
一种结合灰狼和FM算法的云端应用解构方法
2020-02-07 13:33姜凯华
计算机与现代化 2020年1期
姜凯华,孙 鹏,韩 锐
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190; 2.中国科学院大学,北京 100049)
0 引 言
随着物联网技术的飞速发展,智能终端已广泛普及至千家万户,并时刻生成海量数据。如何高效、即时地处理这些实时数据,已成为当今网络技术中亟待解决的关键问题[1]。在现有云计算架构中,产生自网络边缘的实时数据需通过互联网传输至远程云端服务器集中处理。由于云端和用户间网络结构复杂、带宽受限,海量数据长距离传输会加重网络负载,造成网络拥塞、服务延迟等问题;同时终端设备能耗和用户隐私安全等问题也不容忽视[2]。因此,传统的集中式云计算服务模式已经难以支撑网络边缘海量数据的实时处理。
为此,中科院提出了海服务的概念。海(SEA)服务是一种广域环境下的现场(on-site)、弹性(elastic)、自治(autonomous)的网络服务系统,通过将位于网络边缘的设备资源聚合抽象成服务平台,为用户提供即时高效的服务。当用户发出请求时,以接入节点为中心,利用节点的自治管理和协作,构建邻域响应集群,从而动态地为实时或准实时性服务请求提供高效响应[3]。
海服务利用靠近请求端的设备快速处理服务请求,为终端用户提供高效、现场的服务,适合局部数据处理和实时请求响应;而云计算则基于虚拟化技术,对服务请求实现时空弱约束的承载,适合全局数据汇聚和批量处理[3]。2种服务系统各有侧重,协同合作可将全局信息与局部信息分级处理,为用户提供多类型、多级别的服务,满足具有多等级用户体验和服务质量应用的需求。
在海云协同架构中[3],云端应用被解构成有依赖关系的子任务序列,并部署到海端节点上,其中解构指云端应用被拆分成子任务序列的过程。解构得到的子任务粒度直接决定任务部署策略的解空间大小,进而影响部署后任务在海端节点上的总执行时间;同时由于子任务间存在依赖关系,故依赖任务间的传输开销也会影响其排队等待的时间,进而影响服务完工时间。因此需要研究适合海云协同架构的云端应用解构方法,使解构子任务序列适配海端节点的资源分布,并尽量减少任务间的数据传输量,缩短等待时延。
1 云端应用解构
应用解构的概念最初来源于软件工程领域中功能模块“高内聚、低耦合”的设计思想。在面向服务架构(Service-Oriented Architecture)中,应用解构的定义是:将复杂软件的组件封装为离散、自治、自由接入的独立服务,从而达到灵活部署和屏蔽平台异构的目的[4]。微服务中,解构指将应用拆分成不同的微服务以提高模块性[5]。在海云协同架构中,应用解构定义为将云端应用拆分成有依赖子任务序列,以便在海端节点上部署和执行[3]。
现有应用解构方法主要应用于分布式系统部署场景。典型应用包括:
1)划分系统Coign利用中间件层在编译过程中拆分二进制代码段,实现应用解构[6]。
2)分布式计算引擎Spark采用弹性分布式数据集(Resilient Distributed Dataset)设置各基本操作间的宽窄依赖,进而划分操作对应的执行位置[7]。
3)边缘云计算范式Clonecloud将移动端服务拆分后迁移至云端[8],与海云协同场景中云端应用下放至网络边缘有相近之处。首先,Clonecloud根据预先设置的静态规则,从代码中选出开始拆分和重新合并的切入点;随后根据任务的执行流程,在切入点间将代码拆分成数段,建立调用关系树;最后将拆分后的子任务建立成任务成本图,将选择问题转化为图划分问题,并采用线性规划求解。
上述应用解构方法各自存在缺陷:Coign的拆分粒度过细,且需要人工设置代码段中断点;Spark采用的RDD只能实现粗粒度划分,且难以划分异步更新并共享状态的批处理应用;Clonecloud将终端任务迁移至云端,没有考虑云端的计算、存储开销和执行时间;而海云协同场景中,应用是从云端下放到边缘,终端开销、能耗和任务完成时间不可忽略。此外,现有应用解构方法主要针对简单图,负载均衡的定义是子划分中任务量相等[9];而海云协同场景中云端应用属于有向带权图,且海端节点异构性强、负载波动剧烈,负载均衡要求子划分任务规模匹配海端节点资源分布。因此,现有应用解构方法难以应用到海云协同系统中。
在海云协同场景中,云端应用规模动态变化,耦合程度高,其功能模块间的调用关系树需要用有向带权图表示[10],如图1所示。其中,顶点权重表示该模块对应任务的完工时间;有向边权重表示模块间传输的数据量。如此,可将应用解构转化为图划分问题,其优化目标表述如下:

图1 有向带权图示例
一方面,子划分中的任务规模应匹配海端节点资源分布,即划分子图中顶点权和与资源状况满足相同分布,才能保证任务部署时有充裕的解空间进行寻优。其数学表述如式(1)所示:
(1)

以子任务队列与分布曲线的相关系数表示其匹配程度,数学表述如式(2)所示:
min (ρC,R|C:{Vj|vj∈Ci},R:{rk|nk∈Nsea})
(2)
其中,C表示子任务序列,R表示海端节点资源序列;相关系数ρC,R越大,说明匹配程度越高,越有利于部署过程寻优。
另一方面,部署后节点间通信开销应尽量小,则划分后子图间边割权和与图的总边权之比、即割权比最小。其数学表述如式(3)所示:
(3)

2 结合灰狼和FM算法的解构方法
作为经典的NP-hard问题[11],图划分问题广泛存在于各种领域,目前业界的主流算法分别如下:
1)KL/FM算法。KL算法于1970年由Kernighan和Lin提出[12]。其原理是,在初始划分方案的基础上,在2个分区内找出一对可使划分边割减少节点进行交换,并标记已互换的节点,接着从分区内继续寻找未被标记的节点对互换,直至图内所有节点都被标记;随后以此次迭代得到的划分作为初始划分,进入下次迭代;重复迭代直至边割数目不再减少。在KL算法基础上,Fiduccia和Mattheyses提出FM算法[13]。每次迭代前,先计算节点移动后的移动收益并排出优先级队列;迭代中选择收益最大的一个节点移动,并将其从队列中删除。重复上述过程直至没有节点可以移动。由于每次只需要移动一个节点,FM算法的计算量远小于KL算法。
2)多层K路均分算法。该算法分粗化、初始划分和逆粗化3个步骤[14]:粗化根据图的最大边覆盖原则,将图中相近的点合并为单点。粗化重复迭代多次,直至粗化图粒度足够大。随后使用其他划分方法对最终粗化图进行划分。最后逆粗化将初始划分后的粗化图逐层映射回上层粗化图,并在各层粗化图上使用KL/FM等算法对已形成的划分进行局部优化,最终完成对整个图的划分。
3)启发式算法。启发式算法参照仿生学原理设计划分规则,收敛较快,全局性强,适用于大规模图的划分。Tao等人[15]采用模拟退火算法处理多路图划分问题;Farshbaf等人[16]引入遗传算法,在图划分过程中实现多目标优化。
然而,上述算法各自存在缺陷:KL/FM算法需要较好的初始划分、多层K路均分无法处理异构边缘设备、启发式算法不适应网络边缘规模的动态性。因此,需要研究适合海云协同场景的划分算法。在诸多启发式算法中,灰狼算法(Grey Wolf Optimizer, GWO)以其参数简单、快速收敛等优点受到广泛关注。灰狼算法模拟狼群的社会阶层和捕猎机制,将狼群分为α、β、δ和ω这4个等级,每头狼都代表一个可行解[17]。其中,α狼作为种群头狼,代表当前迭代中种群内最优解;β狼和δ狼分别代表次优解和第3最优解。其余可行解用ω狼表示。每次迭代中,ω狼根据头狼的引领更新位置,包围猎物,其数学模型表述如式(4)、式(5)所示:
(4)
(5)

(6)
(7)
各头ω狼的位置更新公式如式(8)所示:
(8)

虽然灰狼算法计算简单、求解快速,但仍存在着探索和开发过程转化不明显、易陷入局部最优的缺陷,不适用于求解图划分问题[19]。
灰狼算法全局性好、收敛快,但局部开发能力弱,易陷入局部最优;而FM算法的局部开发能力强,但性能受初始划分限制。因此,本文将灰狼算法与FM算法结合,扬长避短,优势互补,提出一种混合算法,其工作流程如图2所示。

(9)
其中,amax、amin分别表示非线性收敛因子的极大值和极小值,tmax表示最大迭代次数。相比线性收敛因子,cos 函数可保证前期的快速收敛,并在算法停滞时,快速提高随机因素权重,加快初始划分的生成。

图2 灰狼-FM混合算法工作流程图
另一方面,在位置更新公式中,灰狼算法中α狼、β狼、δ狼对ω狼位置的影响程度均等,限制了算法向当前最优解收敛的速度[21]。故本文提出一种变权重位置更新策略,如式(10)所示:
(10)
其中,距离当前搜索个体距离最远的头狼权重最高。变权重的位置更新策略,能有效提高算法的收敛速度,并加强算法早期的全局性[22]。
3 仿真实验
为测试本文提出的灰狼与FM算法结合的混合算法的性能,本文将混合算法与灰狼算法、FM算法以及基于权重的软件模块划分方法(Weighted Clustering Algorithm, WCA)进行对比。其中,应用的调用关系利用源代码分析工具Doxywizard得到;节点资源分布方面,由于海端节点的异构性和动态性,在长尾分布、双峰分布等多种分布模式中随机选择,特征参数依据工程经验设置[23];优化指标采用相关系数和割权比之差,数学表述如式(11)所示:
(11)
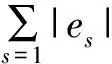
图3表示各算法在500次迭代中适应度值的变化对比。其中,混合算法和灰狼算法明显优于另外2种算法。混合算法在初始阶段收敛快于灰狼算法,说明改进的有效性;混合算法陷入停滞后,将解传递给FM算法继续开发,局部跳出能力有所提高,而灰狼算法则陷入停滞;图4表示各算法的割权比的对比。其中,混合算法的割权比持续下降,显著低于另外3种算法,大大降低了通信开销。

图3 各算法适应度值对比图

图4 各算法割权比对比图
4 结束语
海云协同系统中,应用解构方法严重影响服务质量。对此,本文提出了一种结合灰狼和FM算法的混合算法,利用灰狼算法快速收敛的特点和FM算法的局部开发能力,将灰狼算法的解作为初始划分输入到FM算法中。实验结果表明,混合算法的效果优于现有方法。划分后子图中顶点权和与海端节点资源分布相匹配,且割权比明显降低。说明解构子任务序列适配海端资源,且通信开销大大减少。
猜你喜欢
华人时刊(2022年5期)2022-06-05
小资CHIC!ELEGANCE(2022年1期)2022-01-11
金桥(2021年6期)2021-07-23
小学阅读指南·低年级版(2021年3期)2021-03-19
现代装饰(2020年5期)2020-05-30
小太阳画报(2019年1期)2019-06-11
现代装饰(2018年11期)2018-11-22
数学大王·低年级(2018年5期)2018-11-01
中国周刊(2018年4期)2018-05-15
快乐作文·低年级(2017年3期)2017-03-25
