
图像描述问题发展趋势及应用
2020-02-05 06:00马倩霞李频捷宋靖雁
无人系统技术 2020年6期
马倩霞,李频捷,宋靖雁,张 涛
(清华大学,北京100084)
1 引言
自媒体时代的繁荣催生了多模态深度学习。我们日常生活中所接触到的各大社交平台混合了文本、照片、视频等各种模态的信息。我们能够很自然的从这些混合模态中迅速得到有效信息,但对于智能无人系统而言,这个简单的过程需要融合多个人工智能领域的技术。人工智能领域的一个长期目标是开发能够感知和理解我们周围丰富的视觉世界,并能使用自然语言与我们进行交流的代理[1]。因此图像语义分析是人工智能中非常重要的一部分内容。这需要我们将计算机视觉(Computer Vision,CV)和自然语言处理(Natural Language Processing,NLP)两个相对独立的领域联合起来进行研究,实现一些在过去看来非常困难的任务,例如视觉-语义联合嵌入(Visual-Semantic Embedding)。视觉语义联合嵌入的一个典型应用就是图像描述生成(Image Caption)。这个对于人类而言很轻松的过程,却一直被视为人工智能领域一个极具挑战性的难题。2016年,图像描述问题研究成为IEEE 国际计算机视觉与模式识别会议(CVPR)上一个热门的专题。2020年CVPR 会议中,视觉和语言研究领域受到了广泛关注,与识别、检测、分割和姿态估计,半监督、无监督、迁移、表征和小样本学习,3D 计算机视觉与机器人,图像和视频合成并列成为本次会议的五大主题。
2 概述
多模态机器学习(Multi Modal Machine Learning,MMML)旨在通过机器学习的方法达到处理和理解多模态信息的效果[2]。模态(Modality)是指事物出现或者被感受到的方式。每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉、听觉、视觉、嗅觉;信息的媒介,有语音、视频、文字等;多种多样的传感器,如雷达、红外、加速度计等。以上的每一种都可以称为一种模态。本文所提及的多模态主要指多种信息媒介,现有的研究主要集中于以下三种感知模态(Sensory Modalities):视觉信息(图像、视频等)、音频(声音和伴随语言(paraverbal)等)以及自然语言(书面语言和口语等)。
多模态机器学习主要面临着五大挑战,包括表征(Representation)、翻译(Translation)、对齐(Alignment)、融合(Fusion)、联合学习(Colearning)[2]。这五大挑战并不是相互独立的,相互之间存在着密切的联系。如图1所示,多模态问题首先需要解决的往往是表征。Tadas 等将多模态的表征分为以下两大类,联合表征(Joint Representations)和协调表征(Coordinated Representations)[2]。联合表征将不同的模态嵌入到统一的特征空间,协调表征则在不同的空间先单独提取不同模态的特征,然后寻求这些特征之间的对应关系,这就涉及五大挑战中的对齐问题。“一图胜千言”“一千个观众心中有一千个哈姆雷特”,当我们需要表达同样的语义时,不同的感知模态所呈现的方式和量级不同,用户的学习成本和体验也截然不同。如何寻求一种合理且具有一定可拓展性的对齐方式成为多模态机器学习的一大难题。

图1 多模态机器学习核心挑战Fig.1 Core challenges in multimodal machine learning
图像描述问题(Image Caption)也称为图像标注问题,其实是一个视觉到语言(Visual-to-Language,V2L)的问题,融合了计算机视觉和自然语言处理,尝试用机器学习的方法完成图像到文本的“翻译”过程[3-4]。它研究的是在给定一张或是一系列的图像时,系统能自动给出每一幅图像的描述。描述需要包含图像中的主要物体、物体的主要特性以及场景等主要信息,可以理解为将一副图片翻译成文字描述。这就像是小朋友的看图说话过程,我们设计的系统需要能够将图像信息转换成为语言信息,一般来说是文本信息。这就需要机器不仅能够理解图像的语义,并且有一定的表达能力。同时,图像包含的信息量很丰富,所以我们还希望我们设计的模型能够作出合理的筛选。
对于人类而言,一般看到图像的第一眼我们就能顺利找到图片的主要内容并对其进行描述。但这个简单的动作对于智能无人自主系统而言却需要大量跨领域的人工智能技术。自动图像描述其实从原理上讲类似于场景理解(Scene Understanding)。模型不仅需要识别出图片中的物体,而且需要能够用恰当的自然语言表述出他们之间的相互关系。所以这个问题是一个涉及计算机视觉与自然语言处理两个方向的交叉领域,一直被认为是一个极具挑战性的人工智能研究问题。
图像描述问题的研究历史不过十年。但在这短短十年内,图像描述模型却经历了多次重大变革,从早期的分割成不同领域的问题单独研究逐渐转变为现在的端到端学习模型,深度神经网络(Deep Neural Networks,DNNs)的使用使得模型的性能得到了极大的提升。
在图像描述问题正式被提出之前,研究者们已经做了很多相关的研究,为图像描述奠定了坚实的基础。2009年,Li等将多示例学习的方法用到了图像感兴趣区域(ROI)问题上,取得了当时最好的定位效果[5]。早期图像描述的完成主要有两大类的方法:一种是基于物体识别和属性检测[6-8]。三元组常被用来作为图像的表示[9-10],这类方法只能识别具像化的物体,无法描述抽象概念。为了得到语法正确的描述语句,我们需要解决分词、歧义等问题。同时,借助语言模型产生的描述句式结构往往比较简单。多物体的检测也存在着诸多技术难点。另一种是将检索得到的相似图像的描述进行修改得到[11-12]。这种方法需要一个包含大量带描述的图像数据库,从而限制了实际的应用。后续一些使用的基于摘要技术的方法[13]类似于上述第二类方法。
图像描述是一种极具描述性和紧凑性的表示方法。神经网络的使用是该领域的一大突破。第一个使用神经网络来解决图像描述问题的方法是Kiros 等在2014年提出的。基于深度视觉模型和长短时记忆单元的多模态嵌入空间模型,可以完成检索排序以及图像描述任务[14-15]。此后,很多尝试专注于使用更深的神经网络[12]或者不一样的网络结构,如门控循环单元(GRU)、长短时记忆单元(LSTM)[16]、双向LSTM[17]和phi-LSTM[18]等。
考虑到深度学习的黑箱子问题,研究者们进行了很多高层次语义的研究。2017年,Yao 等微软亚洲研究院的研究人员们提出了基于属性的长短时记忆网络(LSTM-A)[19],在CNN 和LSTM 结合的模型的基础上加入了高级属性特征,借助弱监督的多示例学习方法来完成图像描述任务。Jiang 等在编解码器的结构基础上提出一种指导网络(Guiding Network)来添加图像的属性特征,使得解码器每个时刻不仅要考虑前一时刻的输出,还要结合指导网络的输出指导向量(Guiding Vector)来进行预测[20]。Rupprecht 等利用用户反馈的信息来更新卷积神经网络(Convolutional Neural Networks,CNNs)的激活值,从而在不重新训练网络的前提下就能提高模型的准确率[21]。2019年,Deshpande 等利用词性(Part-of-Speech)高层语义信息快速生成图像对应的文本,并增加了描述的多样性[22]。
基于注意力机制的Transformer 模型[23]在机器翻译领域取得了非常显著的成果。该模型摒弃了CNNs 和循环神经网络(Recurrent Neural Networks,RNNs),仅采用注意力机制提取每个语种文本内部以及语种之间的特征。近两年有不少将注意力机制引入图像描述研究领域的尝试[24-26]。其中Cornia等设计的M2Transformer 模型[24]基于Transformer 模型开发,采用多层注意力机制提取图像和文本的特征,并采用网状连接学习两者特征之间的联系。该模型取得了目前最领先的图像描述效果,成果发表于CVPR2020 上。同时,强化学习的多种决策方式和生成对抗网络也被用于图像描述问题的研究[27],增加了生成文本的自然性和多样性。
3 研究用数据集
我们整理了一些用于图像描述问题研究的比较经典的数据库,列于表1。近两年,许多经典的传统数据集都加入了不少新的内容条目,如ImageNet(谷歌、CMU、Cornell 大学合作完成的Open Images,目前已有第五个版本,包含约九百万张带有多标签的图像,横跨了大约6 千个类别,涵盖范畴是之前ImageNet的6倍)、COCO、CIFARs、SBU以及MNIST。当然,也有一批新的数据集进入了研究领域,如加州大学圣地亚哥分校和Adobe 提出的Stock3M 数据集包含3217654个用户在一个股票网站上上传的图片,每个图片都与一个描述相关,描述的平均长度为5.25 个单词,比MS-COCO 短得多[28]。场景分类数据Places2[29]、CMPlaces[30]和拓展后的SceneNet RGB-D[31]为场景识别提供了很好的数据资源。
近年来也出现了不少英语以外语种的图像描述数据集,如日语描述的STAIR Captions[32]、AI Challenger中文数据集等。
4 研究方法
这里我们对图像描述的一些主要方法进行介绍,其中的大部分是近几年比较常用的主流方法,也有一些是出现过且对后续的研究有较大启发性的模型。
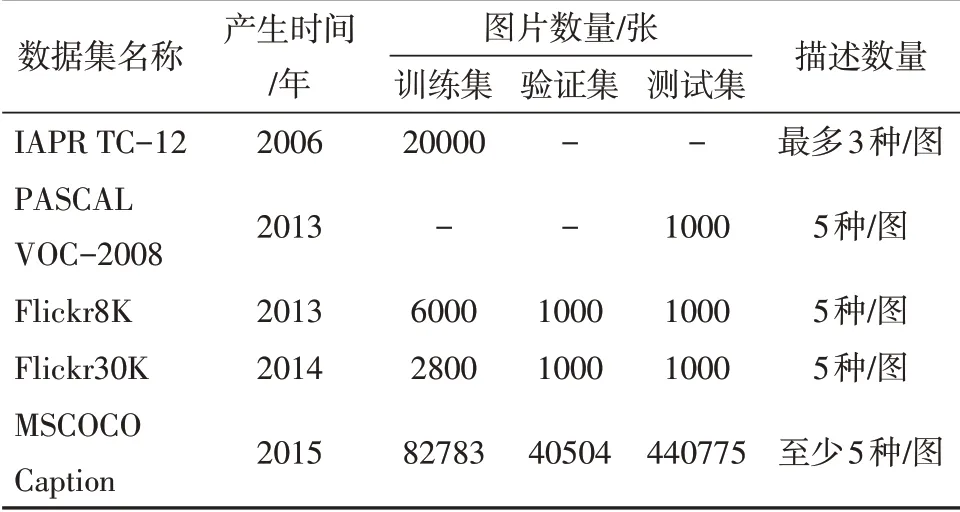
表1 图像描述常用数据集Table 1 Commonly used datasets for image caption
4.1 基于物体识别和属性检测
物体识别作为计算机视觉比较早期的研究取得了不少成就,也形成了很多方法。所以在图像描述问题研究的早期,研究者们自然而然地想到将整个问题分解成多个子问题。图2就给出了我们人类进行图像描述的一个简化过程:首先我们的视觉感官接受来自外界的图像信息,然后根据我们已储备的知识分别识别图像中的名词、动作、形容词、副词、介词等,进而组织成完整通顺的文本序列来进行表达。模仿这个过程,我们得到了基于物体识别和属性检测的模型。首先分别识别图像中的主要物体以及场景,然后再利用语言模型(通常借助于一些模版)得到一个完整的描述序列。随着物体检测和属性检测技术的发展,分别出现了三元组、四元组、五元组等表示。例如,简单的主语、谓语、宾语构成的三元组能够简洁明了地表述图像中的主体事件。
但这类方法存在着很多弊端。首先,它借助了物体检测,因此这种方法没有办法描述抽象概念。此外,由于这类方法需要借助于语料库来生成描述,能够表达的词汇范围非常有限。同时,完整序列的生成通常要使用模板,所以产生的句式单一,表达的多样性很受限制。
4.2 基于多示例学习的模型
多示例学习(Multi-Instance Learning,MIL)是Dietterich 等[33]在对分子活性的研究时提出的一种新的机器学习类别[34-36]。它有别于传统的三大学习框架——监督学习、无监督学习和强化学习。
包(bag)和示例(instance)是多示例学习中非常重要的两个概念。在数据集中,每一个数据称为一个包,每个包是示例的集合。对于数据集中的所有包,其正负类标记是给定的,但是示例是无标记的。由此可以认为多示例学习是一种介于监督学习和无监督学习之间的学习方法,但是它又不同于半监督学习。早期多示例学习被用于医学领域,如CT图会被标记为有无病症,如果有病症,那么其中必然有至少一个病灶区域。
这里有一个特殊的判别规则:只要一个包中有一个示例为正,则包为正;否则为负。例如,若CT中有一处病灶区域,则标记为有病症。只有当所有区域都正常时才标记为无病症。多示例学习的任务就是在给定一些有标记的包(这些包中的示例无标记),预测新的包的标记。解决这一问题通常采用迭代优化的方式我们先假设已经知道了所有样本的标记,那么就可以通过某种监督学习的方法进行预测,然后更新标记,这些重新得到的标记又可以成为新的训练样本来更新模型。具体实现方法有很多,从最初Dietterich等提出该方法时给出的三个基于轴平行矩形的方法[33],到后来的Diverse Density[37]、Citation-kNN、ID3-MI、RIPPER-MI、BPMIP[38]、DD、EM-DD[39]以及SVM、神经网络、条件随机场方法等。Noisy-OR 版本的MIL 模型[40-41]采用了目标检测的方法。
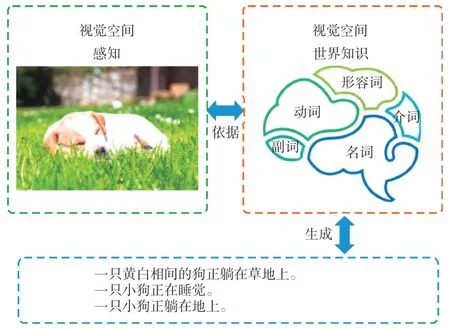
图2 人类生成图像描述过程示意图Fig.2 Image caption process by human beings
4.3 编码器-解码器结构模型
神经机器翻译模型中的大部分模型采用编码器-解码器机制,编码器从输入中提取特征后保存在一个定长的向量中,然后解码器将向量中的特征信息进行提取解码得到输出。序列到序列(sequence-to-sequence,seq2seq)学习最早是由Cho等在2014年的论文中提出的,其实就是基于两个RNNs 的编码器-解码器模型。seq2seq 问题采用的神经网络主要是RNNs。后续的不少模型改用性能更好的RNNs,如GRU[42]、LSTM、双向循环神经网络(bi-RNNs)、回声状态网络(ESNs)。
百度是第一个设计基于CNNs 和RNNs 的多模态模型进行图像描述任务的[43]。Mao 等百度研究院的研究员们采用RNNs 替代了正向传播网络,首次提出用CNNs 和RNNs 结合的多模态模型来解决图像标注、图片和语句检索问题,后常被简称为m-RNNs 模型[43],网络结构如图3(a)所示。其后的大部分尝试都是在该模型基础上进行的改进优化,如使用更深的神经网络等,但主体思路基本是一致的。如2014年,谷歌的Vinyals 等设计了NIC 模型(如图3(b)所示)。由于图像信息并不随着时间而变化,该模型只在初始时刻输入图像特征[44]。
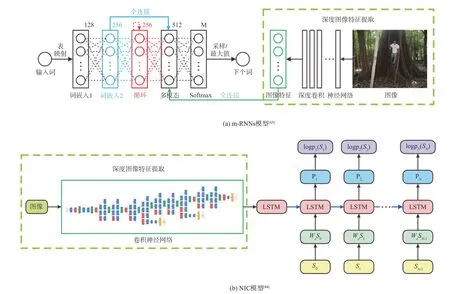
图3 编码器-解码器模型Fig.3 Encoder-decoder models
4.4 注意力模型
2015年以前,神经机器翻译模型大部分采用编码器-解码器机制[42,45],编码器从输入提取特征信息后保存在一个定长的向量中,然后解码器将向量中的特征信息进行提取解码得到输出。这种机制的一个主要瓶颈在于一个定长的向量所能保存的信息量有限,随着输入序列的长度增加,将所有有效信息都集成到一个定长的向量就显得越困难,因此机器翻译的效果也大幅下滑[42]。由此引入了注意力机制[40]。注意力模型能在不同时刻关注输入的不同位置,从而提升预测的准确率。
基于注意力机制的模型成为了近两年研究的热点,2014年DeepMind 首次提出的神经图灵机采用了一种基于软注意力的寻址机制,由于完全可微,模型可以借助梯度下降进行端到端学习[46]。注意力机制是一种对齐机制,使得每个时刻模型可以更多地关注相关信息,从而弱化噪声信号的干扰,提高性能。软注意力机制在其他应用中也有着突出的表现,如自然语言处理中的机器翻译[47]。2015年,Sukhbaatar 等在Weston 的记忆网络基础上设计的基于循环注意力机制的记忆网络,实现了端到端的训练。为了提高计算效率,硬注意力机制产生了作用[48]。但由于不可微,采用硬注意力机制的模型没有办法直接进行反向传播从而更新参数,为此研究者们进行了各种尝试。
图4所示为谷歌用于seq2seq问题的Transformer模型[23]。该模型完全抛弃了CNNs和RNNs,编码器部分和解码器部分都仅借助于注意力机制完成。这一机器翻译模型也给图像描述问题提供了新思路。
注意力机制建立的是一个对应关系,这种对应关系可以是图像特征之间的、不同语言之间的、图像与文本之间的,也可以是文本与语音之间的。
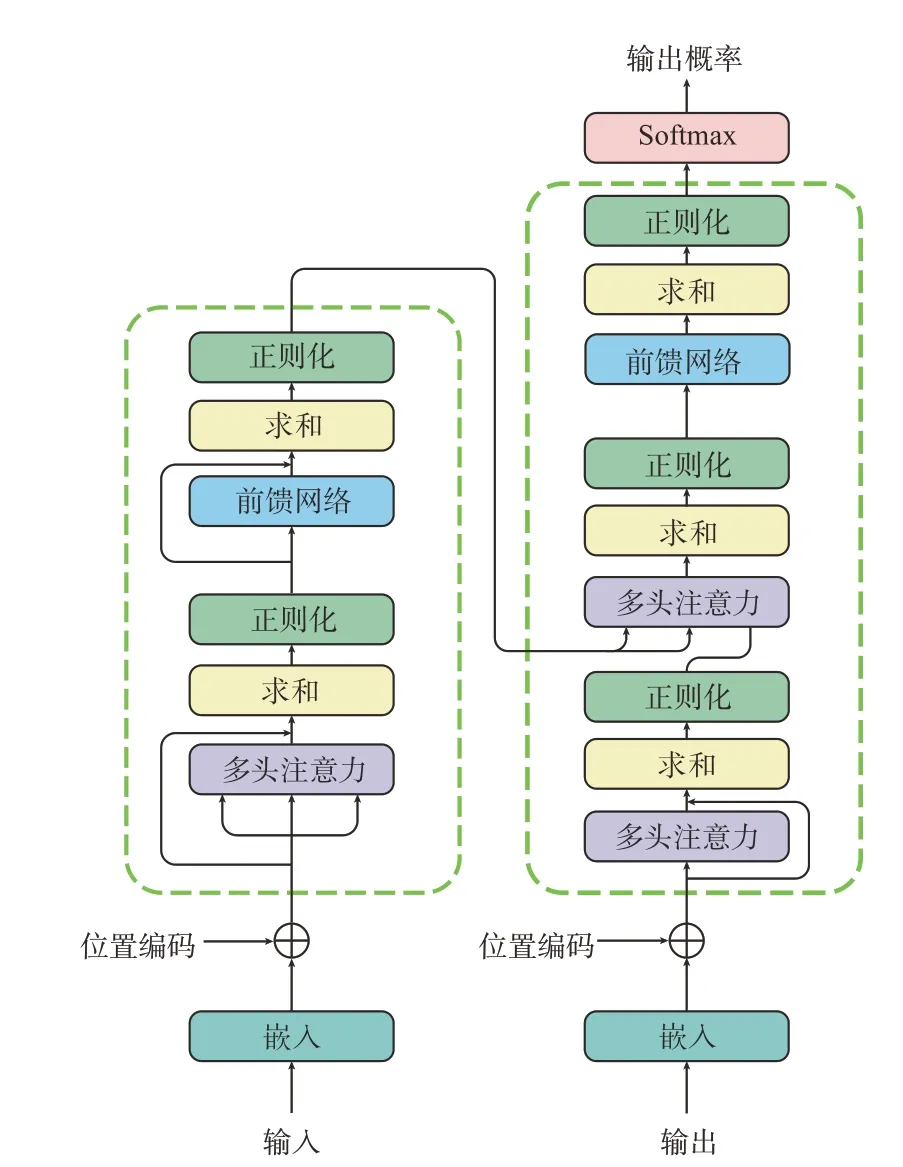
图4 Transformer模型[23]Fig.4 The Transformer model[23]
4.5 强化学习模型
最常用的编码器-解码器架构常使用CNNs 和RNNs 分别处理图像和文本信息。这样的方式存在两大弊端,首先,训练时每一时刻RNNs的输入是标签中的单词(即上一时刻的理想输出),而测试时生成模型的输入是上一时刻的预测结果,由此引入了曝光误差(Exposure Bias)。在测试和实际使用模型时,预测误差不断累积。这一点在长序列的环境中表现尤为显著。其次,该类模型将图像描述问题看作是一个分类问题,常借助交叉熵损失函数来进行训练。但交叉熵损失函数要求评价标准可以进行微分运算。训练时的损失函数与测试时的评价标准之间存在不一致的问题。
强化学习将图像描述问题看作是一个决策问题,每一个决策都包含一系列的动作。强化学习通过引入决策网络和奖励函数的方式来构建一种新的决策框架。为了防止前期搜索空间过大,可以使用交叉熵损失函数和强化学习损失函数相结合的方式来开展训练:训练的前期使用交叉熵损失函数,然后逐渐加入强化学习损失函数。
Dai 等使用MSCap 通过在生成器加入风格指示生成特定风格的图像描述[49]。Dognin 等在训练判别器时使用自约束序列训练法(Self-Critical Sequence Training,SCST)解决了离散和不可微的问题,性能优于Gumbel 直通训练法(Straight-Through,ST)且更稳定[50]。Li 等使用自下而上,注意力机制(BottomUp Attention)进行图像表征,并借助自注意力(Self Attention)获取不同区域特征间的关系,从而构建全连接关系图[51]。该方法将完整的句子和图像映射到同一个嵌入空间,由此得到两者的相似性。但与此同时,强化学习的一些算法所存在的搜索空间大、难以收敛、鲁棒性差等问题也随之而来。
4.6 生成对抗模型
早期的图像描述研究生成的文本描述基本为中性,且描述单一、句法简单。为了丰富生成图像的多样性,生成对抗网络(Generative Adversarial Networks,GANs)也被用于图像描述问题。
如图5所示,GANs主要由生成器和判别器两部分组成,两者的训练交替进行。在生成器部分,我们可以采用上述的基本模型进行描述的生成。在判别器部分,我们可采用不同的标准进行评判。这种评判可以包含描述是否为模型生成的“虚假”描述,图文对是否匹配等。为此,我们需要设计相应的损失函数,也可以准备不同类型的正负训练样本来辅助上述功能的实现。
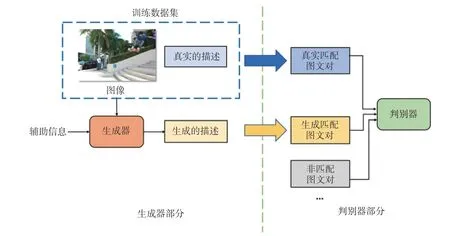
图5 生成对抗模型框架Fig.5 Framework of generative adversarial networks
4.7 混合模型
近几年也出现了不少基于两种及以上上述模型相结合的模型。如在编码器-解码器结构上添加高层语义特征信息来提高模型的效果。强化学习中的梯度下降等算法解决了生成对抗模型中的离散问题。
5 应 用
图像描述实现了从图像自动获取目标文本的功能,智能处理视觉信息并采用自然语言进行表述,是无人智能系统理解环境并与环境交互的一个重要环节。该技术在很多领域都有着重要的应用,如图像检索、儿童教育、视力受损人士的生活辅助、医学图像分析、智慧城市、移动智能终端等[2]。我们对于常见的图像描述应用进行了整理总结。
图像检索:图像描述技术与图像检索是一个平行对称的过程。统一的模型能通过语义对齐迅速找到匹配概率排在前几位的结果。我们这里所说的图像检索指的是通过输入描述文本检索得到符合描述的图像的跨媒体搜索过程。如何从海量的大数据中快速得到需要的有效信息是大数据分析的一大挑战。图像检索通过提取输入信息的深层语义信息,进而从数据库中检索得到最符合描述的图像[52]。人物侧写、跨模态行人重识别、商品检索等都是日常生活中的常见应用场景。
教育领域:图像描述可以理解为一个“看图说话”的过程。在儿童教育、视力受损人员的教育上,图像描述技术能提供大量图像-描述样例,同时也能对作答的问题进行自动验证。
医疗辅助:对于视力受损人士,图像描述可帮助理解图像内容,从而实现生活辅助的目的。图像描述技术将视觉信息转化为自然语言,可借助于文本生成和语音生成技术,通过文本或者语音的方式输出给用户。
医学影像分析:传统医学影像的报告生成完全依赖于医护人员的专业医学知识。然而,大量的医学影像分析需要投入巨大的人力物力,且X 光片、CT 等影像中存在着较大比例的正常样本,即影像中不存在病灶区域。图像描述技术能够直接对输入的医学图像生成诊断结果,大大节省了医护人员的时间。同时基于DNNs的图像描述模型能保证较高的识别准确度,可用于早期筛查、诊断等评估场景,有望从一定程度上缓解医疗资源分配不均的问题。已有研究将图像描述模型用于目前全球肆虐的新型冠状病毒(COVID-19),通过胸部CT[53]和X光片[54]分析对新冠病毒进行筛查。
新闻媒体:早期的图像描述问题研究者就将目光投向了新闻报道。网络媒体上存在大量的新闻报道,其中包括新闻配图,以及与这些图片相对应的标题和文字描述。通过引入这些带标签的图像-标题-描述三元组数据作为训练数据,我们可以得到新闻报道自动生成系统。随着训练样本数量和主题多样性的增加,生成的报道能接近人为创作的报道。同时,如果能在此基础上引入不同的风格特征,无人系统生成的文本也将具有不同的文字风格。
智能交通:无人驾驶系统离不开环境视觉信息的语义理解。车载的传感器接收到路况的图像信息后进行特征提取,最终得到实时的周围环境信息。另外,对于交通图像数据的集中分析能帮助决策管理部门及时地掌握城市路况信息[55],实现紧急事件的有效、高效处理。
其他应用:图像描述问题是结合视觉信息和自然语言的交叉问题,图像描述技术可拓展应用于类似的领域。例如在视觉空间,我们除了图像,还可以处理视频问题。在自然语言领域,也可用于机器翻译、语音生成、语音识别等。
6 发展趋势
6.1 端到端学习
传统的系统通常分多个阶段进行处理,需要投入大量的人力和时间进行预处理和中间阶段数据标注工作。端到端的深度学习可以用一个神经网络来表示整个系统结构,训练时输入为整个系统的原始输入,网络的输出直接是最终输出,训练过程的参数更新由网络输出和真实值计算得到。端到端学习训练得到的是输入与输出之间的映射关系,它的引入大大节省了时间和人力。
6.2 高层语义
正如其他深度学习领域的问题,图像描述也面临着“黑箱”难题——即模型不具备较好的可解释性。尽管DNNs在很多领域都取得了喜人的应用效果,我们尚且无法用现有的数学理论给出很好的定量解释。因此现有研究大多停留在语言描述和实验说明阶段,可解释性成为了DNNs 的一个灰色区域。对于可解释性的探究将极大地促进我们发现模型问题的根源,辅助训练过程。目前已有一些研究进行了这方面的尝试,这些实验都一致地给出了如下结论:当在现有模型基础上融合高层语义后,模型的准确性有了提升[56]。
6.3 链式结构向层级结构的转变
在层级结构中,底层的网络捕捉相邻词之间的依赖关系,高层的网络则用于捕捉远距离的关系[57]。与RNNs 等链式结构相比,分层结构能够在更短的距离内捕捉长距离的依赖关系。以CNNs为例,我们如果使用大小为k的核,则仅需O(n/k)就能得到窗口大小为n的各词之间的依赖关系,而RNNs 则需要O(n)。这样既可以解决序列变长的问题,又可以实现在不同序列位置的并行计算,可谓一举两得。
另一方面,目前大部分的图像描述模型都是基于编码器-解码器结构,可以拆分成图像部分和描述生成部分两块,最常用的神经网路分别是CNNs和RNNs。如果能用一种结构类型的网络来统一处理不同模态的信息,模型的可拓展性将有极大的提升。
6.4 注意力机制
大脑的信息处理能力有限,注意力机制是一个用来分配有限的信息处理能力的选择机制,具有强大的数据筛选能力。换句话说,如果我们大脑的信息处理能力不是有限的,可以在极短的时间内理解并表达所有内容,那么注意力就变得毫无意义了。同样的,计算机处理信息的能力也受很多物理因素的限制,所以注意力机制在图像描述问题中的广泛应用势必成为一大趋势。
视觉注意力机制使我们暂时只关注最感兴趣的部分,图中其余的都成为背景,减少了噪声信号的干扰。同样的,在自然语言处理中注意力机制也发挥着不可替代的作用。以机器翻译为例,如我们要将一个英语句子翻译成中文,那么对于每一个中文字符,都存在着一个或是多个英文单词与之存在密切联系。所以在预测每个中文字符时可基于注意力机制找到最想相关的原文部分,从而大幅提升翻译的准确率。
6.5 统一架构
现有的大部分方法采用不同的模型或网络架构处理不同模态的信息,需要开发多套独立的特征提取模型。多模态的联合表征存在着巨大的挑战。如果采用统一的架构来处理图像、视频、文本等不同的模态,将输入嵌入到统一的特征空间,算法的可拓展性和迁移能力将大大提升。
7 结束语
图像描述作为多模态学习的典型问题,需要我们结合计算机视觉、自然语言处理、机器学习等多领域的技术和知识。现有的模型逐渐摆脱了早期基于目标识别方法和模板生成文本的限制,基本都采用编码器-解码器结构。同时DNNs 的引入实现了端到端学习,大幅提高了训练效率,在BLEU、METEOR、CIDEr、SPICE 等评价指标上都能得到较高分值。由于DNNs 缺乏较好的可解释性,高层语义特征的引入一定程度上增加了模型的可解释性,对于提升图像描述模型的性能有显著的作用。同时,为了增加模型的可拓展性,不少研究开始着眼于寻求统一的框架处理图像和文本这两个不同的感知模态。
然而,该问题仍面临诸多挑战——“一图胜千言”,不同模态的信息所能包含的信息量如何找到一种对应关系,如何用一句或几句话来概括一张图像中的主要内容需要我们作出合理的筛选。这也是多模态机器学习中的一大挑战——模态对齐问题。注意力机制能够更好地找到不同模态之间的对应关系。同时,图像描述问题也面临着计算机视觉和自然语言处理等领域各自存在的挑战,如遮挡、低像素、抽象概念目标识别等问题。此外,目前常用的评价标准均借鉴机器学习等领域的评价标准,然而图像描述问题有其特殊性,如何找到一种更适合图像描述问题的自动评价标准也是值得探讨的问题。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电影新作(2014年1期)2014-02-27
