
基于优化SVR 的军用软件可靠性预测方法*
2020-01-08 03:33:32马振宇刘福胜
火力与指挥控制 2019年11期
马振宇,张 威,吴 纬,韩 坤,刘福胜
(1.陆军装甲兵学院,北京 100072;2.解放军63963 部队,北京 100071)
0 引言
当今信息化、现代化发展迅猛,部队为了保证自身的战斗力不受削减,适应新时代的作战需求,也在不断地普及信息化,因此,许多规模较大,复杂程度较高的系统软件都嵌入到部队装备当中,例如火控系统、制导系统以及控制系统等。为了保证军用软件和装备在一起使用时,不会出现由于软件的失效而导致装备无法使用的情况,这就要求军用软件自身具有较高的可靠性[1-3]。如果软件在备装部队之前,能够及时准确地预估软件可靠性,就能够保障软件今后的正常使用。
文中首先通过相关分析,找到对军用软件可靠性影响较大的5 个度量元。然后通过数据归一化以及随机排序的方法对这5 个度量元进行数据预处理。接着利用网格寻优法对SVR 算法中的参数进行寻优,以此为基础构建出基于优化SVR 算法的军用软件可靠性预测方法。最后通过案例分析,证明了该方法的可行性和有效性。
1 相关准备工作
1.1 度量元采集
软件一般含有多种属性,软件度量是度量对软件自身可靠性造成影响的属性,而这些属性一般称为软件度量元[4]。度量元可以用来处理模块缺陷分类、模块缺陷数分类和遗留等问题,因此,通过选择度量元,找到与军用软件可靠性指标之间内在的联系,构建出军用软件可靠性预测模型,是提升软件可靠性行之有效的办法。
本文使用静态分析工具Logiscope 获取软件度量元数据[5]。Logiscope 是一款优秀的软件静态分析工具,能够采集应用程序级、文件级、类级和函数级4 级代码度量,共有44 个度量元,其中应用程序级11 个、文件级10 个、类级11 个、函数级12 个,如表1 所示。
1.2 数据预处理
在进行军用软件可靠性预测之前,需对相关数据进行预处理,避免在预测过程中由于某些“问题点”之间数值差过大,造成结果的不理想。数据归一化就是把原始数据规范到[0,1]这个区间的过程,其表达式如下所示:
其中,valuemax为原始数据中最大值;valuemin为原始数据中的最小值。
另外,样本数据的不同排序一定会导致不同预测结果的发生。采用随机取样法,对训练集与测试集进行随机排序,一是可以保证预测结果不失一般性,更具有说服力;二是避免因为训练集和测试集中的“问题点”影响实验结果的准确性。
1.3 相关性分析
为了取得较好的预测效果,需要对度量元进行优选,本文通过相关性分析来选择度量元[6-7]。通用的有两种相关性分析指标,一种是Pearson 相关系数,一种是Spearman 秩相关系数[8-9]。Pearson 相关系数适用于有线性关系的数据,且整体上满足正态分布的连续变量;Spearman 秩相关系数对原始变量的分类不作硬性规定,也就是说不需要符合任意分布规律,就可以通过秩相关系数很好地量化彼此间的关联程度。因此,该方法通用性、适用性、灵活性很好,在当今的领域里得到广泛应用。本文提取的度量元和军用软件可靠性指标没有明确的线性关系,因此,本文选择Spearman 秩相关系数进行分析。其计算表达式如下:

表1 四级代码度量元

相关程度依据相关系数的绝对值进行分类,一般分成5 个等级,如表2 所示。当r>0,说明度量元和军用软件可靠性指标关系为正相关;反之r<0,则为负相关。特别指出:当r=1,则为完全正相关;r=-1,则为完全负相关;当r=0,则不存在关系。

表2 相关程度等级划分
2 基于优化SVR 的软件可靠性预测模型
2.1 SVR 算法的预测模型
支持向量机是由Corinna Cortes 和Vapnik 的科研团队在20 世纪末初次提出的有别于其他机器学习的算法[10-12],其方法在使用初期主要用于处理模式识别问题,随后它在处理小样本、非线性以及高维度空间识别里体现出许多独有的优势[13]。Vapnik在接下来的科研工作里,提出损失函数概念,把SVM 应用到非线性回归估计和曲线拟合当中,得到一种专门针对曲线拟合回归估计的模型算法,即ε不敏感支持向量回归[14]。该算法在非线性这一类问题当中有着很好的实验结果,所以SVR 逐渐成为SVM 函数回归领域的研究热点。

其中,w 是权重系数,b 为偏置项。
先定义由Vapnik 提出的ε 不敏感损失函数:
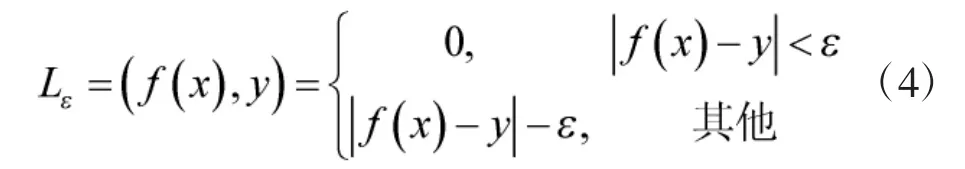
其中,ε 称作不敏感系数,其主要用于调控拟合度。
不妨假设全部训练集的拟合误差率最大为ε(所有输入训练集的点到高维空间平面的距离最大为ε),即:

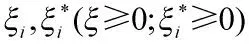

使用相同的优化算法求解对偶最优问题:

从而得到最终的最优回归估计函数:

2.2 参数寻优
SVR 算法中包含许多种影响计算结果的参数,并且这些参数都有默认的初始值[15]。然而在寻找具体问题的最优值时,设定的参数值往往不能满足实际的需求。因此,需要针对具体问题进行参数寻优,找到最优值。
本文主要对SVR 算法中两个比较重的参数C和g 进行寻优。C 是惩罚因子,表示的是对误差的宽容度。其值越大,表明越不能接受出现误差,容易过拟合;其值越小,容易出现欠拟合。C 值过大或者过小都会导致泛化能力变低。g 是调节RBF 的核函数中σ 的参数,它决定着数据映射到新的特征空间以后的分布。其值越大,支持向量越少,反之,则越多。支持向量的个数决定着模型预测的准确性。这两个参数没有确定的最优值,需要依据具体问题寻找最优值。
网格寻优法是一种遍历搜索的方法,其根据步长将数值分割成若干个小网格块,再将所有分割出来的网格块进行分组并取尽它所有的可能值。通过这种遍历的方法找到最优的一组值。该方法的优点是每个网格相互独立,便于并行计算。具体寻优过程如下:
第1 步:对参数C 和g 进行初始化,并组成二维数组对(C,g)。同时给定分割步长的长度。
第2 步:根据确定的分割步长,将参数C 和g分别分割成m 和n 个数值。
第3 步:将分割出的数值依次进行相互配对,共形成m*n 个二维数组对(C,g)。
第4 步:将每一组二维数组对,带入SVR 模型中,得到预测结果。
第5 步:直到将所有二维数组对都遍历完成以后,寻找预测结果中精度最高值所对应的二维数组对,作为参数的最优值。
3 实验结果及分析
实验原始数据来自通用装备保障软件评测中心的实测结果,通过采用LogiScope 对33 组原始数据进行度量,得到4 级44 个度量元。通过Spearman相关系数分析与软件可靠性指标的相关系数,结果如表3 所示。
本文选择与软件可靠性指标的相关系数绝对值大于0.4(中等相关)以上的度量元,共有5 个:ap_cof,struc_pg,cu_cdusers,cu_cdused 和in_noc,即耦合因子、违反结构化编程数量、使用某个类的类数量、某个类使用的类数量和子类数量。
对33 组软件数据进行随机取样,选取出22 组数据作为训练集,剩余的作为测试集。为了很好地衡量该算法预测效果,本文选取均方根误差,平均绝对误差,相对平方根误差和相对绝对误差这4 个指标进行分析。
本文首先分别用ε-SVR 模型和v-SVR 模型进行军用软件可靠性的预测。接着通过网格寻优法对v-SVR 预测模型中(C,g)参数进行搜索,预期找到参数的最优值,最优值如图1 所示,其中C 的最优值是8,g 的最优值为0.5。最后将寻优后的v-SVR模型和其他5 种机器学习算法的实验结果进行对比,如下页表4 所示。

表3 度量元和软件可靠性指标的相关性
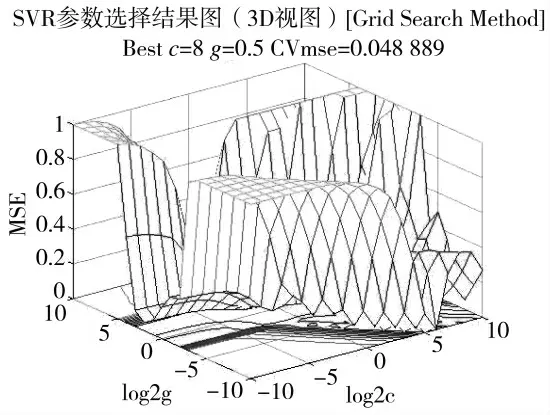
图1 SVR 参数寻优图
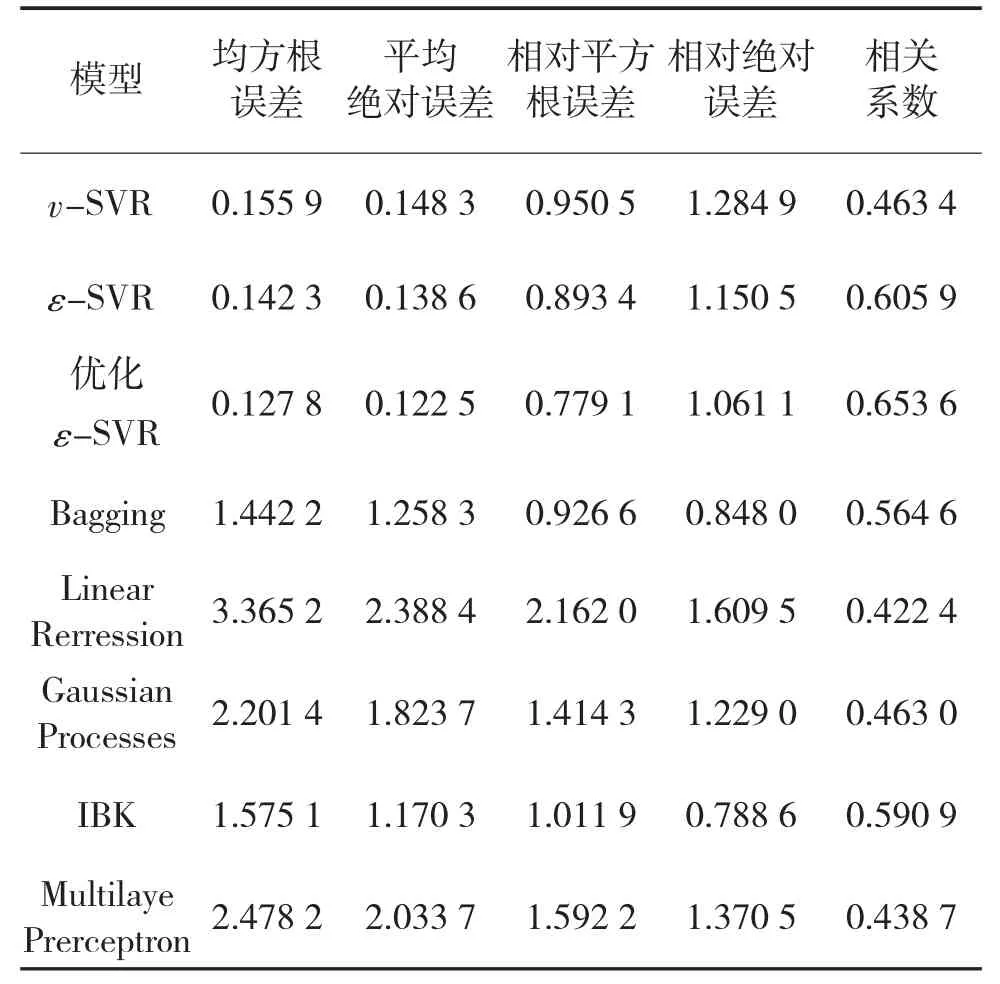
表4 软件可靠性指标预测结果分析
通过表4 可以得到以下结果:
1)v-SVR 模型较ε-SVR 模型预测结果更优,证明了v-SVR 模型具有使ε 自动最小化,并且可以根据数据集调整精度级别的优势。对v-SVR 模型进行参数寻优后的预测结果精度的确有所提高,说明了优化SVR 算法的有效性。
2)与其他算法相比,本文的优化SVR 算法在预测军用软件可靠性方面有着较大的优势。优化后的SVR 算法在4 个指标评价方面的误差值都是最小的。
3)相关系数表示的是度量元和可靠性指标之间的相关程度。相关系数越大,度量元与软件可靠性指标相关性越大。由于不同算法构建预测模型的机理不同,所以预测精度和相关系数之间不存在正比关系。但是在相似的算法当中,如支持向量回归算法,其预测效果越精准,度量元和软件可靠性指标相关程度越大。
4 结论
本文首先通过使用LogiScope 软件,对实测的33 组软件进行度量元提取,共获得4 级44 个度量元。然后对提取出来的度量元进行数据预处理,经过相关性分析,找出5 个与军用软件可靠性关联程度较大的度量元。然后通过网格寻优法对SVR 算法中的参数进行寻优,在此基础之上,构建出基于优化SVR 算法的军用软件可靠性预测方法。最后通过案例分析,证明了网格优化SVR 参数在软件可靠性预测方面的可行性和有效性。
本文采用的样本数为33 组,相对而言,样本数偏少,在今后的研究工作中,需要进一步收集测试样本,提高模型的预测精度;对更多参数进行组合优化,同时简化算法本身,提高运算效率。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
军事文摘(2020年14期)2020-12-17 06:27:24
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
信息安全研究(2018年11期)2018-11-15 09:00:26
下一代英才(酷炫少年)(2018年4期)2018-04-28 08:29:50
中国老区建设(2016年4期)2017-01-15 13:53:54
现代工业经济和信息化(2016年1期)2016-05-17 05:33:48
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
小天使·一年级语数英综合(2015年10期)2015-10-14 06:19:33
