
无人车地面目标识别及其优化技术研究
2020-02-05 06:00:32张洵颖赵晓冬裴茹霞张丽娜
无人系统技术 2020年6期
张洵颖,赵晓冬,裴茹霞,张丽娜
(1.西北工业大学无人系统技术研究院,西安710072;2.西安格儒电子科技有限公司,西安710077)
1 引言
在现代战争当中,无人车通过搭载各类型传感器,可以实现战场信息的实时监测。无人车上较为常见的传感器类型包括可见光传感器和红外传感器,通过可见光数据集和红外数据集分析,可以实现地面目标种类和位置的识别。机器视觉技术的发展,为无人车高精度自动识别地面目标提供了新的技术实现途径。机器视觉技术通过将视觉模块引入机器,可以使得机器获得丰富的外界信息,从而大大提升机器与外界环境之间的交互能力。通过将无人车技术与机器视觉技术结合,可以显著提升无人车的自主目标识别水平。
研究机器视觉技术在无人车上的应用,不仅具有重要的理论意义,也同时具有极为广泛的军事应用价值。目前已经应用于军事化的无人车,普遍缺乏智能因素的支持。若能有效解决智能算法在无人车上的技术创新及应用问题,将使得无人车可以更好地适应复杂环境下的多类别地面目标智能识别需求,从而提升无人车的军事化智能程度。
随着人工智能技术的和大数据的发展,基于深度学习的目标识别方法取得了瞩目成绩。基于卷积神经网络(Convolutional Neural Network,CNN)的目标识别算法,其识别准确率已经超越人眼水平。目前主流的基于CNN 的识别算法,大致分为两大类,基于区域建议的方法和基于回归的方法。前者错误率低,识别速度较慢;后者直接产生目标的类别概率和坐标,更加符合实时性要求,同时准确率也可以满足需求。
基于区域建议的识别算法包括区域建议型卷积神经网络(Region-CNN,R-CNN)[1],以及在此基础上不断改进得到的Fast R-CNN[2]和Faster RCNN[3]。R-CNN 系列算法的发展,体现了深度学习自主识别算法从开创到实现端对端之间映射的发展过程。随着算法不断发展,又相继出现了区域建议型全卷积神经网络(Region-based Fully Convolution Network,R-FCN)[4]及其改进算法。基于回归的方法包括只看一次(You Only Look Once,YOLO)[5]系列算法及单点多盒探测(Single Shot MultiBox Detector,SSD)[6]系列算法,以及在此基础上不断改进得到的YOLO9000[7]、去卷积单点探测(Deconvolutional Single Shot Detector,DSSD)[8]、YOLO V2、YOLO V3[9]和YOLO V4 等算法。相比SSD 系列算法,YOLO 系列算法从检测速度与精度两方面获得了均衡的识别结果。
智能算法复杂度的高低,直接决定了智能算法对于硬件资源需求的大小。典型的深度神经网络结构在相应参数结构下的计算数量统计情况如表1所示。其中,乘积累加(Multiply Accumulate,MAC)运算数目和权值大小是极为重要的两项参数,可直接反映硬件资源的需求量。MAC数目合计越大,代表所需的硬件乘累加操作越多;权值大小合计越大,代表所需存储空间越大。

表1 典型CNN的参数及MAC计算数量统计Table 1 Statistics of parameters and MAC calculation quantity of typical CNNs
从表1 可以看出,神经网络对于硬件资源的较高需求与嵌入式硬件资源特点存在显著矛盾。为了解决这一矛盾,不断改进的神经网络算法[10-14]及基于神经网络的压缩算法[15-17]应运而生。网络压缩算法通过各种数学模型、基于优化思想,在精度损失较小的情况下减少网络参数,从而降低算法对于硬件的资源需求量,最终协助完成智能算法在嵌入式平台的部署。经典的研究成果主要包括神经网络裁剪、神经网络量化、核的稀疏化、低秩分解、轻量化网络设计、低位量化等。核的稀疏化是指在训练过程当中对权重更新进行诱导,采用更加紧致的存储方式,其在硬件上的执行效率不高;低秩分解是指将卷积核视为张量,并对张量进行分解从而消除冗余信息,其对全连接层效果较为明显,对于卷积层效果不佳;轻量化网络设计通常采用不同卷积方式,减少模型参数;低位量化使得网络精度损失较为明显,无法在提高推理速度的同时保持精度。最适于硬件实现的方法主要包括神经网络裁剪和神经网络量化。
本文首先分析评估了目前基于CNN 的各类识别算法对于硬件资源的需求量,具体包括基于区域建议的方法和基于回归的方法,指出YOLO V3算法在精度和速度两方面更加适用于高精度识别要求时的硬件加速。其次,对YOLO V3算法的网络结构进行了具体分析,提出了双正则项自适应裁剪优化算法和面向FPGA 的神经网络INT8量化优化算法。最后,基于Xilinx 公司UltraScale+MPSoC 系列的XCZU7EV 器件验证平台,以及无人车拍摄的真实可见光数据集和红外数据集,实现了识别及优化算法的仿真验证,并对两类数据集的精度损失情况和硬件加速比情况进行了总结评价。
2 CNN识别算法硬件资源需求评估
针对目前主流的基于CNN的识别算法,进行硬件资源计算量的统计,具体统计情况如表2所示。

表2 基于CNN的识别算法资源计算量统计Table 2 Resource calculation statistics of recognition algorithms based on CNN
从表2 可以看出,针对不同的识别算法网络结构,硬件资源需求各不相同。从实际识别性能角度讲,YOLO V3算法从精度和速度两方面均衡的角度取得了较为理想的效果。目前在实际应用中更多采用YOLO V3系列的Tiny网络,资源计算量约为完整算法的1/13,识别性能较差,无法适应高精度识别要求时的多目标分类场合应用。所以如何将YOLO V3 这类识别效果较为理想的复杂网络算法应用至嵌入式平台领域,是亟待解决的难题。
3 YOLO V3网络结构分析
YOLO V3 网络共计107 层,在特征提取时采用了Darknet53 的网络结构,同时借鉴残差网络的思想建立层间的连接。YOLO V3 网络独有的组合式卷积形式如图1所示。
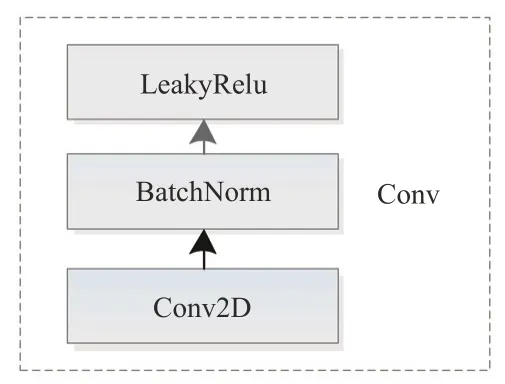
图1 YOLO V3网络的组合式卷积形式Fig.1 Combined convolution form of YOLO V3 network
其中,Conv2D 层、BatchNorm 层及LeakyRelu层,可视为统一的卷积处理层,一起构成YOLO V3网络独有的最小组件。
当网络输入图像的大小分别为416 × 416 和608×608 时,所需的硬件详细资源统计量如表3所示。表3 中所列举出的详细的资源统计量,代表了YOLO V3网络对于硬件资源的需求,可作为硬件设计的参考。

表3 YOLO V3网络硬件资源及其在两种输入分辨率下的资源大小一览Table 3 Hardware resource statistics of YOLO V3 network
YOLO V3 网络的三层输出特征图参数如表4所示,在输出特征层的基础上,结合上采样获得最终并置层,并进行多目标的分类与位置回归。其中,输出层1用于检测较为大型的目标,输出层2用于检测较为中型的目标,输出层3 用于检测较为小型的目标。

表4 YOLO V3网络三层输出特征图参数Table 4 Parameters of three layer output characteristic diagram for YOLO V3 network
YOLO V3 网络的边界框预测示意图如图2所示,当预测边界时,假设cx和cy是相对于特征图预先划分方格左上角的距离,并且每个单元格的长度是1,即cx= 1,cy= 1。边框预测计算过程如公式(1)所示,计算结果为边界框坐标值bx、by、bw和bh,即边界框相对于特征图的位置和大小。


图2 边界框预测示意图Fig.2 Bounding box prediction sketch map
为了加速学习过程,同时简化参数的数据处理过程,在网络学习过程中,真正的学习目标是tx、ty、tw和th。其中,pw和ph代表预设的anchor box 映射到特征图中的宽和高,即手动设置的anchor 宽和高。tx和ty代表预测的坐标偏移值,tw和th代表尺度缩放,分别经过sigmoid函数,输出0~1之间的偏移量,与cx和cy相加后得到边界框中心点的位置bx和by。tw和th分别与pw和ph作用后得到边界框的宽bw和高bh。Sigmoid 函数σ(tx)和σ(ty)分别将变量tx和ty映射到[0,1]区间内,从而确保目标中心处于预测网格单元中,防止偏移。
4 神经网络双正则项自适应裁剪
神经网络裁剪过程如图3所示,通过剪枝、剪神经元的方式,借助最优计算,可以在对网络裁剪的同时,保持网络模型的精度。
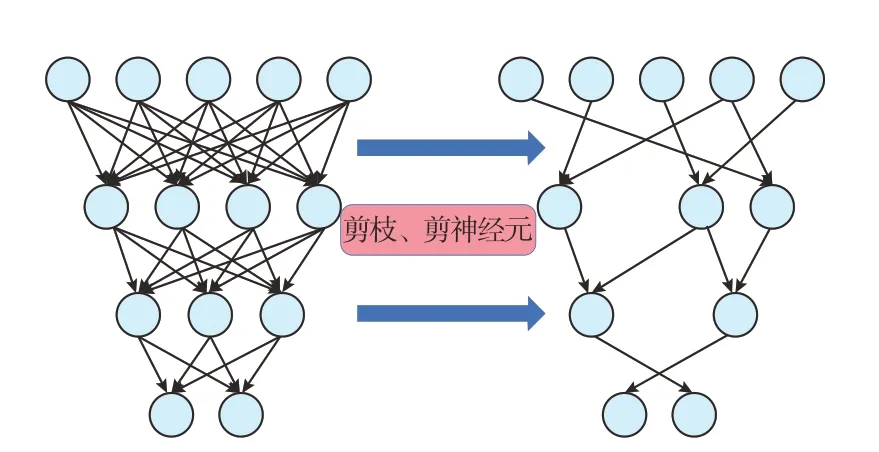
图3 网络结构裁剪前后的对比示意图Fig.3 Comparison of network structure before and after pruning
较为基础的裁剪方法是裁剪滤波器。裁剪滤波器是一种先裁剪后重新训练的方法,通过阈值设定裁剪掉每层当中较低权值的连接,从而有效降低模型复杂度。

裁剪滤波器的表示方式如公式(2)所示,其中ω代表阈值,i和j代表卷积核的维度。对每层中滤波器权重绝对值大于经验阈值ω的权重项进行保留。
裁剪滤波器实现较为容易,但是裁剪后的网络性能相对较差,经验阈值较难设定。为了使得裁剪过程与训练过程协同计算,本文提出一种自适应的网络裁剪算法,通过将注意力模块[18]与BatchNorm层缩放因子组合,以正则化方式实现自适应的最优裁剪。
注意力模块由全局池化层、全连接层和激活函数组成。将注意力模块的输出称为注意力缩放因子,注意力模块变换过程如公式(3)所示。
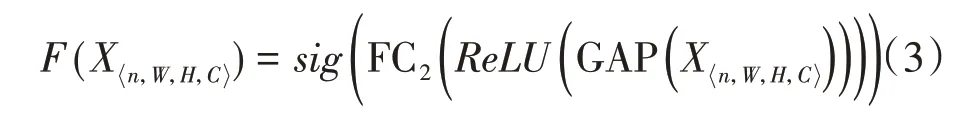
(1)通过公式(3)计算注意力缩放因子,获得能够衡量通道重要性的参数,缩放因子越小,代表对应通道越不重要;
(2)将注意力缩放因子与BatchNorm 层缩放因子同时作为优化约束策略,在L1 正则框架下,将两类缩放因子同时归入目标函数,并进行稀疏化训练。目标函数如公式(4)所示,第一项代表网络代价函数,第二项代表注意力缩放因子正则项,第三项代表BN层缩放因子正则项,α和β分别代表两项正则项在优化过程中的系数;

(3)进行训练与裁剪的协同计算,并反复迭代从而获得最优的裁剪后网络。裁剪与训练协同计算流程如图4所示,通过微调,可以较快收敛到最优网络;通过反复迭代,可获得更高的压缩比。
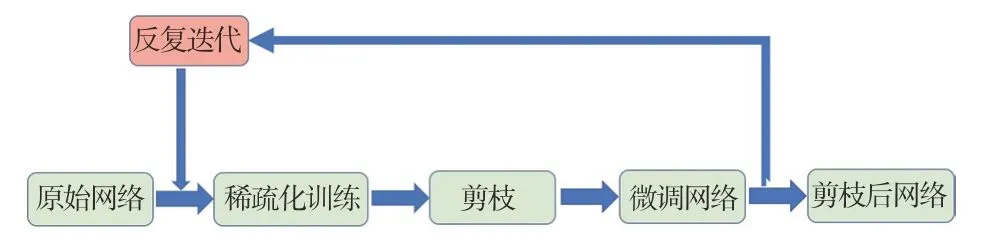
图4 裁剪与训练协同计算流程图Fig.4 Collaborative computing flow chart of pruning and training
网络裁剪的核心目的是在保持网络精度的前提下,对网络进行压缩。本文所提出的神经网络自适应裁剪算法,可以显著保持裁剪后的网络精度,适用于ARM 或FPGA 等各类嵌入式平台部署前的网络裁剪。
5 面向FPGA的神经网络INT8量化
目前最为高效的基于FPGA的神经网络量化方式是INT8 量化。INT8 量化是指将训练时使用的32bit 计算模式,用较少的8bit 模式进行存储和推理计算。相比Fp32 浮点型运算,INT8 量化方式可以减少4 倍的位宽。INT8 量化算法分为不饱和映射和饱和映射两种方式,不饱和映射是指将权重数据量化到[-127,127]范围中,这种方式将导致精度的较大损失。饱和映射是指通过各类算法计算,获得最优阈值并将映射到±127 范围中。超过阈值的部分,将被直接映射到±127。饱和映射示意图如图5所示。
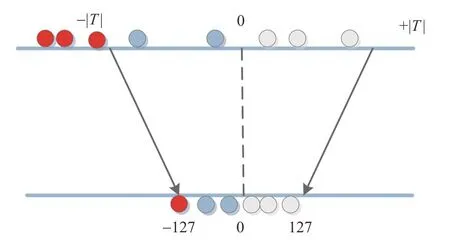
图5 饱和映射示意图Fig.5 Schematic diagram of saturation mapping
这两种基于映射的量化算法,都不能获得最优的INT8量化结果,原因在于统一的、最优的阈值很难通过优化算法进行选择,因此精度容易出现较大损失。本文提出一种面向FPGA 的神经网络INT8 量化方法,其主要思想是将原始32bit 权值模型量化为与其差值最小的2 的幂次方形式或0,并通过不断迭代训练的方式,逐步全局收敛到最优量化结果。其权重量化范围的具体选择策略如下:
(1)通过公式(5)计算量化过程参数,其中,s代表具有最大绝对值的权值,m代表量化位宽上限,b代表量化位宽,Pij代表量化后的2 的幂次方形式或0,Wij为卷积核,i和j代表卷积核的维度;

(3)在训练过程中,采用两组相同权重同步训练、每组组内逐步细分分组训练的方式。首先,将两组相同权值同步分为相同的两部分,并在各组内根据经验阈值设定不同的量化步长及训练参数,基于公式(5)同时对两组细分后的一部分做量化;
(4)在每轮量化完成后,对比两组量化后的参数,将量化后不一致的权重部分重新视为未量化部分,进行新一轮的迭代求解过程,从而获得局部更优的量化结果,在此基础上,进行反向训练更新;
(5)在各组内参数反向更新时,只更新未做量化的部分;反复迭代步骤3 和步骤4,直到各组内所有参数全部量化完成。量化后的所有权值,可直接在FPGA 上进行移位计算,大大加速了神经网络在FPGA上的执行效率,可以获得较高的加速比。
本文提出的神经网络INT8 量化算法,可以显著保持量化后的网络精度。全精度浮点运算直接替换为移位操作的方式更加适用于FPGA平台上的量化加速。
6 仿真验证
为了验证本文提出并应用的神经网络压缩算法在硬件平台上的加速能力,硬件仿真验证平台采用Xilinx公司UltraScale+MPSoC系列的XCZU7EV器件来实现基于CNN 的无人车地面目标识别加速器硬件研制及程序部署。在该硬件实现中,控制程序运行在XCZU7EV 片内集成的Cortex-A53 上,计算加速逻辑利用FPGA 实现,验证平台参考结构图与实物图分别如图6~7所示。
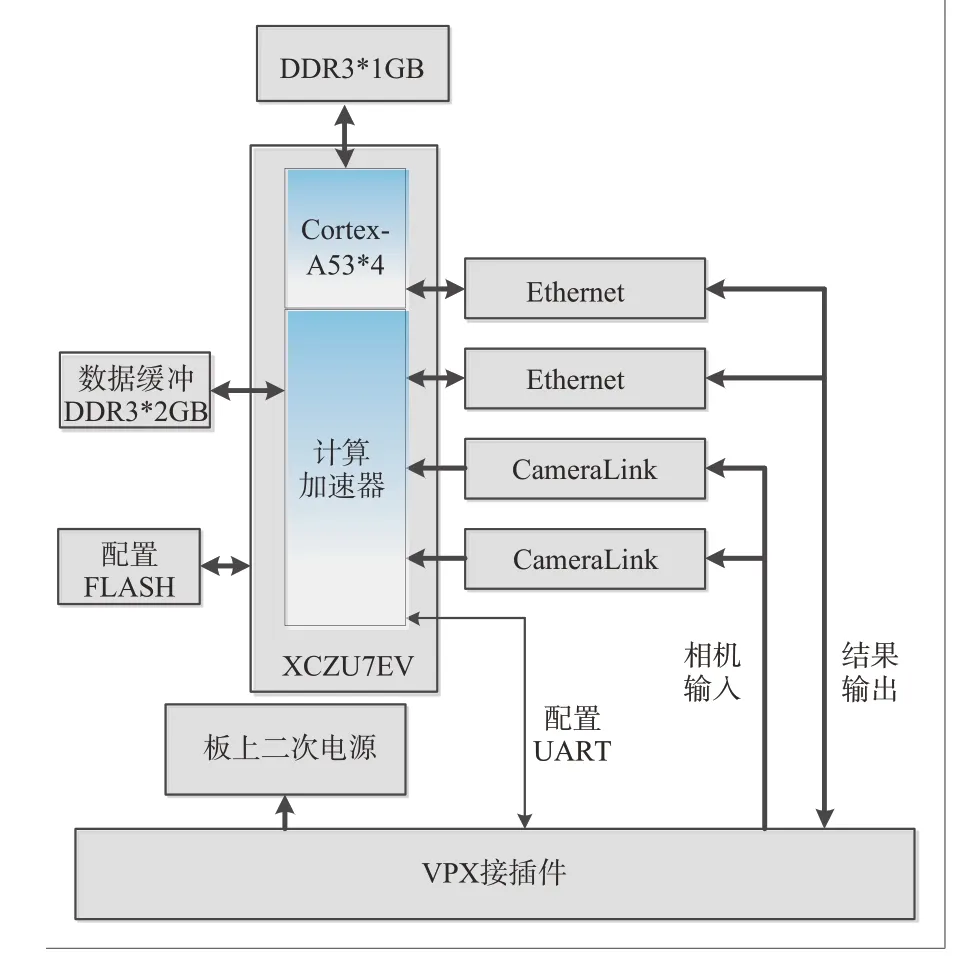
图6 验证平台参考结构图Fig.6 Reference structure diagram of verification platform

图7 智能算法硬件加速器Fig.7 Intelligent algorithm hardware accelerator
在基于无人车拍摄的真实可见光数据集和红外数据集训练的基础上,对本文所提出的神经网络优化算法进行验证。其中,可见光数据集包括训练集7200 张,测试集800 张;红外数据集包括训练集3250 张,测试集350 张。数据集中的所有图像,均进行了目标位置及种类标注。可见光数据集和红外数据集,各自共计5 个种类,分别包括坦克、汽车、越野车、装甲车和卡车。
首先,利用初始权重计算其对应的mAP值。然后,利用裁剪及量化优化算法进行算法优化,并针对算法优化后的权重,重新计算新的mAP值。在算法优化过程中,经过10 次裁剪与量化仿真测试,选取最优的仿真结果进行具体参数的设置及应用,网络裁剪及量化前后的精度仿真验证结果如表5所示。表5 中的结果均是多次程序执行后所选取的最优结果,图像输入分辨率为416×416。
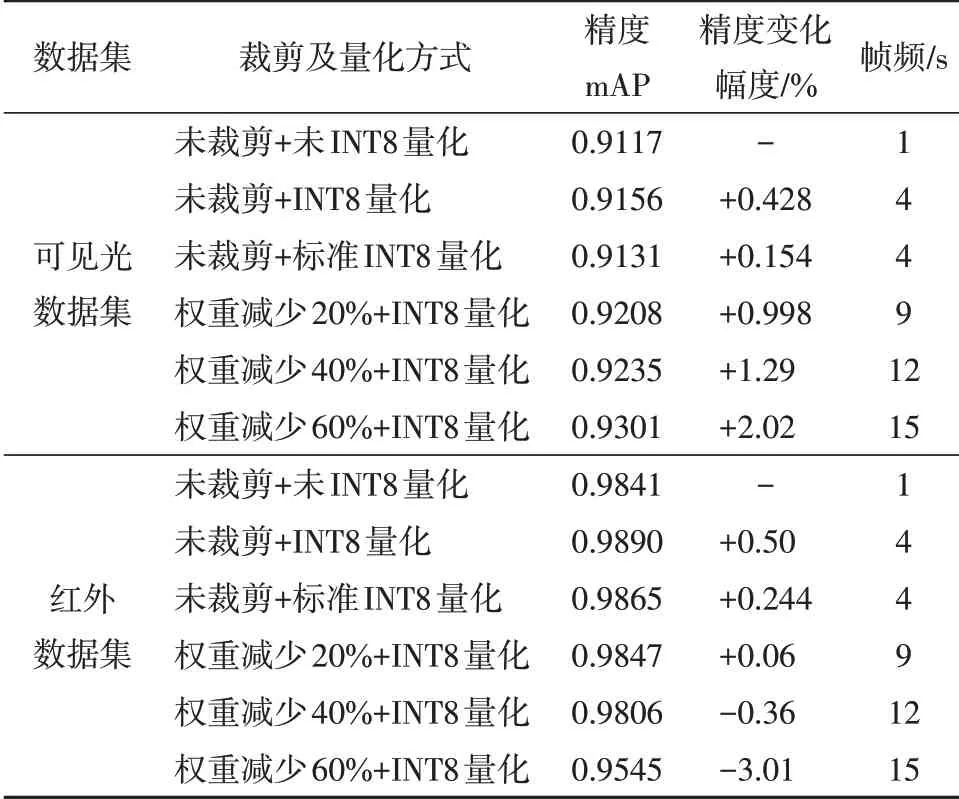
表5 YOLO V3算法裁剪量化前后精度及速度对比Table 5 Accuracy and Speed Comparison of YOLO V3 before and after Pruning and Quantification
从表5 中的验证结果可以看出,针对可见光和红外数据集,未裁剪和未INT8 量化时的帧频数为1,在不同的裁剪系数和INT8 量化组合形式下,帧频数的提升倍数有所不同。此外,随着裁剪力度的不同,裁剪及量化后精度的变化情况均有所不同,且不同的数据集,表现出了不同的变化情况。网络裁剪会直接改变网络的结构,自适应裁剪算法针对不同的卷积层,根据最优原则自适应地进行网络裁剪。有些卷积层的通道数目变小,有些卷积层的通道数目则保持不变。
针对可见光数据集,裁剪力度为20%、40%和60% 时,精度变化分别为+0.998%、+1.29% 和+2.02%;针对红外数据集,裁剪力度为20%、40%和60%时,精度变化分别为+0.06%、-0.36%和-3.01%。在裁剪力度为20%、40%和60%时,帧速率可达9、12和15帧/s。
基于可见光数据集的典型场景目标识别结果如图8~9所示。其中,图8 为裁剪及量化前的识别结果,图9 是裁剪60%及INT8 量化后的识别结果。

图8 裁剪及量化前的可见光目标识别结果Fig.8 Target recognition results of visible light image before pruning and quantification
基于红外数据集的典型场景目标识别结果如图10~11所示。其中,图10为裁剪及量化前的识别结果,图11 是裁剪60%及INT8 量化后的识别结果。
经过裁剪的网络,某一类的AP 值变化情况,与mAP 值的变化情况不一定呈现一致状态。由图可以看出,尽管在裁剪60%的前提下,mAP 下降了3.01%,但是truck类别的AP值上升,所以相比未裁剪和量化前的目标识别结果,裁剪后多识别出了truck类目标。mAP值的下降,说明其中多数类别的AP值呈下降趋势。

图9 裁剪60%及INT8量化后的可见光目标识别结果Fig.9 Target recognition results of visible light image after pruning with 60%ratio and INT8 quantification

图10 裁剪及量化前的红外目标识别结果Fig.10 Target recognition results of infrared image before pruning and quantification

图11 裁剪60%及INT8量化后的红外目标识别结果Fig.11 Target recognition results of infrared image after pruning with 60%ratio and INT8 quantification
7 结论
针对416 × 416 分辨率的输入图像,采用基于Xilinx 公司UltraScale+MPSoC 系列的XCZU7EV 器件验证平台,利用本文提出的裁剪及量化算法优化后的YOLO V3网络进行实时推理,在保证精度的情况下,网络实时推理速率可达到15 帧/s。与原始YOLO V3 网络在基于GPU 的嵌入式Jetson TX2 平台上执行的3.3帧/s结果相比,经过裁剪及量化,推理速率获得了4.5 倍的加速比,能够满足无人车地面目标识别的精度要求与实时性要求。
本文提出了针对CNN的压缩优化算法,并完成了硬件加速器平台的开发及验证。本文所提出并应用的神经网络裁剪及量化算法技术,可以实现神经网络压缩及硬件平台嵌入式应用。基于所提出的裁剪及量化算法,结合嵌入式硬件平台部署应用,有助于实现自主可控的神经网络加速器研制。此外,本文提出的网络压缩优化思想,可扩展并应用于各类智能硬件平台,从而方便地实现算法扩展及复用,仿真验证分析结果表明:
(1)基于CNN 的目标识别算法,其硬件资源计算需求量均可通过计算获得。针对某一具体算法,在嵌入式硬件部署前,可以通过资源计算分析,合理进行资源配置,从而选择更优、更适合的嵌入式硬件平台。
(2)本文所提出和采用的神经网络自适应裁剪算法、面向FPGA 的神经网络INT8 量化算法,在网络精度损失较小的前提下,相比原始网络在Jetson TX2平台上执行的3.3帧/s结果,获得了4.5倍的推理速度提升。本文的优化算法思想,对针对不同硬件平台的神经网络优化技术应用,提供了新的技术思路。
本文的下一步研究方向,是基于FPGA 平台的进一步程序优化及硬件优化[18-21],并探索更为先进的针对CNN的算法级优化技术,更好地实现深度学习目标识别算法的应用部署,为无人车地面目标识别提供进一步的技术解决方案。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
小哥白尼(军事科学)(2019年2期)2019-04-17 02:17:28
小哥白尼·趣味科学画报(2019年12期)2019-02-28 11:55:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
岷峨诗稿(2017年4期)2017-04-20 06:26:43
新高考(英语进阶)(2017年12期)2017-02-26 11:37:34
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
