
兴安落叶松立木材积和树皮材积可加性模型研建
2020-02-12 09:02:46靳晓东姜立春
中南林业科技大学学报 2020年2期
靳晓东,姜立春
(东北林业大学林学院,森林生态系统可持续经营教育部重点实验室,黑龙江 哈尔滨 150040)
随着森林生态系统在全球气候变化中的作用越来越重要,森林资源监测越来越得到普遍重视,其中森林蓄积量是反映森林生长情况和森林生态活力的主要指标,而建立立木材积模型的主要目的是预估森林蓄积[1],并且林木地上生物量与立木材积有着密切的相关性[2],国内外开展的大量研究都以此为基础。骆期邦等[3]以杉木、马尾松、阔叶树3个树种的实测数据为基础,提出了用线性联立以及非线性联合估计模型来建立立木生物量模型,从而解决了生物量总量与它各分量,即与干、皮、枝、叶之间的相容性问题;Parresol[4]提出采用非线性似乎不相关模型来解决非线性生物量方程的可加性问题;贺东北等[5]根据中国南方马尾松实测数据,通过线性联立方程组的方法,研建了与材积兼容的可加性(相容性)立木生物量模型。
董利虎等[6]基于276 株实测生物量数据,研建了东北林区红松、臭冷杉、红皮云杉以及兴安落叶松4 个天然针叶树种总量和各分项的一元、二元可加性模型,很好地预估了4种天然针叶树种的生物量;甘世书等[7]以桉树、木麻黄以及加勒比松、马占相思、橡胶树为研究对象,分别以胸径10 cm和胸径12 cm 为节点,采用分段建模方法建立海南省主要树种立木材积模型,有效地提高了二元立木材积模型的通用性;宋博等[8]以人工小黑杨为研究对象,进行了各分项生物量最优模型的选取,并构建了3 种小黑杨可加性生物量模型系统,结果表明3 种可加性模型均有较好的拟合效果。
树皮作为树木有机体的重要组成部分,它是森林采伐和木材加工的副产物,每年都会有大量的树皮产生,是一个很大的资源宝库[9]。随着生物质能源的增加树皮的利用率也在增加,因此准确预测树皮的蓄积量变得尤为重要[10]。与传统的立木材积模型相比,可加性立木材积模型解决了总立木材积与各分项立木材积之和相等这一逻辑关系问题,避免了各分项立木材积的估计值之和不等于总立木材积的估计值。
目前,可加性模型的构建方法主要有总量控制法[4]和总量分解法[11]。以大兴安岭兴安落叶松Larix gmeliniiRupr.天然林为研究对象,选择常用的立木材积模型进行对比选优,进而分别采用控制法和分解法构建可加性立木材积模型。可加性模型的参数估计具体采用非线性似乎不相关方法,拟合结果采用确定系数(R2)和均方根误差(RMSE)进行评价;检验结果则通过确定系数(R2)、均方根误差(RMSE)、平均相对误差(MRE)、平均误差绝对值(MAB)和相对误差绝对值(MPB)进行评价检验,选出最优可加性方法,旨在为大兴安岭落叶松立木材积和树皮材积的精准预测提供科学依据。
1 数据来源与处理
数据来源于大兴安岭西林吉、图强、阿木尔、呼中林业局不同林龄和不同林分采集的落叶松样木数据。树木被伐倒后,测量胸径(1.3 m)、树高及15 个相对树高0%、2%、4%、6%、8%、10%、15%、20%、30%、40%、50%、60%、70%、80%、90%处的直径并测量各区分段梢头和梢底直径以及中央位置处的带皮和去皮直径。绘制树高—胸径散点图剔除异常数据后得到了767 株样木的干形数据,并通过区分求积法计算带皮和去皮立木材积。所收集的样木代表性较强,干形良好。将所收集全部样木数据按径阶划分为6(4 ~8)、10(8 ~12)、14(12 ~16)、18(16 ~20)、22(20 ~24)、26(24 ~28)、30(28 ~32)、34(32 ~36)、38(36 ~40)、42(40 ~44)、46(44 ~48)、48(≥48)cm 以上12 个组,每个径阶随机抽取40 株样木作为建模样本,剩余的样木作为检验样本。最终得到,建模样本480 株,检验样本287 株。每个径阶样木接近均匀分布,在大尺度范围具有一定代表性。样本数据的基本统计指标如表1 所示。
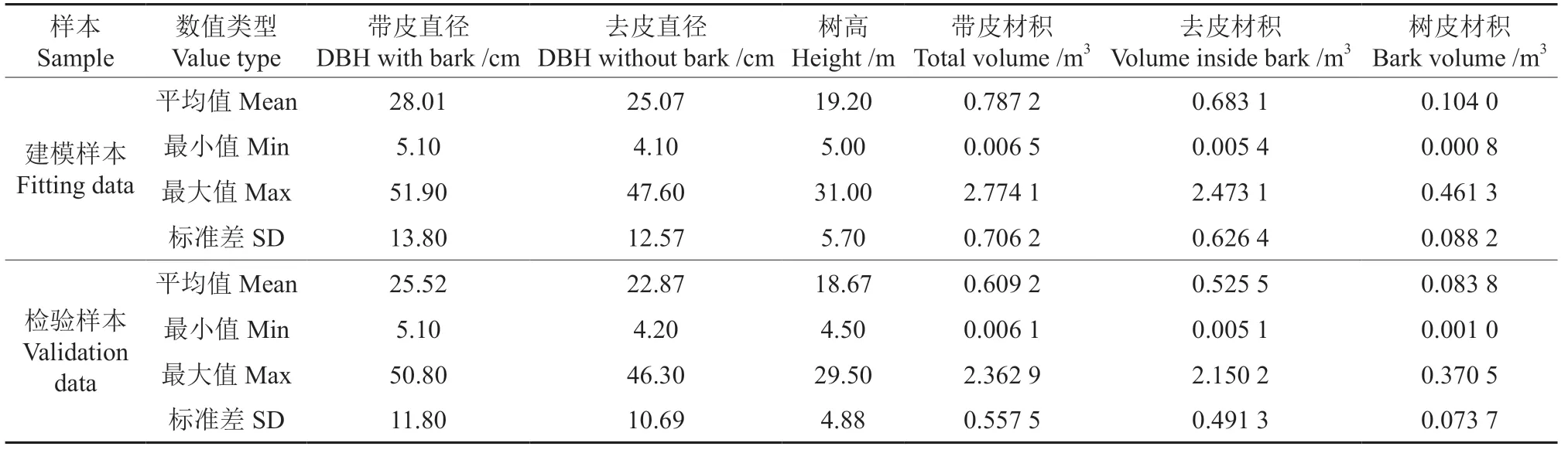
表1 样木调查因子统计量Table 1 Statistics of sample survey factors
2 研究方法
2.1 基础模型选择
计算林木的立木材积离不开相关的材积模型,常用的立木材积模型包括基于胸径和树高的二元模型,以及仅以胸径为解释变量的一元模型[12]。我们初步选择18 个常用的一元和二元模型[13],模型的具体形式如表2 所示:

表2 立木材积备选模型形式†Table 2 Candidate model forms of volume
2.2 可加性模型构造
本文研究的是关于立木材积的可加性,即单木总材积与其去皮材积和树皮材积满足可加性原则。为了便于阐述,以林业上最常用的山本式立木材积模型(模型5)为例,分别使用控制法[4]和分解法[11]来构建可加性模型系统。
2.2.1 总量控制法
总量控制法主要根据Parresol(2000)提出的非线性模型可加性方法,即把总立木材积(带皮立木材积)直接分为去皮和树皮材积2 个部分,在满足总立木材积=去皮立木材积+树皮立木材积的条件下来构建可加性方程系统。为了便于叙述,v0,v1,v2分别代表总材积、去皮材积和树皮材积。则可加性方程系统为:

式(1)中:a0、a1、a2、b0、b1、b2、c0、c1、c2为模型待估参数,且a0、b0、c0为总材积模型待估参数;a1、b1、c1为去皮材积模型的待估参数;a2、b2、c2为去皮材积模型待估参数。为总材积的估计值,和分别为去皮材积和树皮材积的估计值。
2.2.2 总量分解法
总量分解法是根据唐守正等(2000)[14]提出的非线性模型比例平差法,也是解决非线性可加性模型的一种方法,该方法就是要满足各分量占总量的比例之和等于1。同样以模型5 立木材积方程为例,可加性方程系统为:

式(2)中:a、b、c、是回归系数,r1、r2、k1、k2、f1、f2为模型待估参数,且r1=a2/a1、r2=a1/a2、k1=b2-b1、k2=b1-b2;f1=c2-c1、f2=c1-c2。为 总 材积的估计值,和分别为去皮材积和树皮材积的估计值。
2.3 异方差处理
在模型拟合过程中经常会产生异方差现象,尤其是在立木材积模型中,在因变量预测值增大的过程中误差一般也随着增大,即表现为明显的异方差性[15-17],所以在模型拟合过程中需要采取措施以消除异方差的影响。目前普遍采用的消除异方差的方法有对数转换和加权回归[18-19]。而在联立方程组拟合过程中产生的异方差现象时,则必须采用加权最小二乘法来消除异方差参数估计的影响[20-21],且当权函数不一样时,就分别进行加权[22]。
2.4 模型评价及检验指标
拟合结果采用确定系数(R2)和均方根误差(RMSE)进行评价;检验结果通过确定系数(R2)、均方根误差(RMSE)、平均相对误差(MRE)、平均误差绝对值(MAB)和相对误差绝对值(MPB)进行检验。它们相应的数学表达式为:
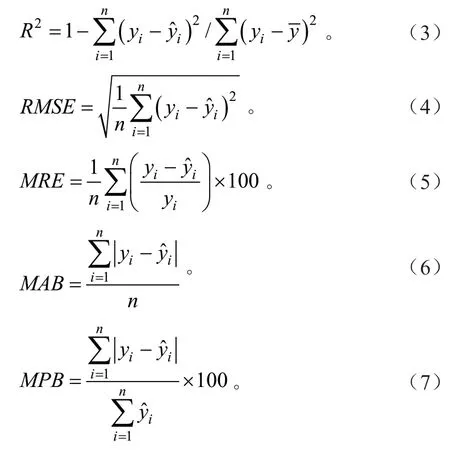
式中:yi和分别为第i株样木的实测值和预估值,为全部样木实测值的平均数,n为样本总数。
每个可加性立木材积模型系统由去皮材积和树皮材积以及总材积方程共同组成并拥有不同的参数,在确保去皮材积、树皮材积和带皮材积之间的可加性前提下进行参数估计,这实际上是解决带限制的非线性联立方程组模型的参数估计问题[23-24]。具体采用SAS 统计软件模型模块proc model 中的NSUR 法进行拟合及参数估计。
3 结果与分析
3.1 基础立木材积模型选择
利用480 株落叶松样木的材积量数据,采用SAS 软件的proc nlin 对模型1 ~18 进行拟合,其结果见表3。可以看出,在全部18 个材积模型中,常用的山本式立木材积模型5 的确定系数(R2)最大且均方根误差(RMSE)最小分别为0.964 4 和0.133 3,因此本文选择模型5 作为可加性立木材积模型的基本方程。

表3 不同材积模型回归估计结果Table 3 Regression estimation results of different volume models
3.2 可加性立木材积模型拟合
基于模型5 分别采用控制法和分解法构建带皮、去皮和树皮材积可加性模型系统。利用480株落叶松样木的材积数据,采用SAS 软件的非线性似乎不相关方法(NSUR)对各可加性模型系统进行拟合。拟合结果见表4。从R2和RMSE来看,基于2 种方法构建的总材积、去皮材积和树皮材积模型的评价指标非常接近。基于分解法的总材积、去皮材积和树皮材积模型略优于总量控制法的相应模型。图1 为基于控制法和分解法的带皮材积、去皮材积和树皮材积模型的残差图,从图1可以看出,加权后各模型的残差图显示了均匀和随机的残差分布。
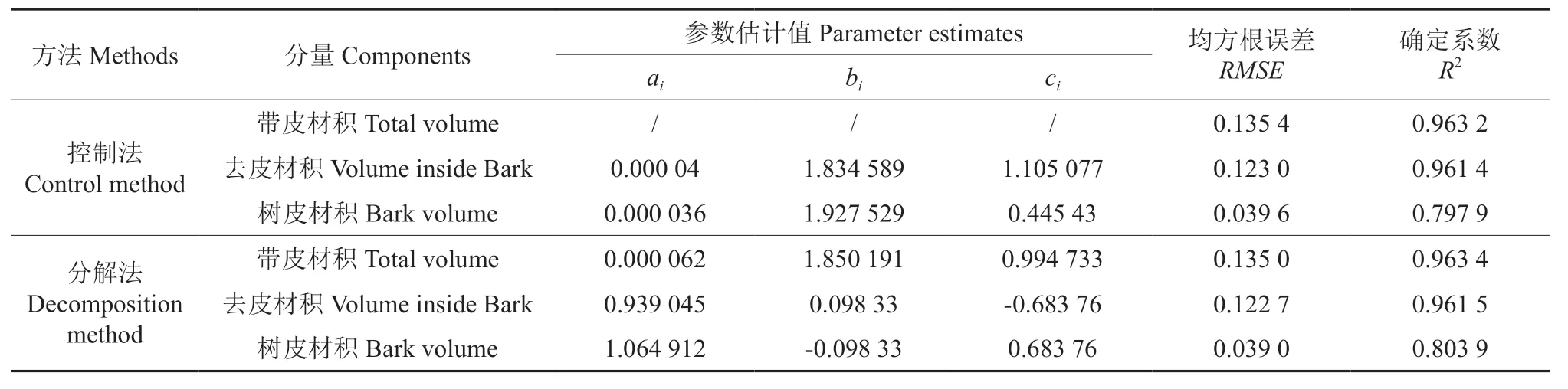
表4 可加性模型系统参数估计值和拟合优度Table 4 Parameter estimates and goodness of fit statistics of additive model systems

图1 基于控制法和分解法的可加性立木材积模型的残差图Fig.1 Residual graph of additive volume models based on control method and decomposition method
3.3 可加性立木材积模型检验
利用检验数据,基于表4 中各模型的参数估计值,通过SAS 软件计算各可加性模型的确定系数(R2)、均方根误差(RMSE)、平均相对误差(MRE)、平均误差绝对值(MAB)和相对误差绝对值(MPB)进行评价。计算结果见表5,可以看出,2 种方法构建的可加性模型对于带皮材积、去皮材积和树皮材积的MAB、MPB和RMSE预测误差非常接近。R2和RMSE统计量与拟合统计量基本一致。对比MRE评价指标可知,基于分解法的总材积、去皮材积和树皮材积模型都优于总量控制法的相应模型。因此,总体来说,基于分解法的各材积模型优于总量控制法的各材积模型。

表5 可加性立木材积模型检验结果Table 5 Validation results of additive volume models
总体模型比较不能反映不同方法在不同径级的预测效果。图2,图3 给出了各方法构建的可加性模型在不同径级上的预测误差。由图2,图3 可以看出,2 种方法对带皮材积、去皮材积和树皮材积在不同径级上的预测误差柱状图非常接近。从标注的误差数值(MAB 和RMSE)可以看出,对于小径阶(5 ≤D<20 cm)和大径阶(D≤36 cm)的树木,基于分解法的带皮、去皮、树皮材积模型的预测精度要比基于控制法的各立木材积模型要稍好,而对于中等径阶(20 ≤D<36 cm)的树木,基于控制法的模型要相对较好。

图2 不同径阶平均误差绝对值检验结果Fig.2 Evaluation results of mean error absolute value of different diameter classes
4 结论与讨论
以大兴安岭西林吉、图强、阿木尔、呼中林业局不同林龄和不同林分采集的兴安落叶松立木材积实测数据为研究对象,采用非线性回归的方法对比选出适合于该区域的最优立木材积模型。基于所选的材积模型采用2 种方法构建了带皮、去皮和树皮材积的可加性模型系统,通过对比分析,可以得到以下结论:
1)通过对比18 种立木材积模型得到了最合适的材积模型5 作为基础模型。然后以模型5 为基础模型分别采用控制法和分解法建立了可加性立木材积模型系统。总量分解法和总量控制法都可以解决立木材积和树皮材积的可加性问题,且所建模型的效果均较好,其中基于分解法的模型系统拟合效果略优于基于总量控制法的模型系统。

图3 不同径阶均方根误差检验结果Fig.3 Evaluation results of root mean square error of different diameter classes
2)从模型整体检验评价结果来看,基于控制法和分解法的模型系统的检验效果均相当,其中基于分解法的各模型的平均相对误差要优于总量控制法,从其它指标来看,2 种方法差距不大。
3)2 种方法的分径阶检验表明,对于中等径阶的树木(20 ≤D<36 cm),基于控制法的模型相对较好,而对于小径阶(5 ≤D<20 cm)和大径阶的树木(D≤36 cm),基于分解法的带皮、去皮、树皮材积模型的预测精度要比基于控制法的各立木材积模型要稍好。
综上所述,基于分解法的可加性立木材积模型更为理想。但在实际应用中,若样地数据多为中等径阶的树木(20 ≤D<36 cm),建议考虑采用控制法构建的各模型,若样地数据多为于小径阶(5 ≤D<20 cm)或大径阶的树木(D≤ 36 cm),建议采用基于分解法的可加性立木材积模型系统。本文所构建的可加性模型系统不但能预测单木带皮材积和去皮材积,还能预测树皮材积,并确保了在预估时得到一致性的预测结果。在具体应用时可根据实际情况选择。
对于本文提到的2 种方法,由于数据的限制,仅比较验证了基于大兴安岭地区兴安落叶松立木材积和树皮材积的可加性模型。因此,不同地区不同树种的单木材积和树皮材积的可加性模型对比有待于进一步研究。此外,既然满足可加性,理论上也应该满足可减性,即树皮材积等于带皮材积减去皮材积或者去皮材积等于带皮材积减去树皮材积。因此在满足可减性的基础上研建立木材积模型方程系统的精度评估也有待于进一步研究。
猜你喜欢
基层中医药(2022年5期)2022-10-24 01:27:32
新农业(2022年22期)2022-01-01 08:30:16
吉林农业(2018年21期)2018-10-25 08:16:24
电子制作(2018年2期)2018-04-18 07:13:31
时代农机(2018年12期)2018-02-14 06:07:04
上海公路(2017年1期)2017-07-21 13:38:33
现代工业经济和信息化(2016年12期)2016-05-17 05:37:56
西南农业学报(2016年6期)2016-04-16 05:13:02
武夷学院学报(2015年3期)2015-07-18 11:03:47
长春工程学院学报(自然科学版)(2013年4期)2013-12-06 06:32:18
