
基于学习自动机和用户兴趣的PageRank算法研究
2020-02-19 14:08姜金川
计算机工程与应用 2020年3期
姜金川,王 冲
桂林电子科技大学 计算机与信息安全学院,广西 桂林541004
1 引言
伴随着网络信息技术的飞速发展,越来越多的信息资源出现在网络上,如何高效、快速、便捷地向用户提供相关信息以满足他们的需求成为当前搜索引擎的首要目标。当用户提交检索关键词时,搜索引擎会返回大量的搜索结果集,用户需要从这些返回的结果集中搜寻自己需要的信息,这无疑会浪费大量的时间。Page和Brin[1]提出的PageRank算法被用于Google搜索引擎中,它通过分析链接来衡量页面的重要性。虽然PageRank算法已成功运用于Google中,但是它仍然存在一个问题:在实际的网页中,网页中的某些链接可能比其他链接更重要。
本文通过对经典PageRank算法进行深入的研究分析,发现PageRank算法主要存在以下不足:(1)由于与查询关键词无关而导致查询到的网页PR值高但是不符合用户检索意向的主题漂移问题;(2)对链接到本页面的网页不考虑网页权威度而采用的平分链接权重的问题;(3)忽略用户浏览行为而造成的忽略用户兴趣问题;(4)由于旧网页在网络中存在的时间长,获得网页链接几率更大,导致PR值越高的偏重旧网页问题。本文着重针对PageRank算法存在的平分链接权重和忽略用户兴趣问题,提出了一种基于学习自动机和用户兴趣的页面排序算法LUPR(Page Rank based on Learning Automata and User Interest)。
本文首先介绍了PageRank算法、WPR算法以及相关改进算法和学习自动机。其次,对LUPR算法进行了详细的阐述,一方面使用学习自动机确定网页之间超链接的权重;另一方面通过对用户行为的进一步分析和提取,获得兴趣度因子。然后,通过MyEclipse、Heritrix和Lucene工具搭建仿真环境,对比实验验证排序质量。最后对本文的改进算法进行了总结并给出了下一步的研究工作。
2 相关算法及技术
2.1 PageRank算法
PageRank算法[2]是一种基于网络链接关系的网页排序算法,在图1中,节点代表网页,箭头表示各网页间的链接关系。图中V1存在一个指向U的箭头,意味着网页V1有一个前向链接是U,该算法认为网络中任意一个页面的PageRank值是其反向链接的所有页面贡献值的累加和。如图1所示,Vn有三个前向链接,则网页Vn对U的贡献值是Vn本身PR值的1/3。显然,V本身的值越高,对U的贡献值越大,并且U获得的PR值越高,同时,页面U反向链接的数量越多,U的PR值则越高。
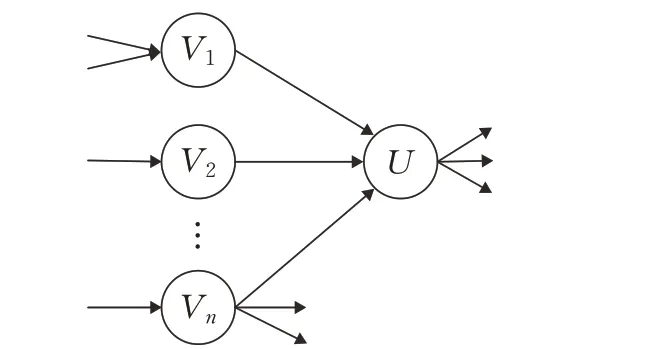
图1 PageRank原理图
2.2 Weighted PageRank算法
Weighted PageRank算法[3]是Xing等人通过对网页的链接结构进一步分析,综合考虑了网页的链入、链出结构,提出的一种加权PageRank算法(WPR算法),它是PageRank算法的一种扩展算法。传统的PageRank算法仅仅考虑了网页链接结构中的链出结构,而WPR算法不仅研究了网页的链出结构,也对网页的链入结构进行了分析。WPR算法改善了传统RageRank算法中的平分链接权重的不足,Xing等的研究表明,WPR算法较传统的RageRank算法排序结果较为理想,但WPR算法仍然仅考虑了网页的链接结构,与传统RageRank算法相比同样存在着主题漂移、偏重旧网页以及忽略用户兴趣的不足。
2.3 相关改进算法
针对PageRank算法出现的主题漂移问题,Tan[4]提出了一种基于向量空间的改进PageRank算法,此算法将矢量空间检索评估模型进行了融合,考虑到网页链接结构和主题内容的相关性,将主题内容的相似度与经典PageRank算法相结合,加权融合后得到新的PR值,但该算法未考虑到源网页与出链网页之间的权值分配问题。Yang等人[5]提出了一种基于时间反馈和主题相似度的改进PageRank算法,该算法通过添加页面更新率因子、主题相关因子和网页相似度对PageRank算法进行改进,但并未考虑用户兴趣对网页排序的重要性。文献[6]提出一种基于比率的加权PageRank算法,使用基于比率的方法在其引用的节点之间划分节点的PageRank值,使每个节点根据其自身权重获得相应权值,但算法未考虑没有出链的悬挂节点,显然是不合理的。文献[7]提出了一种基于资源分配(IPRA)的改进PageRank算法,该算法虽然在定向网络中识别了更具有影响力的网页,但也大大提高了计算复杂度。针对忽略用户兴趣问题,王旭阳等[8]提出了基于用户行为与页面分析的改进PageRank算法,该算法考虑了网页浏览者对页面的点击行为,缺点是未对用户的点击次数做有效性验证。文献[9]通过对不同用户的已发表文章和转载信息等内容的相似性分析获取用户的关系结构,但是因不同网页浏览者的页面传播速率不一样,对很少访问互联网的人群影响力权值分配为0是不合理的,其次,存在数据识别问题,其中由于用户信息被盗取而导致的错误信息被发布占据相当大的比重。文献[10]基于大量数据,该算法通过分析用户的历史行为给出相应的用户预测,从而获得用户关系结构,但在提高用户查询准确度的同时也增大了算法的时间复杂度。
2.4 学习自动机(LA)
自动机可以被看作是一个具有有限动作集的抽象模型。学习自动机[11-12]通过不断地与随机环境进行交互并获得经验来改善其行为,随机环境通过评估动作,给出自动机所选动作的概率。自动机使用来自环境的响应(即动作概率)来选择其下一个动作。通过继续此过程,在可选动作中选择该环境下的最佳动作。其工作原理如图2所示。

图2 学习自动机工作原理图
环境是一个三元组<α,β,c>,其中:α={α1,α2,…,αr}是学习自动机的r个动作集合;β={β1,β2,…,βm}代表环境的反应集;c={c1,c2,…,cr}是r个动作的惩罚概率,其中元素ci对应于动作集α中的动作αi。学习自动机的输出集α中的αn在t=n时刻应用于环境。
可变结构学习自动机[13]可由一组四元组<β,α,T,P>表示,其中α={α1,α2,…,αr}代表一组待选动作;β={0,1}表示环境的反馈;其中0表示奖励,1表示惩罚;T是学习自动机的更新规则;p(n+1)=T[α(n),β(n),p(n)]是学习算法。参数p是与α一一对应的一组概率值,p={p1(n),p2(n),…,pr(n)}是动作概率向量,其中pi(n)代表在时刻n选择动作αi的概率。在自动机中,如果在第n阶段选择动作αi并从环境中收到理想响应,则pi(n)的概率增加,其他概率减小,反之pi(n)减少,其他概率增加。以下学习算法是更新动作概率的方案,定义如下。
理想响应:

非理想响应:

分布式学习自动机[14](Distributed Learning Automata,DLA)是由一组相互协作的学习自动机构成的网络,它们共同合作解决特定问题。在DLA中,任何LA的动作数量等于该LA所连接的LA数目(出边数量)。当自动机选择其中一个动作时,将激活与此动作相对应的自动机。任何时候网络中只有一台自动机将会被激活。形式上,具有n个学习自动机的DLA可以被描述为图(V,E)。其中,V={LA1,LA2,…,LAn}是n个学习自动机的集合,E是图中边的集合,边(LAi,LAj)对应于自动机LAi的动作αj即LAj经LAi选择动作αj后被激活。
3改进的PageRank算法:LUPR
算法包括两个步骤,第一步计算基于学习自动机的网页之间每个超链接的权重,使用已存储在日志文件中每个用户导航路径来计算网页之间超链接的权重;第二步计算网页兴趣度因子,使用网页浏览者搜索网页的等待时长以及浏览时长,网页的浏览时间越长,在某种程度上可以代表网页浏览者对此页面越感兴趣。
将wi→j定义为页面i和j之间的超链接权重,这个权重由学习自动机确定,将TD(k)定义为兴趣度因子,该因子基于浏览网络的用户行为确定用户的兴趣度。将DLA视为N×N的矩阵,其中每一行表示一个网页(引入自动机i),每列j表示自动机i的第j个动作。矩阵M的每个元素mij的值是(1/N),当用户进入系统并浏览网页Pi时,该页面的学习自动机(即LAi)被激活。当用户从页面Pi移动到Pj时,LAi自动机中的动作被选择。根据马尔科夫理论的特点和PageRank计算,所提算法公式如下所示:
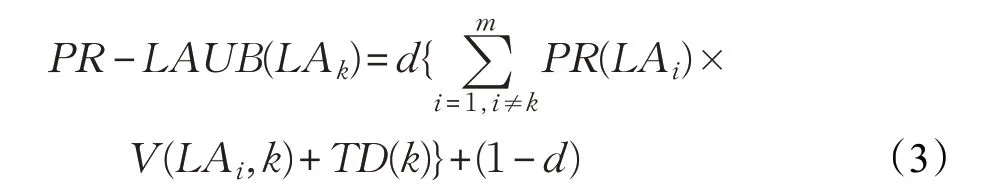
其中,LAk是页面k的学习自动机,V(LAi,k)是LAi自动机中动作概率k的值,这个概率值显示了网页之间超链接的权重,TD(k)代表兴趣度因子,参数m是网页数量,d是阻尼系数,一般取值0.85[15]。
3.1 基于学习自动机确定网页间的超链接权重
网页和用户扮演DLA中现有学习自动机的随机环境的角色。在网络中每个网页Pi,即对应一个学习自动机LAi。如果网络中有m个网页,那么自动机就有m-1个动作。当用户从页面Pi移动到页面Pj时,激活DLA中LAi自动机的第j个动作,并根据学习算法更新LAi自动机的动作概率向量。这个动作概率向量显示了网页i和网页j之间的超链接的权重。设pkm(n)为在时刻n时学习自动机LAk选择动作αm的概率。如果用户从页面Dk移动到页面Dm(Dk→Dm),则学习自动机LAk根据学习算法更新其动作概率向量。例如,如果学习自动机LA1中的动作向量和其动作概率向量分别为(A2,A3,A4),(0.2,0.5,0.3)用户从D1移动到D2,则:
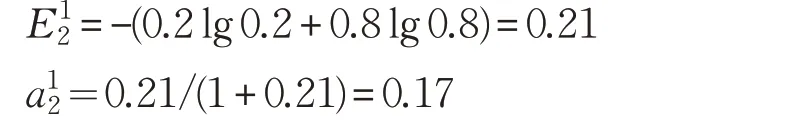
那么LA1的动作概率向量则更新为(0.35,0.42,0.23)算法描述如下:
(1)根据网页结构创建一个分布式学习自动机DLA。
(2)对每个学习自动机,初始化动作概率向量。
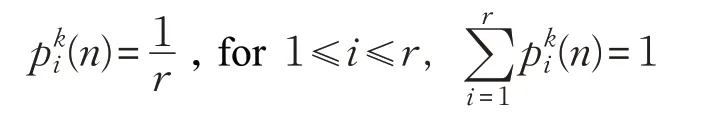
(3)对用户日志文件中每个用户访问路径,如果用户从Dk移动到Dm则根据如下学习算法更新LAk自动机的动作概率向量。
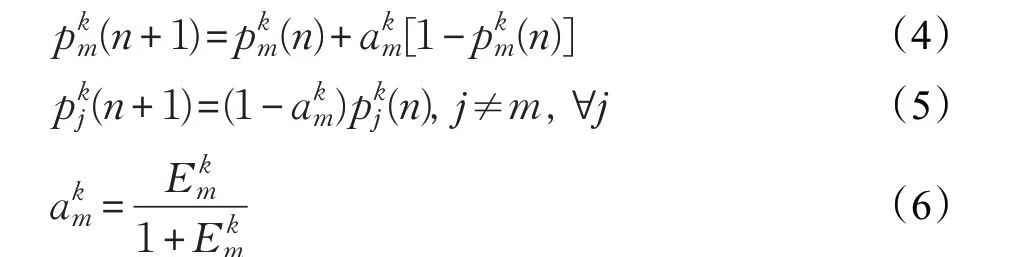

3.2 兴趣度因子
兴趣度因子主要是通过分析网页冲浪者的搜索行为,获取用户搜索页面时的行为信息。在关键词Key下,对用户访问过的网页集合中的每个网页,系统需要采集的用户数据包括:(1)等待行为:用户获取页面全部内容所需要等待的时间ts;(2)浏览行为:网页处于激活状态时普通人正常阅读网页的整个内容继而进行评论和思考的时间。
用户在页面上花费的时长需要考虑网页内容和篇幅因素的影响,如果页面浏览者对该网页感兴趣,则需要花费更多的时间来浏览页面,停留时间的长短与页面的文字、图片及视频的数量以及浏览者是否对该页面感兴趣等因素密切相关。当用户搜索到相关网页时,获取全部网页内容需等待的时间为ts,经统计显示,当网络通畅时,ts≤3 s,设置阈值平均时间ts=5 s,当用户的等待时间超过5 s时,用户对页面内容的兴趣度将减少,则可能在该网页上的停留时间会相应缩短。
设正常人阅读完整个页面的内容并进行思考和评论的时间为tc,其中tc的计算公式如下:

其中,Cw、Cp和Cv分别代表页面正文文本量、页面中图片个数以及页面视频的个数。为了便于计算,这里将图片与视频依据其含义转化为描述的文字量,分别近似于50和100个字,正常人一般阅读速度为280字数/min,k是评论系数,取值为1.2~1.5。兴趣度因子的计算如下:

其中,tr是用户访问当前网页的实际浏览时间;tr/tc是网页浏览者的基本兴趣度;(ts-5)×0.1为基本兴趣度的偏移量。通过分析用户的搜索行为,获得用户浏览页面的行为信息,增加兴趣度因子。
4 实验仿真
4.1 主要实验步骤
本文使用Java作为前端开发,编译环境使用MyEclipse、Lucene 3.0jar包和Heritrix等,对LUPR算法进行实验仿真,步骤如下:
(1)用户数据收集。使用Heritrix网页爬虫工具从“巨细热点网站”抓取5 000个IP用户近一个月的访问信息。
(2)网页数据收集。根据抓取的网页数据,生成网页链接结构图,获取链接关系,将其作为记录存入数据库中。
(3)搭建MyEclipse实验平台,在实验项目中添加Lucene 3.0jar包,添加中文分词器IKAnalyzer3.2.8.jar包,配置相关停用词,放在项目的根目录中。
(4)在既定环境中,使用Java语言分别实现传统的PageRank算法,WPR算法和本文提出的LUPR算法,LUPR算法在本实验中,k取1.35。
(5)比较并分析查询得到的页面。
4.2 实验结果
为了对比算法的优越性,将用三种不同的查询算法对同一查询关键词进行实验分析,为了突出LUPR算法的优越性,以下是可以显著突出用户查询需求的关键字:“转基因”。为了节省文章篇幅下面给出了查询结果排名前十的排序结果。查询结果如图3~5所示。

图3 PageRank基于“转基因”关键词查询结果
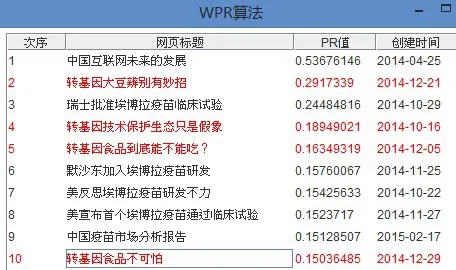
图4 WPR基于“转基因”关键词查询结果

图5 LUPR基于“转基因”关键词查询结果
其中,图3是完全基于链接关系的传统PageRank算法基于“转基因”关键词的页面排序结果,而图4是改进了权值均等分配缺点的WPR算法基于“转基因”关键词的网页排序结果,可以看到WPR算法对于权威度高的网页并没有做出很大的调整,依然排在页面很靠前的位置。图5是本文的LUPR算法,可以看出与主题无关的网页数量大大减少,完全与主题无关的网页已经退出了前十的位置;另外,排名前十的网页中出现了9条和用户查询相关的网页,PR值很高但是用户兴趣度不高的网页得到了下降,例如:网页标题为“瑞士批准埃博拉疫苗临床实验”的网页排名位置由PageRank算法的第1位下降到了第3位,而用户兴趣度高的网页得到了提升,例如:图5中的网页标题为“中国限制转基因食品‘另有隐情’的用户兴趣度高的网页(兴趣指数TD(k)=1.100 034 5)已经较PageRank算法的排名第24位(如图6),WPR算法的第22位(如图7),均有较大的提高。

图6 PageRank排名第24位的网页

图7 WPR排名第22位的网页
通过查准率说明本文LUPR算法的排序质量。本文研究的查准率是指通过小规模的仿真实验获得的统计结果,其含义是,在采样的样本数量中用户对查询结果满意的样本数量占总样本数量的百分比,是根据网页浏览者的主观判断,确定查询结果与浏览者需求相关度的一个衡量标准。其中对用户评价分为四个不同级别:不满意、较满意、满意、非常满意,对结果为满意、较满意和非常满意的页面,就标记该页面为和用户查询主题相关的页面。查准率的计算公式如式(10)所示:

本实验为测试查询结果中的前30个页面,随机选取1 217名学生进行测试查询信息,对5个查询关键词分别为“转基因”、“苹果手机”、“中国制造”、“食品安全”、“流行病”的查询结果进行测评,测试结果如图8所示。

图8 三种算法查准率对比图
通过选取更多的查询关键词,进一步说明本文LUPR算法的排序质量。选取当前社会热点、网络热词等与当今社会息息相关的50个关键词进行测评,首先统计单个关键词的查准率,然后以5、10、20、30、50为单位逐步扩大关键词的个数,求取三种算法的平均查准率,目的是为了消除个别关键词的差异性,更好说明LUPR算法的排序质量,测试结果如图9所示。

图9 三种算法平均查准率对比图
用户满意度评估[16]:评估公式如公式(11)所示:

查询结果分为四个不同级别:非常满意、满意、较满意和不满意。Si是满意度系数,不同级别的满意度系数分别是:1.0,0.6,0.2,0.0。其中n是页面总数,在此实验中n是不同排序算法结果中的前30个页面,i是计数器。通过用户满意度评估公式与算法测试结果,结果比较如图10、11所示,可以看出改进的LUPR算法在用户满意度上远远高于其他三种算法。

图11 三种算法的用户满意度对比图
仿真实验证明,LUPR算法在一定程度上可以提高网页排序质量、信息查询的精准度和用户检索的满意度。
5 结束语
本文提出了一种基于学习自动机和用户兴趣的页面排序算法LUPR,该算法根据学习自动机确定页面间的超链接权重,以缓解PageRank算法平分链接权重问题;考虑到网页排序的结果不能仅仅依靠网页的自身因素(网页的权威性、重要性等),还应该充分权衡网页用户的兴趣度,通过对网页浏览者行为的分析和提取,以浏览者的浏览行为衡量浏览者对页面的兴趣度,获得兴趣度因子。仿真实验表明,该算法在一定程度上提升了信息检索的精准度和用户满意度。下一步工作是考虑尝试在学习自动机中使用网页相似度和用户停留时间作为奖励进行网页排序,或使用可变动作的学习自动机对所提算法进行改进,这对于动态网页中页面或链接的动态变化将非常有用。
猜你喜欢
计算机工程与科学(2022年2期)2022-03-22
现代电子技术(2021年16期)2021-08-16
数学物理学报(2021年3期)2021-07-19
成都信息工程大学学报(2021年6期)2021-02-12
魅力中国(2020年19期)2020-12-08
河北农机(2020年7期)2020-01-08
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
