
基于无人机航测数据的森林郁闭度和蓄积量估测
2020-02-22 04:14:38苏迪高心丹
林业工程学报 2020年1期
苏迪,高心丹
(东北林业大学信息与计算机工程学院,哈尔滨 150040)
森林是地球生态系统中重要的组成部分,其碳汇功能在维持全球碳平衡方面发挥着重要作用。森林蓄积量是生物量和碳储量研究的重要参考因素,是评价森林固碳能力的重要指标,也是森林资源调查的重要因素。传统的一、二类森林资源调查是测算森林蓄积量的重要方法,这两种方法虽然准确度较高,但在时间与空间上存在较大的局限性,调查过程会耗费大量的时间和人力[1-2]。如何在准确获取森林蓄积量信息的同时,快速、高效地为区域生态状况评估提供参考[3-5]已成为研究热点。
近年来,随着遥感技术的发展,基于遥感因子的森林蓄积量估测方法因其可以快速、高效获得蓄积量模型而引起了国内外学者的广泛关注[6-8]。回归建模估测法因其工作量相对较少、估测频率高、估测覆盖面积大等优点逐步成为基于遥感因子蓄积量估测研究的主要方向[9-11]。按照自变量数量可以将蓄积量回归模型分为一元和多元回归,按照方程表现形式可以分为线性和非线性回归[12-13]。研究森林蓄积量的线性回归方法主要有最小二乘法、逐步回归法、主成分回归法、偏最小二乘法[14-16]。其中,偏最小二乘法结合了多种回归方法的功能和优点,有效地改善了模型自变量间的多重共线性问题,目前已广泛地应用于各领域的估测研究中[17-20]。带有点云数据的航测数据与其他遥感数据相比,具有分辨率高、细节更完善、时效性强、成本低等优点,可以更准确地提取蓄积量的相关特征因子[21-23],从而提高蓄积量估测精度。
本研究利用无人机航摄影像点云数据估测树高和胸径因子,使用正射影像通过分水岭算法提取树冠个数,结合提取的坡向等因子,用主成分回归方法估测郁闭度,结合全部因子通过偏最小二乘回归方法估测森林蓄积量。
1 研究区域与数据
1.1 研究区域
以帽儿山林场老山施业区森林为研究区域(127°18′0″~127°41′6″E,45°2′20″~45°18′16″N),该林场是东北林业大学实验林场,位于尚志市西北部,场址距市区40 km,隶属于尚志国有林场管理局。林业用地面积26 067 hm2,其中有林地面积23 204 m3,森林总蓄积1 879 380 hm2,森林覆盖率83.29%。老山施业区属于帽儿山林场的一部分,原始地带植被为阔叶红松混交林,现存植被以红松、樟子松、落叶松人工林为主,该区域具有丰富的森林资源适合进行蓄积量研究。
1.2 研究数据
研究数据1 来源于航测数据,原始图像数据来源于型号为DJI X3 的无人机拍摄而成的影像,机上搭载Canon⁃EOS⁃60D 数码相机拍摄,有效像素1 240 万,最大分辨率可达到4 000×3 000 ppi,成像时间为2015 年9 月14 日,利用航空影像中获得DOM(digital orthophoto map,数字正射影像图),DOM 影像面积达到4 723.169 7 hm2,其地理坐标为xian80,研究区域内的DOM 与小班矢量图叠加图像见图1。用lasmerge 软件将多个点云数据合成为一个点云数据,按照研究数据2 实测范围对点云数据进行裁剪,其地理坐标为xian80,其面积为3 129.276 hm2,平均点云密度为49 point/m2,按高程显示的点云数据图像见图2。
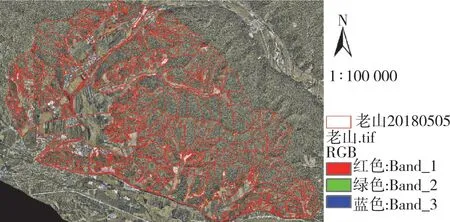
图1 DOM 与小班矢量图叠加图像Fig.1 DOM and sub⁃compartment vector overlay image
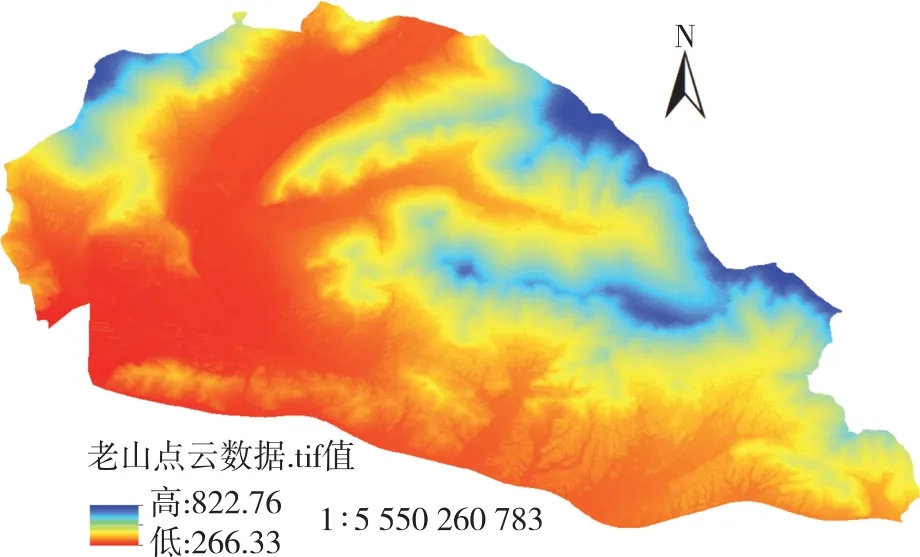
图2 点云数据图像Fig.2 Point cloud data image
研究数据2 是实测数据,为帽儿山林场老山实验区森林资源二类调查数据。其中包括2015 年调查的1∶10 000 地形图,618 个以矢量地理信息数据形式储存的小班二类调查数据。
研究数据3 为实测数据,为东北林业大学帽儿山实验林场森林固定样地数据,2004 年调查更新的比例尺1∶25 000 的固定样地分布图,调查总面积为26 496 hm2,包含263 个样地的二类调查信息。
1.3 样地筛选
不同类型的GIS 因子数据对蓄积量模型精度有严重的影响,为了减少该影响,对研究数据2、3中的针阔混交林小班采用标准差分析法剔除样本中离群较大的数据,即剔除样本中的数据。重复上述步骤,最终选择到120 个针阔混交林样本数据。将所有数据进行中心标准化处理,去除因各个因子间量纲不同带来的影响,统一所有因子的量纲,如式(1)所示:
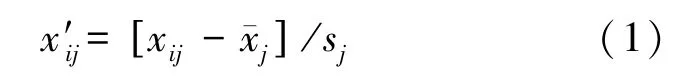
2 特征参数提取与结果
利用GIS 技术提取与森林蓄积量相关的树冠个数、平均树高、平均胸径、坡度、坡向、海拔、小班面积、郁闭度这8 个GIS 因子建立蓄积量模型,通过该方法提高蓄积量的估测精度。本研究先使用ArcGIS10.2 软件将DOM 图像和点云数据图像按照小班边界进行裁剪,为进行特征因子提取做准备。本研究结合点云数据、DOM 图像和研究区小班矢量数据,以二类调查小班为单位对树冠个数、平均树高等因子进行估测,对海拔、坡向等因子进行提取,获得建立蓄积量模型所需的特征因子,特征因子提取流程图见图3。
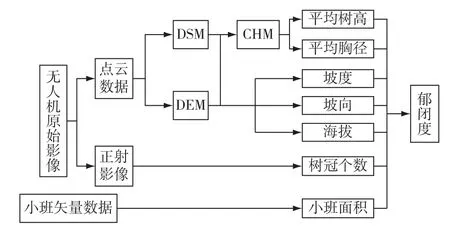
图3 特征因子提取流程图Fig.3 Feature factor extraction flow chart
2.1 特征参数的提取
2.1.1 分水岭树冠个数提取
分水岭算法适合提取边缘微弱较敏感、分辨率高、细节多的影像轮廓,但传统分水岭算法存在过分割问题,为了解决该问题,本研究将120 个小班正射影像作为分水岭分割的原始图像,首先使用支持向量机的分类方法将其分为针叶林和阔叶林;其次采用最大熵法分别获得针叶林和阔叶林的最优阈值,比较针、阔叶林的最大熵最优阈值,发现针叶林最优阈值大于阔叶林最优阈值;最后对形态学开闭重建处理后的针阔混交林图像进行基于阈值标记的分水岭分割,第1 次将小于阔叶林阈值区域进行标记和分水岭分割,第2 次将大于阔叶林最优阈值,小于针叶林最优阈值进行分割得到树冠轮廓图像。
2.1.2 树高和胸径的估测
使用LIDAR360 工具对点云数据进行去噪处理,生成0.5 m 分辨率的DEM(digital elevation model,数字高程模型)和DSM(digital surface model,数字地表模型)。由于DEM 模型中只有地形的高程信息,不包括DSM 模型中的森林树木高度等地表信息的高程,因此从DSM 中减去DEM 即可获得CHM(canopy height model,冠层高度模型)。
CHM 中每个点的像素值即为该点的高程值,通过MATLAB 2013b 软件编程,读取各个小班样本的CHM 模型平均高程,只保留高程值不为0 的点进行平均高程的计算。由于CHM 为冠层模型不能等同于树高,因此需要结合读取的CHM 平均高程利用一元线性回归方法建立平均树高模型和平均胸径模型。
2.1.3 海拔、坡向、坡度、小班面积因子的提取
使用LIDAR360 软件在DEM 基础上生成等高线图(图4a)。其中比例尺为1∶1 000、三角形最大边为30 m、间曲线等高距为2.5 m、首曲线等高距为5 m、计曲线等高线为25 m。利用DEM 数据生成坡向图像和以10°为间隔进行处理生成坡度图像,如图4b、c 所示。
使用Python2.0 编程,用双线性插值法提取等高线、坡向和坡度平均值。使用ArcGIS10.2 软件结合小班矢量图计算小班面积,提取各项因子为接下来建立郁闭度和蓄积量模型提供特征因子。
2.1.4 郁闭度估测
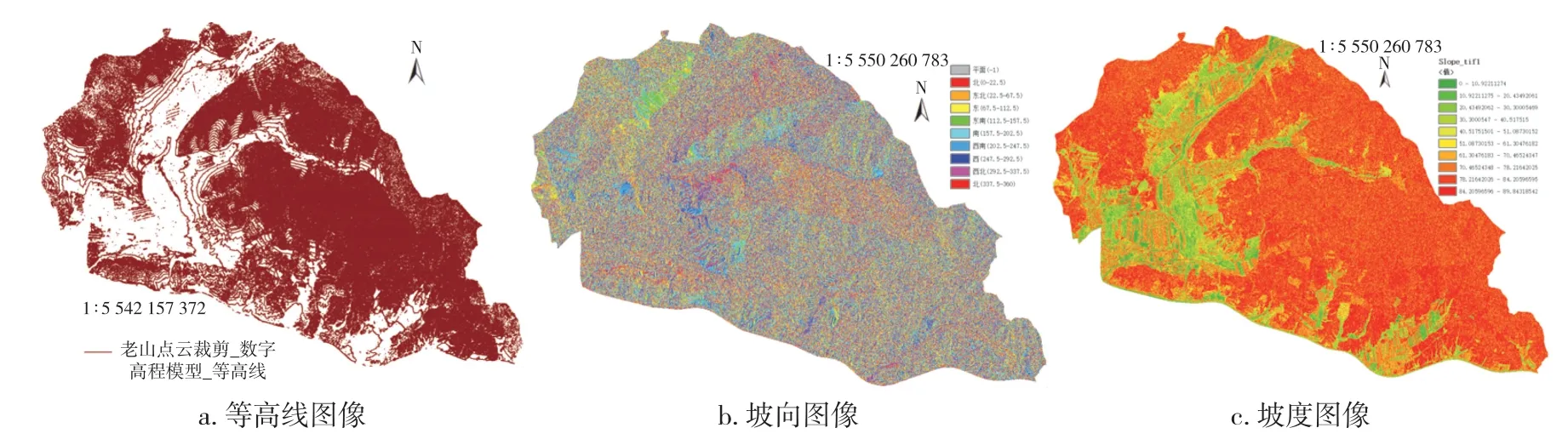
图4 等高线、坡向、坡度图像Fig.4 Contour line,aspect,slope image
主成分回归是主成分分析和回归估计结合的方法,主成分分析是一种变量降维技术,是将多个相关变量重新组合成几个主成分变量,减少变量个数的变量分析方法。该方法能够简化分析过程,提高分析效率。同理主成分回归是用合成后的主成分变量进行回归分析,不仅保留了原自变量对因变量的影响,还消除了各个变量相互间的共线性问题。本研究通过主成分回归将树冠个数、平均树高、平均胸径、坡度、坡向、海拔、小班面积这7 个特征因子组成若干相互独立的主成分,根据各个主成分的贡献率大小选取模型最终的主成分变量,建立郁闭度回归模型。使用MATLAB 2013b 编程,分析1~70 号小班数据,得出了各主成分的特征根、主成分得分、主成分累积贡献率。按照贡献率累积80%以上的选取标准,根据贡献率的大小顺序选取主成分,主成分与特征因子间的关系方程,再根据主成分的构成,还原郁闭度方程,得到郁闭度与7个特征因子的关系模型。
2.2 特征参数的提取结果
2.2.1 树冠个数提取结果
实验使用2.1.1 部分改进后分水岭分割算法提取树冠轮廓信息,将树冠分割结果图像进行二值化处理计算连通区域得到树冠个数,通过公式(2)计算分割准确率和平均分割准确率来显示分割效果。

式中:Ad为准确率;为平均准确率;Nc为分割的树冠个数;Nd为小班树木株数总数(实测小班株数);n为图像个数。
通过计算得到120 个样地DOM 图像的传统分水岭平均分割精度为52.89%,改进后分水岭平均分割精度为80.03%,能够达到基本分割要求,改善了传统分水岭存在的过分割现象,分割后得到的树冠个数可以用于建立蓄积量模型。经计算,23 号样地树冠分割精度与平均分割精度最相近,所以选择该样地图像进行显示(图5)。

图5 样地23 图像Fig.5 Sample plot 23 image
2.2.2 平均树高、平均胸径估测结果
根据2.1.2 部分得到平均树高和平均胸径模型结果如下:

由图6 和平均树高、平均胸径模型的平均精度可知,估测值与实测值的拟合程度较好,且都是由CHM 直接进行估测而成,充分利用点云数据所生成的CHM 数据。
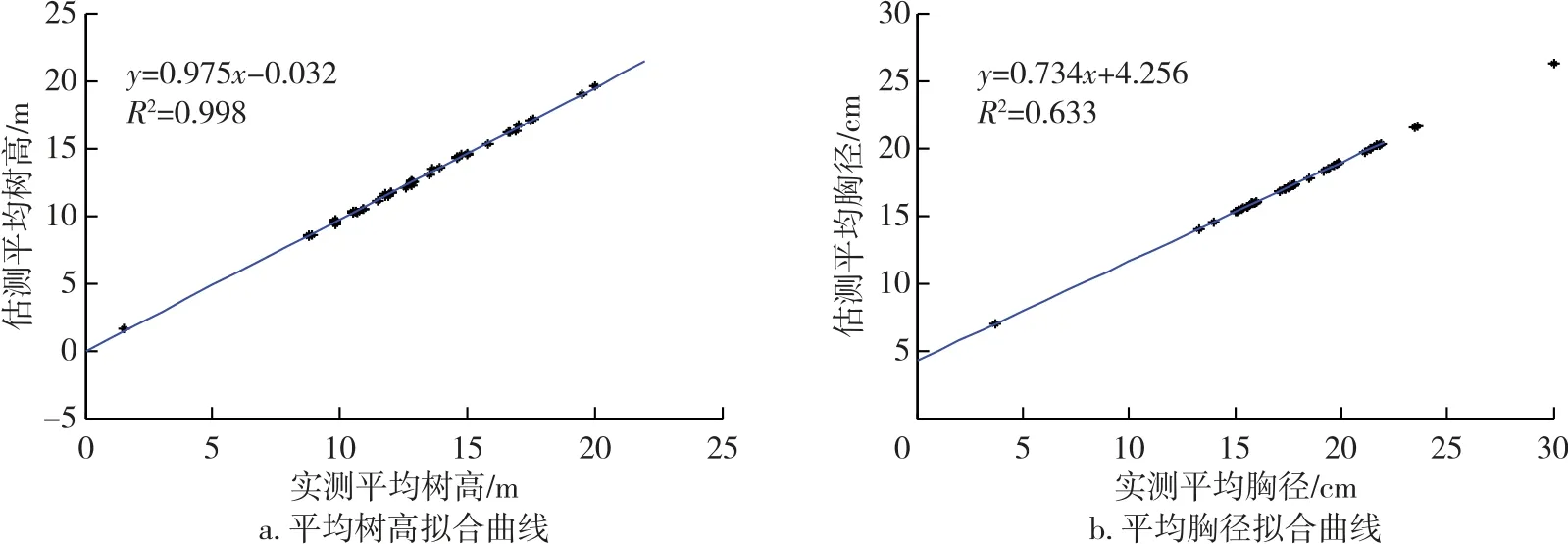
图6 平均数高和平均胸径拟合曲线Fig.6 Average height and average DBH curve
2.2.3 郁闭度估测结果
由2.1.4 部分将7 个变量进行主成分分析,其中第1 主成分贡献率32.087%,第2 主成分贡献率24.375%,第3 主成分贡献率18.005%,第4 主成分贡献率13.769%。前4 个主成分贡献率已达到88.235%,符合主成分选取要求,选取前4 个主成分因子为新变量。则公式(5)~(8)为4 个主成分与特征因子间的关系方程。
第1 主成分为:
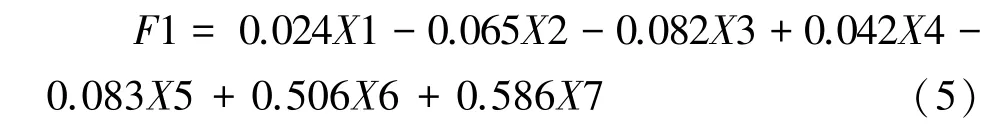
第2 主成分为:
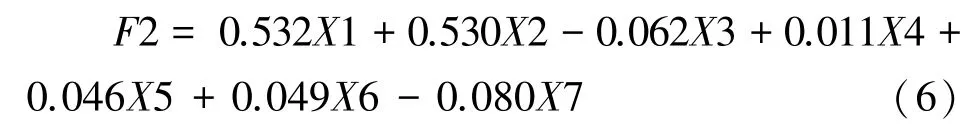
第3 主成分为:
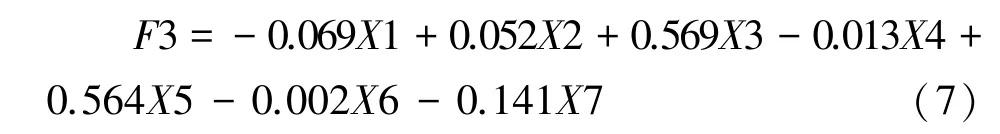
第4 主成分为:
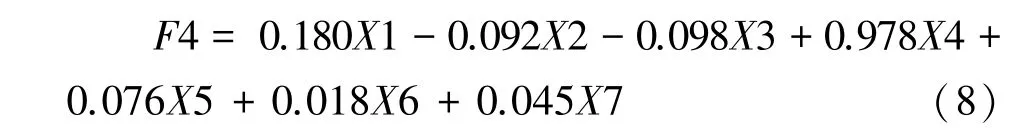
公式(5)~(8)中:X1 为小班平均树高;X2 为平均胸径;X3 为坡度;X4 为坡向;X5 为海拔;X6 为小班面积;X7 为分水岭提取的树冠个数。
主成分回归在减轻原始变量的多重共线性问题后,得到以4 个主成分为新自变量的郁闭度模型,回归方程为:
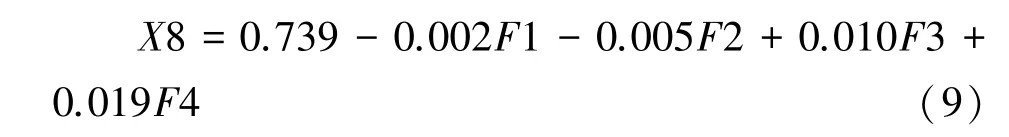
根据4 个主成分的构成,将回归方程还原,得到关于自变量X1—X7 的回归方程为:
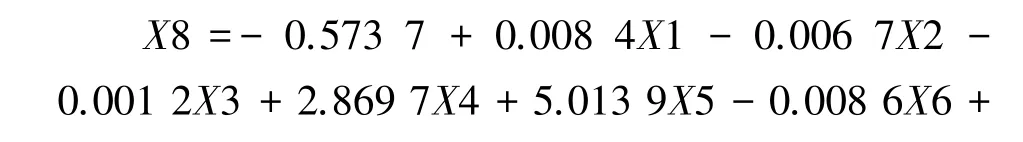

方程(9)和(10)中X8 为郁闭度,通过71~120号50 个检验数据进行精度检验,郁闭度模型(公式10)精度为83.18%,可以达到精度要求,再结合前文所有提取和估测的特征因子建立蓄积量模型,进一步研究各个特征因子与蓄积量之间的关系。
3 蓄积量估测模型
3.1 偏最小二乘回归方法
偏最小二乘回归方法是一种集典型相关分析和主成分分析优点以及功能于一身的多元线性分析方法。该方法由于精度高,稳健性实用性好而被广泛地应用于各种估测研究中。
设已知单个因变量Y和自变量X=[x1,x2,…,xp],样本个数n,偏最小二乘法从X和Y的相关矩阵中提取主成分t,使用Y和X对t进行回归,对于回归分析的需要,偏最小二乘回归在提取成分时添加以下两个目标:1)尽可能多地在t中携带X矩阵数据表中的变异信息;2)t和Y的相关程度能够达到最大。在对X和Y进行一次成分提取后,分别进行X对t的回归和Y对t的回归。如果回归方程达到了满意的精度,就停止计算,否则将X关于t回归后的残差矩阵与Y关于t回归后的残差矩阵进行新一轮的成分提取。反复重复这个过程,直至满足交叉有效性原则规定的条件,最终确定提取主变量成分的个数,建立偏最小二乘回归方程[19]。
3.2 蓄积量模型的建立
借助SPSS 软件,通过相关性分析得到与蓄积量存在显著关系的8 个自变量如表1 所示,表中X1—X8 同前文。
表1 表明各因子间存在多重相关性,一般回归模型已不适用,偏最小二乘法对自变量的选择门槛不高,不需要选择最优因子,且较多变量有益于对提取的主成分进行累计解释分析,因此本研究采用偏最小二乘法建立森林蓄积量估测模型。
在MATLAB 2013b 软件中按照偏最小二乘原理编写PLS 回归代码,对1~120 号样本用偏最小二乘法建立蓄积量模型,对模型进行交叉有效检验,得到原始变量的回归方程系数,据此可以拟合出基于偏最小二乘回归方法蓄积量方程。
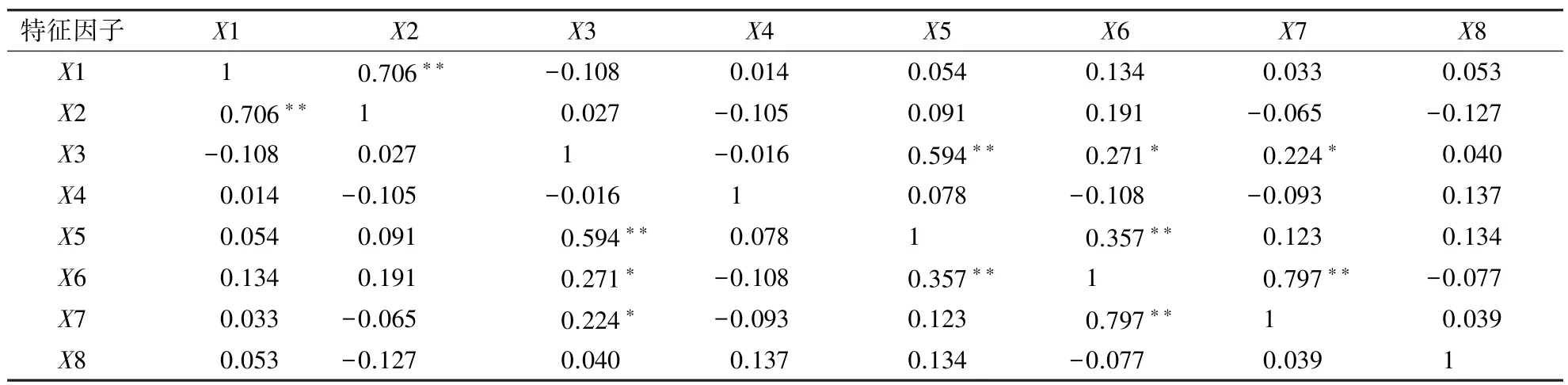
表1 特征因子相关系数Table 1 Characteristic factor correlation relationship table
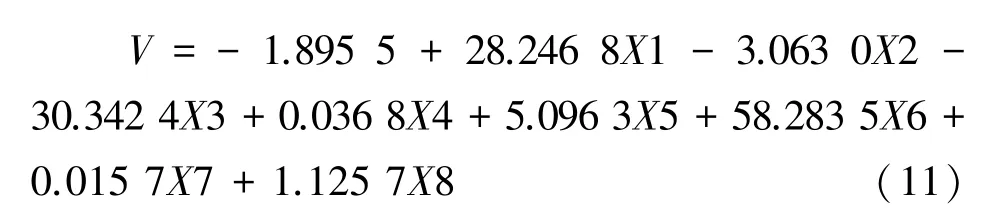
式中:V为蓄积量,方程包含的X1—X8 与上文一致,将30 个固定样地检验样本数据代入方程(公式11),得到蓄积量估测值,为模型评价和精度检验做准备。
3.3 模型评价和精度检验
结合预留的121~150 号30 个验证样本实测数据和蓄积量方程(公式11)估算的森林蓄积量得到图7 实测值与估测值折线图。

图7 实测值与估测值折线图Fig.7 Line chart of stock volume measured value and estimated value
从图7 中可以看出估测的蓄积量值整体偏大,通过对蓄积量实测值和估测值进行配对T检验,得到T=-0.374,P=0.657>0.05,说明实测值和估测值相比虽然整体偏小,但不存在显著性差异。
使用实测值与估测值对模型进行评价,根据模型的决定系数R2,均方根误差RMSE,总体相对误差RS,平均相对误差MRE,预估精度Pr为评价指标。根据公式(12)~(16)计算:

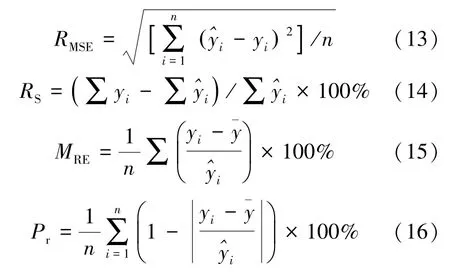
式中:yi为蓄积量实测值;为蓄积量模型预测值;为蓄积量实测样本平均值;n为检验样本数;i表示第i个样本。本研究蓄积量模型(公式11)的R2=0.738 6,RMSE=5.135 3 m3/hm2,说明模型拟合效果较好。利用模型偏差统计量进行比较并评价模型的预测能力,RS=-1.285 8、MRE=-0.263 0,说明估测蓄积量与实测蓄积量偏离不大,可以很好地进行蓄积量估测;精度达到88.43%,估测能力较好,并且有一定的可推广性。
以蓄积量实测值为横坐标,估测值为纵坐标,建立实测值和估测值散点图,建立的散点图趋势线拟合效果较好,实测值和估测值比较吻合(图8)。
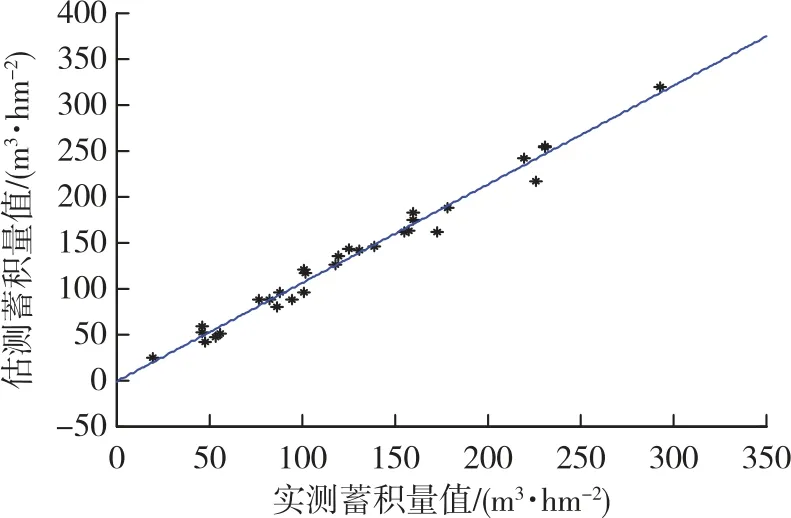
图8 蓄积量实测值与估测值的散点图Fig.8 Scatter plot of measured and estimated values of stock volume
4 结论
利用无人机影像生成的点云数据和正射影像估测蓄积量的方法,能够在充分利用无人机影像的同时最大限度地保留无人机影像的细节和各种因子的特征,提高特征参数的提取精度。该方法不仅提高了实施效率、降低了估测成本,还为代替人工野外实测森林调查信息提供了可能。无人机数据生成的正射影像与高分辨率卫星影像相比具有重叠度大、分辨率高等优点;其生成的点云数据不仅可以代替机载雷达获得高程信息,还具有航线灵活、操作方便、时效性好等优点。无人机航测数据弥补了高分辨率卫星影像无法同时获得影像和高程信息的缺点,在估测森林生物量和蓄积量方面应用前景广阔。
本研究利用无人机航摄方法采集了黑龙江帽儿山林场老山实验区航摄影像,利用三维点云数据提取CHM 模型高程,估测了平均树高和平均胸径;用改进的分水岭算法获得了树冠个数;用DEM数据获得坡度等特征信息,估测了森林蓄积量。使用帽儿山林场固定样地数据作为检验样本,结果表明,平均树高提取精度达到97.34%,平均胸径提取精度达到91.27%,树冠个数提取精度达到80.03%,郁闭度模型精度为83.18%,森林蓄积量估测精度达到88.43%,满足森林调查精度要求。研究得到如下结论:1)在提取CHM 平均高程值时不计算高程值为0 的点,减少了点云数据空白点对平均树高、胸径模型的影响;2)通过遥感技术提取特征因子,用主成分回归的方法可有效地估测郁闭度;3)模型中所有因子都是通过遥感与回归方法提取或估测生成,使用偏最小二乘回归方法建立蓄积量模型,为信息化、自动化提取特征因子估测蓄积量提出可能。由于时间和试验条件限制,仍存在很多不足和改进的地方,如波段信息对蓄积量估测的影响等方面有待进一步研究。
猜你喜欢
东方企业家(2020年5期)2020-05-29 08:13:43
福建林业(2020年5期)2020-03-18 08:23:02
山西文学(2019年8期)2019-11-01 02:14:24
文学港(2019年5期)2019-05-24 14:19:42
热带林业(2019年4期)2019-03-05 09:53:58
山东林业科技(2018年6期)2019-01-08 09:48:04
森林工程(2018年3期)2018-06-26 03:40:46
山东林业科技(2017年1期)2017-06-29 07:54:06
林业与生态(2016年2期)2016-02-27 14:23:42
农民致富之友(2014年7期)2014-10-21 20:06:25
