
深度学习在故障诊断与预测中的应用
2020-02-19 14:07余萍,曹洁
计算机工程与应用 2020年3期
余 萍,曹 洁
1.兰州理工大学 电气工程与信息工程学院,兰州730050
2.兰州理工大学 甘肃省工业过程先进控制重点实验室,兰州730050
3.兰州理工大学 电气与控制工程国家实验教学示范中心,兰州730050
1 引言
深度学习(Deep Learning,DL)是一种源于人工神经网络的机器学习方法,其本质是通过在层次结构中堆叠多层非线性信息处理模块来模拟数据背后的高级表示,并对模式进行分类和预测。结合特定的领域任务,深度学习可以自动完成对数据的学习,提取出不同水平和维度的有效特征表示,有更高的数据解释能力。早在20世纪80年代,多层神经网络的理论就已经被提出[1],典型算法是采用了随机设定初始值及梯度下降优化策略的BP(Back-Propagation)神经网络[2-3]。然而过拟合、梯度消失及计算能力受限等问题制约了神经网络的发展。直到2006年,Hinton团队提出一种无监督深层神经网络的有效训练算法,即深度置信网络(Deep Belief Networks,DBN)[4-5],它成功地训练了具有多层网络结构的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),在没有任何监督的情况下呈现了数据的统计特性。这一技术的出现打破了神经网络发展的瓶颈,同时,伴随着处理器计算能力的提升,引发了深度学习的热潮。近年来,涌现出许多新的模型训练方法,并被用来有效解决越来越多极具挑战性的问题,在图像处理[6-7]、医学图像分析[8-9]、语音识别[10]、目标检测[11-12]、文本检测和识别[13-14]以及自然语言处理[15-16]等诸多领域均获得了突破性进展。
表1列举了近五年来一些重要的深度学习研究综述和专著,这些文献详细地反映了深度学习取得的阶段性进展或在某一领域的应用概况。表2列举了目前主流的几款深度学习开源仿真工具平台,旨在为研究者提供参考。值得注意的是深度学习在故障诊断与预测中的应用仍属于新兴领域,因此,本文特别强调以下两个方面:(1)围绕故障诊断与预测这一研究主题,梳理了五种典型深度学习模型的结构、原理及区别;(2)整理了深度学习在故障诊断与预测领域的最新研究进展,对存在的问题、面临的挑战进行了分析,并就解决的办法以及今后的发展趋势和研究方向进行了展望。

表1 近五年发表的深度学习相关应用研究综述和专著

表2 深度学习主流开源仿真工具
2 深度学习模型
2.1 AE及其变体
自动编码器(AE)是一种典型的前馈无监督神经网络[71],其结构如图1所示:包括编码器和解码器两个部分。
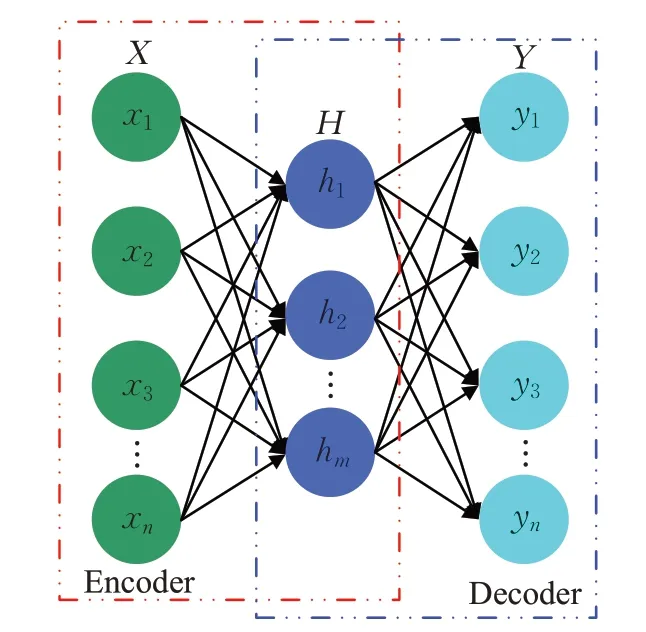
图1 单隐含层自动编码器结构
编码器接受输入x并将其映射到隐层h,其非线性映射关系如下:

式中,φf为非线性编码激活函数,b为编码器偏差向量,ω为输入层与隐层间的连接权值矩阵。隐层H可以看作是数据样本X的一种更抽象、更有意义的表示。然后,解码器再以相似的方式将隐层表示映射回原始表示:

式中,φg为解码激活函数,ω′为解码器偏差向量,b′为隐层与输出层间的连接权值矩阵。
定义θ为模型参数集合:

为了使得输出y与输入x的重构误差最小,要对参数θ进行优化,相应的优化问题表示如下:
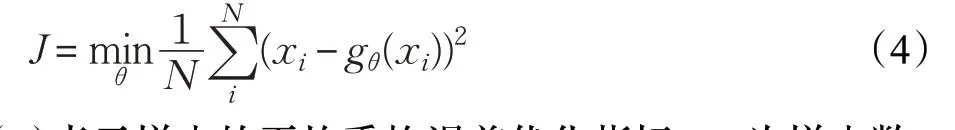
式(4)表示样本的平均重构误差优化指标,N为样本数。
为了使隐含层的输出更具鲁棒性,三种典型的改进包括:稀疏自动编码器(Sparse Auto-Encoder,SAE)、去噪自动编码器(Denoising Auto-Encoder,DAE)和堆叠去噪自动编码器(Stacked Denoising Auto-Encoder,SDAE)。
2.1.1 SAE
为防止样本性质的波动,在隐层单元上增加稀疏性约束[72],使得学习到的隐层表示成为稀疏表示,相应的优化功能更新为:

式中,m是隐含层的层数,第二项是隐层单元上的Kullback-Leibler(KL)散度总和。其中:

式中,p是预先定义的平均激活目标,pj是整个数据集中第j个隐藏神经元的平均激活度。
2.1.2 DAE
DAE的思想是将含有噪声的数据样本作为输入送入编码器进行编码,再通过解码器从含噪的样本中去重建去噪后的输入。最常用的噪声是dropout噪声,它随机地将输入特征的一部分设置为零[73]。增加了去噪功能的DAE增强了噪声干扰情况下的网络鲁棒性。
2.1.3 SDAE
SDAE的思想是通过将第j层的输出作为第j+1层的输入,这样可以将多个DAE堆叠在一起,逐层完成贪婪训练,从而形成更深层的网络来学习高级表示[74]。SDAE依然采用梯度下降算法来训练网络参数。经过SDAE的分层预训练后,可以将自动编码器的参数设置为DNN所有隐藏层的初始值,然后执行受监督的微调以最小化预测错误。在网络输出端通常添加一个SoftMax回归层,以将最后一层输出映射到目标。研究表明,基于SDAE的预训练DNN模型,相比随机初始化条件下的DNN具有更强的收敛能力[75]。
2.2 DBN
深度置信网络(DBN)是由叠加多个受限玻尔兹曼机(RBM)来构建的。RBM是具有一个显层和一个隐层的双层神经网络,如图2(a)所示,显层(v)与隐层(h)之间存在对称连接约束,但层内节点之间无任何连接。RBM可以从训练数据分布中得到潜在的特征表示,因此它是一个生成模型[76]。

图2 受限玻尔兹曼机(RBM)与深度置信网络(DBN)
给定模型参数θ=[ω,a,b]时,能量函数可定义为:

式(7)中,ωij表示显层和隐层间的连接权值;ai表示可视层偏置值;bj表示隐层偏置值。根据能量函数E计算所有单元的联合分布:


RBM采用了无监督的对比散度算法(Contrastive Divergence,CD)进行网络训练,训练目标是使联合概率最大化。
叠加多个RBM就构成了DBN,它具有学习训练数据深层表示的能力,其中第i层(隐层)的输出作为第i+1层(显层)的输入,结构如图2(b)所示。与SDAE类似,DBN也是通过无监督的逐层贪婪学习算法进行网络训练,学习过程包含预训练和微调两个步骤。
2.3 CNN
卷积神经网络(CNN)是一种典型的监督型前馈神经网络,它的训练目标是通过交替和叠加卷积核以及池化操作来实现对抽象特征的学习。结构上主要包含三部分:卷积层(Convolution layer)、池化层(Pooling layer)和全连接层(Fully Connected layer,FC layer),如图3所示。
卷积层采用多个卷积核来实现对多特征的提取,每一层的输出都是对多输入特征进行卷积,数学模型如下:

池化层的作用是通过池化操作将特征空间的尺寸减半,从而在保证特征不变性的情况下,降低特征维度。常见的池化操作有最大值池化(Max-pooling)和均值池化(Mean-pooling)。
最后,输入数据在经过多次卷积和池化后,传递到一个或多个完全连接(FC)层,其结果将作为顶层分类器(例如,SoftMax)的输入。
CNN的训练方式包括前向传播和反向传播。首先,输入信号经过多次卷积、池化、全连接运算得到实际输出信号,并计算实际输出和理想输出的差;然后利用BP算法反向逐层传递误差;最后利用梯度下降法更新各层参数[77]。
近年来CNN的主要改进技术体现在两方面:(1)采用ReLU、GeLU等改进的非线性激活函数[78],加速了网络的收敛速度,更适应深层网络的训练;(2)采用了深层网络的正则化方法[79],很大程度地防止了训练过程中的过拟合现象。
2.4 RNN
循环神经网络(RNN)是一个处理顺序数据的框架,通过每层之间节点的连接结构来记忆之前的信息,并利用这些信息来影响后面节点的输出。RNN可充分挖掘序列数据中的时序信息以及语义信息,这种方式在处理时序数据时比全连接神经网络和CNN更具有深度表达能力。如图4所示,多层感知器只能从输入数据映射到目标向量,而RNN能够从以前输入的整个历史映射到目标向量,从而利用过去的信息克服简单神经网络的局限性。RNN以后向传播的方式通过时间对受监控的任务进行训练。
RNN可以使用其内部存储器来处理顺序数据,t时刻的隐层神经元状态ht由该时刻的输入xt和前一时刻的隐层神经元状态ht-1确定。在典型的vanilla RNN中:

图3 基于CNN的故障诊断流程

图4 多层感知器与典型RNN

式中,φ为非线性可微转移函数,采用不同的转移函数可以形成不同的RNN模型;ω为隐层与输入层的连接权值,u为隐层神经元之间的连接权值,b为偏置值。
对于分类任务,通常加全连接层和softmax分类层,将序列映射到特定类别标签[80]。
2.5 GAN
Goodfellow等人2014年提出了生成对抗网络(Generative Adversarial Network,GAN)[81]。尽管出现的时间较短,但以其独特的特点迅速成为了机器学习领域最令人兴奋的突破之一。GAN结构如图5所示,生成器(FG)和鉴别器(FD)巧妙地展开相互竞争,生成器试图混淆鉴别器,而鉴别器则试图区分输入数据集中的生成器生成的样本和原始的实际样本,由此建立了一个零和博弈的框架。在这个框架中,生成器和鉴别器不断竞争,各自获得更强的模拟原始数据样本和迭代识别的能力[82]。

图5 GAN结构示意图
3 深度学习在故障诊断与预测中的应用
3.1 研究背景
系统的异常检测和故障诊断一直是学术界关注的重点问题,而随着工业设备日趋复杂化、大型化和智能化,高效获取准确、完备的诊断信息越来越困难。传统的诊断技术已很难满足现代工业的故障诊断需求,迫切需要能够将故障机理、模型建立、特征提取与分类方法等相关问题相融合的混合智能故障诊断技术,而深度学习的出现为这一技术的实现提供了新的思路和途径。下面从三个方面分析未来工业的故障诊断与预测为什么需要深度学习。
(1)故障复杂性
复杂工业系统从结构上来说具有多层次、互相关和复杂性等特点,这就导致了系统的故障具有了传播性、耦合性、继发性和不确定性的特点。举例说明,一个微小故障的存在可能引发大型故障的出现,或随着系统结构层次进行故障传播从而引发一系列故障,继发多故障的耦合,最终对设备构成致命性毁坏。在这一过程中仅故障种类就包含了早期微小故障、复合故障、系统故障等。微小故障具有潜在性和动态响应微弱的特点;复合故障和系统故障由于多因素耦合和传递路径复杂,导致难以有效溯源故障成因。这些都为故障诊断带来了难度,传统基于数据的故障诊断技术中人工设计并提取故障特征的方法已远远不能满足实际需要,而能够进行数据深层挖掘、自动提取故障特征、具有端对端操作特点的深度学习技术必将成为整个故障诊断体系中的关键性技术。
(2)环境复杂性
系统未知的干扰和噪声会对故障信号产生很大的影响,例如微小故障信号的幅值较低,很容易被未知扰动和噪声信号所掩盖,尤其是当噪声和微小故障信号发生混叠时,就很难对其进行区别。而深度学习方法中已有很多优秀的改进模型用来帮助解决此类问题,如堆叠去噪自动编码器(SDAE)、自带去噪功能的CNN等。此外,由于数据采集、传输、存储过程中受环境影响所导致的异常以及传感器自身漂移等因素,都将使得系统的故障和征兆具有随机性、模糊性和信息不确定性等特点,这些都需要进行深度的数据挖掘来实现故障的有效识别。
(3)数据复杂性
随着信息化技术的发展,未来复杂工业系统将不仅能获得到时间与空间两个维度上不同尺度的海量数据,还能获取到不同来源、不同工况、不同部门、不同类型的海量数据,这就为数据的处理带来了巨大难度。如何实现对海量故障数据的快速分析和深度挖掘是大数据时代的挑战性难点,而深度学习方法必将是攻克这一难题的有力武器。
3.2 发展趋势
如图6所示,随着深度学习技术的不断发展,在故障诊断领域中,数据处理的方法已由单一算法逐渐演变到混合模型算法,例如深层/浅层网络的相互合作等;应用范围也越来越广,从最初的机械设备到风力发电设备,再到航空航天设备等,普遍性和实用性获得了极大的提升;技术侧重点也从故障诊断到退化状态研究,再到故障预测。由此可见,深度学习在这一领域的发展是值得期待的。

图6 基于深度学习的故障诊断与预测研究概览
3.3 深度学习用于故障诊断的一般流程
基于深度学习的故障诊断基本框架如图7所示,包括定义状态阶段、数据预处理阶段、训练阶段、测试阶段及诊断结果评估阶段等五个步骤。

图7 基于深度学习的故障诊断基本框架
易见,基于深度学习的故障诊断方法的特点在于:(1)与“浅”层网络不同,深度学习没有人工设计故障特征环节,将故障特征选择提取和分类模型训练合为一体;(2)深度学习是多隐层网络,能够避免维度灾难和“浅”层网络诊断能力不足的局限性。
3.4 数据来源
数据是所有机器学习和人工智能方法的基础。为了进行有效的故障检测,使得研究方法的验证结果更有说服力,必须对数据集的可靠性、实用性和通用性做很好的评估。但实际采集数据耗时严重,例如轴承劣化过程可能需要很多年的时间,因此大多数研究人员都采用人工注入故障的方法来收集数据。因此,除了规范的实际实验数据以外,目前几种典型的可用于测试、评估和比较不同的算法的通用故障数据集如表3所示。从现有文献来看,CWRU数据集[83]用于轴承故障识别的应用研究最多,有利于研究结果的对比。而更多的数据集的出现,也为深度学习故障诊断与预测提供了更丰富的选择。
3.5 深度学习方法在故障诊断与预测中的应用
3.5.1 基于AE的故障诊断方法
在故障诊断中使用自动编码器的研究报道较多。文献[93]使用了深度为5的AE网络实现了自适应提取故障特征及有效分类的轴承故障诊断,分类精度达到99.6%,明显高于70%的反向传播神经网络。为减少噪声对故障特征的干扰,文献[94]以多级齿轮传动系统为研究对象,在多工况条件下基于去噪自编码器(DAE)对多种故障进行了诊断,实验结果表明,其诊断准确率明显高于单隐含层BPNN、多隐含层BPNN及基于常用特征的SVM分类。在文献[95]中,实现了一种由三个堆叠的自编码器组成的堆叠去噪自动编码器(SDAE),实验中原始的CWRU轴承数据受到15 db随机噪声的干扰,用以实现噪声条件的模拟,并以多工况数据集作为测试集,检验其在转速和负载变化下的故障识别能力。实验表明,该方法达到了最低91.79%的诊断准确率,比传统的SAE高3%~10%。在文献[96]中使用了另一种形式的SDAE,CWRU数据集的信号与时间域中不同级别的人工随机噪声相结合,然后转换为频率信号。该方法比DBN网络具有更高的诊断精度,特别是在附加噪声的情况下,故障诊断精度提高了7%。文献[97]有效集成了DAE和Elastic Net(EN)来解决故障诊断中的噪声干扰问题,实验结果表明,该方法能有效地检测工业过程中的异常样本,并能准确地将故障变量与正常变量隔离开来。为应对处理较大数据集的需要,文献[98]提出一种引入了dropout技术和ReLU激活功能的堆叠式自动编码器(SAEs)来解决齿轮箱故障诊断问题,在自动提取显著故障特征的同时,减少了训练过程中的过拟合问题,提高小训练集的训练性能。实验结果表明,该方法优于原编码器及其他一些传统方法。文献[99]构建了一种4层的堆叠稀疏自动编码器(SSAE),该方法对振动数据进行非线性投影压缩,压缩比为70%,并在变换域内进行自适应特征提取,分类精度高达97.47%,比SVM高8%,比传统单隐层人工神经网络高60%,比多隐层人工神经网络高46%。

表3 若干典型的故障诊断测试数据集
此外,研究者也开展了着重于混合式设计以改进诊断性能研究和早期微小故障的研究。如文献[100]设计了一种由一系列不同激活功能的自动编码器(AE)集成的深度自动编码器(Ensemble Deep Auto-Encoders,EDAE),然后按照一种组合策略来确保诊断结果的准确性和稳定性。实验结果表明该方法的分类精度为99.15%,与BPNN(88.22%)、SVM(90.81%)和RF(92.07%)相比,性能显著提升。文献[101]采用了一种基于自动编码器的极限学习机(Extreme Learning Machine,ELM),综合了自动编码器的自动特征提取能力和ELM的高训练速度优点。与小波包分解支持向量机(WPD-SVM)(94.17%)、经验模态分解支持向量机(EMD-SVM)(82.83%)、WPD-ELM(86.75%)和EMDELM(81.55%)相比,平均准确率为99.83%。更重要的是,由于采用了ELM,使用相同的训练和测试数据,所需的培训时间减少了60%到70%。文献[102]构造了一种深耦合自动编码器(DCAE)模型,将捕获到的不同多模数据之间的关键信息无缝集成到数据中加以融合,即从多模数据中获取联合信息进行故障诊断,实验结果表明,该模型能够进行准确的故障诊断,具有更好的性能。文献[103]提出一种新的轴承智能诊断方法,通过创建新子集的方法从不同的故障模式中学习并识别特征,在此基础上提出了一种具有自适应微调功能的基于子集的深度自动编码器(Subset Based Deep Auto-Encoder,SBDA)模型来实现特征的自动提取。该方法以三个公共轴承数据集为对象进行了实验验证,平均测试精度分别为99.65%、99.66%和99.60%。与13种智能诊断方法的比较表明,SBDA能获得更高的诊断精度。文献[104]提出了一种由自动编码器和SoftMax分类器构成深度学习网络(Deep Learning Network,DLN),用于识别不同程度的轴承故障。首先,通过集成经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)方法形成高维特征向量作为DLN的输入;然后,在DLN中完成学习和参数微调用以减小分类误差。实验结果表明,该方法对轴承故障诊断具有较好的效果,也为更复杂的数据分类提供了有力的理论与实验研究基础。文献[105]提出了一种基于深度自动编码器的无监督电机故障诊断方法。该方法利用加速度计获取振动信号,仅通过正常数据进行网络训练。实验以接收机工作特性曲线的曲线下面积(Area Under Curve,AUC)对诊断性能进行了评价,结果表明多层感知器(MLP)自动编码器、卷积神经网络自动编码器和由长短期记忆(Long Short-Term Memory,LSTM)单元组成的循环式自动编码器都优于OCSVM(One-Class Support Vector Machine)算法。这其中,MLP自动编码器是性能最高的体系结构,实现了99.11%的AUC。文献[106]基于叠层稀疏自动编码器,实现了一种能够提高分类和预测精度的实时在线处理方案,对传统统计技术检测不到的早期故障具有较高的检测效率。
3.5.2 基于DBN的故障诊断方法
作为最早出现的深度学习模型,早在2013年就有报道基于DBN的故障诊断研究结果。文献[107]提出基于DBN的多传感器健康诊断可分为三个阶段:第一阶段,定义用于DBN训练和测试的数据集;第二阶段,开发基于预定义好的健康状态的DBN分类诊断模型;第三阶段,验证DBN分类模型。并与现有的SVM等四种诊断技术进行了比较,证明了该方法的有效性。
近年来,DBN更多的是与其他技术相结合来解决故障诊断问题。文献[108]实现了一种多传感器振动数据融合技术,融合了通过多个二层SAE提取的时域和频域特征;然后利用基于三层RBM的DBN进行分类。结果表明,即使在运行工况发生变化后,也能有效地识别轴承故障,该方法的诊断精度达97.82%。文献[109]提出了一种基于DBN的变压器故障诊断方法,通过分析变压器油中溶解气体与故障类型的关系,确定气体的非编码比作为DBN模型的特征参数,并采用多层和多维映射的方法提取断层类型的更详细差异,在此基础上构建并测试了DBN诊断模型。通过不同的特征参数、不同的训练数据集和样本数据集,分析了DBN诊断模型的性能,实验结果表明,该方法大大提高了电力变压器故障诊断的准确性。文献[110]针对轴承故障分类问题,提出了一种自适应DBN和双树复小波包(Dual-Tree Complex Wavelet Packet,DTCWPT)相结合的诊断方法。首先利用DTCWPT对振动信号进行预处理,在振动信号中生成具有9×8特征参数的原始特征集,然后利用5层自适应DBN(“72-400-250-100-16”结构)进行故障分类。实验表明该方法的平均准确率为94.38%,远高于ANN(63.13%)、GRNN(69.38%)和SVM(66.88%)的诊断精度。文献[111]提出了一种改进的压缩传感卷积DBN网络(Convolutional Deep Belief Network,CDBN),用于滚动轴承的故障特征学习和故障诊断。在采用CS(Compressed Sensing)降低振动数据量的基础上,构造了一个新的CDBN模型并采用指数移动平均(Exponential Moving Average,EMA)技术,提高了网络的泛化性能。实验结果表明,相对于传统方法,该方法更有效。类似的,在文献[112]中,采用卷积RBMs构造卷积DBN,首先,将自动编码器压缩降维后的数据送入基于高斯可见单元的卷积DBN学习故障特征,然后利用SoftMax层进行分类,得到了97.44%的准确率,与同条件下的AE(90.76%)、DBN(88.10%)和CNN(91.24%)相比,具有更好的分类精度。在文献[113]中,由多个DBN进行特征提取,然后根据提取的特征确定故障条件,在负载变化情况下进行诊断,并最终通过DS(Dempster-Shafer)证据理论融合诊断结果,诊断准确率达98.8%。为进一步克服缺陷、提高网络性能,文献[114]针对不平衡数据的分类问题,提出了一种进化的成本敏感DBN网络(Evolutionary Cost-Sensitive Deep Belief Network,ECS-DBN)。ECS-DBN采用自适应差分进化算法,将错误分类成本进行优化后,应用于DBN网络中。实验结果表明,该方法在故障诊断基准数据集和现实数据集上均有很好的诊断能力。文献[115]提出了一种结合奈斯特罗夫动量的自适应学习速率DBN网络,分别在齿轮箱和机车轴承试验台的数据集上进行实验验证,结果表明,该方法的故障识别率得到显著提升,证明了该方法的准确性和鲁棒性。文献[116]提出了一种基于DBN和传递学习策略的高压断路器机械故障诊断方法。首先,利用DBN实现了对样本数据故障特征的深度挖掘和自适应提取,并结合传递学习方法,通过调整训练样本的权重来实现数据学习的目标。结果表明,该方法可获得更强的泛化能力。
3.5.3 基于CNN的故障诊断方法
自2016年CNN被用于识别轴承故障以来,出现了很多基于这一主题的文献报道,从数据源处理、抗噪、提速、结构改进、灵敏性等多方面、多角度不断提升CNN的故障诊断性能和适用范围。文献[117]采用了一种传感器融合方法,将从驱动端和风扇端两个加速度传感器采集的CWRU原始数据进行时空信息叠加,从而将一维时间序列数据转换为二维输入矩阵。样本的70%用于训练、15%用于验证、15%用于测试;实验结果表明,基于两个传感器数据的平均诊断精度为99.41%,高于只有一个传感器时98.35%的平均诊断精度。文献[118]中使用的自适应交叠CNN(Adaptive Overlapping Convolutional Neural Network,AOCNN),能够直接处理一维原始振动信号,并消除嵌入在时域信号中的移位变量问题。该方法在自适应卷积层将样本分割成若干段后,采用稀疏滤波(Sparse Filtering,SF)的方法获取局部特征。分类结果表明,采用SF的AOCNN能诊断出轴承的10种健康状况,检测准确率达99.19%。针对实际轴承损伤数据很难甚至不可能收集到,转而使用人工轴承损伤数据从而产生的应用差异问题,文献[119]使用了德国Paderborn大学轴承数据集,此数据集包括人为诱发故障和机器老化导致的实际自然故障。该文献提出了一种新的基于空洞卷积的深度初始网络模型(Deep Inception Net with Atrous Convolution,ACDIN),当仅使用人工轴承损坏产生的数据进行训练时,ACDIN将实际轴承故障的诊断精确度从75%(传统数据驱动方法的最佳结果)提高到95%。此外,文中还利用特征可视化方法分析了该模型高性能背后的机理。文献[120]提出了一种基于故障位置和损伤程度不同而对原始振动信号进行智能分类的故障诊断方法。通过将数据集转换成光谱图的方式,最大程度地保留时域信号的原始信息,然后利用深度全卷积神经网络进行训练。实验结果表明,此方法收敛速度快,精度高达100%,具有更好的泛化能力。针对含噪信号所导致的诊断精度不高的问题,文献[121]实现了具有2个卷积层和2个汇集层的4层CNN结构,其精度优于传统的SVM和浅层SoftMax回归分类器,特别是当振动信号与环境噪声混合时,这种改进可以提升25%的诊断准确率,体现了CNN算法出色的去噪能力。文献[122]提出了一种基于CNN的滚动轴承故障诊断新方法,通过将一维振动信号转换成二维图像,并利用CNN对图像分类的有效性,可使CWRU轴承数据集达到100%的诊断精度。此外,当负载条件发生变化时,在不重新训练分类器的情况下,该方法仍能以较高的精度获得满意的性能,具有较强的鲁棒性和抗噪声能力。为了节省CNN算法训练时间,在文献[123]中采用了多尺度深度CNN(Multi-Scale Deep Convolutional Neural Network,MS-DCNN),使用不同尺度的卷积核并行提取不同尺度的特征。实验对比9层一维CNN、二维CNN和提出的MS-DCNN的平均精度分别为98.57%、98.25%和99.27%。此外,MS-DCNN需要确定的网络参数数量仅为52 172个,远远低于一维CNN(171 606个)和二维CNN(213 206个)。文献[124]构建了一个新的深度学习框架,并利用迁移学习来实现高精度的机器故障诊断,实验结果表明该算法训练速度快、精度高。文献[125]在传统CNN结构的基础上,加入一个错位层,可以更好地提取不同信号之间的关系,最终实验中获得了96.32%的诊断准确率,相比传统CNN83.39%的诊断准确率,性能得到了很大的提升。文献[126]提出了一种新的基于LeNet-5的CNN故障诊断方法。将信号转换成二维图像作为网络的输入,并利用电机轴承、自吸离心泵、轴向柱塞液压泵这三个基准数据集进行了测试,预测精度分别为99.79%、99.481%和100%。实验结果优于自适应深度CNN、稀疏滤波、深度置信网络和支持向量机等。文献[127]提出了一种包含一维残差块的更深层的一维卷积神经网络(Deeper One-Dimensional CNN,Der-1DCNN),在框架内还包含了残差学习的思想并首次采用了宽卷积核和dropout技术,有效地缓解了网络训练难度和性能退化的问题,提高了网络的泛化性能。实验表明,该方法与目前常规的轴承故障诊断深度学习方法相比,具有更好的诊断性能。文献[128]实现了一种基于CNN的新体系结构(即LiftingNet),该结构包括分割层、预测层、更新层、汇集层和完全连接层,主要学习过程有分割、预测、更新和循环。利用CWRU数据集对方法进行了分类性能验证,转速相同情况下分类精度为99.63%,四种不同的转速下平均精度仍达到93.19%,比常规方法高14.38%。针对普遍存在的故障诊断中由于标记样本的体积较小所造成的DL模型的深度较浅,限制了最终预测精度的问题,文献[129]基于ResNet-50提出一种迁移学习卷积神经网络(Transfer Convolutional Neural Network,TCNN)用于故障诊断。首先,将时域故障信号转换为RGB图像格式作为ResNet-50输入;然后对所提出的TCNN在轴承损坏数据集、CWRU电机轴承数据集和自吸离心泵数据集三个数据集上进行测试。实验结果表明TCNN(ResNet-50)的预测精度高达98.95%±0.007 4、99.99%±0和99.20%±0,明显优于其他DL模型和传统诊断方法。此外,从提高诊断灵敏性角度出发,以早期微小故障为对象的诊断方法研究是极具现实意义的研究方向,值得深入研究。文献[130]提出了一种基于卷积神经网络的变速轴承早期故障诊断新方法。结合谱能量图(SEM)和DS-DLM算法,实现了可变操作速度下的轴承早期故障诊断,效果显著。
3.5.4 基于RNN的故障诊断方法
早在2005年就出现了将RNN用于故障诊断的文献[131],2008—2010年出现了大量此类文献,但由于梯度消失/爆炸及难以训练等问题该方法经历了一段时间的沉寂,直到2015年才逐渐复苏。文献[132]中将RNN用于轴承故障诊断,首先,利用离散小波变换提取故障特征,并进行特征选择,然后,输入RNN进行故障分类。实验表明,该方法在非平稳工况下也能准确地检测和分类轴承故障。文献[133]中提出了一种将一维CNN和LSTM结合起来进行轴承故障分类的方法,整体结构包括一维CNN层、Maxpooling层、LSTM层和SoftMax层。实验测试精度为99.6%。文献[134]中提出一种具有堆叠隐藏层的LSTM单元,以均方误差(MSE)作为损失函数,并采用自适应学习率来提高训练效果。基于CWRU数据集的诊断实验显示,该方法在转速为1 750转/min和1 797转/min时的平均测试精度分别为94.75%和96.53%。文献[135]提出了一种新的基于RNN的轴承故障诊断方法。该方法利用了具有很强的泛化能力的基于GRU的非线性预测去噪自动编码器(GRU-NP-DAEs),从上一周期预测下一周期的多次振动值,然后利用下一周期数据与GRU-NP-DAE生成的输出数据之间的重构误差,对异常情况进行检测,并进行故障分类。实验结果表明,该方法具有较强的鲁棒性和较高的分类精度,性能优秀。
3.5.5 基于GAN的故障诊断方法
2014年提出的生成对抗网络(GAN)在故障诊断领域最早的应用报道出现在2017年[136],该文献针对故障数据量远小于正常数据量而导致的数据不平衡问题,设计了一个用于故障检测和诊断的深度神经网络,并将生成对抗网络的过采样与标准的过采样技术进行了比较。仿真结果表明,在给定条件下,生成对抗网络的过采样性能良好,所设计的深度神经网络能够对异步电动机的故障进行高精度的分类。文献[137]提出了一种用于滚动轴承无监督故障诊断的分类对抗式自动编码器(Categorical Generative Adversarial Auto-Encoders,CatAAE)。该模型用对抗性方法训练了一个在编码空间上施加先验分布的自动编码器,然后,分类器通过预测分类和样本间的信息平衡对输入样本进行聚类。实验结果表明,当环境噪声和电机负载发生变化时,该方法具有良好的性能和较高的聚类指标,且具有较强的鲁棒性。文献[138]提出了一种结合GAN和SDAE的故障诊断方法。首先,利用GAN生成器产生与振动信号原始样本分布相似的新样本。然后,将生成的样本和等量原始样本一起输入SDAE进行分类,并对新模型进行了并行优化。实验结果表明,该方法可在小样本情况下实现精确故障分类,且具有良好的抗噪声能力。文献[139]提出了一种将Wasserstein GAN与传统分类器相结合的混合生成对抗网络,同样可以解决小样本情况下的能耗元件的自动故障诊断问题,在训练过程中以有限的故障训练样本模拟现实场景进行故障诊断,实验结果证明了该方法的有效性。文献[140]提出了一种新的基于生成对抗网络(GAN)的工业时间序列不平衡故障诊断方法。在GAN中采用了编码器-解码器-编码器三个子网络,该子网络基于深度卷积生成对抗网络(Deep convolutional GAN)。为了验证该方法的有效性和可行性,利用CWRU滚动轴承数据进行了验证,性能良好。
3.5.6 基于深度学习的故障预测方法
故障预测是依靠历史数据来估计预测对象未来时刻工作状态的方法。深度学习具有深度特征学习和复杂非线性函数逼近的能力,表明了其在故障预测中的有效性。然而,就目前的研究成果看,此类文献还比较少,有待研究者做进一步研究。文献[141]中,将多目标进化算法与传统的DBN训练技术相结合,将多个DBN同时进化为两个相互冲突的目标,再用进化后的DBN构建一个用于剩余寿命(Remaining Useful Life,RUL)估计的集成模型,通过差分进化算法优化模型组合权重,并在几种预测基准数据集上进行算法评估,验证了方法的优越性。文献[142]应用带FNN的DBN进行自动特征学习,在轴承座上垂直于轴的方向安装了两个加速度计,每5分钟采集一次数据,采样频率为102.4 kHz,持续时间为2 s,实验结果表明,所提出的基于DBN的方法能够准确预测未来5 min和50 min的真实RUL。文献[143]研究了常规RNN、AdaBoost-LSTM和GRU(Gated Recurrent Unit)-LSTM三种RNN模型在航空发动机故障预测中的应用。文献[144]提出了一个非常有效的RUL预测结构,设计了一种基于LSTM的编码器-解码器结构。首先,通过编码器将多变量输入序列转换成固定长度的矢量,再利用该矢量生成目标序列,然后,在无监督情况下进行网络训练,最后,利用重建误差计算健康指数,并将其用于RUL估计。从实验结果可以看出,较大的重建误差对应于更不健康的机器状况,实现了基于重建误差的机器健康状况表征。文献[145]提出了一种基于深度学习的故障预测方法,通过故障模型训练、故障特征识别、故障演化等方法,在设备状态监测和测试验证的海量数据基础上,实现了在线动态故障预测。文献[146]提出了一种基于稀疏自动编码器的深度转移学习(DTL)网络。采用三种转移策略,将由历史故障数据训练的SAE转移到新的目标上。并以刀具剩余使用寿命(RUL)预测为例,验证了DTL方法的有效性。文献[147]提出了一种基于长短期记忆(LSTM)网络和支持向量机(SVM)的电力系统故障预测方法。根据南方电网万江变电站的实际电力系统数据进行了实验,结果表明与现有的数据挖掘方法相比,该方法有明显的改进。文献[148]分别用长短时记忆(LSTM)网络、栈式自编码器(SAE)和门循环单元(GRU)神经网络,实现了电力负荷的预测,验证了深度学习模型在预测应用中的可行性,并从中选择了最佳预测模型。文献[149]提出了一种新的在线数据驱动框架,利用深卷积神经网络(CNN)预测轴承的RUL。首先利用Hilbert-Huang变换(HHT)对训练数据进行处理,并构造一种新的非线性退化指标,然后利用CNN识别出退化指标与振动数据之间的隐藏模式,最终实现了对轴承退化的自动估计。实验结果表明,与目前最先进的RUL估计方法相比,该框架具有更好的性能和通用性。
3.5.7 五种模型应用于故障诊断与预测的优缺点
结合文献,表4整理了故障诊断与预测领域中常用的五种深度学习方法的优缺点。

表4 五种模型应用于故障诊断与预测的优缺点
4 总结与展望
4.1 存在的问题及解决方法探索
作为一个新兴的、重要的研究领域,深度学习在很多应用中都显示出巨大的威力和潜力。但是,在故障诊断方面仍然存在一些需要进一步发展和完善的空间。
4.1.1 从数据角度
(1)缺乏大量的有效数据
基于深度学习的故障诊断方法性能的好坏很大程度上取决于数据集的规模和质量,即依赖于大量优秀的数据。然而,现实中这通常是做不到的。首先,设备无法承受在故障条件下运行的严重后果,其次,设备存在发生预期故障前的潜在耗时退化过程,也就是说从非目标机器上采集的公共可用数据集或自收集数据集和实际的目标机器的运行轨迹不可能完全吻合,势必由于目标设备的自然老化而存在差异性,即使在同一台机器在不同的负载设置下,也不可避免地存在训练集和测试集的分布差异,性能仍然会受到影响。相较于图像识别领域中由包含1 000多万个注释图像的大型数据集ImageNet作为支撑,基准CNN模型就能达到152层的巨大优势,大量有效数据的缺乏是基于深度学习的故障诊断技术的发展瓶颈之一。
迁移学习的出现为解决这一问题提供了新的思路和方法,多种迁移学习的框架被提出[150]。目前比较流行的方法是域自适应[151],通过研究域不变特征自适应建立从源域到目标域的知识迁移。对于源域的标记数据和目标域的未标记数据,域自适应算法可以减小两域之间的分布差异。从这个角度出发,设计新的域自适应模块与深度学习体系结构相结合,用来克服有效数据的不足问题,是一个值得研究的方向。此外,GAN网络的出现也为这一问题的解决提供了新思路,可以模拟任何数据分布的强大功能势必使得GAN在解决有效数据量缺乏这一问题上提供非凡助力。
(2)使用数据源单一,且不平衡
从前述文献分析中可以看到,现有文献大多数使用了CWRU数据集。很多精度超过99%的DL方法都是在固定的运行条件下获得的,这势必影响测试精度的准确性,一旦受到噪声或电机转速/负载变化的影响,精度可能下降到90%以下,而这种影响在实际应用中是不可避免的。此外,样本的选择并没有保证均衡抽样,这意味着健康状态和故障情况不接近1∶1,存在严重的不平衡,这时仅采用精度作为评估算法的唯一指标显然会影响算法在实际应用中的有效性。
针对此问题,认为如果考虑选用通用数据集,则首先需要对原始数据集进行各种干扰以此来打破数据集的饱和度,即用随机噪声污染信号来测试算法的去噪能力,其次,可以选择更为复杂的数据源,比如前文提到的德国Paderborn大学提供的故障数据库,或多个数据源综合验证的方法进行性能比较可能结果更为准确和有效。同时,可搭建实验仿真分析平台,注入不同类型的故障,得到不同故障对应的仿真信号,通过分析故障机理的方式对深度学习方法进行有益的补充,或许是一个可行的研究思路。
(3)数据处理的复杂性
如前所述,数据的复杂性不言而喻,如何对样本多源、且存在标注不规范、不统一、不全面的数据进行有效处理是提高深度学习性能不可回避的重要问题。笔者认为,增设完善的数据预处理平台,多角度出发搭建各自独立又逐层递进的子网络来实现不同类型的数据处理,待数据转化为统一的数据规范类型后再输入深度学习网络中进行故障特征提取和分类不失为一种可行的思路。
4.1.2 从结构角度
(1)缺乏理论证据
目前,很多深度学习模型正被用于解决特定的故障诊断问题并取得了很好的效果。但是研究者没有解释深层网络内部的计算机制,也就是说缺乏足够丰富的理论证据说明为什么在故障诊断和预测中使用深度学习可以获得特定的结果以及如何去选择、设计或实现深度学习体系结构。
针对这一问题,认为模型和数据可视化是可以尝试的途径之一。学习的表示和应用模型的可视化可以为这些深度学习模型的选择、设计提供参考。例如,用于高维数据可视化的t-SNE算法模型[152]以及2016年提出的可视化操作平台Deep Motif Dashboard[153]等。
(2)深度网络结构的优化
从前述文献中不难看出,基于深度学习的故障诊断方法具有训练数据多、计算量大的特点,这成为深度学习方法在故障诊断领域实现在线诊断以及故障预测的瓶颈之一。这就要求研究者施加结构限制以控制各种深度学习架构的计算量,同时,又不能以降低诊断精度为代价。寻找一些精度与速度之间的平衡,或者在保证精度的前提下,引入其他方法来提高速度的方法更加值得研究,例如,实现并行操作,包括GPU加速、数据并行和模型并行等。
(3)模型的参数优化
在模型构建过程中参数的动态优化调整是其发展的一大挑战。从现有文献看,针对优化学习模型参数的可见报道稀缺,基本集中在非线性激活函数的改进[154]和参数初始化[155]等方面,这无疑是制约深度学习技术发展的一大阻碍。今后的研究应该花更大的力气多角度、多方法的实现模型参数优化,从而从根本上提高深度学习网路性能。
4.1.3 从方法角度
(1)发展混合算法
根据前述,深度学习模型因理论支撑不足而被人们称为“黑匣子”,其在故障诊断领域的应用也给人“因人而异”的印象,这些问题的存在,使得其泛化能力备受质疑。由此,很多研究者进行了混合算法的初探,比如文献[156-158]将深度学习和频谱、小波、PCA等进行了混合,他们试图通过加入人工提取特征环节来减少训练时间。然而这种做法可能会在算法的早期训练中就产生偏差从而导致结果不可靠,同时也违背了深度学习端到端学习的重要思想。近年来又涌现出了一些新的方法[104,159]试图解决上述问题,这是一种好的现象,但目前还远没有达到各种方法“有机结合”的程度。因此,在今后的研究中还应继续探索新的可能性,比如,将深层、浅层网络进行组合构建新的具有优异性能的混合深度学习模型;将监测数据组合成为二维图谱,以充分展示深度学习模型的图形处理优势等,最终通过各种方法取长补短、优势互补的有机结合实现高效、高准确率的复杂工业系统的故障诊断与预测。
(2)缺乏对结果评价的基准
从前述文献可以看出,很多研究者已成功应用各种深度学习方法实现了故障诊断和预测,并就诊断精度与SVM、单隐层神经网络等方法进行比较,效果明显。但这可能会产生误导,因为使用多层信息处理模块能够得到更好的诊断结果这几乎是可以预见的。然而,在实际应用中,得到一个好的诊断结果绝不是衡量一个故障诊断与预测方法好坏的唯一标准,可靠性、灵敏性、稳定性、效率、成本、泛化能力等都是不可忽视的问题。比如,实现架构是否为受控系统、实现方法是否很好地解决了故障诊断的可靠性问题、是否存在信息的丢失而影响了系统的稳定性、方法的灵敏性如何、时间是否有延迟等问题都有可能导致诊断失去意义。因此,制定结果评价基准是实现方法性能准确鉴定的必要前提条件。如何建立合理、全面、可操作的结果评价基准是今后研究中需要思考的问题。
4.1.4 从应用角度
故障诊断与预测技术绝不能仅仅停留在实验研究层面,它一定是能够进行实际应用的技术手段。因此,研究者应该从工业实际和学术双角度出发,全面考虑环境、成本、可靠性、灵敏性、实用性、效率等众多因素,且不能将工作集中在提高低设计级别的故障诊断上,故障的预测、停机时间的控制、故障的隔离、故障决策效率、微小故障的跟踪、设备老化进程跟踪、跨领域策略等等问题都应是今后的研究方向。
4.2 展望
对于工程界而言,深度学习已经为未来的研究开辟了一片广阔的天地。正如本文所看到的,深度学习展示了很多的优点并取得了一定的成绩,这使得它更具吸引力。然而,如上所述,其在故障诊断与预测领域中仍然存在很多的挑战和难点,这也为今后发展的方向提供了指导。对应用深度学习进行故障诊断和预测的发展趋势作如下展望:
(1)研究进程从故障诊断到退化状态识别再到故障预测已成为必然趋势。
(2)研究数据的来源、构建大数据库、进行复杂数据的处理已成为基于深度学习的故障诊断与预测技术发展瓶颈的重要突破口。
(3)突破深度学习理论研究瓶颈,探索其内部算法打开“黑匣子”是其技术发展不可回避的问题。
(4)将深度学习与传统浅层模型相结合,构建具有优异性能的混合深度学习模型势在必行。
(5)从应用视角出发,尝试用人工故障训练的算法对自然故障进行预测,这实际上是对基于深度学习的故障诊断与预测算法在现实中应用的合理期望。
5 结束语
故障诊断与预测的最终目的是准确判断部件的状态从而预防事故的发生。与传统浅层机器学习方法相比,深度学习在故障诊断和预测中能够提供更好的表示和分类,因此利用深度学习方法进行故障诊断与预测是必要、可行的。本文首先对近年来深度学习及其在各领域发展的优秀综述文献以及主流的开源仿真工具平台进行了整理,同时介绍了目前典型的五种深度学习模型,包括AE及其变体、DBN、CNN、RNN和GAN;其次就深度学习在故障诊断与预测中的应用研究进行了归纳总结,从研究背景、实现流程及研究动态等三个方面进行了阐述,并在研究动态中就发展趋势、数据来源进行了介绍,系统梳理了近年来这一领域发表的相关论文;最后从研究实际出发就深度学习在故障诊断与预测领域应用中存在的问题、挑战及解决方法进行了探讨,并对未来的发展进行了展望。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
一重技术(2021年5期)2022-01-18
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
电子制作(2018年10期)2018-08-04
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
