
基于生成对抗网络去除车辆图像运动模糊模型
2020-02-19 01:52:12姜丽芬孙华志马春梅
天津师范大学学报(自然科学版) 2020年1期
安 祺,姜丽芬,孙华志,梁 妍,马春梅
(天津师范大学 计算机与信息工程学院,天津 300387)
随着云计算、大数据和物联网等技术的发展,我国城市智能交通市场规模呈持续高速增长态势,包含智能公交、电子警察、交通信号控制、卡口和交通监控等项目,其中交通监控是减少交通安全事故的一道重要防线.监控图像包含丰富的信息,是非常重要的信息来源,然而,由于车速过快或不良照明等因素,容易造成抓拍图像出现模糊退化等问题,这些问题不仅严重影响了图像信息的价值,也给图像信息的进一步处理,如特征提取与分析等带来一定困难.因此,监控图像的去模糊处理尤为重要.通过缩短曝光时间可以减少运动模糊,但代价是噪声更高、景深更浅,对成像传感器质量要求更高,或者需要更强的照明,所以这种方法并不总是可行的,并且需要较高的成本.近些年来,随着数值计算设备的改进,深度学习技术快速发展.卷积神经网络具有良好的容错和自学能力,在样本数据存在一定缺损的情况下,它可以处理图像模糊、背景信息复杂等情况的模式识别问题.因此,在车辆识别系统中卷积神经网络算法具有优势[1].模糊图像一般被看作由清晰图像卷积模糊核得到:文献[2]提出了单独估计模糊核的方法;文献[3]基于该方法结合贝叶斯最小均方误差采样算法进行反卷积,去除图像的运动模糊;文献[4]使用基于最大后验估计的盲去模糊模型处理模糊车辆图像.上述方法能够在一定程度上去除噪声,增强细节,有效改善运动模糊图像的质量,但对于未知模糊核的运动模糊图像,它们需要进行复杂的计算来估计模糊核,从而使模型计算开销增大,响应时间变长,一旦模糊核估计错误还会影响图像处理的质量,出现振铃伪像.文献[5]使用一个仅由卷积层和Relu 层组成的15 层卷积神经网络来处理车牌图像的运动模糊,但该网络仅适用于处理模糊程度一般的模糊图像,对于模糊程度比较高的图像则显得比较乏力.文献[6]基于深度CNN 去噪器处理图像的运动模糊,这种模型在处理模糊程度较高的图像时得到的峰值信噪比较低.文献[7]基于由粗到精的模式提出了一种尺度递归网络,这种方法在去除图像运动模糊方面取得了较好的效果,但是由于训练模型时使用的数据集不具有针对性,所以在处理车辆图像运动模糊时效果欠佳.
本文基于生成对抗网络[8],引入多尺度递归网络作为生成对抗网络的生成器,提出一种去除图像运动模糊的网络模型.该模型在专门的车辆数据集上训练网络,实验结果显示,去除运动模糊后的图像比较清晰,处理后的车辆图像峰值信噪比达到了29.52.
1 模型搭建
1.1 生成对抗网络模型
模型的基本框架如图1 所示.模糊图像B 经生成器G 得到生成图像G(B),判别器D 以清晰图像S 和生成图像G(B)作为输入得到一个概率值表示置信度,置信度表示生成图像G(B)是清晰图像S 的概率,以此来判断生成器G 的性能优劣.生成器G 的目标是尽量生成真实的图像去欺骗判别器D,而判别器D 的目标是尽量把G 生成的图像与清晰图像区分开,当判别器D 无法区分清晰图像S 和生成图像G(B)时,认定此时生成器G 的性能达到最优.
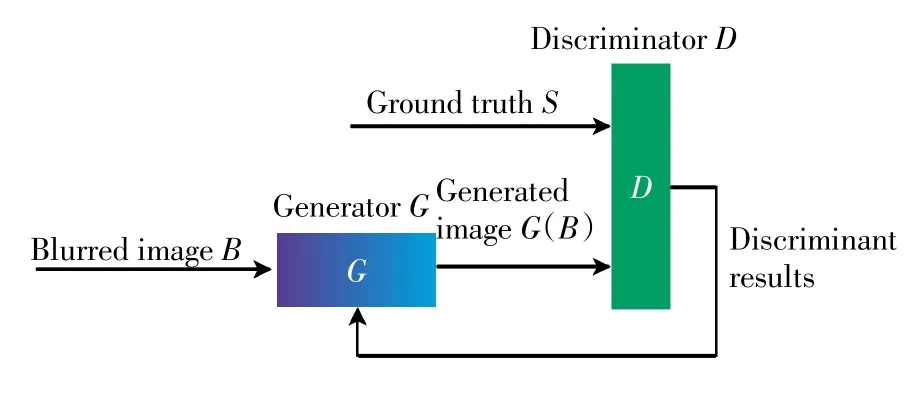
图1 生成对抗网络模型框架Fig.1 Framework of genarative adversarial network
1.2 生成器模型结构
本文生成器的模型包含3 层网络结构,由粗糙到精细.为了在保留精细级别信息的同时利用粗糙级别的信息,网络采用高斯金字塔的形式,更精细级别的去模糊由较粗级别的特征辅助,由粗到精级别的网络分别由不同分辨率的图像作为输入.生成器模型结构如图2 所示.
在生成器模型中,本文引入了多尺度递归网络.该网络以3 个不同尺寸的模糊图像作为输入,输出去模糊后的清晰图像,每个尺寸的输出都经过训练,整个网络的最终输出是原始比例的图像.在生成器网络的3 个不同尺度结构中,每个尺度上都产生该尺度对应的清晰图像,产生的清晰图像经过图像上采样与下一尺寸的模糊图像作为输入再次产生清晰图像.在训练时,3 个尺寸模糊图像的大小设置为64×64,128×128 和 256×256.
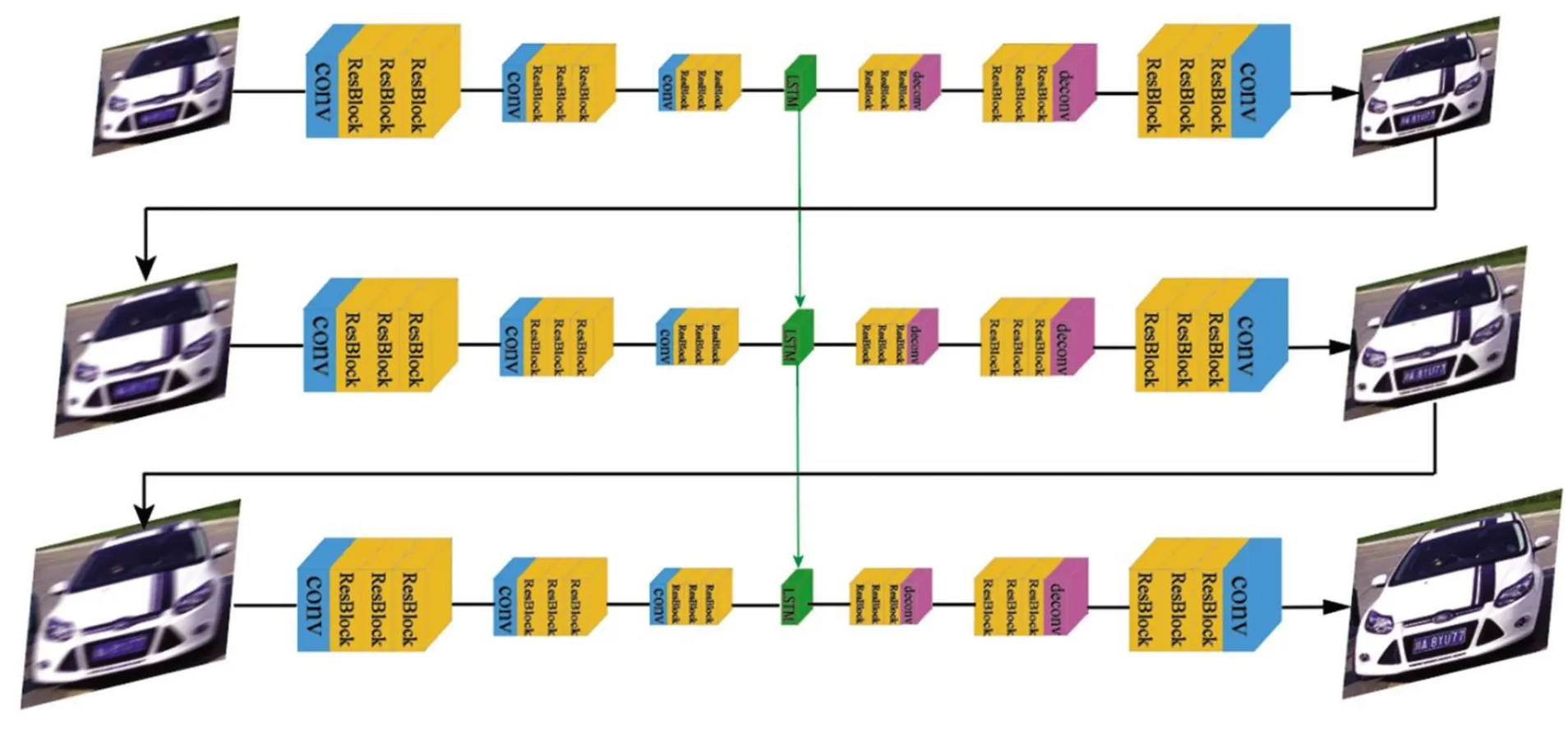
图2 生成器模型Fig.2 Model of generator
生成器的第1 层网络是最粗糙的网络,第3 层网络是最精细的网络.为了实现更深层的网络架构,本文使用了残差子网.最粗糙网络的第1 层卷积层将1/4 分辨率、64 ×64 大小的输入图像处理为64 个特征映射.生成器每个级别的网络分为7 个模块,包括1个输入块、2 个编码块、1 个 LSTM 块、2 个解码块以及1 个输出块.每个编码块都由1 个卷积层和3 个残差模块组成,编码块将输入的特征映射下采样为原来的1/2.解码块与之相对应,每个解码块包括3 个残差模块和1 个反卷积层,反卷积层将输入的特征映射上采样到原来的2 倍.输出块将上采样后的特征映射作为输入生成图像.在生成器的第1 层网络运行结束时,生成最粗糙的潜在清晰图像,第2 层和第3 层网络将上一层生成的清晰图像与下一级别尺寸的模糊图像作为输入,为了使上一层网络的输出图像适应下一层网络的输入尺寸,需要对图像进行上采样.
1.3 改进的残差网络模型
在残差模块中,本文将传统残差进行修改,在传统残差网络中去掉了BN 层,每个残差块中包含2 个CNN 层,这样可以扩展感受野,也可以提高网络训练的收敛速度.改进后的残差模型结构如图3 所示.

图3 改进的残差模型Fig.3 Improved residual block
1.4 判别器模型结构
在生成对抗网络中,生成器的参数更新不是直接来自于数据样本,而是来自于判别器的反向传播,因此,生成对抗网络往往可以生成比其他模型更接近真实清晰图像的样本[8-9].本文采用生成对抗网络的判别器层次结构如表1 所示.
该判别器模型共有9 层卷积层,每一层卷积层都使用LeakyRelu 激活层,之后连接全连接层,最后经过Sigmoid 层输出置信度.判别器以生成器最精细网络的输出图像与清晰图像作为输入,输出的值是置信度.若置信度值大于0.5,则判定该输入图像为清晰图像.
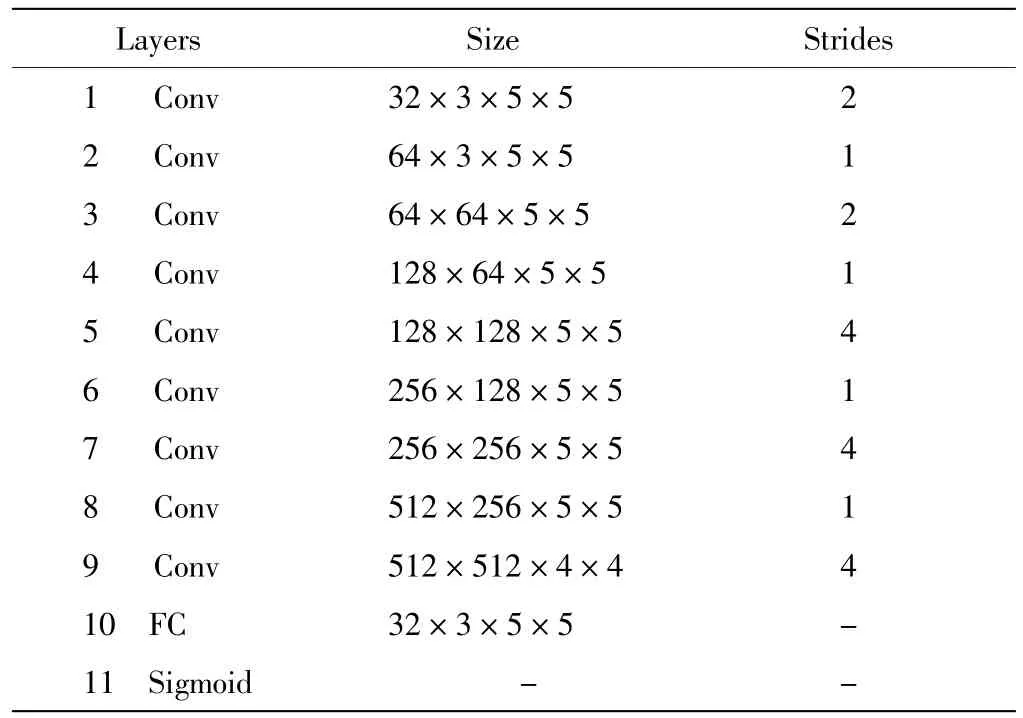
表1 判别器模型参数Tab.1 Model parameters of discriminator
1.5 损失函数
在优化网络参数时,本文采用多尺度内容损失和对抗性损失这2 种损失函数,将2 种损失函数进行组合,训练模型.
由粗到精的方法希望输出的图像都是该尺度下清晰度最高的图像.为了防止过拟合同时获得更好的效果,本文使用l2范数,定义多尺度内容损失函数为
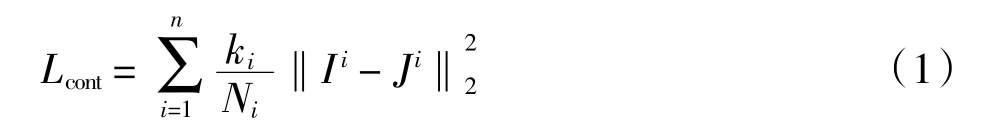
其中:Ii、Ji分别为在尺度水平i 下模型输出图像和对应的清晰图像;ki为每个尺度的权重;Ni为Ii中需要标准化的元素数量.对抗性损失函数为
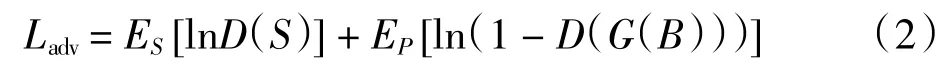
在训练时,生成器试图最小化对抗损失,而判别器则试图最大化对抗损失.结合以上2 种损失函数,总的损失函数为

其中λ为权重系数,经过对比实验结果,确定λ=10-4.
2 实验
2.1 数据预处理与数据集建立
本文使用PKU-VD 公开数据集,选取其中的13 516 张带有车辆牌照的汽车图像,这些图像均为由交通监控设备采集到的清晰图像.数据集中训练集占总数的80%,测试集占总数的20%.数据集部分样本如图4 所示.
利用Matlab 为所有图像添加运动模糊效果来模拟汽车在运动中被拍摄时产生的运动模糊,具体方法为使用Matlab 的IPT 函数fspecial 对图像进行模糊建模,
PSF=fspecial(′motion′,len,theta)fspecial 函数返回PSF,motion 为选用的滤波器,len为移动的像素个数,theta 为移动的角度.本文使用len值为9,theta 值为0,即在水平方向上对图像进行9个像素的移动产生运动模糊效果.清晰图像和添加模糊效果的图像如图5 所示.

图4 数据集部分样本Fig.4 Part of examples of datasets

图5 原清晰图像(左)和添加模糊效果的图像(右)Fig.5 Ground clear image(left)and blurred image(right)
为了防止网络过拟合,本文对数据集中的图像进行了扩增,包括对图像进行几何翻转,为图像添加高斯噪声等操作.
2.2 实验环境及参数设置
在以上数据集上训练模型,模型采用深度学习框架TensorFlow,训练模型时使用Adam 求解器,通过实验并结合经验进行参数调整,以使模型性能达到最优,最终确定参数设置为 β1=0.9,β2=0.999,ε=10-8.模型训练在配备有英特尔i7CPU 以及NVIDIAGTX1080Ti GPU 的计算机上进行.
2.3 实验结果
模型在训练集上训练2 ×105次后收敛,在测试集中测试模型效果.针对车辆图像的去运动模糊效果如图6 所示.由图6 可见,去除车辆运动模糊后的图像比较清晰,可以分辨细节内容.另外,本文还利用该模型处理了一些其他场景的运动模糊图像,也取得了较好的效果,如图7 所示.
此外,本文还采用了峰值信噪比PSNR(peak signalto-noise ratio)来衡量图像恢复的效果.峰值信噪比PSNR 表示信号最大可能功率与影响它表示精度的破坏性噪声功率的比值.由于许多信号都有非常宽的动态范围,PSNR 常用对数分贝单位来表示.PSNR 越高代表恢复后的图像与原图像相似度越高.在测试集中利用本文算法与相关文献的去模糊算法针对峰值信噪比做了比对实验,包括文献[4]中的CNN-15 算法和文献[10]中基于l0范数的去模糊方法,实验结果如表2 所示.由表2 结果可见,本文算法的PSNR 相比CNN-15 和基于l0范数的方法获得了一定的提升.

图6 车辆去运动模糊效果Fig.6 Results of removing image motion blur for vehicle

图7 其他场景去运动模糊效果Fig.7 Result of removing image motion blur on other sences

表2 不同方法的峰值信噪比结果Tab.2 PSNR results of different methods
3 结语
基于生成对抗网络,使用多尺度卷积神经网络作为生成器去除车辆图像运动模糊,实验结果表明,处理后的图像可以分辨细节内容,模型处理每张模糊图像仅需1.7 s,可以用于交通监控图像的处理.下一步将继续提升模型性能,以适用于车辆或车牌的自动识别.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
太空探索(2016年5期)2016-07-12 15:17:55
河南科技(2015年8期)2015-03-11 16:23:52
时代英语·高三(2014年5期)2014-08-26 17:01:17
