
一种基于BERT的自动文本摘要模型构建方法
2020-02-07 13:33岳一峰任祥辉
计算机与现代化 2020年1期
岳一峰,黄 蔚,任祥辉
(华北计算技术研究所,北京 100083)
0 引 言
自动文本摘要是信息抽取的主要任务之一,也是自然语言处理(Nature Language Process, NLP)[1]领域的主要研究方向。它可以帮助人们从海量数据中快速、精准地获取所需要的信息,解决了数据总量庞大而且信息含量密度低与用户高效精准读取信息的矛盾,并且在自动报告生成、新闻标题生成、搜索结果预览等领域中都有应用[2]。
文本摘要从20世纪50年代末首次提出到现在已经发展了60年,尽管它是NLP的主要研究方向之一,又有着很多的应用场景,但是这个领域却一直发展得比较缓慢。自动文本摘要按原文长度可分为长文本摘要和短文本摘要,按输入文本的数量可分为单文档摘要和多文档摘要[3],按摘要的产生方式可分为抽取式摘要(Extractive)和生成式摘要[4](Abstractive)。从一开始基于统计学的抽取式摘要到如今基于机器学习的生成式摘要,从一开始的PageRank算法到协同过滤,再从后来的聚类到如今的深度学习,学者们一直没有停止对自动摘要算法的研究与创新。
生成式摘要对计算机来说,是一件极具挑战性的任务。从文档中生成一份合适的摘要,要求计算机在理解的基础上对文章进行分析取舍、裁剪拼接,最终生成短文。由此可见生成式文本摘要需要依靠NLP的相关理论。因此,它也成为近几年的重要研究方向之一。
1 相关工作
1.1 文本摘要研究现状
抽取式摘要主要是通过分析文本的统计特征、潜意语义特征等,在句子或者是段落级别上选择关键句从而生成摘要。2004年,Mihalcea[5]提出了TextRank模型,该模型通过句子之间的相似度,而不是单纯计算某些句子含有的关键字数量,可以考虑整个句子以及全文的信息。2011年,Munesh Chandra等通过k-mixture概率模型计算句子的权重,以此选择句子来组成摘要。而Badrinath等[6]针对单文档的查询摘要提出了一种基于改进的LexRank算法,该算法首先对文章中句子进行处理,然后构造出一个标量图,最后通过计算余弦相似度等对句子进行打分,计算出文本摘要。
与抽取式文本摘要不同,生成式摘要主要在理解文章语义的基础上,从词语层面上对句子进行压缩、提炼,最终实现生成摘要的目的。Yang等[7]设计了一种深度框架,用于多文档自动摘要,首次将深度学习用于自动摘要。Rush等[8]将深度学习技术应用到概括式自动摘要的研究中,该算法使用卷积模型对原始文档进行编码,采用上下文相关的注意力前馈神经网络生成摘要。本文研究的就是这种基于深度学习的文本摘要。
当前深度学习的出现虽然带动了文本摘要的发展,但是依然存在诸如传统词向量在因无法对多义词进行有效表征而降低文本摘要准确度和可读性等问题,为此本文提出BERT-Seq2Seq-Attention模型用于文本摘要生成。
1.2 BERT研究现状
BERT(Bidirectional Encoder Representations from Transformers)模型[9]于2018年由Google提出,模型采用表义能力更强的双向Transformer网络结构[10]来对语言模型进行训练,是一种通过大量语料训练得来的一个通用的“语言理解”模型,是第一个用在预训练NLP上的无监督的、深度双向系统。
BERT只需要一个额外的输出层,对预训练BERT进行微调,不需要针对特定任务对模型进行修改就可以满足各种任务。目前,BERT已在句子关系判断任务、抽取式任务(SQuAD)、序列标注任务(命名实体识别)、分类任务(SWAG)上都取得了突破性进展。
2 BERT-Seq2Seq-Attention模型
BERT-Seq2Seq-Attention模型整体结构如图1所示,模型主要分为Encoder、Decoder和Attention,Encoder和Decoder均由Word embedding层、LSTM层和Hidden states组成。由Encoder对文本解码,再由Decoder进行编码最终生成文本摘要。
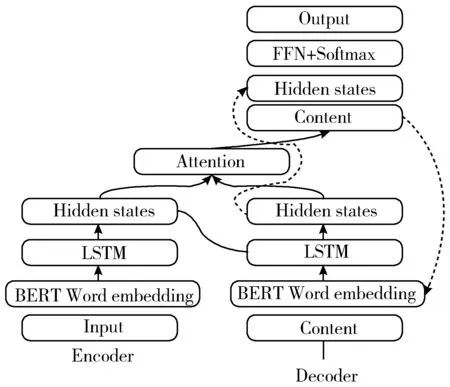
图1 Seq2Seq+Attention文本摘要模型
2.1 BERT词向量模型
近年来,研究人员采用预训练深度神经网络作为语言模型,再以该语言模型为基础针对垂直任务进行微调然后处理的方式取得了很好的效果。比较典型的语言模型是从左到右计算下一个词的概率,如公式(1)所示:
(1)
但是很多时候在将预训练模型应用到垂直领域的时候,并不需要语言模型,而是需要一个词的上下文表示,就能够表征字的多义性、句子的句法特征等。针对这个问题,在2018年Devlin等[9]提出了BERT预训练语言模型。
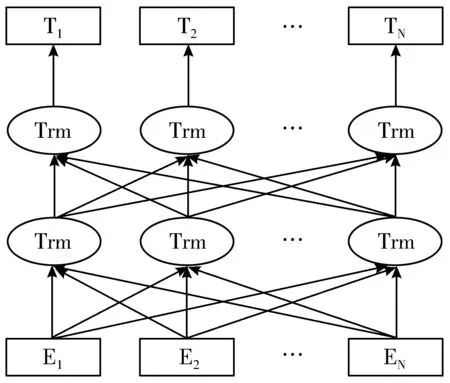
图2 BERT语言模型
为了关联字左右两侧的上下文,BERT采用双向Transformer作为编码器,结构如图2所示。BERT模型还提出了“Masked语言模型”和“下一句预测”2个任务与创新点,分别对词级别和句子级别进行表示,并进行联合训练。
“Masked语言模型”的提出是为了表示向量,该方法采用一个非常直接的方式,遮住句子里某些单词,让编码器预测这个单词的原始词汇。
为了解决fine tuning过程中出现没有见过的词等问题,算法中随机遮住15%的单词作为训练样本,并且使用如下方法:
1)其中80%用masked token来代替。
2)10%用随机的一个词来替换。
3)10%保持这个词不变。
“下一句预测”是指预训练一个二分类的模型来学习句子之间的关系。在NLP领域中很多诸如问答(QA)和自然语言推断(NLI)等重要任务,都需要对2个句子之间的关系进行理解,而人们现在使用的语言模型都不能很好地直接产生这种理解。为了理解语句语义,同时预训练“下一句预测”任务,算法先随机替换一些语句,然后利用上一句进行IsNext/NotNext预测。
BERT最重要的部分是双向Transformer编码结构,Transformer舍弃了RNN的循环式网络结构,完全基于注意力机制来对一段文本进行建模。Transformer编码单元如图3所示。
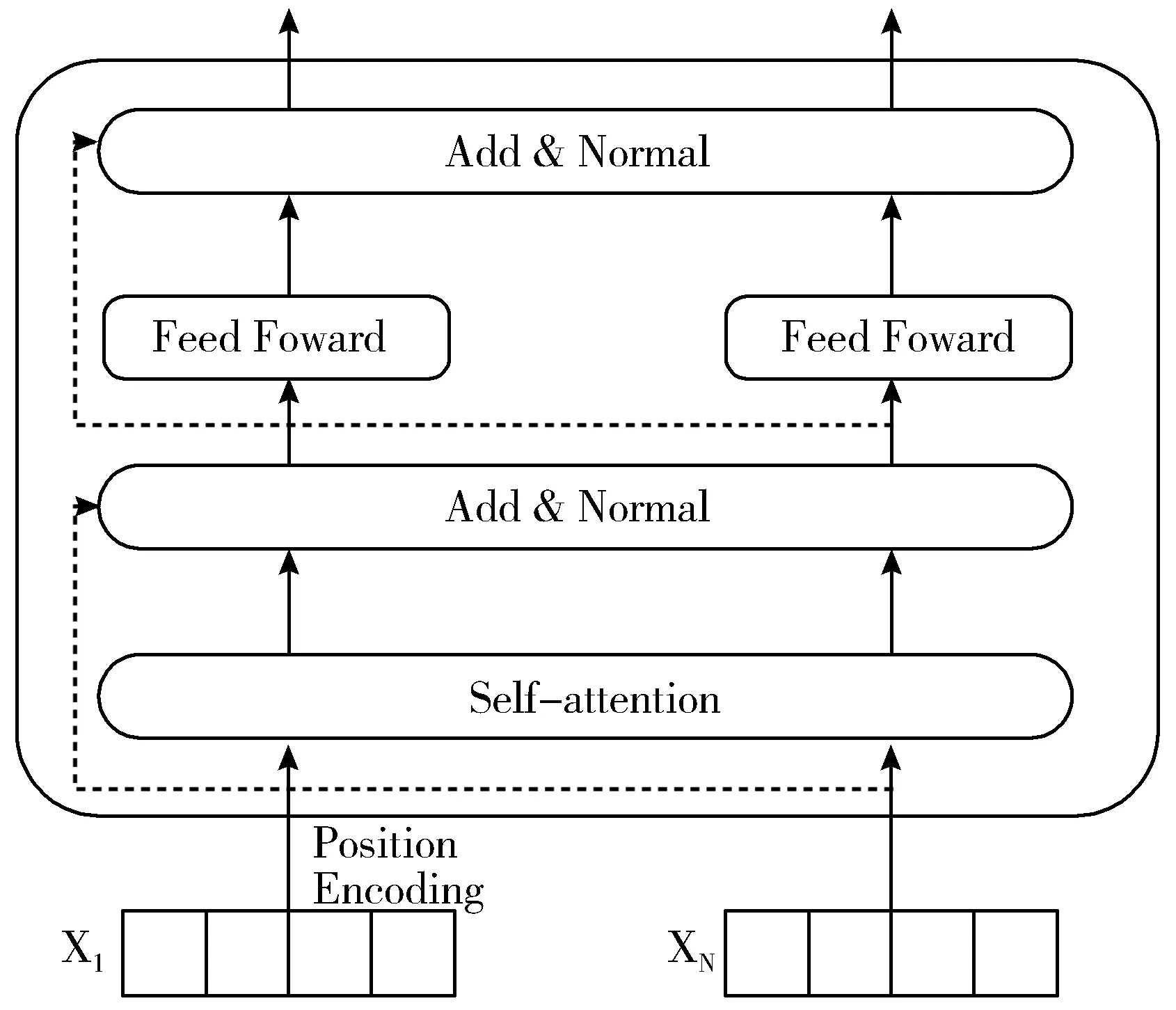
图3 Transformer编码单元
Transformer编码单元最主要的模块是自注意力部分。算法先对文章中的每一句话进行处理,计算出单个词与所有词之间的关系,而后根据词与词之间的相互关系得出不同词之间的关联性及该词在句子中的权重。因此利用这些相互关系来调整词的权重可以重新获得每个词的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。
BERT预训练语言模型与其他语言模型相比,可以充分利用词上下文的信息,获得更好的词向量表示,因此可以在一定程度上针对多义词区分表示。
2.2 Sequence-to-Sequence模型
Sequence-to-Sequence(Seq2Seq)模型[11]的出现最早可以追溯到2014年,当时主要用于机器翻译任务,而生成式摘要和翻译从深度学习框架下来看本质上是一样的,因此也可以采用Seq2Seq模型来生成摘要任务。Seq2Seq模型本质上是一种Encoder-Decoder框架,在生成式摘要中,模型首先使用编码器对原文进行编码[12],得到原文的向量化表示S,然后再用解码器对S进行解码,得到相对应的摘要。
在Seq2Seq模型中,输入是一段长文本,输出则是一段短文本。假设输入为x=(x1,…,xTx),Encoder的输入是由Word embedding[14]层对原文本中每个词编码后得到的词向量(xt)和上一个RNN cell的Hidden state(ht-1)组成,输出是这个RNN cell的Hidden state(ht),如公式(2)所示:
ht=RNNenc(xt,ht-1)
(2)
如图4所示,从Encoder开始,输入经过embedding层转换为词向量,然后进入LSTM层。LSTM会在每一个cell上输出Hidden state。如图中的h1~h8。
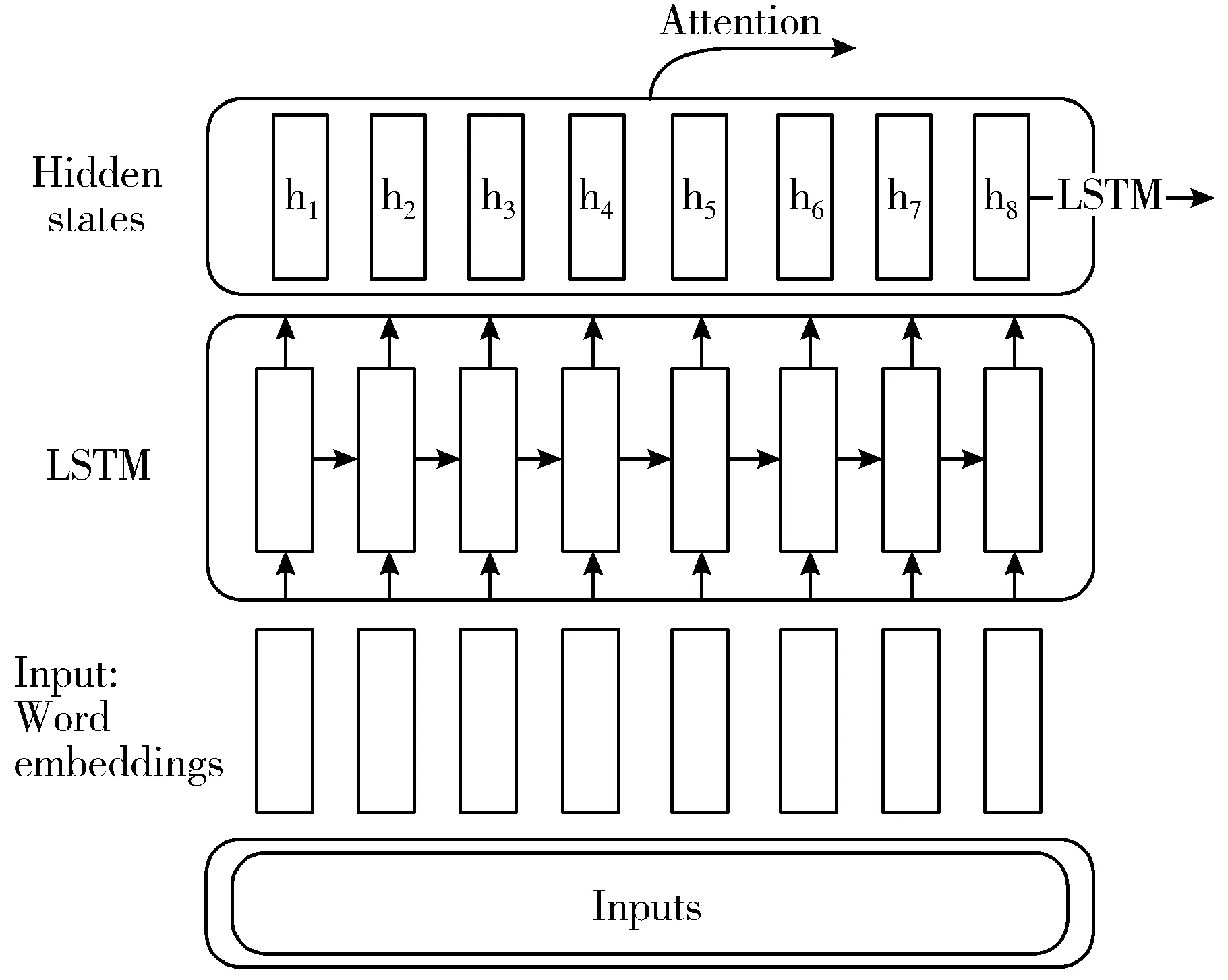
图4 Encoder图解
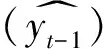
(3)
如图5所示Encoder的最后一个Hidden state:h8、Word embedding以及原始Context vector作为Decoder的输入,输出是Hidden state。
Context vector是对Encoder输出Hidden states的加权平均,如公式(4)所示:
(4)

图5 Decoder图解
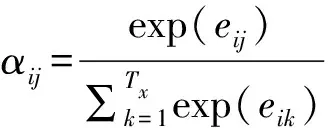

(5)
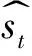
(6)
2.3 Attention注意力模型
Encoder-Decoder模型虽然非常经典,但是也有着需要固定语义向量长度的局限性。因此Encoder-Decoder模型中编码器需要对整个输入序列进行压缩,而这就会带来一些弊端,比如:压缩后的语义向量无法完整地表示原始的信息;原始输入内容携带的信息的重要性也可能会因为序列的压缩而降低。这就使得解码器在解码时一开始就没有获得全部的关键信息,从而导致解码时准确率的降低。
为了解决上述问题,本文采用Attention模型[17]。模型在生成输出时,会生成一个注意力范围来标记输入序列需要重点关注的部分,然后根据所关注的部分生成下一个输出。人们在阅读的时候,通常只会注意具有信息量的词,就是说人们对每个词所施加的注意力是有所不同的,而Attention模型就由此而来。Attention模型虽然会增加模型训练的难度,却能提升生成文本的效果。模型的大概示意图如图6所示。
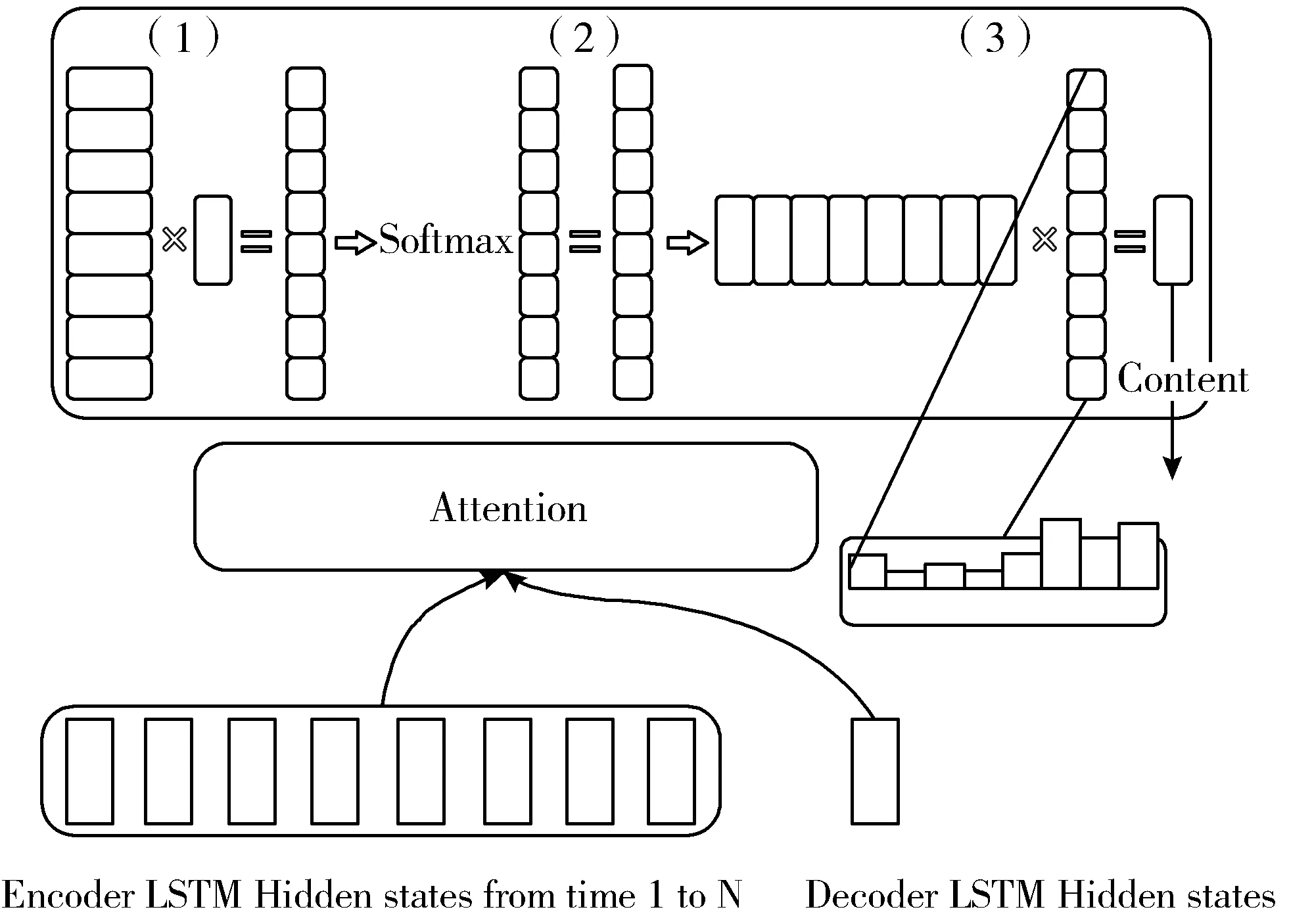
图6 Seq2Seq中的Attention
Attention层的输入是Encoder的所有Hidden statesH:大小为(Hidden dim, Sequence length)和Decoder在一个时间点上的Hidden states大小为(Hidden dim, 1)。
第一步:转置H为(Sequence length, Hidden dim)与s做点乘得到一个大小为(Sequence length, 1)的分数。
第二步:对分数做Softmax[22]得到一个和为1的权重。
第三步:将H与第二步得到的权重做点乘得到一个大小为(Hidden dim, 1)的Context vector。
3 实验及结果分析
3.1 实验环境
实验环境如表1所示。
表1 实验环境

操作系统GPUPythonTensorFlowCudaRougeUbuntuTesla P403.61.13.110.10.3.2
3.2 数据集
本实验采用的数据集是Gigaword,共包含接近950万条来自New York Times等多个新闻源的新闻语料,其中部分文章包含一句话新闻摘要(headline)。Gigaword数据集的数据规模如表2所示。
表2 Gigaword数据集规模
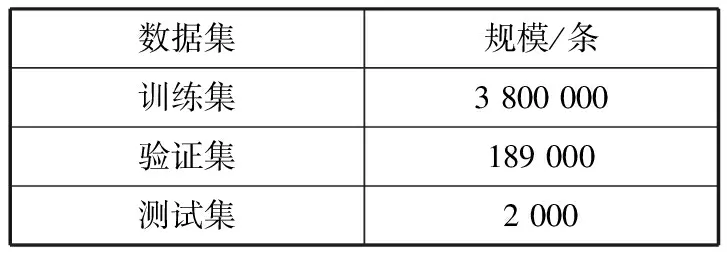
数据集规模/条训练集3 800 000验证集189 000测试集2 000
Gigaword数据集的特点在于原句和摘要句都是单个句子,而在实际应用中,除了对单个句子生成摘要的情形之外,还存在对由多个句子组成的整篇文本生成摘要的情形。
3.3 评价指标
评价方法上,采用DUC的ROUGE[23]评价准则对训练出的模型进行评测,该准则被广泛应用于文本摘要的生成效果评估,主要包括ROUGE-1、ROUGE-2和ROUGE-L。
3.4 实验过程
为了验证BERT作为embedding层的Seq2Seq-Attention模型的有效性,固定Seq2Seq-Attention的参数,采用不同的embedding层训练模型进行对比。
1)Word to Vector模型。它本质上是一种单词聚类的方法,基本思想是把自然语言中的每一个词语统一表示为一维的短向量,可以在百万数量级的词典和上亿的数据集上进行高效的训练,并且生成的词向量可以很好地表示词与词之间的相似度。但是Word2Vec语言模型有自身的缺陷,它只能根据文章中句子的上文来推测下文,或者根据文章的下文来推测上文,就是说传统的LSTM模型只能学习到单向的信息。
2)GloVe[24]模型。它可以把一个单词表达成一个由实数组成的向量,从而捕捉到单词之间的相似性、类比性等一些语义特性。相对于Word2Vec,GloVe算法更容易并行化计算、速度更快,但由于其使用了全局信息,所以内存开销也较高。
3)BERT模型。从模型或者方法的角度来看,BERT借鉴了ELMO、GPT以及CBOW,主要提出了masked语言模型和next sentence prediction。BERT可以解决其他词向量无法对多义词进行有效表征而降低文本摘要准确度和可读性的问题,并且BERT效果好、普适性强,几乎所有的NLP任务都可以套用BERT解决。
实验中采用的GloVe模型为Stanford开源的用Wikipedia2014和Gigaword5训练的glove.6B.100d,Word2Vec模型由Gigaword语料训练而来,BERT模型采用Google提供的BERT-Base,一共12层,隐层768维,采用12个Multi-head Attention模式,共1.1×108个参数。实验中,其他参数的设置为:num_units设置为256,learning_rate设置为0.001,dropout设置为0.2。
3.5 实验结果及分析
实验数据表明,BERT、GloVe和Word2Vec模型都在10个epoch左右的时候达到最优解。最优解时,从loss值来看,采用BERT模型的loss值最低,然后是GloVe和Word2Vec。从ROUGE评测结果来看,采用BERT的文本摘要算法在ROUGE-1、ROUGE-2、ROUGE-L上均得到了提升。实验中,模型的loss值随epoch的变化情况如图7所示。
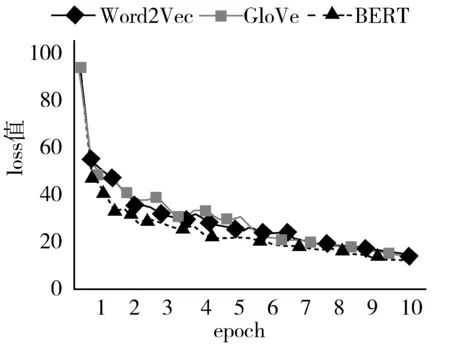
图7 实验loss值
BERT-Seq2Seq-Attention模型所生成的摘要效果如表3所示,对原文内容概括充分完整并且用到了原文中没有出现的单词进行概括,由此可见BERT在处理多义性时也有一定效果。
表3 BERT-Seq2Seq-Attention模型摘要示例

原文while trying to clear the way for u.n. fact-finders, u.s. sec-retary of state colin powell told congress wednesday he has no evidence of an israeli massacre of palestinians at the jenin ref-ugee camp on the west bank.标准摘要powell says he has no evidence that israel massacred palestini-ans生成摘要powell tells congress he has no evidence of israeli massacre
实验最终在ROUGE评价准则上的评测结果如表4所示。其中P代表准确率(Precision);R代表召回率(Recall);F代表F1分数值,是准确率和召回率的调和平均数。
表4 ROUGE评测结果
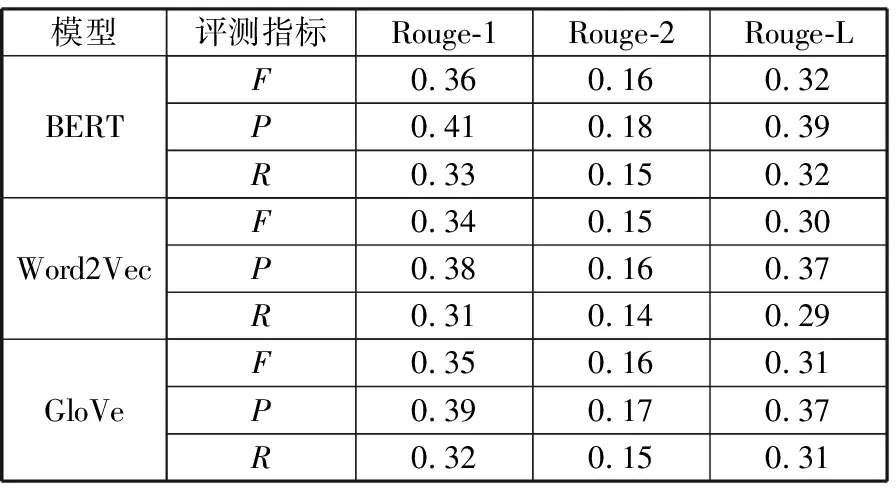
模型评测指标Rouge-1Rouge-2Rouge-LBERTF0.360.160.32P0.410.180.39R0.330.150.32Word2VecF0.340.150.30P0.380.160.37R0.310.140.29GloVeF0.350.160.31P0.390.170.37R0.320.150.31
从评测结果可以看出,采用BERT模型在F1分数值上,Rouge-1、Rouge-2、Rouge-L较Word2Vec分别提升了5.9%、6.7%、6.7%,较GloVe分别提升了2.9%、0、3.2%;在召回率上较Word2Vec分别提升了6.5%、7.1%、10.3%,较GloVe分别提升了3.1%、0%、3.2%;在准确率上较Word2Vec分别提升了7.9%、12.5%、5.4%,较GloVe则分别提升了5.1%、5.9%、5.4%。由此可见采用BERT模型可以更好地完成文本摘要任务。
4 结束语
本文提出了BERT-Seq2Seq-Attention模型来解决传统词向量在自动文本摘要中无法表征词的多义性的问题。该模型较Glove-Seq2Seq-Attention等模型,在提高生成摘要的准确率和可读性上都有一定的效果,ROUGE评测结果也较之前有一定程度的提升。
使用BERT与训练语言模型做编码层比传统的编码层更能表征语句的特征,但仍有许多不足之处,例如由标准摘要转换为向量时会产生信息的损耗;仁者见仁智者见智,人们对文章的理解不尽相同,标准摘要的侧重点也不同;深度学习方法生成的摘要仍存在句子不通顺、指代不明等问题。下一步的研究方向可以选择解决摘要中指代不明等问题以及对中文自动文本摘要进行改进,之后在情报分析等领域中加以应用,解决现阶段情报工作的情报数据更加多元化、情报价值获取更加困难、传统情报处理和应用模式无法满足应用需求等问题。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
新高考·高一数学(2022年3期)2022-04-28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
艺术评论(2020年3期)2020-02-06
电子制作(2019年22期)2020-01-14
制造技术与机床(2019年10期)2019-10-26
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年18期)2018-11-14
