
电网企业指标数据质量提升应用研究与实施
2020-02-04 02:03缪新萍汪浩葛松
电子技术与软件工程 2020年20期
缪新萍 汪浩 葛松
(1.贵州电网有限责任公司信息中心 贵州省贵阳市 550003 2.贵州电网有限责任公司 贵州省贵阳市 550002)
指标是指示、衡量目标达成的参数,在企业的经营、管理以及决策过程中起着十分重要的作用。指标数据的可信和准确直接关系到企业能否制定恰当的管理措施、做出正确的经营决策。
指标数据的产生,通常是基于一些基础数据、经历一个复杂的统计和计算过程得到。因此,指标是典型的派生类、加工类数据,指标数据的质量依赖参与加工处理的源数据及实施计算的过程。从数据治理的角度,指标数据质量的提升和保障应当正本清源,通过指标溯源追溯其源头数据,同时对源数据项进行数据职责的分配和落实,从源头施治确保数据项的质量,进而保证指标数据的质量。
本文针对贵州电网企业指标实用化工作推进的需要,在提升指标数据可信和准确性的质量问题上,阐述结合数据溯源与数据认责技术方法的研究与实施,实现提升企业指标数据质量、促进企业指标实用化的一个可行、有效的方案。
1 指标数据质量依赖
指标数据是反映企业经营运行状况的重要指针,同时也是进行管理决策的重要依据。根据南网公司加强企业数据资产管理,推动公司经营决策数字化转型的重要决定,正在大力建设和推广业务运营指标监控系统等一批数据应用,以期提供及时、准确、可信的数据参考和支撑。同时,指标数据也已经成为指导各部门按照精益化管理要求开展年度业务工作的重要指挥棒。
电网企业的指标数据通常是基于多个单位和部门的若干个数据元按照一定的统计口径进行计算而得到,因此指标数据的真实性和准确性有赖于这些数据元的质量状况,同时这些数据元又因业务活动的不断开展而处于不断变化之中。指标数据与相关指标数据元形成了一个相互关联、影响的金字塔结构,处于这个结构中的每个指标数据元的质量波动都将对顶端的指标数据造成影响。
因此,一方面,对指标数据的相关数据元进行溯源管理,理清指标数据的数据脉络成为评估指标可信度和影响的重要依据;另一方面,指标数据元的质量管控成为保障指标质量的重要基础。
2 数据溯源
数据溯源(data provenance)的概念大致诞生于20世纪90年代,最初命名各异,如数据族系(Data Lineage)、数据系谱(Data Pedigree)、数据来源(Data Origin)等。经历一段时间的发展完善,大部分文献将其命名为数据溯源,有追踪数据的起源和重现数据的历史状态之意。至此,数据溯源开始作为正式术语使用。
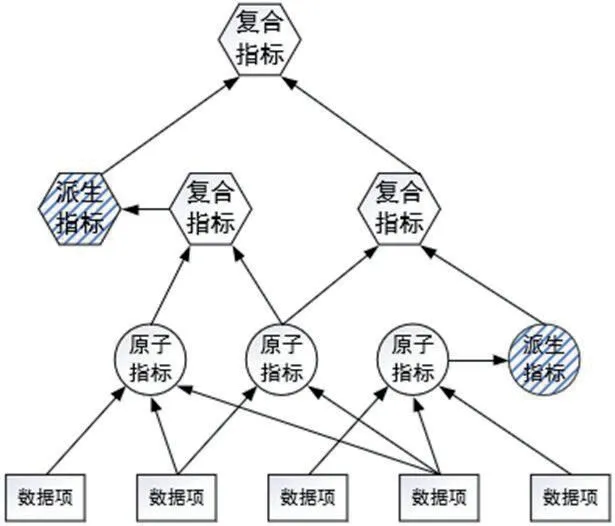
图1:指标数据依赖关系示意图
目前,数据溯源还没有公认的定义,因应用领域不同含义有所差别。Goble 从生物信息学角度指出,数据溯源除了要追溯目标数据的源头数据和过程信息外,还需记录数据演变过程中涉及的工具信息,需要更加详细的信息记录以保证数据的可重用性[1]。Lanter在GIS 中将其定义为,数据溯源是对目标数据衍生前的原始数据以及演变过程的描述。Greenwood 等认为数据溯源是一种记录信息的派生路径和注释的元数据[2]。Simmhan 等也认为数据溯源是一种元数据,用于记录数据产品最原始数据和演变转换过程的信息[3]。Glavic 等认为数据溯源包括两方面,一方面是将数据项的溯源描述为导致其创建的过程,另一方面则关注派生数据项的原始数据来源[4]。戴超凡等比较系统地研究了数据仓库系统中数据溯源追踪技术,将数据溯源定义为记录数据在整个生命周期内(从产生、转换、传播到消亡)的演变信息和演变处理内容[5]。
上述定义展示了数据溯源的不同侧重点,但均关注两个重要内容:数据本源(即源头数据),以及数据随时间推移而演化的整个过程。因此,可以将数据溯源概括为追溯数据的原生数据和衍生过程。
在大数据环境中,数据的生成规模、传播速度急剧增长,数据的来源以及衍生路径呈现出多样化、复杂化的特点,许多数据不是直接观察、测量获得,而是通过计算机程序的应用从其他数据中得到。原生数据常常经过多次流转、迁移、集成、抽取、计算等操作后形成海量派生数据。如果不对原生数据的溯源信息进行记录,将在很大程度上降低数据的真实性和有效性,以致给数据的应用带来风险。数据溯源正是为评估数据的真实性、增加数据信任、再现数据生成过程提供了必要的基础和手段,数据溯源技术应需而生。
图2:认责数据管理

图3:认责计划管理
图4:认责关系建立
指标数据就是典型的经原生数据计算、加工转化而来的派生或衍生数据。对指标数据进行数据溯源,是保障和提升指标可信性、准确性的必要前提。
3 指标数据溯源
数据溯源应用广泛,涉及食品安全、历史考古、科学研究、生物医疗、数据开放共享等对数据真实性、可靠性要求较高的领域。针对不同的应用场景、不同的应用目的,溯源的目标和内容是不同的。指标数据溯源,首先从应用目的出发来分析和确定其溯源的内容和目标。
3.1 指标数据依赖关系
指标,具体来说就是业务统计报表中的一个字段,比如售电量、应收电费等。一个指标具体到计算加工,主要涉及几个部分:

图5:认责关系维护

图6:认责工作管控
(1)指标计算逻辑,比如count,sum,avg 等;
(2)维度,指定不同值对象的描述属性或特征,比如按部门、地域进行指标统计,对应SQL 中的group by;
(3)业务限定、修饰词,比如以不同的时段来进行指标统计,对应SQL 中的where 子句。
除此之外,指标本身还可以派生、衍生出更多的指标,基于这些加工特点,可以将指标进行分类:
(1)原子指标:基本业务事实,没有维度、没有业务限定,表达业务实体原子量化属性的且不可再分的指标,如用户数、工单数都算原子指标。
(2)复合指标:建立在其它指标之上,通过一定运算规则形成的指标,如资产负债率(由负债总额和资产总额两个指标计算得到)。
(3)派生指标:某个指标与维度、统计属性、管理属性等业务限定相结合产生的新指标,如当期售电量(加上时间限定),主营业务收入(加上业务属性限制)等。复合指标也可以派生出新的指标。
不同分类指标之间、以及指标与源数据项的依赖关系示意,如图1所示。
3.2 指标数据溯源目标
实际业务统计中直接使用原子指标的情况是很少的,绝大多数都为派生类或复合类指标,且指标间的关系要比上述指标数据依赖关系示意图更复杂,也就是说大多指标数据的生成需要经历复杂的计算加工过程。
指标数据溯源的目标,就是要以指标数据为顶端向下拆解,梳理和绘制出指标数据依赖关系图,进一步挖掘和追溯到参与指标计算的相关源数据项,确定源数据项所在的应用系统、数据表及数据字段,掌握指标源数据项在业务系统中的分布情况。
通过指标数据溯源梳理得到的指标数据依赖关系图,呈现了由源数据项到指标数据的衍生路径和加工脉络,成为评估指标可信度和影响分析的重要依据。
另一方面,通过指标数据溯源挖掘得到指标计算相关的源数据项及其系统位置分布,即可采取从源头施治、对指标源数据项进行数据认责,以确保数据项的质量,从而保证和提升指标数据的准确性。
4 指标数据认责
数据认责是企业构建数据治理体系的一项重要的基础性工作。数据认责的根本目的,就是通过明确企业内的各类数据责任者、明确人与数据之间的职责关系,建立起以责任为基础的数据治理组织,为全面、协调推动各项数据治理工作、提升保障数据质量提供基础和保障。
数据认责实施,通过梳理企业数据资产中的数据项与企业组织机构、岗位人员之间的操作和使用关系,明确数据项的主责、录入、审核、改进等各类型责任者,使得数据责任关系明确化,从而为数据问题的分析、定位和解决,以及数据管理各项措施、制度的有效落实提供保障[6]。
4.1 数据认责基础奠定
贵州电网公司从2018年开始,便将建立数据认责管理机制作为公司信息化的一项重点工作,围绕数据全生命周期开展数据认责管理机制的研究、制定以及实施工作。2018年,在部分区局开展数据认责管理试点实施,构建认责组织架构,以问题为导向梳理核心数据项,并完成一批89 个数据项的认责关系梳理和责任分配落实,实现了数据管理“认责到岗、层层管控”的目标,为进一步在全省推广数据认责管理奠定基础。
2019年,在上一年数据认责体系建设和数据认责试点实施成功经验的基础上,进一步完善数据认责体系和工作机制,优化认责方法及模板,明确数据认责管理组织架构、岗位及人员。通过面向全省开展数据认责管理机制的宣贯培训、开展年度数据认责实施工作,在全省范围完成数据认责机制建设,建立起明确的数据认责管理组织,实现数据认责在全省范围的推广实施。
4.2 指标数据认责效率提升
过去数据认责工作的具体实施是利用Excel 文档工具来支撑。随着公司数据认责工作深化,数据认责范围不断扩大、认责粒度不断细化,相关工作量和工作复杂性持续增长。此时,亟待一套操作简便,能快速建立责任关系、同时又便于长期维护认责关系的工具来支撑数据认责工作。
2020年,在基本成熟的认责组织架构、认责职责分配、认责操作流程的基础上,在指标数据认责工作的驱动下,公司提出了数据认责管理系统建设需求。
数据认责管理系统通过工作流的方式把认责实施工作各个环节串联起来,以图形化的方式展示,实现从数据认责计划制定、过程实施到结果监控的全过程流程化支撑和管控,大幅提升数据认责工作效率。
第一批针对40 个重点业务指标,通过指标数据溯源得到91 个认责相关指标数据项,借助数据认责工具面向企业全省各层级组织机构同步开展指标数据质量提升数据认责保障工作:
(1)认责数据管理,实现对指标数据项信息的维护。91 个指标数据项导入认责工具系统并在此进行必要的数据项信息管理维护。如图2所示。
(2)认责计划管理,实现认责计划的发起、计划执行状态及进度跟踪管理。2020 企业指标数据项认责工作计划同时下发到各地市、区县局及班站所,工作推进进度在系统中实时统计反馈。如图3所示。
(3)认责关系建立,实现指标数据项主责认领,主责人对数据录入/改进、审核的操作责任人分配,以及被分配责任人的责任关系确认。建立起指标数据项认责到岗、到人的明确、清晰的责任关系网络。如图4所示。
(4)认责关系维护,支持数据责任关系变更需求。数据责任人可以主动发起变更申请、经审核确认后完成责任关系变更。也可以在出现如人员岗位变迁触发认责关系预警的情况下,由主责人或数据资产管理员来发起责任变更申请及另外分配责任人。责任变更流程进度可跟踪。如图5所示。
(5)认责工作管控,通过交互式综合视图,可总览全省认责工作进展,也可以下钻查看地市区县的工作情况。有整体、有局部,灵活管控。如图6所示。
指标数据认责,目标在于构建指标源数据项与数据责任人之间确定、明晰的责任关系。信息化数据认责工具解决了认责实践过程中效率低、难落地、难维护的问题,提升数据认责工作效率、保障数据认责工作成果。当出现指标数据问题时,借助认责工具便可以直接、快速定位到问题数据项及相关责任人,实现问题一键溯源、信息一键推送,及时推进数据整改,使数据问题得到解决、数据质量得以提升,进而实现指标数据的业务价值。
5 结论
指标是反映企业经营运行状况的重要指针,也是企业管理决策的重要依据。在企业数字化转型的进程中,保障和提升指标数据的质量是利用和发挥指标数据价值的前提和基础。本文首先分析指标数据质量的需求在于指标的真实可信和准确可靠。结合数据溯源思想,研究了指标数据溯源的应用目标:溯源指标计算的数据依赖关系图、形成评估指标可信度和影响分析的重要依据;溯源定位指标源数据项,掌握数据项的系统分布详情。进一步,探索在公司实践多年的数据认责工作经验的基础上,对指标数据项从源头施治进行数据认责,实现保障指标数据准确性、提升指标质量的目的。基于数据溯源和数据认责实现指标数据的质量控制与可信管理,具有重要的研究价值和实践意义。
指标数据流转、加工、计算的复杂度决定了指标溯源数据分解的难度。当前,指标数据溯源还依赖人工实现。下一步,将深入数据溯源技术及模型的研究,设计适合指标溯源应用的溯源模型与方法,实现指标数据自动溯源,与数据认责工具集成,进一步提高指标数据质量保障和提升的效率。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
中国生殖健康(2019年2期)2019-08-23
科技与创新(2019年14期)2019-08-12
计算机应用(2018年12期)2019-01-08
汽车观察(2016年3期)2016-02-28
集美大学学报(自然科学版)(2015年1期)2015-02-28
计算机工程与设计(2011年7期)2011-09-07
