
基于大数据的网约车平台定价规则分析1
2020-02-21 10:30
交通与港航 2020年1期
上海财经大学公共政策与治理研究院交通经济与政策研究中心,上海财经大学公共经济与管理学院
0 引 言
近年来,网约车的出现改变了人们的日常出行方式,网约车平台所采用的技术与理论成为经济学、管理学、交通运输工程及计算机科学领域的研究热点,众多学者从不同专业角度进行了探讨[1,2]。与传统的出租车运营方式有所不同,网约车平台根据客户需求提供个体机动化定制服务,供需匹配算法及动态定价策略是其中的两项关键技术,相关算法模型、定价方式及运行效果引发研究者的高度关注[3-5]。这些研究构建了多种定价策略的理论模型,研究的重点在于如何通过价格调节手段实现司机与乘客的快速匹配,以提高平台运营效率,节省客户等待时间,实现乘客、司机及平台三方利益最大化。
网约车定价问题的研究意义表现在以下三个方面:首先,通过分析网约车的定价规则并使其透明化,可以帮助消费者获得更多的信息,确保乘客在出行交易中的知情权,维护其正当权益。其次,有助于政府部门实施有效的价格监管,防止平台过度攫取消费者利益、获得垄断利润。第三,有助于评估交通基础设施的使用效率,维护市场秩序,促进不同运输方式之间的公平有序竞争。因此在“互联网+交通”高速发展时期,借助大数据分析工具,对网约车定价方式进行深入分析和探讨,对构建平台、司机、乘客及监管者等参与方的合作共赢关系以及推动网约车平台健康持续发展具有重大的现实意义。
网约车定价是一种复杂的市场行为,现有研究侧重建立理论模型进行分析,而市场行为的复杂性很难完全采用理论来准确刻画。为此,本文采用基于真实订单数据的实证研究方式,根据某网约车平台公开的近百万条订单记录,在统计分析的基础上提取出多种可能影响定价规则的特征,采用包裹法结合增l减r法等多种方法对这些特征进行判断选择,筛选出决定该网约车平台定价规则的关键因素。分析发现,这些特征可分为三类:
第一类包含行程距离、行程时间、车型等,这与传统的出租车定价规则相似。
第二类包含每小时订单数、起点区域订单数、终点区域订单数等,显示网约车平台会根据不同时段、区域的乘车需求变化适时地调整定价。
第三类与乘客累积消费金额、累积预约次数等信息相关,表明网约车平台注重收集乘客个人数据,分析其消费行为,并在最终的服务定价上明显地反映出来。
本文应用提升决策树算法(gradient boosting decision tree,GBDT)对订单的行程金额进行回归分析,预测结果均值为74.67±4.63元。这表明,本文筛选出的特征及建立的算法模型可以对网约车定价规则做出准确的刻画描述。本文详细分析了这些关键特征所起的作用及算法模型的输出结果,研究成果可为政府监管及相关理论研究提供重要的技术参考。
1 数据集说明及基本统计分析
本文数据取自国内某知名网约车平台的公开数据集,该数据集包含2017年7月全部订单数据及8月1~7日部分时段订单数据,共988175条记录。表1显示每条订单记录包含11个字段。

表1 订单记录包含字段及含义
本文的研究目的是挖掘数据集中每个“行程金额”数据背后隐含的定价规律。从数值上看,行程金额最小值为15元,最大值为5077.1元,中位数为59.68元,均值为75.62元,标准差为67.16元。采用自组织混合网络模型[6]进行概率密度估计,所得的分布函数如图1所示。
从图1可看出,行程金额(单位为元,以下省略)具有长尾分布特性,98.4%的数据集中分布在[15.0, 241.6]区间范围内,而在[241.6, 5077.1]区间数据分布非常稀疏。对[241.6, 5077.1]区间数据采用箱线图(boxplot)进行分析,发现其下四分位数Q1=261.36,上四分位数Q3=361.0,四分位间距IQR=99.64,高位极端异常值=659.92。在订单记录中,行程金额大于659.92的记录共有708条,均值为1387.73,平均每条订单的行程距离为163.07公里,这已超出一般市内交通运输的范围,并且最终成功交易数仅占18.5%。显然,这部分数据具有完全不同的统计特性,需剔除出来逐条分析处理。本文重点分析余下987467条记录的数据。
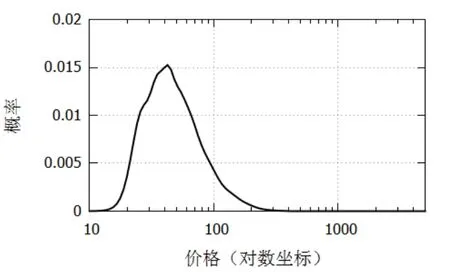
图1 行程金额的分布函数
从订单状态可看出,当乘客发出用车需求时,平台可能存在没有司机接单的情况,将有或无司机接单两种情况分别进行统计,可得两者的概率密度分布函数如图2所示。从图中可以看出,无人接单的记录,其价格分布平均右移,在数值上表现为无司机接单记录的平均每公里运价比有司机接单记录高出约18.8%。这表明,网约车平台可以及时掌握车辆供给信息,并通过提高价格来激励车辆进入市场以实现供需双方的平衡。
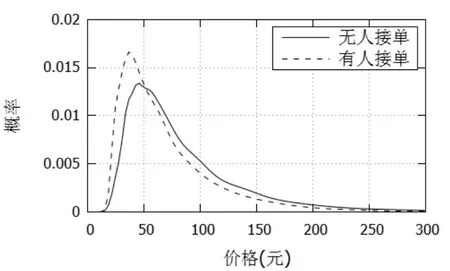
图2 有司机接单与无司机接单情况下的价格分布函数
2 特征构造及选择方法
大数据与机器学习中所有方法都依赖于一组用来描述对象性质的特征。每一种算法的成败取决于其所构造的特征能否很好地反映所研究问题的本质。正如本文的研究,如果选择了错误的特征,就会对网约车定价问题产生错误的理解。特征选择通常可分为过滤法与包裹法[7]。过滤法先利用可分性准则来选择特征,再进行分类或者回归拟合;包裹法则利用所有的特征来设计算法,然后考察各个特征在算法中的贡献,逐步剔除贡献最小或无关的特征。本文在不同阶段分别选择性地使用这两种方法。
从表1可以看出,本文所使用的数据集中,司机、乘客、起点区域、终点区域仅有编号信息且进行了hash变换。这些特征无法直接使用,但可以通过统计变换计算出这些字段相应的频次、均值、方差等统计量,然后利用对应的统计值来表征这些特征。其次,在某些情况下,必须根据分析目标针对性地构造出相关的统计特征。例如,我们推测每位司机所使用的车辆类型不尽相同,不同车型可能对应不同的收费标准,为此可以统计出每位司机每公里的平均运费,以此判别不同车型及其收费标准。
通过统计分析及特征构造,理论上可以组合出近乎无限维数的特征,这时需采用绘制数据分布曲线、散点图(scatter plot)、计算相关系数等方法进行基本的分析判断。图3、4给出了两组特征的分布曲线和散布图示例。

图3 行程距离与运价的散点图
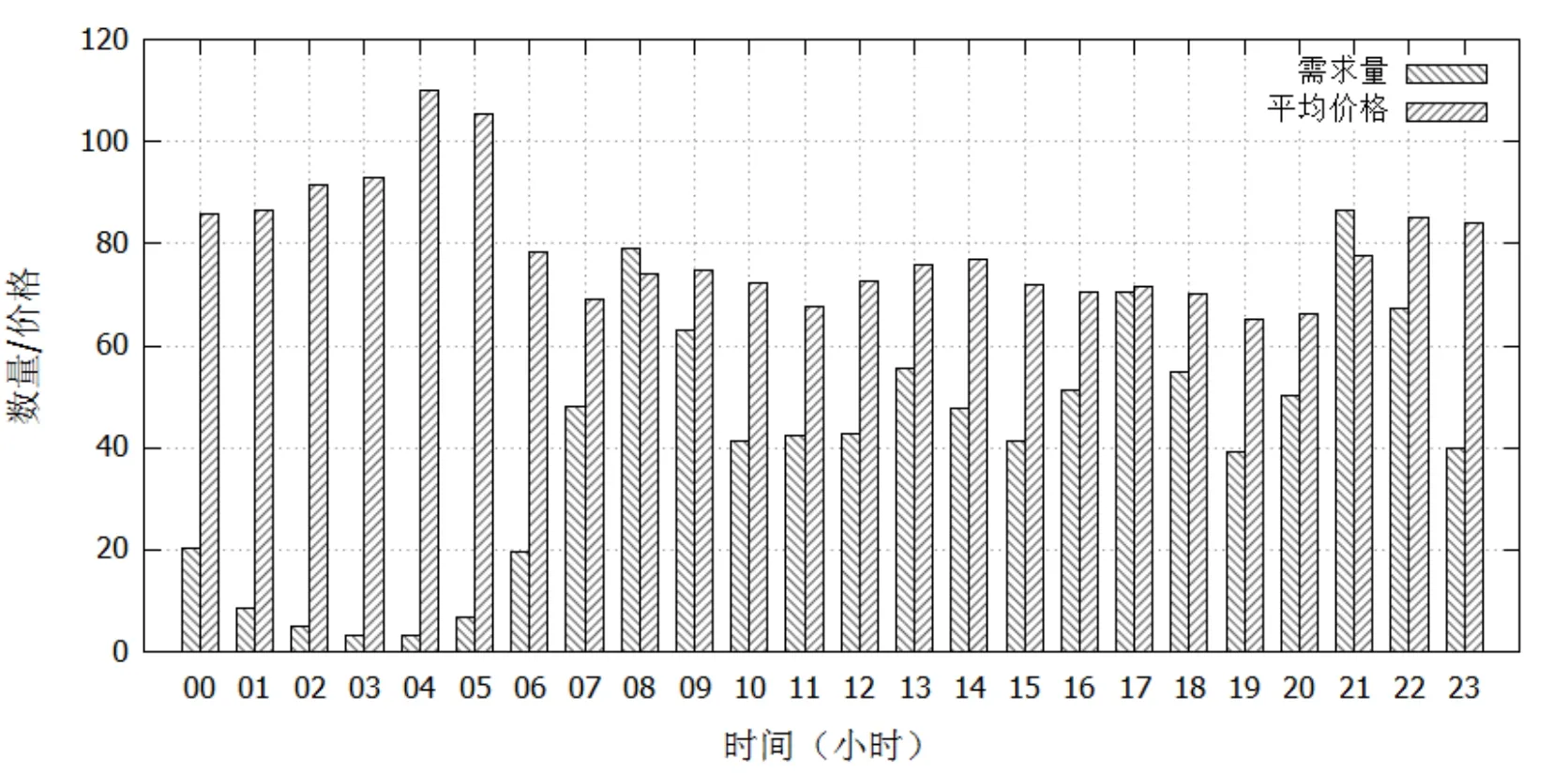
图4 每小时订单需求量及平均运价
从图3可以看出,行程距离与运价之间为强相关(Spearman秩相关系数为0.9186),并且它们之间呈现出明显的线性关系。从图4每小时订单需求总数及平均运价上看,在每天凌晨2点至6点之间,网约车需求量大幅下降,而此时的服务价格比其它时段高出约20%。
在初步判断筛选的基础上,我们进一步利用包裹法进行特征选择。本文以GBDT算法作为包裹器(wrapper),将算法与特征选择集成起来。特征选择理论上可采用分支定界、遗传算法等多种方法,但必须考虑到包裹法本身非常耗费计算资源,与这些算法结合将产生巨大的计算量而变得难以运行。综合性能与效率两方面的考虑,本文选用增l减r法来进行特征选择,具体步骤如下:
(1)针对运价估计问题,选择最小化均方差(MSE)为特征判别准则;
(2)选择行程距离、行程时间等关键因素作为主要特征;
(3)逐步增加l个与其它特征组合后准则最优的特征;
(4)逐步剔除r个(r<l)与其它特征组合后准则最差的特征;
(5)重复步骤(3)-(4),直至没有特征的增减会引起准则的变化。
通过上述算法步骤,最终确定以下13维特征为决定网约车运价的关键因素(见表2)。

表2 决定网约车运价的关键特征及与运价的相关系数
3 数学建模及结果分析
利用表2筛选出的13维特征,本节应用多元线性回归、随机森林、支持向量机、GBDT等多种算法从多种角度进行建模分析,验证所选择特征的合理性及回归分析结果的可靠性。特征分析过程中,我们将数据分为[15.0, 241.6]、[241.6, 659.9]两个组别进行讨论。
多元线性回归方法的分析结果如表3所示。线性模型虽然形式简单,但易于建模且蕴含着机器学习中的一些基本概念与思想,同时可直观地表达各个特征在预测中的重要性,可对各种特征在回归模型中所起的作用给出总体的解释。
从回归结果可以看出:(1)两组数据的复相关系数分别为0.939和0.830,说明多元线性回归效果良好;(2)在两组数据中,行程距离、司机每公里运价(按车型)、每小时平均运价、Day of week等特征对运价的作用均相当显著;(3)乘客的累积消费金额对定价的影响也非常明显,并且呈现正相关特性;乘客累积预约次数对定价也有一定影响,呈负相关性,相当于消费(预约)次数越多,平台对价格给予一定的折扣。
GBDT算法拟合结果如表4所示。提升树可以拟合输入与输出数据之间复杂的关系,是机器学习及大数据分析中性能最好的方法之一[8]。在提升树算法中我们采用8折交叉验证的方法,将数据集分为8等份,每次依次取出1份数据作为校验数据,其余7份数据作为训练数据,最后以8次交叉验证的平均值作为最后的结果。从表4可以看出,在提升树算法中学习结果得到大幅度的提升,第1组数据的最小化均方差MSE从14.36下降到8.26,第2组数据的MSE从45.49下降到11.65。
对于决策树算法,通常可用每个特征被选中的频次及由此对优化目标函数所带来的作用来衡量其贡献大小。本节以每个特征所带来的均方误差减少值除以总的均方误差减少值,来表示每个特征的重要程度(以百分比表示)。从表4可以看出,有些在相关性分析或线性回归中不被认为重要的特征(如乘客累积消费金额)实际上对网约车定价产生了重要的影响,而有些特征正好相反(如Day of week)。这是由于在相关性分析或线性回归分析中,每一维的特征都被分开单独考虑,而提升决策树算法则将所有特征综合在一起,从更高的维度分析问题,因此能得到更精确的分析结果。
从表4中可以看出,随着学习算法的提升,“乘客累积消费金额”这一特征的重要性不断提高,在长距离订单(第2组数据)中,其重要程度甚至超过了30%。从数据上看主要有两种原因:(1)对于长距离订单,行程时间无法精确估计,因此这一特征的重要性下降,而其它特征的作用就会明显表现出来。(2)长距离订单的定价规则有更大的随意性,往往会因人而异,“乘客累积消费金额”则部分反映了乘客的消费习惯和乘车偏好,因此它对定价的正向影响在长距离订单中的权重有所增加。

表3 多元线性回归分析结果(按第1组数据偏相关系数排序)

表4 提升决策树分析结果(按第1组数据重要性排序)
对全部987 467条记录(均值=74.67)统一建立一个包含30 000颗决策树的GBDT回归模型,采用8折交叉验证得到平均绝对误差为4.63,即预测结果为74.67-4.63,相对误差仅为6.2%。这一结果表明,利用本文所筛选出的特征可对网约车定价规则做出准确的刻画描述。
需进一步说明的是,本文所使用的训练数据集数据量相对有限,由此造成有些统计量会带有一定程度的偏差,对算法的预测精度也会带来较大影响。此外,数据中有许多关键信息被hash处理而刻意隐藏。在获得更充分数据的前提下,本文算法的预测精度还可较大幅度地提高。
4 结 论
本文应用多种特征选择方法,从网约车大数据中合理筛选出定价规则的关键特征,在此基础上进行回归分析,得到较为精确的预测结果。分析发现,网约车的定价特征可分为三个组成部分。第一部分定价特征与传统的出租车定价规则相似,比如行程距离和时间、每小时平均运价以及司机每公里运价(按车型)等。第二部分包含订单需求变化信息,比如每小时订单数、起点和终点区域订单数等,表明网约车平台会根据乘车需求的时空变化适时调整定价,充分体现出动态定价的优势。第三部分与乘客的消费信息相关,说明网约车平台注重收集数据分析乘客消费习惯,存在消费越多则定价越高的相关关系,同时也反映出消费次数越多给予一定价格折扣的激励策略。
这种按照需求变化和乘客消费习惯的定价策略及其所带来的影响值得进一步深入分析与讨论。首先,第一部分定价特征说明网约车与传统巡游出租车本质上属于同质服务,两者在价格机制上遵循大体相同的原则,即以行程距离、行程时间、车型等因素作为定价的主要依据。其次,第二部分特征表明网约车定价相比出租车考虑了更多精细化因素,由于需求和供给在时空上的分布不均匀、也不匹配,此时动态定价体现了价格对供给的激励作用,有利于市场资源实时配置,这正是网约车的竞争优势所在。第三部分特征反映网约车平台利用大数据对消费者偏好进行刻画并实施个性化定价,这也是判断平台是否存在价格垄断和过度攫取消费者利益的重要依据,进一步对消费水平和定价关系的合理性做出判断后,可为政府部门对平台的价格监管提供分析工具和判断标准。

猜你喜欢
车主之友(2022年6期)2023-01-30
法律方法(2022年2期)2022-10-20
山西青年(2020年3期)2020-12-08
活力(2019年19期)2020-01-06
活力(2019年17期)2019-11-26
消费导刊(2018年10期)2018-08-20
中央民族大学学报(自然科学版)(2017年3期)2017-06-11
航运交易公报(2016年9期)2016-03-19
航运交易公报(2016年9期)2016-03-19
航运交易公报(2015年40期)2015-11-30
