
航天器分布式智能计算体系的数学建模与调度算法研究
2020-01-09 07:35李金哲
空间控制技术与应用 2019年6期
李金哲,王 磊
0 引 言
目前国内外航天器计算体系结构主要包括三种方式:基于串口的计算体系结构、基于内部总线的计算体系结构以及基于串口和内部总线混合的计算体系结构.但是这些计算体系结构从本质上来说都是以计算机为中心的主从式星型拓扑结构.在节点通讯时,一般仅能与计算机进行点对点通讯,无法实现任意节点之间的高速实时互联.旧有体系的局限性也对航天器的性能产生了限制:大量物理系统的参数不能通过计算体系传递到信息系统的各个节点,导致航天器自主管理与生存能力不足;同时为了可靠性,各节点设计了大量冗余模块,资源消耗过多;目前航天器的计算节点大多是预先设定好功能的专用节点,若其发生故障将导致航天器部分功能的缺失,严重情况下甚至将威胁整星的安全.要解决这些问题,不仅要建立具有自组织能力的智能计算体系,将节点通用化并利用高速总线网络互相连接,利用整体的计算能力为单个节点提供冗余与备份;还要在该体系中高效的进行任务调度,其本质就是寻找一种分配策略[1].基于该策略,可以将任务分配给不同的节点,以实现任务在可用资源之间的合理分配与高效执行[2].不合适的任务调度策略不仅可能造成计算资源的严重浪费,降低系统的运行效率,还容易造成系统中节点负载不均衡,长期负载过重的节点的寿命将受到影响,严重时将威胁系统的安全.
分布式计算体系的任务调度问题是一个NP完全问题[3],难以使用穷举法对其求解,而近年来,智能优化算法在分布式计算体系的任务调度问题中的应用研究越来越广泛,文献[4]使用了遗传算法以最快完成任务为目标求解了任务调度问题;文献[5]使用了粒子群算法以能耗最低为目标实现了任务调度;文献[6]使用了蚁群算法以负载均衡为目标实现了任务调度.各种算法都存在着其优势与不足,遗传算法可以进行快速全局搜索,但其参数较多,实现较为复杂且容易陷入局部最优;粒子群算法较遗传算法拥有更快的收敛速度,且参数较少,实现起来较为容易,但其局部搜索能力也有所欠缺;蚁群算法拥有良好的寻优能力,但由于算法初期的信息素匮乏,导致收敛缓慢.且目前研究分布式计算体系任务调度算法时,多数是进行单目标优化,对多目标优化的任务调度问题研究较少,由于多个优化目标互相之间往往存在冲突,无法同时达到最优,因此寻找多目标的相对最优解成为相关研究的重点与难点.
本文首先对航天器分布式智能计算体系进行数学建模,给出了任务调度问题的多目标优化模型;然后结合了粒子群算法全局搜集能力强、收敛速度快和蚁群算法寻优能力强的优势,同时又对二者分别设计了进一步的优化算法,将粒子群算法生成的调度结果对蚁群算法进行初始化,利用蚁群算法生成了最终的调度结果,实现了任务调度算法性能的提升,使计算体系适应时域上不断变化的用户需求和系统状态,处于健康、高效地运转状态.
1 智能计算体系模型
1.1 智能计算体系的组成
本文所描述的分布式智能计算体系在物理上由三部分组成:若干个专用或通用的计算节点、高速总线网络以及用于公共存储的固态大容量存储器.
其中,各个节点通过高速总线网络进行连接,相互通讯.而大容量存储器存储有智能应用的程序,还有存储智能应用程序的位置描述文件,各个节点可根据位置描述文件通过高速总线网络从存储器相应位置下载所需的应用程序;节点获取任务后,会在大容量存储器中写入运行描述文件,运行描述文件中包含任务执行节点的信息和任务执行程度的信息,当该节点出现故障无法继续执行任务时,其余节点可以根据任务执行程度继续执行该任务,提高计算体系的运转效率[7].大容量存储器还存储不断增加的实时大数据,用于在线的智能学习和训练.
1.2 智能计算体系的节点模型
设初始计算体系中含有m个节点,则计算体系可以表示为一个集合S={s1,s2…sm},为了对节点的状态进行描述,需要建立节点的数学模型,使用以下几个指标来表征当前节点的状态:
1) 计算裕度
计算节点的主频决定了它的峰值计算能力,这是一个固定的量.用占空比μi(0≤μi≤1)可以描述当前时刻节点的计算裕度.
占空比μi是单位时间内CPU进行任务计算的时间所占的比例,它直接描述的是CPU当前的负载情况,μi与时间和任务分配方式有关,即μi=f(Δ,t),Δ为当前任务分配方式,t为时间,当任务被分配到节点后,由于其预期完成时间是给定的,所以也就确定了计算节点在每个脉冲周期需要进行的运算次数,从而确定单位时间内CPU的有效工作时间,即为当前CPU的负载情况.
当任务发布表更新时,各节点通过检查自身占空比得到负载情况,用峰值计算能力减去当前负载即为此时节点的计算裕度.实际中为了延长节点的寿命,提高节点的可靠度,往往不希望节点长期处于满负荷运行的状态,可以人工设置一个占空比的上限μmaxi(0≤μi≤μmaxi<1),用该上限减去当前负载即为节点此时的计算裕度.
2) 剩余存储能力
剩余存储能力是指节点本地空闲动态存储器的大小,单位为兆字节(Mbytes).节点在执行任务时需要从大容量存储器中读取该智能应用程序及其运行描述,并将之复制到本节点的动态存储器的空闲分区,因此足够的剩余存储能力是节点执行任务的必要条件,不满足任务剩余存储能力要求的节点无法参与该任务的竞标.
3) 实时能耗
节点在工作过程中将产生能耗,其能耗与当前负载有关,当前节点占空比越高,能耗越高.
CPU的能耗与负载是正相关的,CPU的负载情况可以由CPU占空比μ来表示,这是一个在实际应用中很容易获取的参数.首先建立计算体系的能耗模型,将CPU占空比映射到系统能耗上,即pcpu=f(μ).根据相关研究,CPU利用率与能耗存在线性相关的关系[8],如式(1)所示:
Pcpu=mPmax+μ(1-m)Pmax
(1)
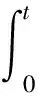
1.3 智能计算体系的任务模型
智能计算体系中用户的需求本质上是一种应用,它是一段可安装的程序,已经装载于大容量存储器之中.包括代码、任务需求、运行描述和任务表四个部分:其中代码是可执行、可复制的,包括BSS、data和代码段;任务需求是关于对存储量、运算量的描述,为一个数组;运行描述是该程序已经被执行程度的表述,是由一组动态数据表达;任务表用于发布该应用,是一个数组.
本文将任务模型中不可再分解的程序记为task0,一个任务由一个或多个task0构成,且task0之间相互独立,各个task0的任务长度和占用存储已知.若任务可以分解为多个task0,那么执行该任务的过程中,可将其分解并将多个task0交由计算体系中不同的计算节点来完成.可以用一个计算任务包含task0的个数、任务长度和所占存储空间来描述该任务,记第i个计算任务为taski,则taski={λtask0i,task_lengthi,task_memoryi},其中λtask0i为包含task0的个数;task_lengthi为任务长度,单位为百万条指令(MI,million instructions);task_memoryi为所占存储空间,单位为兆字节.
2 任务调度问题的优化模型
设当前需要系统执行的计算任务taski由n个task0组成,则计算体系中的任务调度问题可以描述为:在计算体系中,有n个相互独立的task0分配给计算体系中m个计算节点来执行(n>m).其中任务集表示为T={task01,task02…task0n},计算节点集表示为S={s1,s2…sm},task0j表示第j个子任务,j∈{1,2,…n};si表示第i个节点,i∈{1,2,…m}.每个子任务仅由一个节点执行.任务集T={task01,task02…task0n}与计算节点集S={s1,s2…sm}的分配关系可以用矩阵X表示为:
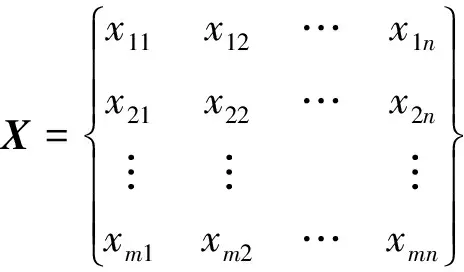
(2)

2.1 优化目标
1) 执行任务时间最短
对用户来说,期望计算体系可以尽快的完成计算任务,设ETij为子任务task0j在节点si的期望运行时间,与映射关系X类似,可得运行时间矩阵ET如下.

(3)

(4)
式中,length_task0j为task0j的长度,单位为百万条指令MI,million instructions,process_si为节点si的执行速度,单位是MIPS,即每秒处理百万条的指令数.设bi为第j个子任务开始执行的时间,CTij(i∈{1,2,…m},j∈{1,2,…n})为子任务task0j在节点si的期望完成时间,max{CTij}为计算体系完成整个计算任务的时间,则有
CTij=bj+ETij
(5)
CXmax=max{CTij}
(6)
当CXmax最小时,系统可以以最快的速度执行计算任务.
2) 能耗最低
智能计算体系的正常运转需要充足的能源供应,期望智能计算体系在达到服务质量要求并满足用户的计算需求的情况下,尽可能减少能源消耗.
CPU是计算密集型任务中最主要的能耗部件,因此主要以CPU能耗为建模依据,其占空比与能耗存在一种线性相关的能耗模型如式(1),第i个节点在时间t内的能耗可表示为式(7)

(7)
其中i∈{1,2,…m},系统的总能耗表示为式(8)
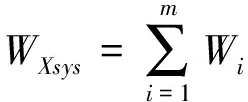
(8)
当WXsys最小时,计算体系的能耗最低.
3) 负载均衡
计算体系中的计算节点处于同等的地位,在运行过程中,期望它们处于一种负载均衡的状态,即没有长期高负荷或负载过低的节点.
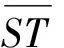
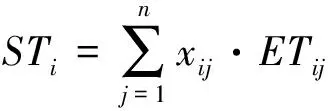
(9)
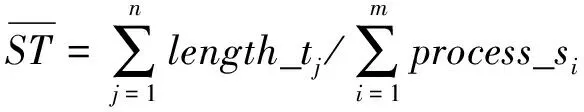
(10)
此种分配方案下计算体系的负载均衡度LBX定义如式(11)
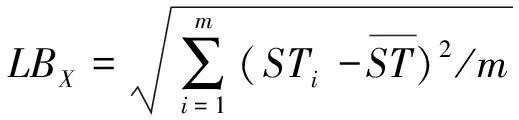
(11)
LBX最小时,整个计算体系的负载最为均衡.
2.2 任务调度的代价函数
基于2.1节所述的优化目标,任务调度问题的代价函数为
minCXmax
(12)
minWXsys
(13)
minLBX
(14)
约束条件为
xij∈{0,1},i∈{1,2,…m},j∈{1,2,…n}
(15)

(16)
0≤μi(t)≤1
(17)
代价函数(12)代表了系统执行任务的时间最短;代价函数(13)代表了系统的能耗最低;代价函数(14)代表了系统负载最为均衡.约束条件(15)中,xij=1代表任务j由节点i执行;约束(16)表示每个任务仅能由一个计算节点执行;约束(17)代表每个节点的占空比不能超过1,即节点均不能超负荷运行.问题的解为任务集T={task01,task02…task0n}与计算节点集S={s1,s2...sm}的分配关系矩阵X.
2.3 多目标优化的帕累托最优模型
在实际工程中,代价函数(12)~(14)之间是不可能同时满足的,使三者同时达到最小的唯一解不存在.这是一个典型的适用于帕累托最优[9]的问题,帕累托最优是指无法在不使群体中任何个体状况受损的情况下,提升群体中任何个体状况的情况.对于任务调度问题的优化,同样期望能在不影响其他代价函数的情况下,对某个代价函数进行优化,最终实现帕累托最优状态.
对于代价函数(12)~(14)来说,任意两个解之间可能存在两种关系:(1)一个解优于另一个解;(2)两个解之间没有解优于对方.本文利用帕累托占优条件来判断两个解之间的关系,设f1和f2是代价函数(12)~(14)的两个解,若f1的一个代价函数严格优于f2,且f1另两个代价函数均不严格劣于f2,则称f1对f2帕累托占优,如式(18)所示

(18)
式中,gi(i∈{1,2,3}),gj(j∈{1,2,3})分别代表代价函数(12)~(14).最终将形成一个解集,这个解集中的所有解均不比其余解更优,这个解集即为帕累托最优前沿,其中所有的解均为帕累托最优解.
在帕累托最优前沿中选择最优解的方法是根据具体需求而变化的,本文选取距离评价指标法[10]选择最优解,以能耗、完成时间、负载均衡度为坐标构建一个空间直角坐标系,则帕累托最优解集中的各解在此直角系中的坐标即可确定,则解集中存在至多三个解,分别使能耗最低、完成时间最短、负载最为均衡,选取这几个解对应的单项最优值为三个坐标,即产生了一个虚拟的最理想解,然后计算各解与虚拟最理想解的距离,距离最短者就是我们选择的解.
3 任务调度算法设计
期望任务调度算法能兼具快速全局搜索能力和良好的局部寻优能力,遗传算法和粒子群算法均可快速全局搜索且局部寻优能力均较弱,但粒子群算法收敛更快,且参数较少易于实现,而蚁群算法的局部寻优能力较强.故先将粒子群算法和蚁群算法进行改良,再将它们结合起来,利用粒子群算法的快速全局搜索能力生成一个初始调度方案,用该初始调度方案初始化蚁群算法,利用蚁群算法良好的局部寻优能力,得到最终的任务调度方案.
3.1 改进的粒子群算法
基本的粒子群算法适用于连续域中的极值搜索,而计算体系中的执行任务节点选择问题是离散问题,因此需要对调度方案进一步的合理处理,方可进行粒子群算法的迭代.

基本粒子群的速度和位置公式如下
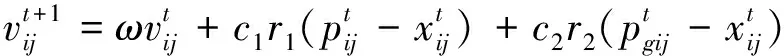
(19)

(20)
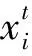
为提高任务调度算法粒子群部分的性能,对惯性权重ω进行动态调整,初期选取较大的惯性权重,扩大算法的全局搜索能力,随着迭代次数的增加线性递减,实现对迭代后期的局部搜索精度的提高,设预定最大迭代次数为tmax,ω∈[ωmin,ωmax],则第t次迭代的惯性权重ωt为

(21)
此时,粒子群算法的速度更新公式如式(22)

(22)
在运行任务调度算法的粒子群算法部分时,速度直接按照式(22)更新,而位置向量按式(20)更新后将违背定义时每一位上均为整数的设定,所以要对位置的更新做进一步的处理[11],方法如式(23)
xij(t+1)=
(23)
式中,|xij(t+1)|表示对xij(t+1)先取绝对值,然后向上取整, mod(|xij(t+1)|,m)表示xij(t+1)的绝对值对m进行取模运算,通过这种进一步的处理方式,将位置向量的各位合理均匀地映射到预设的取值范围,完成对位置向量的更新.
3.2 改进的蚁群算法
用粒子群算法得到的调度结果对蚁群算法进行初始化,将粒子群算法中的向量形式转化为式(2)所示的矩阵形式,生成一组节点集,通过蚁群算法从节点集中生成一组节点,达到调度目的.
迭代过程中,第k只蚂蚁在结点i处选择结点j作为下一个结点的概率为

(24)

当m只蚂蚁均完成一次游历后,各路径上的信息素将按照式(25)进行更新

(25)
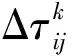

(26)
为提高算法的性能并提高算法的运行速度,在蚁群算法中加入精英策略,引入精英蚂蚁e,即具有迄今最优游历Te的人工蚂蚁,在信息素更新时对精英蚂蚁穿越过的所有边再额外增加信息素,对Te进行加强,实现对优秀个体的保护,降低最优解丢失的可能性.信息素更新公式如式(27)

(27)

(28)
式中,Q为常数;W为一权重系数,Le为精英蚂蚁e所完成的迄今最优游历Te的长度.
任务调度算法的蚁群部分按照式(27)更新信息素,并按照式(24)进行位置转移,当迭代次数达到预先设定值时,算法停止运行.
3.3 算法流程
Step1 定义任务调度问题的3个目标函数.
Step2 设定该选择算法的相关参数.
Step3 初始化粒子群的位置和速度.
Step4 计算每个粒子的目标函数值,找出粒子个体局部帕累托最优解集和全局帕累托最优解集.
Step5 确定每个粒子的个体极值pbest和全局极值gbest.
Step6 对粒子速度和位置进行更新.
Step7 如果达到设定的迭代次数,输出任务分配的初始选择结果,否则,跳转至Step4.
Step8 根据粒子群算法得出的初始调度结果初始化蚁群算法的信息素.
Step9 蚂蚁进行路径搜索.
Step10 每只蚂蚁按照迭代关系选择选择下一节点,更新信息素时将三个目标函数的值先各自乘以一个比例系数再相加作为路径长度,按照帕累托最优选择精英蚂蚁并加强它的信息素,并把所选节点加入到调度列表.
Step11 蚁群算法达到最大迭代次数,保留全局蚂蚁最后一代的值作为全局最优解集合,算法结束,输出调度结果.否则,跳转至Step9.
4 仿真验证与结果分析
为了对本文提出的DPSO-EACO算法进行评估,使用了澳大利亚墨尔本大学开发的分布式计算仿真平台CloudSim[12],对其中的DatacenterBroker类进行扩展添加自定义的任务调度算法即可对调度算法进行仿真模拟.
选取了5个计算节点,运算能力分别为{400MIPS,600MIPS,800MIPS,1000MIPS,1200MIPS},分别在50个长度在[5000MI,10000MI]之间的任务调度规模和500个长度在[5000MI,10000MI]之间的任务调度规模下,使用离散粒子群算法(DPSO)和精英蚂蚁算法(EACO)和本文的DPSO-EACO算法进行了对比.离散粒子群部分,ωmax=0.9,ωmin=0.4,c1=c2=1.5,群体规模为20,迭代次数为40代;精英蚁群部分,群体规模为20,α=1,β=1,ρ=0.1,Q=10,迭代次数为160代.作为对比的DPSO算法的参数设置与离散粒子群部分参数相同,EACO算法的参数与精英蚁群部分相同,二者迭代次数均为200代.
首先仿真了以执行时间最短为单一目标的情况下,3种算法的性能对比,分别将3种算法各运行20次,得到两种调度规模的结果如图1和图2所示.

图1 总任务完成时间曲线(5个节点,50个任务)Fig.1 Completion time curves of total tasks(5 nodes,50 tasks)

图2 总任务完成时间曲线(5个节点,500个任务)Fig.2 Completion time curves of total tasks(5 nodes,500 tasks)
从上面的实验结果可以看出,设置50个子任务时,DPSO算法收敛速度较快,在迭代约20次后即收敛到约116.4 s完成任务,EACO算法在150代左右才完成收敛,但是优化效果较好,约118.9 s完成任务,DPSO-EACO算法在120代左右完成收敛,优化效果最好,约109.6 s完成任务,可见DPSO-EACO算法虽然比DPSO算法收敛的慢,但是优化效果提高了约6.8 s;DPSO-EACO算法比EACO算法约早30代收敛,优化效果也提高了约2.2 s.设置500个子任务时,DPSO算法约30代收敛到1 178 s,EACO算法约10代收敛到1 123 s,DPSO-EACO算法约43代收敛到1 116 s,可见随着任务数的增多, DPSO-EACO算法与EACO算法和DPSO算法相比依然具有更优的优化效果.
通过两种调度规模下的仿真实验,结果表明本文提出的DPSO-EACO算法在单一目标下的时间性能和优化性能上都取得了比较好的提升.
然后演示了完成求解综合能耗、完成时间、负载均衡度的多目标调度帕累托最优问题时3种算法的性能对比.设定Pmax=30 W,m=0.6.分别将3种算法各运行20次,得到两种调度规模的结果如以下各图所示.
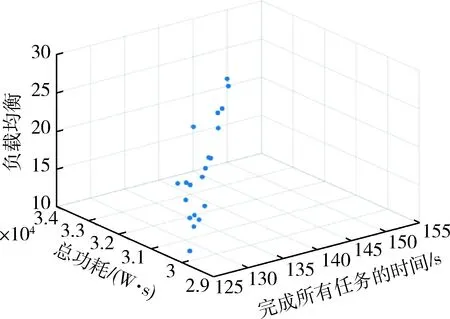
图3 DPSO算法的帕累托最优解集(5个节点,50个任务)Fig.3 Pareto optimal solution set of DPSO algrithm(5 nodes,50 tasks)
图4 EACO算法的帕累托最优解集(5个节点,50个任务)Fig.4 Pareto optimal solution set of EACO algrithm(5 nodes,50 tasks)
图5 DPSO-EACO算法帕累托最优解集(5个节点,50个任务)Fig.5 Pareto optimal solution set of DPSO-EACE algrithm(5 nodes,50 tasks)

图6 DPSO算法的帕累托最优解集(5个节点,500个任务)Fig.6 Pareto optimal solution set of DPSO algrithm(5 nodes,500 tasks)

图7 EACO算法的帕累托最优解集(5个节点,500个任务)Fig.7 Pareto optimal solution set of EACO algrithm(5 nodes,500 tasks)
图8 DPSO-EACO算法帕累托最优解集(5个节点,500个任务)Fig.8 Pareto optimal solution set of DPSO-EACO algrithm(5 nodes,500 tasks)
从上面的实验结果可以看出,当调度规模为50个任务时,DPSO的优化结果为时间Tmax1=125.78 s;能耗W1=2.99×104J;负载均衡度LB1=11.5,EACO的优化结果为时间Tmax1=116.58 s,能耗W1=2.86×104J,负载均衡度LB1=3.5;DPSO-EACO算法的优化结果为时间Tmax1=115.6 s;能耗W1=2.85×104J;负载均衡度LB1=3.1.当调度规模为500个任务时,DPSO的优化结果为时间Tmax2=1 128.5 s,能耗W2=2.75×105J,负载均衡度LB2=62;EACO的优化结果为时间Tmax2=1 092.6 s;能耗W2=2.71×105J;负载均衡度LB2=18,DPSO-EACO的优化结果为时间Tmax2=1 080 s;能耗W2=2.683×105J;负载均衡度LB2=12.与DPSO算法对比,DPSO-EACO算法的优化性能获得了大幅度提升,避免了DPSO算法过早收敛至局部极值的问题;与EACO算法对比,50个子任务时收敛相对较快,500个子任务时收敛略慢,但可以取得更好的优化效果.以上仿真结果表明,在不同的调度规模下,DPSO-EACO算法均可以实现对较快速全局搜索与良好局部寻优的兼顾.
5 结 论
本文给出了航天器分布式智能计算体系的数学模型和任务调度问题的多目标帕累托最优优化模型.对离散粒子群算法中使用了动态权重,在蚁群算法中使用了精英蚂蚁,将优化后的算法结合起来,利用粒子群算法生成初始调度方案,再用该初始调度方案初始化蚁群算法,使用蚁群算法生成最终的调度结果.综合利用了粒子群算法的快速收敛速度和蚁群算法较强的局部寻优能力,不仅在针对任务完成时间最短这一单一目标优化时取得了更好优化性能;在寻找能耗最低、任务完成时间最短、负载均衡的帕累托最优状态时,也发挥了更优的优化性能.
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
昆钢科技(2022年2期)2022-07-08
计算机测量与控制(2022年2期)2022-03-30
昆明医科大学学报(2022年1期)2022-02-28
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
建材发展导向(2021年23期)2021-03-08
知识就是力量(2019年7期)2019-07-01
华人时刊(2018年15期)2018-11-10
分析化学(2018年12期)2018-01-22
飞碟探索(2015年8期)2015-10-15
