”。党的十八大以来,国家高度重视精准识别政策的设计和执行,在顶层设计的指导下结合空间维度和时间维度上的调试性执行,逐步探索出一套行之有效且独具特色的贫困人口精准识别机制。
(一)贫困识别政策的顶层设计
脱贫攻坚是一项国家工程,顶层的体制机制设计在扶贫过程中具有总揽全局的核心作用。精准识别作为扶贫的一项基础性工作,需要做到标准统一、程序规范、管理有序,因此顶层设计的整体部署和系统指导显得尤为重要。
2013年,中共中央办公厅国务院办公厅出台《关于创新机制扎实推进农村扶贫开发工作的意见》(中办发〔2013〕25号),强调“国家制定统一的扶贫对象识别办法”、建立精准扶贫工作机制,并要求各省(自治区、直辖市)在已有扶贫工作的基础上,按照“县为单位、规模控制、分级负责、精准识别、动态管理”的原则开展贫困人口的识别和建档工作。在此基础上,2014年4月国务院扶贫办印发《扶贫开发建档立卡工作方案》(以下简称《方案》)进一步设计精准识别的实施细则,识别的政策目标要求做到“分析致贫原因,摸清帮扶需求,明确帮扶主体”。精准识别政策的顶层设计聚焦在五个方面:(1)定标准,(2)定规模,(3)定程序,(4)定时间,(5)定责任。
第一,在标准设定方面,《方案》规定“以2013年农民人均纯收入2 736元(相当于2010年2 300元不变价)的国家农村扶贫标准为识别标准”,该标准遵循了国际上以基本收入为贫困划定主要依据的做法,为地方政府的识别工作提供了参考。同时,考虑到区域间发展不平衡等问题(连片和深度贫困地区主要集中在中西部),中央也给予地方一定的标准设定权限,允许“在确保完成国家农村扶贫标准识别任务的基础上,可结合本地实际,按本省标准开展贫困户识别工作”,因此实施过程中存在东部发达地区的识别标注要高于西部欠发达地区的情况。概括来说,顶层设计确立了全国统一的底线标准,各省市可以在保证完成底线任务的基础上可以按照自身情况因地施策。
第二,在规模控制方面,国家依托权威统计数据将2013年底的全国农村贫困人口数(8 249万人)设定为全国脱贫工作的规模基数,并发布了相应各个省级行政单位的贫困人口数量和贫困发生率,作为各省市贫困人口识别规模的参考依据(见表1)。然而,在政策执行过程中,一些地区的实际贫困人口规模可能存在大于国家分配规模的情况。因此,《方案》规定可在国家发布规模的基础上上浮10%,个别省份可上浮更高。各省具体识别规模需要经省级扶贫开发领导小组研究确定后,由省扶贫办报国务院扶贫办核定。概括来说,顶层设计框定了全国贫困人口的识别基数,各省市可以根据本区域实际状况适当增加识别规模。
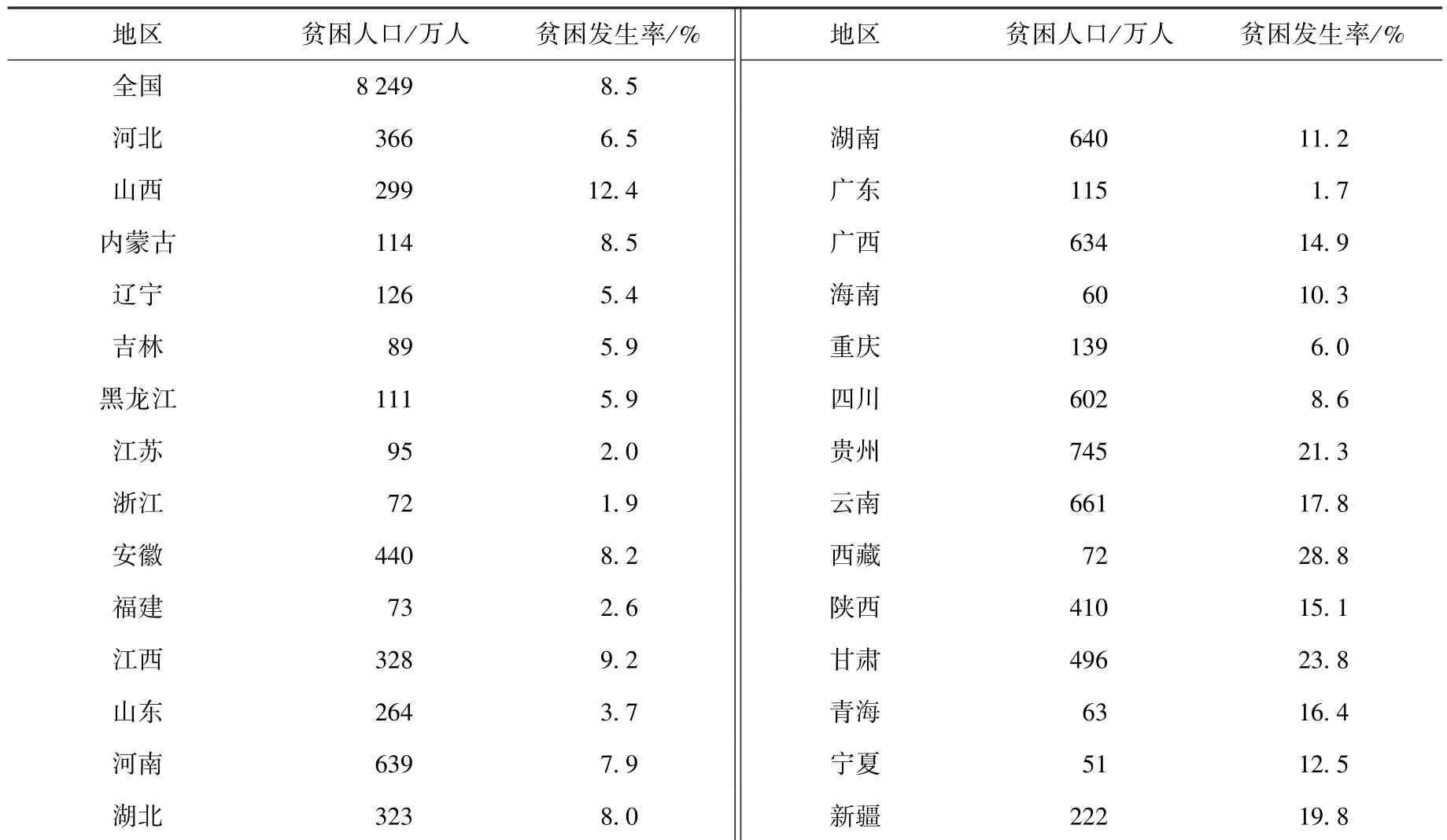
表1 2013年底全国和各省市贫困人口规模分解
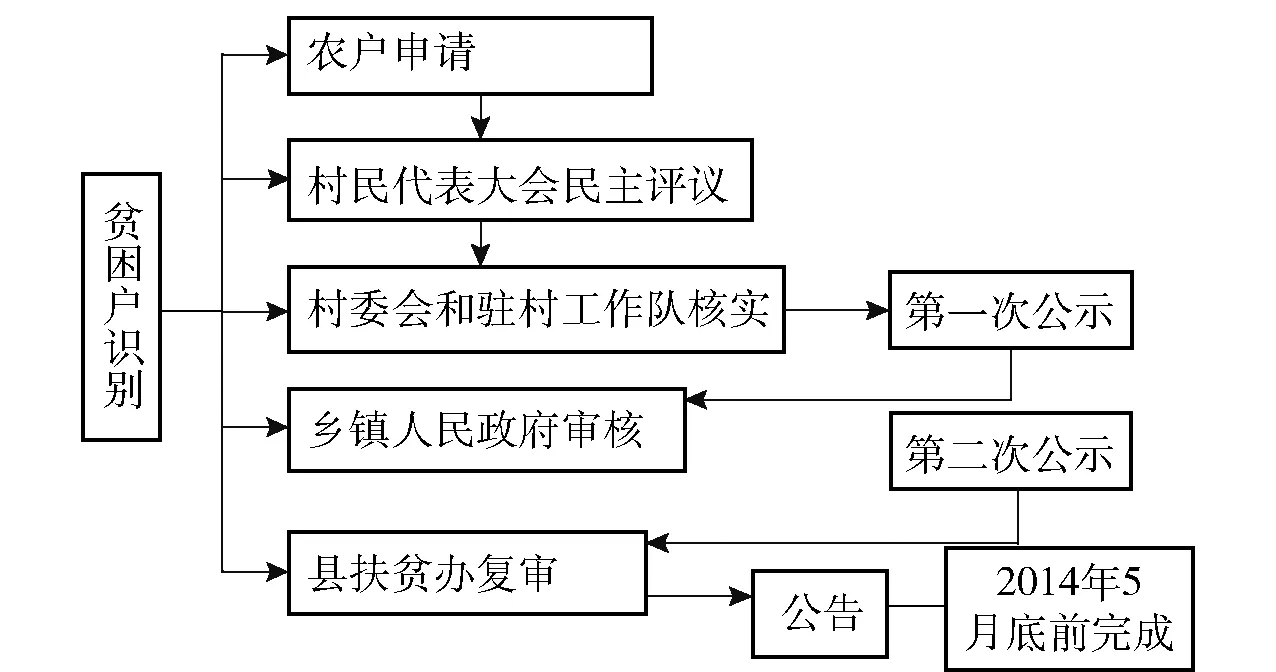
图1 顶层设计的贫困户识别程序示意图
第三,在识别程序方面,顶层设计在定标准和定规模的基础上进一步对贫困识别的程序和做法进行了规范。《方案》规定贫困人口识别以“整户识别”为单位,以农户收入为基本依据,同时综合考虑住房、教育、健康等综合情况,遵循“农户申请、民主评议、公示公告和逐级审核”的基本程序进行识别。按照国家制定的识别程序图示(见图1),贫困户的识别工作主要由县级政府开展落实。先由农户自愿申请,各行政村召开村民代表大会对申请农户进行民主评议,形成初选名单并进行第一轮公示,无异议后报乡镇政府审核,确定乡镇一级贫困户名单并进行第二轮公示,无异议后再报县级部门复审,复审结果在各村公告。以上是顶层设计的精准识别程序,这是中国扶贫开发历史上首次在国家层面确立贫困人口识别的基本程序规范。在实施过程中,各省市对具体识别步骤和过程予以进一步细化,呈现出地域差异性和地方创新性。
第四,在政策执行周期方面,中央要求各地必须在2014年5月底前完成贫困户的初步识别工作,7月底之前制定具体的结对帮扶计划,8月底完成贫困户数据的录入建档。可见第一阶段的贫
困户识别工作时间相当紧迫,根据《方案》的发布时间计算,初步识别必须在两个月内完成,该时间还将包括前期的组织准备、宣传反动和人员培训等环节。首轮识别的时间安排服从于国家脱贫攻坚工作的整体部署,是精准扶贫顶层设计的一部分。同时,首轮识别带有探索和摸底性质,为此后的动态调试奠定了基础。在实施过程,时间压力给基层政府和一线扶贫工作人员带来较大的挑战。
第五,在责任制度方面,为了保证顶层设计落地见效,贫困识别的指标任务和政治责任必须逐级分解到地方。在中国这样一个幅员辽阔、行政层级众多的国家,如何将国家制定的贫困识别政策从中央落实到省、再从省落实到县乡、然后从县乡落实到各个行政村和自然村?对此,国家层面确立了“中央统筹、省负总责、市县抓落实”的识别工作责任体系①参见国务院扶贫开发领导小组办公室:《脱贫攻坚责任制实施办法》。。省级政府根据中央政策制定契合本省实际的识别工作方案,担负总体责任。县级政府主抓识别任务的具体落实,对上承接国家任务、负责政策落地,对下开展识别工作人员的培训和动员、识别政策的宣传和落地、识别过程的组织和监督、以及识别结果的审核和问效。在操作过程中,具体识别工作主要由多个层级组成的一线扶贫队伍(包括驻村工作队和第一书记)完成,县乡村三级通过层层签订责任状的形式明确工作责任。
上述五个方面体现了中国精准识别政策的顶层设计,其总体特点是:国家统筹规划设定基准,在标准、规模、程序、时间和责任等方面设计出最基本的规范和要求,保证各地识别工作有章可循和有令可依。此外,在做到“全国一盘棋”的同时,识别政策也为地方保留了灵活调试和因地施策的空间,不做“一刀切”、不追求“一蹴而就”,在空间和时间维度上维系了精准识别政策的可调试性。
(二)空间维度的调试性执行
在顶层设计层面,国家制定了精准识别的基本标准和程序。作为贫困识别的“元政策”,中央明确了识别过程中的“规定动作”,同时保留了足够的调试空间,以利于地方政府根据自身的条件和情况开发“创新动作”。地方政府在贫困识别的程序安排、工作方法、否决政策和运行机制等方面各具特色,这种空间维度的调试性执行促进了国家精准识别政策的有效落地。
首先,在程序安排上,省级政府在贫困识别政策的精细化和规范化过程扮演了关键角色,识别程序在省与省之间呈现出一定的差异。各省、自治区、直辖市都在国家标准程序的基础上制定了适合本地的精准识别标准和建档立卡工作方案,省级以下扶贫单位均按照本省的实施细则执行。我们搜集整理了全国28个担负脱贫攻坚任务的省级单位②除北京、上海、天津和港澳台地区之外。制定的相关政策文件,分析发现各省市的贫困识别政策在评议和审核环节存在一定差异,主要可分为两种类型(见图2)。
第一种类型是“先评议、后审核”。采取该做法的省份包括山西、辽宁、吉林、湖北、湖南、四川、云南、宁夏、福建、内蒙古、江西、海南、重庆、青海、新疆。此外,根据是否在“村民代表大会评议”(行政村层面)之前附加“村民小组评议”程序(自然村、自然屯层面),又可分为一轮评议和两轮评议。例如,辽宁省确立的识别程序为“农户自愿申请或村两委推荐—村民代表大会民主评议形成初选名单—村两委和驻村工作队核实后村内公示—报乡镇审核公示—县级复核筛查公告”,即先评议后核实,并采用村民代表大会“一轮评议”。内蒙古自治区制定的识别程序为“农户申请—村两委、驻村工作队组织自然村农户代表评议—初始名单依次报乡镇、旗县、盟市、自治区进行比对,并反馈—村两委、驻村工作队召开村民代表大会评议表决—乡镇核查、公示—旗县抽查公示”,也是先评议后审核,但采用自然村和村民代表大会“两轮评议”。
第二种类型是“先调查打分或审核、后评议”。采用该做法的省份包括河北、江苏、安徽、贵州、西藏、陕西、甘肃、河南、浙江、黑龙江、广东、广西、山东。同时,按照评议次数也可细分为一轮评议和两轮评议。例如,安徽省采取先调查、后“一轮评议”,其程序为“农户自愿申请—组织入户调查—村民代表大会评议—村两委或驻村工作队入户核实并公示—乡镇审核第二次公示—县级复审并公告”。广西自治区采用先打分、后“两轮评议”,其程序为“农村居民户申请—入户调查打分—村民小组、村两委组织村民代表评议并公示—乡镇人民政府审核—县级人民政府审定、公告和建档立卡”。根据笔者在广西的实地调研,在调查打分环节,贫困村实行对每户家庭进行调查打分,非贫困村实行仅对申请家庭调查打分。

图2 贫困人口识别政策的落地调试
上述两种类型主要按照“村民评议”与“调查审核”的程序先后来划分,在识别政策执行过程之所以出现这些差异,是因为国家标准程序只规定了“农户申请—村民代表大会评议”的简易程序。然而,在实际操作过程中会出现诸多困难,例如评议的依据是什么?评议人对申请人的情况不了解怎么办?如何防止评议过程中的偏私行为?如何解决识别中的争议?等等。因此,基于提升评议过程公正性和评议结果公信力的需要,必须对申请人的基本情况进行调查和核实。家庭摸底调查和信息核实应该设置在评议之前还是之后,国家政策并没有明文规定,因此地方结合本地需要采用了不同的做法。
其次,在工作方法上,各省入户调查和贫困家庭信息采集的具体工作方法也存在较大差异。虽然国家标准规定了以2013年农民人均纯收入2 736元为基准来识别贫困人口,但具体识别过程中,对农户实际收支进行测量和估计异常困难。第一,农户的收入、资产和消费等信息存在非结构性和模糊性。经济学中收入的测量通常分为工资性收入、生产经营性收入、财产性收入以及转移性收入,但贫困家庭往往没有固定的工资收入,农产品营收收入也不稳定,其生产经营过程中的种子、农药、化肥、农具等支出也难以估算。第二,我们在问卷调查中发现,多数农户对自己的收支情况没有具体概念,访问中经常回答“不知道具体多少”“差不多”“不会算”等。第三,收入评估过程中,县乡与村两委之间存在委托代理困境,村两委与农户之间存在信息不对称性问题,申请人在申报收入时有隐匿自身实际收入的动机,村委位干部也有利用手中权力庇护特定人员的可能。第四,收入多寡虽然是贫困最直接的表现形式,但致贫原因却多种多样(例如因病、因学、因残、因灾等)。同时,精准扶贫要求做到“两不愁三保障”,即不愁吃、不愁穿,上学有保障、就医有保障、住房有保障,如果仅以收支来衡量贫困,可能会漏识部分扶贫目标群体。
因此,为了更加精准全面地评估申请家庭的真实经济状况,各地在国家标准的基础上创制出各具特色的贫困识别操作办法(见表2)。例如,甘肃颁布了《脱贫攻坚“853”挂图作业实施意见》;贵州和西藏提出了贫困识别的“四看法”;湖南总结了贫困识别的“五评法”;河南提出了“一进二看三算四比五议六定”的工作法;重庆按照“四进七不进、一出三不出”标准开展识别。举例来说,河南省的“一进二看三算四比五议六定”工作法要求:包村干部、村级组织和驻村工作队或第一书记对全村农户逐家进户调查走访,摸清底数(一进);看房子、家具等基本生活设施,看是否拥有家用轿车、大型农机具、高档家电(二看);按照标准逐户测算收入和支出,算出人均纯收入数,算支出大帐,找致贫原因,对贫富情况有本明白账(三算);和全村左邻右舍比较生活质量(四比);对照标准,综合考量,逐户评议(五议);正式确定为扶贫对象的,由村“两委”推荐确定,乡镇党委政府核定(六定)。贵州省的“四看法”规定:一看房(住房条件、人均住房面积、出行条件、饮水条件、用电条件、生产条件);二看粮(人均耕地面积、种植结构、人均占有粮食);三看劳动力强不强(劳动力人数、健康状况、素质收入);四看家中有没有读书郎(教育负债和教育回报)。此外,一些省内地方政府也对识别工作进行了创新。例如,江西省井冈山市按照“村内最穷、乡镇平衡、市级把关、群众公认”的原则,根据申请人的贫困程度提出“三卡识别”方法,即把贫困程度较深的作为“红卡户”,贫困程度一般的作为“蓝卡户”,已脱贫的作为“黄卡户”,做到精准分类,力求做到“贫困户一个不漏,非贫困户一个不进”①参见中央纪委国家监委网站:脱贫攻坚的井冈答卷。http://v.ccdi.gov.cn/2018/05/02/VIDEjUeBv3yQyuKu EKbiJ88Y180502.shtml(2020年4月12日访问)。。湖北省巴东县创新开展“屋场院子会”的识别方法,形成了“选主持、定地点、明对象、讲政策、听意见、贴公示、核信息、留痕迹”的八步走议程。综上可见,贫困人口识别是一项精细复杂的系统工程,顶层设计的识别标准在落实过程中需要融合各个地方的创新调试。

表2 部分省/市/自治区的精准识别工作方法
再次,在否决政策上,地方政府在标准识别程序之外还制定了“一票否决”政策。这些政策标定了明显不符合申请资格的各种情况,只要申请家庭存在这些情况就会在评议和审核阶段被剔除。例如,重庆市的“七不进”、山东省的“十不评”、青海省的“八不准”、河北省的“六不得”、黑龙江省的“11种类型”、海南省的“9个不予纳入”等。各省“一票否决”政策名目不一,被纳入的否决项目通常包括“家庭成员中有财政供养人员”“在城镇拥有购买的商业、住宅等商品楼房”“家庭拥有享受型轿车、船舶和大型农机具”“全家外出若干年以上”,等等。一些省份的政策显得更加严格,例如山东省规定“法定赡养、抚养、扶养人有赡养、抚养、扶养能力,但未依法履行义务,致使家庭成员未获得赡养、抚养、扶养权益的家庭”将被一票否决;青海省规定“家庭成员具有健康劳动能力和一定生产资料,又无正当理由不愿从事劳动的,且明显有吸毒、赌博、好吃懒做等不良习性导致生活困难的农牧户”不能评为贫困户。“一票否决”政策有效地提升了识贫的精度和效率,确保了识别过程的公平性,有助于识别结果获得广大民众的认可。
此外,为了更加精准地排除不符合帮扶标准的申请户,地方政府还运用“大数据”技术对农户家庭情况进行核查,结合政府掌握的房地产交易信息、居民户籍信息、工商注册数据、司法数据等对“一票否决”情况开展筛查排除。2017年,国务院扶贫办出台政策优化识别程序,在原有评议、核实和公示的基础上增加了“比对”环节,明确要求各地要加强数据比对,以县为单位将贫困人口名单与相关行业部门开展数据比对和复审,重点核实申请贫困户家庭拥有城镇住房、车辆、经营实体、财政供养人员等情况。各级扶贫部门积极推进信息化建设,与民政、教育、财政、金融、公安、卫健、人社、住建、残联等行业部门建立数据交换共享机制,为精准识别提供大数据支撑。例如,贵州省搭建起精准扶贫大数据平台,打通公安、卫计、教育、人社、住建、民政、水利、国土、工商等17个行业部门相关数据,通过数据比对贫困户信息,快速核定该户家庭是否有小轿车、商品房、财政供养人员等,其中黔东南地区经过对1 925户“异常户”进行大数据核查,最终清退562户①参见“贵州:大数据打通精准扶贫‘经络’”,http://www.xinhuanet.com/info/2018-05/15/c_137179784.htm。。
最后,在识别机制上,不同省市在“基于社区的瞄准法”和“代理家计调查法”两者之间也有不同侧重。贫困识别是一个精细复杂的过程,除了大数据比对,还需要发挥乡土社会的“地方性知识”优势,依托基层自治组织和协商民主机制,吸纳广泛的社会参与。国家政策规定精准识别的结果必须经过村民民主评议,该识别方法类似国际通行的“基于社区的瞄准法”,也是中国大多数省市重点采用的识贫方法。各地民主评议的具体程序和操作方法存在一定差异,一般都要求评议过程必须有村两委干部、驻村第一书记、乡贤代表、党员代表、人大代表、妇女代表、普通村民代表、驻村工作队员等参与其中。这样做一方面有利于扩大识别信息的获取范围,借助熟人社会的信息优势对申请人家庭情况进行核实,增加识别的精准度。另一方面,村民参与有助于防范村干部的专断和腐败行为,提升识别过程的透明性和公正性,经过评议和公示的结果也更容易获得群众认可。以云南省为例,村民小组和村民委员会按照“三评四定”程序召开贫困识别评议会,由村两委干部、第一书记、退休干部、老党员、村民代表、妇女代表、驻村工作队员等组成评议会,评议申请家庭经济状况和人口信息的真实性,以及是否存在漏户、拆户、分户、空挂户现象等情况,评议结果需经过投票表决,并要求参加评议的代表和负责干部在评议表上签名或按手印确认。
在精准识贫过程中,部分省份首次采用了量化打分方法(即“代理家计调查法”,PMT)。该方法借助国际经验,从多个维度设计出农户家庭经济状况的综合测量指标,并设定了每项指标的权重,通过打分和加总得到贫困状况的综合评分结果,以此作为划定贫困的依据。例如,广西自治区制定了“精准识别入户评估表”,并规定以村民小组为工作单元,由2~3位下派工作队员组成评估小组,运用“一进二看三算四比”方法开展入户调查评分(村两委及村民小组长不得参与评分)。该评分表共纳入16项考核指标,包括住房、家电、农机、机动车、饮水、用电、道路情况、健康情况、读书情况、劳动力、务工情况、人均土地面积、养殖业情况、种植业情况,外加一些特殊情况的加分项和减分项。工作队员需要对照评估表逐项评分,最后将所有项目的计分累加起来,得到一户家庭的综合评分结果,得分越低代表越贫困。整村的调查工作结束后,工作队按分值高低排序填写“精准识别入户评估得分统计表”,然后根据县政府划定的贫困线确定贫困户初步名单,并进行评议和复核。根据广西自治区扶贫办提供的资料,首轮识别行动中,共有约10万名工作队员实地走访了600多万家农户,调查了近2 000万群众的“家底”,获得“一个一个人头数过来”的贫困识别数据。
入户调查打分的识别方式在贵州、湖南和海南等省份也得到不同形式的应用。根据我们在广西的调研访谈,打分方法的主要优势在于:(1)指标体系囊括多个维度,能够更加全面系统地评估农户的真实经济状况;(2)有一套明确的考评体系和评估标准,可操作性强、执行速度快;(3)规范的评分标准可以增加户与户之间的可比性,更能够让人信服;(4)客观公正、有据可查,可以预防腐败行为。然而,该方法也存在一些局限:(1)一些指标较难精确地测量,指标权重设置在特定情况下显得不够科学;(2)贫困分数线上下的农户家庭经济状况差别不大,有的农户因为高出几分而未能评上,造成“边缘户”的现象;(3)上级派驻的工作组和调查人员不了解村里和农户的实际情况,可能出现错评和漏评;(4)该方法需要较大的时间和人力投入。出于这些局限性,大部分省份并未采用该方法。根据我们的全国抽样调查数据①数据来自作者所在课题组于2019年夏天进行的全国农村问卷调查,该调查聚焦“精准扶贫与基层治理”,采用科学抽样程序,共抽取了全国9个省、18个县、51个村,有效样本包括村民1 340位,村干部273名。,在“村民评议”和“入户打分”之间,只有24.1%的村干部和22.3%的村民倾向于支持打分方法。虽然,目前量化打分方法在中国贫困识别过程的运用范围和接受程度有限,但可以作为精准识别政策调试性执行的有益尝试。
(三)时间维度的调试性执行
精准识别不是一蹴而就、一劳永逸的短期行动,而是需要不断积累经验、不断查缺补漏、不断动态调整的长期工程。精准识别既要实现“静态的精准”,即把当前的贫困人口找出来;又要追求“动态的精准”,即把已经脱贫的人口、识别不准的人口退出去,把漏评人口、返贫人口和新发生贫困人口及时纳进来。2014年精准识别政策出台之初,国家就提出“一年打基础、两年完善、三年规范运行”的长期工作目标。伴随着脱贫攻坚进入不同任务阶段,精准识别的政策、程序、结果以及工作重点都需要动态调整,这种时间维度上的可调试性是确保脱贫攻坚总体任务顺利完成的关键。
精准识别的渐进调试是由新时期中国脱贫攻坚工作中的各种实际情况决定的。首先,中国在贫困人口的精准识别方面缺乏先期经验,此前的扶贫开发多以县和村为单位,未涉及对具体贫困家庭的识别。其次,中央制定了精准识别的一般标准和程序,留给地方政府较大的自主性,然而地方经验不足、做法不一,效果参差不齐。再次,首次识别时间较短,一些地方存在政策理解不到位、学习培训不深入、准备不充分、执行不严格等问题。最后,随着扶贫工作推进,陆续有贫困户脱贫退出,同时出现因病因学因灾等新发生贫困人口或返贫人口,需要对建档立卡贫困户进行动态调整。因此,精准识别是一个动态过程,需要在渐进调试中不断更新完善。
截至目前,新时期脱贫攻坚中的精准识别工作大致经历了以下几个主要调整阶段(见图3):
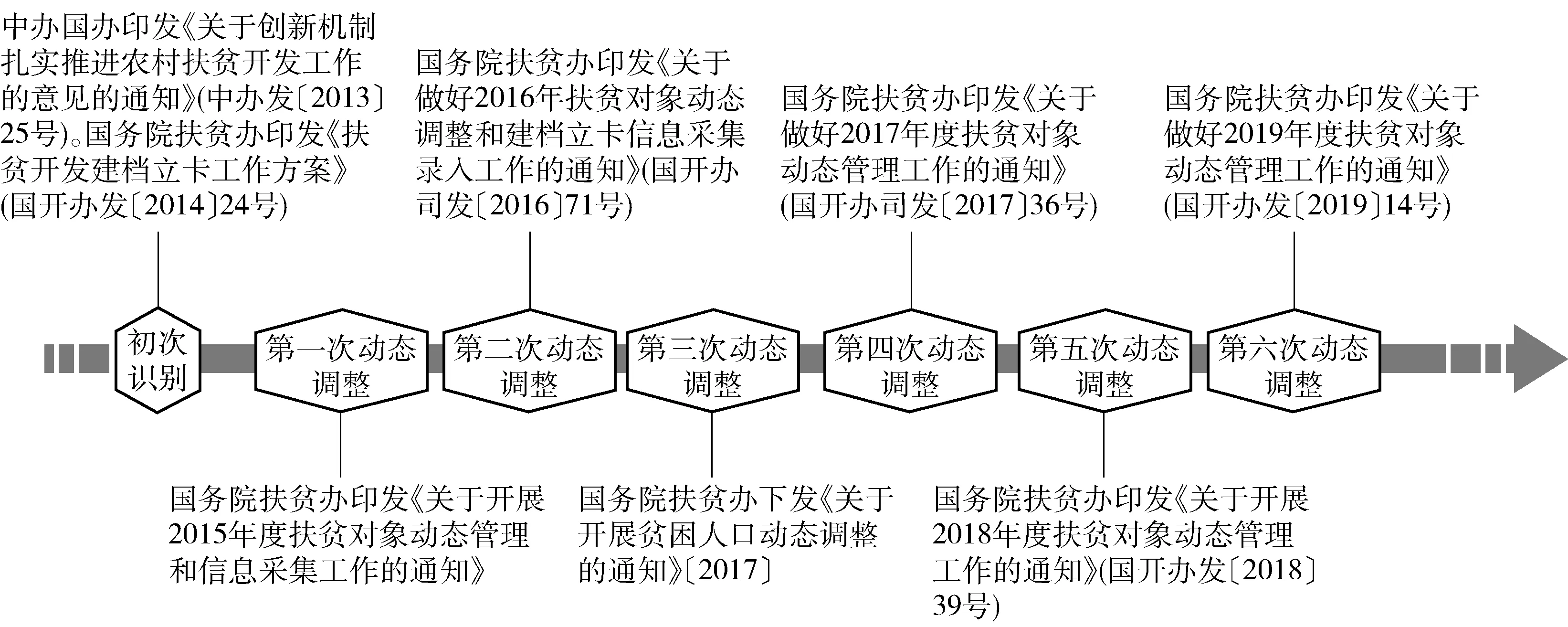
图3 中国精准识贫的渐进调试
(1)初次识别:2013年12月18日,中办国办联合印发《关于创新机制扎实推进农村扶贫开发工作的意见的通知》(中办发〔2013〕25号),要求按照“县为单位、规模控制、分级负责、精准识别、动态管理”的原则,对每个贫困户建档立卡,建设全国贫困人口信息网络系统。2014年4月2日,国务院扶贫办印发《扶贫开发建档立卡工作方案》(国开办发〔2014〕24号),启动贫困识别和建档立卡工作,由此产生了第一批建档立卡贫困户。全国共识别2 948万贫困户、8 962万贫困人口,基本摸清了我国贫困人口分布、致贫原因、脱贫需求等信息。
(2)第一次动态调整:2016年2月4日,国务院扶贫办印发《关于开展2015年度扶贫对象动态管理和信息采集工作的通知》。根据中央提出的“两不愁三保障”①2015年,中共中央、国务院印发《关于打赢脱贫攻坚战的决定》,提出到2020年,要稳定实现农村贫困人口不愁吃、不愁穿,义务教育、基本医疗和住房安全有保障,即“两不愁三保障”。的扶贫总体目标,此轮动态管理的重点工作为2015年达到脱贫标准(2015年人均纯收入达到2 855元)的建档立卡贫困户按照程序脱贫退出。
(3)第二次动态调整:2016年10月8日,国务院扶贫办印发《关于做好2016年扶贫对象动态调整和建档立卡信息采集录入工作的通知》(国开办司发〔2016〕71号),在综合考虑“两不愁、三保障”标准的基础上,将2016年人均纯收入低于2 952元的贫困农户按照程序纳入建档立卡管理,并强调不再实行规模控制。此次动态调整涉及识别新贫困户、纳入返贫户、剔除不精准识别户。
(4)第三次动态调整:2017年6月13日,国务院扶贫办下发《关于开展贫困人口动态调整的通知》,要求7月至9月组织开展以“应识尽识,应纳尽纳”为主要内容的贫困人口动态调整工作,并将识别程序完善为“两评议两公示一比对一公告”,加强与行业部门的数据比对。此轮动态调整规模较大,全国共重新识别贫困人口700多万人,其中返贫人口82万,并清退了一批识别不精准人口。以云南省N县为例,该县在2017年7月对贫困人口展开了拉网式排查,进一步查缺补漏,落实应纳尽纳、应退尽退、应扶尽扶。通过此次动态调整,该县新增贫困对象835户2 267人,返贫户4户12人,不精准剔除857户3 026人②N县扶贫办数据组,《N县贫困对象动态管理工作汇编》(2018年10月19日)。。
(5)第四次动态调整:2017年10月24日,国务院扶贫办印发《关于做好2017年度扶贫对象动态管理工作的通知》(国开办司发〔2017〕36号),要求开展2017年动态调整工作,确保脱贫人口有序退出,同时将符合新年度识别标准的贫困人口纳入建档立卡管理。2018年初,国家再次利用大数据分析,筛选出200多万疑似“脱贫不实”脱贫人口,要求基层开展复核和“回退”工作。
(6)第五次动态调整:2018年9月16日,国务院扶贫办印发《关于开展2018年度扶贫对象动态管理工作的通知》(国开办发〔2018〕39号),部署2018年动态调整工作,针对2018年度年新致贫户、返贫户、自然变更贫困人口进行动态管理。此轮识别进一步落实“应纳尽纳”政策,规定将非建档立卡的贫困人口按照程序纳入扶贫对象管理,且综合考虑以下因素:实际居住C级、D级危房且自身无力改造;家庭因病致贫,且成员未参加城乡居民基本医疗保险;家庭适龄成员因贫辍学,或家庭因学致贫。《通知》还规定享受低保政策但仍符合国家扶贫标准的也应纳入帮扶。
(7)第六次动态调整:2019年9月,国务院扶贫办印发《关于做好2019年度扶贫对象动态管理工作的通知》(国开办发〔2019〕14号)。要求各地开展对扶贫对象的动态调整工作,包括脱贫贫困户有序退出、识别新贫困户和返贫户、核查贫困户家庭成员自然增减等。此外,此轮调整还特别强调对非建档立卡农户中的“边缘户”进行摸底,采集和录入相关信息,并对已脱贫户中的不稳定户(脱贫监测户)进行排查,并在全国扶贫信息系统中进行标注。
由上可见,自2014年首次精准识别贫困人口以来,国家还以年度为节点定期对识别结果进行动态调整和考核问效,实现了动态识别的常态化和规范化。此外,为进一步提高贫困识别的精准度,国务院扶贫办还在全国范围内开展了多轮建档立卡“回头看”工作。全面核查建档立卡贫困户的识别状况,对不符合条件的在库贫困户进行清退,对符合条件的返贫及新增贫困户重新识别录入。根据国务院扶贫办公布的资料显示,2015年和2016年开展建档立卡“回头看”期间,全国共补录贫困人口807万,清退识别不准人口929万。2017年、2018年开展动态调整期间,全国补录贫困人口849万,剔除识别不准人口412万,贫困识别准确率不断提高①参见国务院扶贫开发领导小组办公室:《关于政协十三届全国委员会第二次会议第1551号提案答复的函》。。2019年,国务院扶贫办再次印发《关于组织开展脱贫人口“回头看”工作的通知》,启动新一轮“回头看”工作,全面排查脱贫人口“两不愁三保障”的实现情况,力求做到“脱贫即出,返贫即入”。与此同时,为了更好地完成精准识别和动态调整的任务,各级地方政府也开展了多种形式的自查自纠和“回头看”整改工作。
总体来看,中国的精准识贫在时间维度上经历了以下几个渐进调试过程:(1)在识别标准上,从以人均纯收入为单一标准发展到综合考虑“两不愁三保障”等多方面因素;(2)在识别人数上,从自上而下的规模控制转为应识尽识、应纳尽纳、应扶尽扶、应退尽退,扩大精准扶贫的受益面;(3)在识别程序上,从“农户申请、民主评议、公示公告、逐级审核”完善为“两评议、两公示、一比对、一公告”,强化程序正义;(4)在识别信息的存储和运用方面,从纸质的建档立卡发展到建立起全国统一的扶贫开发信息系统,运用大数据分析开展对识别和脱贫状况的核查;(5)在关注对象方面,从注重建档立卡贫困户拓展到覆盖“边缘户”、返贫人口和新发生贫困人口,致力于解决相对公平和动态管理问题。应该说,经过渐进调试,“中国的贫困识别工作做到了从基本精准到比较精准”②参见国务院扶贫开发领导小组办公室:《关于政协十三届全国委员会第一次会议第2217号提案答复的函》。。
三、结论
贫困治理本质上是一种国家主导下的“再分配”行为,如何识别和确定分配对象,如何有效地分配扶贫资源,一直是政治学关心的核心议题。哈罗德·拉斯维尔认为政治就是“谁在什么时候以什么方式获得什么”。[26]中国精准扶贫的治理目标是实现“扶真贫、真扶贫”,注重精准识别的体制机制设计和方式方法创新,致力于克服优亲厚友、弄虚作假、干部腐败等现象,实现扶贫目标靶向的精准。为了解决“帮扶谁”的核心问题,新时期的脱贫攻坚探索出一套“顶层设计与调试性执行相结合”的贫困人口识别制度。一方面,通过顶层设计确立全国统一的识别标准、识别程序、识别规模和识别时间,并依托“中央统筹、省负总责、市县落实”的责任机制将识别任务层层分解,按照“县为单位、规模控制、分级负责、精准识别、动态管理”的原则落地实施。另一方面,精准识贫的政策过程还在空间和时间维度上呈现出调试性。在空间维度上,各地在贫困识别的程序安排、工作方法、否决政策和运行机制等方面各具特色,空间维度的调试性执行推动了国家政策的有效落地。在时间维度上,国家以年度为节点对识别标准、程序、规模、工作重心、关注对象等进行渐进调试,时间维度的调试性执行确保了贫困识别的“动态精准”。
“顶层设计与调试性执行相结合”的贫困识别模式具有诸多优势:第一,有利于中央政府通过顶层设计实现对精准识别工作的集中统一领导,以上率下、统筹规划,确保贫困识别标准、程序和规范上的全国统一,以及时间和进程上的步调一致。第二,有助于激发地方政府和基层扶贫队伍的积极性、主动性和创造性,将国家政策转化为适合本地情境的工作方法,防止“一刀切”,确保识别工作的高效运行。第三,不同层级之间的沟通互动有助于精准识别体制机制和方式方法的逐步调试和完善,让基层识别过程中的困难、经验以及所汇集的贫困人口数据转化为高层决策的依据和资源,不断提升识别的精准度。第四,促进构建有效的识别分工体系和责任落实机制,让不同层级和不同参与主体各司其职,明确主体责任,同时发挥各自的资源和能力优势,实现“合力攻坚”。
诚然,世界上没有完美无缺的贫困识别制度,中国的精准识别工作也伴随着问题和挑战。例如,顶层设计的初期曾对贫困人口进行规模控制,该规模层层分解到基层成为名额限定,导致一些地区在首轮识别中无法纳入所有符合标准的贫困人口,该问题在动态调整过程中得到及时纠正,转为“应识尽识、应纳尽纳”;识别制度的差异化落地早期曾导致一些地方莫衷一是,担心自己的做法是否符合中央政策,带来迟疑和困惑,该问题随着“一年打基础、两年完善、三年规范运行”逐渐缓解;识别政策的渐进调试曾让识别的程序、标准和要求发生较大变化,致使一些地方需要推翻前期识别结果、重新开展识别,造成精力和资源的浪费,该问题随着识别政策的逐步完善而得到解决。中国经验表明,优良的贫困识别制度不仅需要科学理性的顶层设计,还需要在实践中不断创新完善和动态调试。
通过构建“顶层设计与调试性执行相结合”的贫困人口识别模式,新时期的精准扶贫在中国历史上首次精准地识别出贫困人口和贫困家庭,首次实现对全国贫困人口分布状况和致贫原因的精准把握,为确保扶贫开发工作的精准、公平、高效扣好了“第一颗扣子”,为2020年决胜全面建成小康社会打下了坚实基础,也是贫困治理中国经验的重要组成部分。
猜你喜欢
江苏安全生产(2023年10期)2023-11-14 12:13:08
公民与法治(2020年2期)2020-05-30 12:28:44
领导文萃(2019年5期)2019-03-19 12:01:10
电子制作(2018年12期)2018-08-01 00:47:44
制造技术与机床(2017年6期)2018-01-19 02:41:21
中国经济周刊(2017年40期)2017-10-20 09:47:58
人大建设(2017年2期)2017-07-21 10:59:25
中华诗词(2017年10期)2017-04-18 11:55:24
电子制作(2017年19期)2017-02-02 07:08:38
当代化工研究(2016年6期)2016-03-20 16:21:46
