
机器学习方法在股指涨跌预测中的应用研究
2020-01-10 03:18:42
新营销 2019年9期
(东华大学旭日工商管理学院 上海 200050)
一、引言
在预测金融时间序列的问题中,关于股票价格指数的预测得到了诸多学者的关注。股票指数不仅反映整个市场的价格趋势和变动情况,还能反映国民经济整体发展形势,同时也对投资者投资决策具有重要的参考价值,是灵敏反映市场社会、政治、经济变化情况的晴雨表。因此,预测股票指数具有重要意义。但由于市场受到诸多因素的影响,股指的不确定性增加,预测股票指数走势成为最具挑战性的金融时间序列预测问题之一。
与传统的统计方法相比,机器学习在分类和预测等问题上的优势日益凸显。将机器学习方法应用在股票价格的预测上逐渐成为国内外学者研究的热点。Yakup Kara(2011)[1]等基于人工神经网络(ANN)和支持向量机(SVM)预测了指数的走势,他们选择多项技术指标作为模型的输入,对模型进行调参后,ANN模型与SVM模型的准确率均超过了70%,且ANN模型的平均预测能力明显优于SVM模型。Jigar Patel等(2015)[2]讨论了预测印度股票市场单个股票和股指的走势问题,他们研究比较了ANN、SVM、随机森林与朴素贝叶斯这4种预测模型,结果发现,当输入指标为连续值时,随机森林在整体性能上优于其他3种预测模型。不仅如此,他们还发现,当输入指标为趋势确定性数据时,所有模型的预测准确率都得到了改善。冉杨帆等(2018)[3]则结合了情感分析与机器学习方法,以股票的舆论新闻数据为基础,运用BP神经网络与支持向量机回归(SVR)两种方法,对20只股票的价格进行了预测,结果表明,SVR模型的预测正确率更高。王芊(2019)[4]基于机器学习预测并分析了股票收益率变化方向,综合考虑了技术指标、基本面指标和舆情指标,研究发现极度梯度提升树XGBoost算法的准确率比随机森林、支持向量机等多种前沿机器学习方法高。
由于研究者选择的输入变量、输出变量及应用的股票市场有所不同,各机器学习方法的预测表现也有所差异。但总体来说,相对于传统的统计方法,越来越多的学者更倾向于选择机器学习方法来预测股市走势问题。本文借鉴国内外学者的研究,以沪深300指数为市场代表,建立10个技术面指标,通过支持向量机、随机森林、XGBoost预测股指的价格变动方向,并对比分析各模型的准确率。
二、研究方法
(一)指标获取
沪深300指数集合了沪深两个市场流动性最强、规模最大的300只股票,是A股最具代表性的核心指数。本文以沪深300指数为代表来预测股市的涨跌。选取2006年1月至2019年8月共计3 323个交易日的开盘价(Ot)、最低价(Lt)、最高价(Ht)、收盘价Ct以及成交量(Volt)指标,以此为基础建立如表1所示的10个技术指标。

表1 技术指标建立

由于每个技术指标具有不同的量纲与数量级,本文将做标准化处理后作为模型的特征输入。输出特征为下一日股指的价格变动方向,将其转化为一个二分类问题,分类结果为“上涨”和“下跌”。

为输出变量,class=1代表上涨,class=0代表下跌或不变。
(二)模型选择
相对于传统的逻辑回归、决策树简单的机器学习方法,支持向量机、随机森林以及新颖的XGBoost等机器学习方法因为分类性能好、准确率高等优势得到学者的广泛应用。本文试图通过建立支持向量机、随机森林和XGBoost模型预测沪深300指数价格变化方向,并对比不同机器学习方法的准确率。本文选取两分类模型中常用评价指标(见表2)以及ROC曲线来度量各模型的分类性能。评价指标计算方式依赖混淆矩阵见表3。而ROC曲线向上离对角线越远,曲线下的面积AUC值就越大,则说明模型的分类性能越好。

表2 模型评价指标

表3 混淆矩阵
三、实证研究
本文研究的样本区间包括2006年1月至2019年8月共计3 323个交易日的数据,该区间包含了股市2007年与2015年两次大起大落时期,这对测试模型的稳健性具有重要意义。为测试模型准确性,本文将样本数据分为训练集和测试集,其中训练集占70%,测试集占30%。对10个技术指标做标准化处理后,分别使用支持向量机、随机森林和XGBoost模型对训练集监督训练,并对测试集的进行预测,以检验模型的准确性。
(一)支持向量机对沪深300指数的预测
SVM是比较常用的分类算法,其核心是采用线性分类器,当数据在当前维度下不可分割时,可以映射至更高的维度上。因此它在识别高维数据时要优于其他机器学习模型。本文经过多次参数调整,当惩罚项C取3时,模型的分类性能较好。利用训练好的SVM模型在测试集上预测,输出的混淆矩阵见表4,ROC曲线见图1。
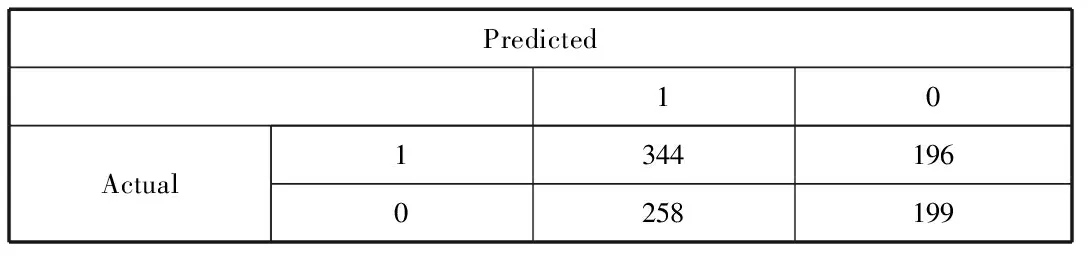
表4 SVM测试集混淆矩阵
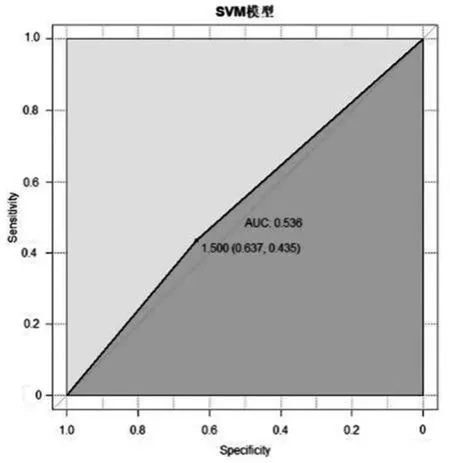
图1 SVM测试集ROC曲线
由表4可知,SVM模型预测下一交易日股指价格上涨且实际也上涨的有344次,预测为股指价格下跌且实际也下跌的有199次,得到模型的准确率为0.544 6。图1展示了SVM模型测试集的ROC曲线,该模型的AUC值为0.545,曲线偏离对角线有一定距离,模型分类性能一般。
(二)随机森林对沪深300指数的预测
随机森林实质是对决策树算法的改进,将多个决策树合并在一起,每棵树建立依赖独立抽取的样本。由于单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样本可以通过每一棵树的分类结果经统计后选择最可能的分类。经过多次实验,本文最终设置森林中树的棵数为300棵。利用训练好的随机森林模型在测试集上预测,输出的混淆矩阵见表5,输出的ROC曲线见图2。

表5 随机森林测试集混淆矩阵

图2 随机森林测试集ROC曲线
由表5可知,随机森林预测为1且实际也为1的次数有336次,预测为1实际为零的次数有204次,实际为零预测为1的次数有236次,预测为零实际也为零的次数有222次。最终可得随机森林模型的准确率为0.559 7。图2展示了随机森林模型的ROC曲线,其AUC值为0.554,ROC曲线偏离对角线有一定距离,模型分类效果相比支持向量机有了提升。
(三)XGBoost对沪深300指数的预测
XGBoost,极端梯度提升,是GBDT的一个变种,GBDT在优化时只用到一阶导数,而XGBoost则对代价函数做了二阶泰勒展开,同时使用了一阶导数和二阶导数,并且在损失函数中引入了正则化项,用于控制模型的复杂度,防止模型过拟合。经过多次实验,当收缩步长设置为0.25,迭代次数为25次,树的最大深度设置为10时,模型得到了较好的分类效果。将学习好的模型用于测试集,输出的混淆矩阵见表6,得到的ROC曲线见图3。
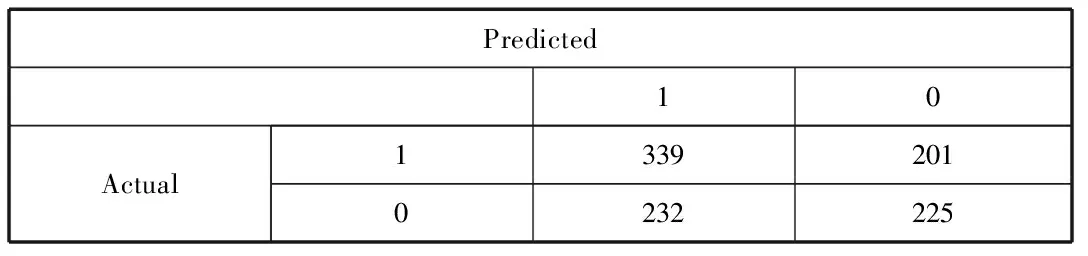
表6 XGBoost测试集混淆矩阵

图3 XGBoost测试集ROC曲线
由表6可知,XGBoost预测下一交易日股指价格上涨且实际情况也为上涨的次数有339次,预测下一交易日股指下跌实际情况上涨的有201次,预测为上涨实际为下跌的有232次,预测为下跌实际也下跌的有225次。最终可得XGBoost模型的准确率为0.565 7。图3展示了XGBoost模型的ROC曲线,其AUC值为0.560,ROC曲线偏离对角线有一定距离,XGBoost模型分类性能相对较好。
(四)模型对比
在二分类条件下比较各算法的预测准确率,即把下一交易日沪深300指数价格上升的样本设置标签为1,价格下降的样本设置标签为零。利用支持向量机、随机森林、XGBoost三种机器学习方法预测的结果见表7。
由表7可见,SVM预测准确率为0.544 6,随机森林预测准确率为0.5597,XGBoost预测准确率为0.565 7,XGBoost相对SVM提高了3.87%,相对随机森林提高了1.08%;SVM的AUC值为0.545,随机森林的AUC值为0.554,XGBoost的AUC值为0.560,XGBoost相对SVM提高了2.75%,相对随机森林提高了1.08%;其他指标也具有相似的情况。随着模型准确度的提高,模型的AUC值越来越大,模型分类性也越来越好。由此可见,XGBoost的预测精度相对SVM和随机森林都有了较大幅度的提升,其中相对SVM的提升幅度更为明显。
四、结论
机器学习是人工智能及模式识别领域的共同研究热点,最前沿的研究领域之一。如何将其应用于金融领域,是近年来学者和投资者广泛关注、积极探索的问题。本文通过支持向量机、随机森林和XGBoost模型预测沪深300指数价格变动方向,并且通过准确率、AUC值等系统比较了该三种模型的分类性能,得出如下结论。第一,从数据本身看,沪深300指数具有反映沪深市场整体形势的能力,能够较好地反映市场价格的变化方向。本文以其每日开盘价、最高价、最低价、收盘价、成交量为基础建立10个技术面指标作为SVM、随机森林和XGBoost的特征输入,可以较好地预测下一交易日的变动方向。其中SVM的预测准确率为0.544 6,随机森林的准确率为0.559 7,XGBoost的准确率为0.565 7,在一定程度上证明了机器学习方法在金融资产价格预测领域的有效性。第二,从使用的机器学习方法看,XGBoost模型预测准确率相对SVM提高了3.87%,相对随机森林提高了1.08%,说明了XGBoost的分类性能优于SVM和随机森林。此外,XGBoost方法新颖,用于预测金融资产价格的研究相对较少,本文将其用于预测沪深300指数的价格变动方向,在一定程度上证明了该方法的可行性,将其用于更多的领域是今后的研究方向。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
新高考·高一数学(2022年3期)2022-04-28 07:02:46
环球时报(2022-03-14)2022-03-14 18:19:44
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电影(2018年8期)2018-09-21 08:00:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
