
大数据挖掘中的MapReduce并行聚类优化算法研究
2020-01-07 05:48林丹楠
太原师范学院学报(自然科学版) 2019年4期
林丹楠,黄 锐
(1.福建商学院 信息技术学院,福建 福州 350012;2.北京理工大学 计算机学院,北京 100081)
伴随着科技的发展,互联网用户数量的快速增加,网络信息量也急剧增长,数据集中包含的数据量呈指数级增长,世界已经进入了大数据信息化时代[1-4].这些大数据包含了人们的生产活动的各方面信息,具有非常大的挖掘价值.但是,这些数据有噪音、持续、多样化,如何从其中提取出所需的规律和隐含结构,以便转换成有用的信息,成了如今热门的研究问题.数据挖掘技术成为了解决以上问题的主流技术.
聚类算法一直是数据挖掘算法中比较重要的一个分支[5].聚类分析可以按照个体或样品的特征将它们分类.聚类分析方法种类较多[5],主要分为划分聚类、层次聚类、基于密度的聚类、基于网格的聚类等.其中,作为十大经典聚类算法之一,K-means算法是典型的基于划分方法的聚类算法,被广泛应用于实际数据集的聚类分析中.
文献[6]针对传统K-means算法敏感于初始中心点的选取的问题,提出了基于不唯一密度的K-means优化方法,改进后的聚类结果较稳定且准确率有所提高.文献[7]利用最小-最大相似度(MMS)建立初始质心,对传统的K-means聚类算法进行了改进得到了MMSK-means聚类算法,其作为一种标签聚类算法,可用于个性化搜索任务.文献[8]利用群体智能优化算法中的PSO算法对典型K-means算法进行了改进,并将其在网络入侵检测中进行了应用.该方法能够解决初始聚类中心随机选择问题,较少聚类结果对初始聚类中心的依赖性.但是,伴随着数据量“爆炸式”的增长,传统模式的K-means聚类算法已经无法适应大规模数据集的挖掘.因此,文献[9]提出了一种基于CPU和GPU辅助的并行化核K-means聚类算法,大大较少了聚类算法的耗时.
随着云计算的快速发展,Hadoop分布式平台为新模式的聚类分析提供了有力支撑.因此,针对传统K-means聚类的初始中心点选取和Hadoop并行化设计问题,提出了一种MapReduce并行聚类优化算法.该算法充分利用了差分进化算法的并行全局搜索优势.并把优化后的算法在Hadoop的MapReduce框架下做了并行化的设计.实验结果表明优化后的K-means 算法大大减少了运算的时间,且聚类效果良好.
1 K-means聚类和差分进化算法分析
1.1 K-means算法介绍
作为一种基于距离的划分聚类算法,K-means聚类算法具有算法结构简单、运行效率高且适用范围大等优点[10]-[13].K-means聚类算法一般通过如公式(1)所示的目标函数来实现优化.
(1)
可以看出,公式(1)所示的目标函数是一个误差平方和计算过程.其中,E为聚类准则函数,K为聚类的总数,Cj,j=1,2,…,K为聚类中的簇j,x为簇Cj中的一个聚类目标,mj为簇Cj的平均大小.通常来说,E的值越小则聚类效果越好.反之,E的值越大则聚类质量越差.
1.2 差分进化算法的基本原理
差分进化算法是一种基于群体智能的新型启发式算法,具有较强的全局优化能力[14].设X表示初始种群,N为种群的大小,Xi(t)(t=1,2,…,N)为当前种群中进化个体,t为进化过程的迭代次数.种群中个体变异操作的过程如公式(2)所示.
(2)
其中,Xp1(t)Xp2(t)Xp3(t)是从当前进化种群中随机选择出来的三个不同个体,F是缩放因子,经验表明,F=0.6时效果较好.D为种群中个体的维度,也就是说变异个体Vi(t)由D 个分量构成.
当前种群中的进化个体Xi(t)与Vi(t)进行交叉操作,生成竞争个体Ui(t)=(ui1(t),ui2(t),…,uiD(t))(由D 个分量构成).竞争个体Ui(t)中j-th分量的计算方法如公式(3)所示[15].
(3)
其中,z为一个随机整数,且z∈{1,2,…,D}.CR∈[0,1]为交叉概率,经验表明,交叉概率CR的取值在0.3到0.9之间较为适宜.
按照如下方法择优更新种群[16-17].
(4)
2 基于差分进化的K-means聚类优化
通过研究发现K-means 算法具有较好的局部的搜索能力,但是容易收敛到局部最优解.主要原因是K-means 算法敏感于初始中心点的选取,从而影响聚类结果的稳定性、执行时间和分类正确率.因此,为了快速高效地对初始聚类中心进行优化,本文利用差分进化算法对 K-means 算法进行改进,从而提高聚类质量.基于差分进化的K-means聚类算法流程如图1所示.
Input:聚类数目K,交叉概率CR,缩放因子F,初始数据集X及其样本数量n,种群规模N.
Output:最佳聚类结果.
步骤1:编码及种群初始化.采用实数编码对数据集中随机选出的聚类中心进行编码.对于进化代数t=0时,初始种群的第i个样本编码方式如下:
Xi(0)=(ci1,ci2,…,ciK)i=1,2,…,N.
(5)
其中,cij示第i个个体的第j个聚类中心,j=1,2,…,K.
步骤2::计算出个体Xi(t)的适应度值f(Xi(t)),本文中的适应度函数采用如下方式得到:
(6)
其中,mi表示簇wi的中心.
步骤3:对当前种群中的个体Xi(t)按式(7)计算得到变异个体Vi(t)=(vi1(t),vi2(t),…,viK(t))完成变异操作.
vij(t)=xaj(t)+F(xbj(t)-xcj(t))j=1,2,…,K.
(7)
其中,a,b,c分别为一个随机生成的整数,且a,b,c∈{1,2,…,N}.
步骤4:根据公式(3)计算竞争个体Ui(t)完成交叉操作.
步骤5:采用贪心选择策略在当前进化个体Xi(t)和当前竞争个体Ui(t)中选择一者放入下一代种群中,选择方式如公式(4)所示.
步骤6:当达到最大的迭代次数时,停止迭代,输出最优解.否则t=t+1,跳转到步骤2.
步骤7:把差分进化算法的输出作为最佳K个K-means的初始聚类中心组合,使用欧氏距离计算所有数据对象与中心的相似度,根据最近邻原则,把数据对象划分到相应的簇中.
步骤8:输出聚类结果.
3 基于MapReduce的聚类分布式设计
采用并行化的结构设计理念完成MapReduce函数设计,包括map()和 reduce()函数,以便在Hadoop分布式平台上运行,提高运行速度,具体分布式流程如下:

图1 基于差分进化的 K-均值聚类算法流程

4 实验及结果分析
4.1 Hadoop平台的搭建
为了验证本文提出并行聚类优化在大数据环境下的性能,在 4台机器构成的Hadoop Hadoop集群上进行了性能测试分析.4个节点(1个主节点master和3个从节点slave)的软硬件配置如表1所示.所有服务节点通过1000M光纤实现相互通信.在所有服务节点上均安装了1.2.1版本的Hadoop,JDK 版本为1.7.4个节点的ip地址分别为214.102.61.2,214.102.61.3,214.102.61.4,214.102.61.5.

表1 节点的软硬件配置参数
4.2 算法性能验证
采用数据集为UCI中的Iris、Wine 数据以及人工数据集KDS1,实验数据参数如表2所示.实验中算法的参数设置为:缩放因子F=0.6,交叉概率CR=0.5,最大进化代数取TMAX=1 500.为了使有效性分析更合理,将本文提出算法与传统的K-means 算法、PSO- K-means算法[8]进行了比较,对其聚类结果取平均值.三种算法的实验结果分析如表3 所示.从表3可以看出,相比其他两种算法,基于差分进化的K-means聚类算法在准确率方面具有最佳性能,即聚类性能最好.

表2 实验数据集参数
表3三种算法的聚类结果对比
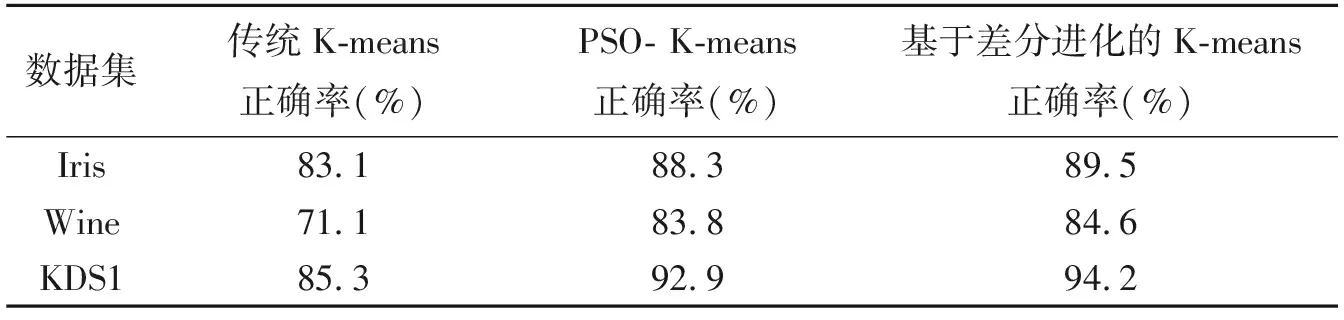
数据集传统K-means正确率(%)PSO- K-means正确率(%)基于差分进化的K-means正确率(%)Iris83.188.389.5Wine71.183.884.6KDS185.392.994.2
4.3 分布式平台性能验证

图2 运行时间对比
为了验证提出MapReduce并行聚类优化算法在分布式平台的加速效果,在单机环境下和集群环境下对算法的执行效率进行了对比.两种情况下运行时间对比如图2所示.可以看出,随着数据集的不断增大,获得的加速效果越来越显著.
5 结束语
本文将差分进化算法与K-means算法相结合提出了一种MapReduce并行聚类优化算法,以便解决传统K-means聚类的初始中心点选取和Hadoop并行化设计问题.利用差分进化算法的强大全局搜索能力克服K-means算法对初始中心较为敏感的缺点,利于增强全局最优解的稳定性.并把优化后的算法在Hadoop的Map Reduce框架下做了并行化的设计.实验结果验证了提出MapReduce并行聚类优化算法的准确性和有效性,能够在Hadoop分布式平台上更加高效地处理海量数据挖掘任务.
猜你喜欢
数学杂志(2022年5期)2022-12-02
今日农业(2022年15期)2022-09-20
湘潭大学自然科学学报(2022年2期)2022-07-28
湖南电力(2022年3期)2022-07-07
新世纪智能(数学备考)(2021年5期)2021-07-28
湖南电力(2021年1期)2021-04-13
中学生物学(2018年8期)2018-03-01
制导与引信(2017年3期)2017-11-02
雷达与对抗(2015年3期)2015-12-09
太空探索(2014年1期)2014-07-10
