
层聚合的对抗机器翻译模型的方法研究
2020-01-07 03:34杨云,王全
陕西科技大学学报 2020年1期
杨 云,王 全
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
0 引言
目前,随着深度学习在自然语言处理领域的发展[1-5],机器翻译[6]从早期的主要以浅层机器学习为核心的统计机器翻译[7,8]的研究过渡到了以深度学习技术为核心的神经机器翻译[9-11]的研究阶段.注意力机制与神经机器翻译的结合[12].除了受深度学习影响的端到端的神经机器翻译的研究之外,也有很多学者将深度神经网络应用到统计机器翻译领域[12-14],这些研究也使得传统基于浅层机器学习方法的统计机器翻译的性能得到了很大改善.
然而,统计机器翻译的弊端在于,需要人类专家设计特征和相应的翻译过程,难以处理长距离依赖,还会因为离散表示带来严重的数据稀疏问题.注意力机制与神经机器翻译的结合[15],有效的缓解了长距离依赖,并且在大规模的平行语料库上,效果远远优于统计机器翻译模型.
Transformer模型[16]的提出是神经机器翻译的革命性变革,性能超过了经典的以RNN和CNN为主要架构的神经机器翻译模型.但经典的Transformer模型和传统的深度模型的共同缺点是:仅利用了模型的末层信息,将末层信息作为整个网络对输入的总结,缺乏利用中间层传播的有用信息.文献[17]研究发现,不同层能够捕获不同类型的语法和语义信息.除此之外,传统的神经机器翻译模型通常采用基于最大似然原理(MLE)的单模型训练方法,即以当前翻译模型为训练目标,通过最大化以源语言为条件来生成目标语言翻译的条件概率进行训练,这很难保证翻译结果的自然性和准确性.
针对以上问题,本文对文献[16]中的Transformer模型进行改进,受到文献[17]和生成对抗网络[18]的启发,本文通过将强化学习方法和对抗性训练方法相结合来训练新模型ATransformer,弥补了基于最大似然原理的单模型的缺点,有效的改善了机器翻译的质量.新模型不仅能够深度捕捉模型的层与层之间的特征信息,而且还考虑了层与层之间的关系.实验测试结果表明,所提出的方法能够有效改善机器翻译的质量,其翻译性能优于基本的Transformer模型以及采用神经网络方法的统计机器翻译模型.
1 ATransformer模型的设计原理
新模型的编码器和解码器均由3个相同的模块堆叠而成,每一个模块分为主层和合并层,主层的设计是Transformer模型的原始层,合并层是新添加的层.对于主层而言,编码器和解码器的主层的设计比较相似,区别仅仅是相比编码器的主层,解码器的主层中多了一个子层.ATransformer模型的编码器的单模块结构如图1所示.

图1 ATransformer编码器单模块结构
图1是编码器单模块结构图.为了完整的表示编码器整体设计结构,本文对单模块的各层作了简化,简化之后的结构如图2所示.
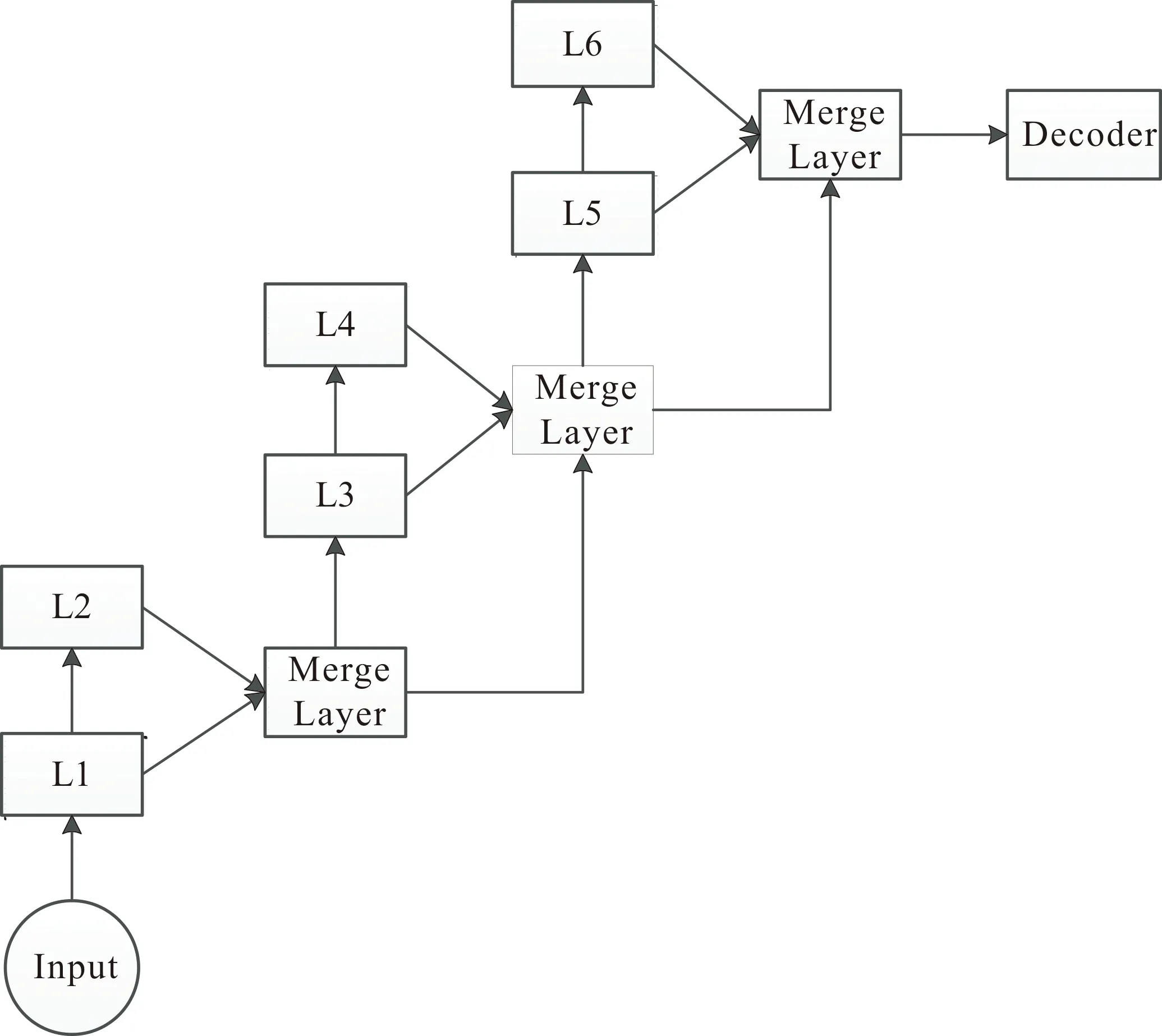
图2 ATransformer编码器简化结构
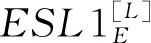
(1)
(2)
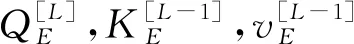
(3)
(4)
FC(X)=max(0,XW[1]+b[1])W[2]+b[2]
(5)
公式(3)、公式(4)以及公式(5)均出自文献[16],Q、K、V是Transformer模型需要学习的三个参数向量,在实验环境中,dk、α和β是在实验中需要设置的参数,μ和σ是输入向量X的均值和标准差,W和b是需要训练的权重和偏置参数,在实验的最开始阶段,随机初始化,上标L表示的是第L层.所有的超参数的设置,会在之后的实验设置中进行设置.对具有6个相同层的原始模型,将层与层的输出结果进行合并,每两层,将信息聚合;然后将合成后的信息作为下一个双层的输入,这样三次合成便完成了对6层信息的融合,与Transformer模型的区别是,新模型每两层就利用合并层进行一次信息抽取,而不是原来的6个层的直接堆叠,这样可以获得更多并且更细节的语言结构特征和网络可利用的信息.换句话说,整个网络结构从最浅、最小的结构的层开始,然后,迭代合并更深、更大的层级结构,一层接一层.最后得到更多的可利用的信息.具有越来越深的含有更多语义信息的这些层,可以表示为:
L[i→j]=[L[i],…,L[j]]
(6)
(7)
Joint(a,b,c)=LayerNorm(FC([a;b;c])+a+b+c)
(8)
在这里,a和b是主层中相邻两层的输出结果,c是合并层的输出结果.直观上来看,这样的设计,可以增加层间信息的多样性,如果不同的层能够捕捉不同的信息,那么这样的逐层进行信息融合会增强模型的表达能力,可以获得更多表达信息.
解码器的设计跟编码器的设计类似,同样由3个相同模块组成,解码器的单模块结构如图3所示.
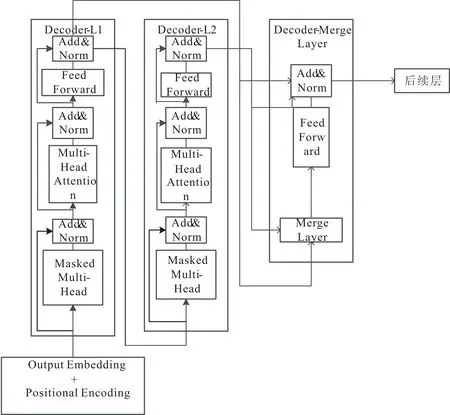
图3 ATransformer解码器单模块结构
(9)
(10)
(11)
同理,简化之后的解码器的结构如图4所示.
综上,本文完成了ATransformer模型的设计.通过对多层的具有Attention机制的层的合并,每一层的Attention机制对于当前输入的句子可以计算出每个时刻在进行翻译时,原句中不同词的关注度,这样经过层的合并,综合了不同层的特征提取结果,加深了词之间的关系,可以有效解决诸如代词之类的代指歧义问题.所以,新模型可以有效地捕捉语句内复杂的句法和语义结构信息.通过之后的实验验证,模型的确有效的提升了机器翻译的质量.
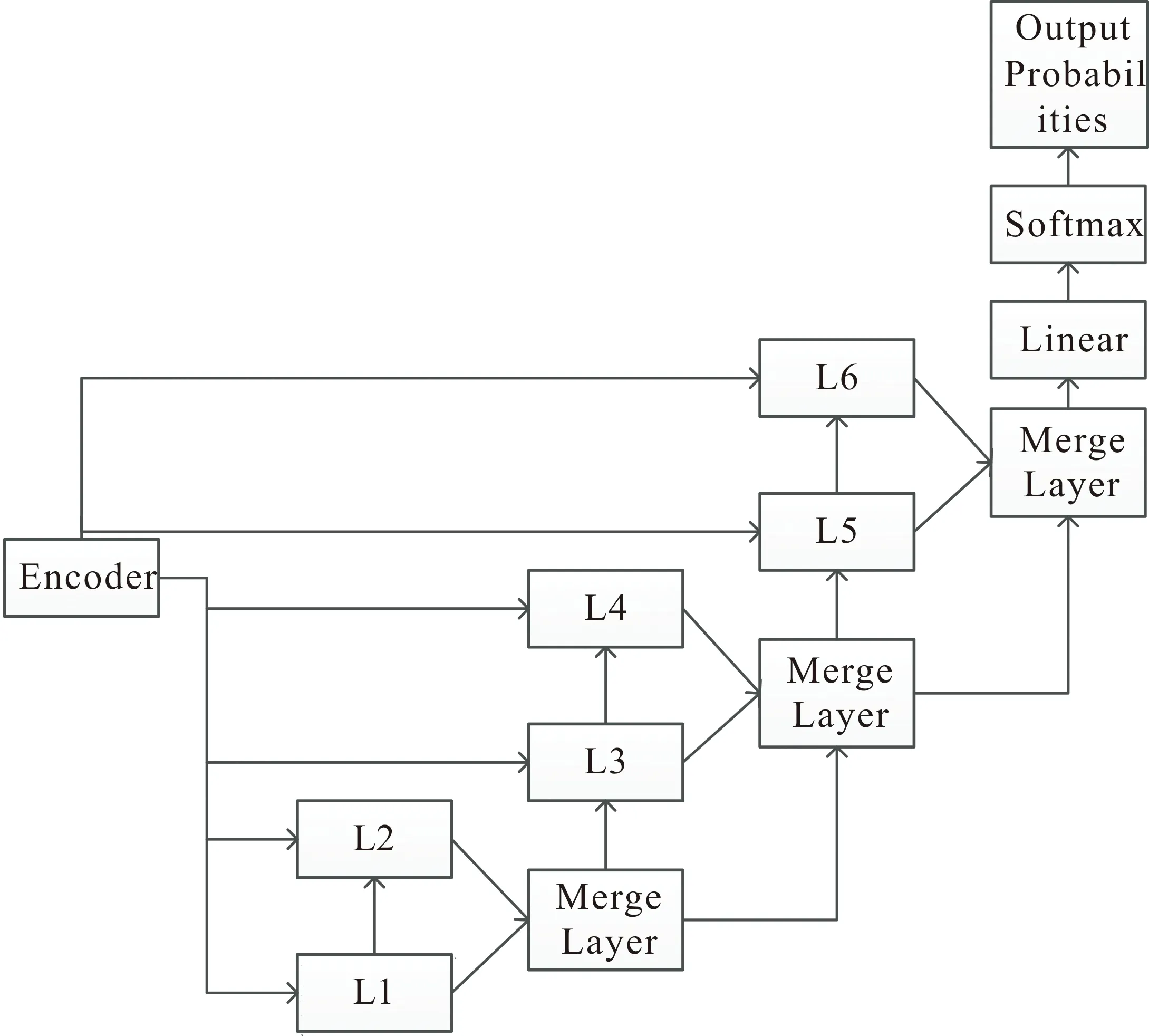
图4 ATransformer解码器简化结构
2 ATransformer模型训练优化的方法设计
本文的核心思想是使用卷积神经网络作为判别器,它具有准确捕捉不同的抽象层次的双语句对的对齐关系能力.其目标是区分ATransformer模型生成的翻译结果和人工翻译的参考译文.
其中,本文使用双语平行语料来进行训练,首先将源语言句子S输入到ATransformer模型中,为了方便说明,将ATransformer模型取名为G模型,将判别器取名为D模型,模型G的输出结果T_Pred,初始训练中,模型的翻译结果可能很差.然而可以将模型的翻译结果T_Pred和平行语料中的源语言S和其对应的目标语言T一起送入到判别器D中,对这种经过编码之后的句子进行拼接转换成卷积网络擅长处理的矩阵形式.具体来讲,每个词作为词向量,对齐的句对对应的词向量进行拼接,构建D的正样本输入.同理将模型G的翻译和原始输入做同样的处理,也构建D的负样本输入,通过公式(14)进行训练,通过D中的多层的卷积网络操作进行特征的提取,最终通过全连接层和含有sigmoid的分类层得到正负类别的概率分布,来判断D的分类能力,并进行进一步的训练.模型G试图产生高质量翻译T_Pred来欺骗D.然而,在进行正负样本采样的过程中,由于从T_Pred中采样的数据是离散的,这会导致难以将来自D的信号反向传播到G.因此本文使用了强化学习中的策略梯度算法来对G进行优化,来缓解这样的问题.通过优化之后,G与D相互对抗训练,直到收敛,即判别器D无法区分模型生成的翻译结果T_Pred和人工参考译文T.
在给定源语言句子S的情况下,判别器D来用于区分G模型的翻译结果T_Pred和语料中的参考译文T.对于平行语料中的双语句对(S,T),首先通过简单的拼接S和T中的词向量来构建成适合卷积网络擅长处理的二维矩阵表示.对于源语言句子S中的第i个词SWi和目标语言句子T中的第j个词TWj,可以得到如下的特征映射:
(12)
基于这样的特征表示,采用5*5的卷积核来对当前得到的特征映射进行卷积操作,卷积后得到结果可以通过下面公式来计算:
(13)
在这里,激活函数使用的是sigmoid激活函数,卷积层计算完后,在池化层进行最大池化操作,减小模型的复杂度,这样进行多层的卷积池化操作,就可以捕获更高级的抽象表示,然后在进行扁平处理,将结果送入到一个全连接网络中,在使用sigmoid函数将问题转化为二分类问题,输出为双语对齐句对(S,T)的概率.对于这种以卷积神经网络模型作为判别模型的最优化的目标是最小化逻辑回归损失函数,即一个二元分类的交叉熵损失函数,其中将平行语料中的双语对齐句对(S,T)作为正样本,将G模型产生的目标翻译T_Pred和输入的源语言句子S构成的句对(S,T_Pred)作为负样本.根据以上所述训练方法的设计原理,模型G与模型D联合训练的模型架构如图5所示.
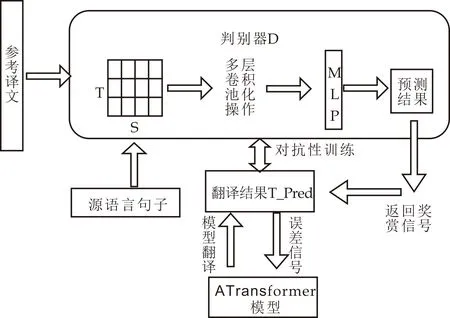
图5 模型G与模型D联合训练的模型架构
因此最终的优化目标为:
ES~Pdata(S),T_Pred~G(·|S)[log(1-D(G(S,T_Pred)))]
(14)
简单来说,模型G根据源语言句子S生成目标语言的翻译结果T_Pred,来欺骗模型D.而模型D目标是能够成功将来自模型G生成的翻译结果和人工的参考译文进行分辨.公式(14)表明,可以提供双语平行对齐对(S,T)以及由源语言句子S和模型G生成的译文T_Pred形成的句对(S,T_Pred),来训练判别模型D.公式(14)包含两部分,外层最小化G和内层最大化D:对于外层最小化G,G希望自己生成的翻译T_Pred越接近参考译文越好,即D(G(S,T_Pred))越大越好,这时目标V会变小.同理,对于D,D希望D((S,T))越大越好,此时V会变大,在实验过程中,先保持G不变,训练D;然后固定D不变,训练G,直到收敛;也就是当D(G(S,T_Pred))接近0.5时,基本收敛.但是难点在于,模型G产生的翻译结果并不是连续值,也就是说很难将误差信号从判别模型D传到生成模型G,来进行训练.因此本文采用策略梯度算法来解决这个问题.根据源语言句子S和模型D可通过最小化下面的损失函数来训练模型G:
Loss=ET_Pred~G(·|S)log(1-D(S,T_Pred))
(15)
现在对需要学习的模型G的参数θG进行梯度计算,利用计算后得到的梯度,使用梯度更新的方式来更新模型G的参数,完成对模型G的训练和优化,梯度的计算如下:
D(S,T_Pred))]=ET_Pred~G(·|S)[log(1-
D(S,T_Pred))θGlog(G(T_Pred|S))]
(16)
可以从模型G产生的翻译句对(S,T_Pred)的分布中进行采样对上面的梯度进行近似计算,得到下式:
(17)
θG←θG-λθG
(18)
其中,λ为超参数学习率.G(·|S)是G产生的条件分布,-log(1-D(S,T_Pred))作为模型D产生的奖赏.从公式(17)不难看出,模型G得到的奖赏越多,那么它所生成的翻译结果T_Pred越可能欺骗判别模型D,并且相对于模型G形成的翻译对(S,T_Pred)的质量将相应的越有利于得到提高.
3 实验结果与分析
3.1 评价指标的设定
为了验证本文所提出的方法的有效性,使用修正的BLEU评测指标,来分析模型翻译T_Pred和人工参考译文T中n元组共同出现的情况,对于一个源语言句子Si(Si∈S),模型的翻译结果T_Predi(T_Predi∈T_Pred),其所对应的目标语言的人工参考译文为Ti={Ti1,…,Tim}∈T.n-grams表示长度为n的词组集合,令wk表示第k组可能的n-grams,hk(T_Predi)表示wk在T_Predi中出现的次数,hk(Tij)表示wk在参考译文Tij中出现的次数,则修正的BLEU对对应语句中语料库级别上的重合精度计算公式如下:
Pn(T_Pred,T)=
(19)
接下来引入一个惩罚因子BP:
BP(T_Pred,T)=
(20)
其中,lT_Pred表示模型的翻译译文语句T_Predi的长度,lT表示参考译文T的有效长度(即如果有多个参考译文时,选取和lT_Pred最接近的长度),最后修正的BLEU指标的计算如下:
BLEU-N(TPred,T)=
(21)
其中,公式(19)、(20)、(21)均出自于文献[19],N代表采用的N-gram模型,本文取值为4,表示对公式(21)的1-gram,2-gram,3-gram,4-gram都进行了考虑,并且对wn取1/N,表示不同阶的语言模型同等重要.
除了BLEU作为模型性能的评估指标之外,在机器翻译中,困惑度指标也是衡量模型泛化能力的一个重要度量,它主要衡量模型所生成译文的流畅性,困惑度越小,译文越流畅,效果越好.其计算公式为:
Perplexity(S,T)=
(22)
其中,公式(22)出自于文献[20],分子表示由源语言和历史翻译生成当前翻译的对数概率之和,分母表示目标语言的句长.
对于训练数据,衡量训练结果的优劣;对于测试数据,可以确定模型的泛化性能以及鲁棒性.
3.2 实验设置及对比分析
为了验证所提出的模型和方法的有效性,模型的开发采用实验数据选择WMT2017中英双语平行语料库.本文将双语语料库上的句子长度限制为30,总共包括大约1 000万个双语句对,其中使用WMT2017中英训练语料库作为训练数据集,newsdev2017作为开发数据集和newstest2017作为测试数据集,词嵌入维度设置为300,并且为了说明模型的鲁棒性,本文将从互联网上爬取的微博语料作为额外的测试语料,微博语料涉及面广,新词较多,通常是衡量一个机器翻译模型性能鲁棒性的比较好的选择.译文的流畅性使用测试语料的困惑度指标来衡量,困惑度越小,译文越流畅.新模型的结果,在下文都会通过实验来验证.
在模型D的训练中使用Nesterov SGD进行优化,使用大小为4的beam search生成所有在训练D的过程中使用的采样样本(S,T_Pred).使用BLEU-4作为评估指标.实验过程中的超参数设置如表1和表2所示.

表1 ATransformer主要参数设置

续表1

表2 判别器D的主要参数设置
模型的训练和测试采用深度学习框架Pytorch,所有模型均在6个NVIDIA K80 GPU上进行训练,每个GPU分配4 000个token,训练时长近60个小时.
在整个过程中,本文首先比较了不同种类的模型的BLEU值随句长的变化情况,其中这些模型分别包括:本文提出的新的训练方法和新模型的结合;新的训练方法和Transformer模型的结合;传统训练方法和新模型的结合;传统方法训练的Transformer;文献[13]所提出的基于深度神经网络的统计机器翻译模型RNN-embed;文献[14]提出的基于神经网络的统计机器翻译模型NN PR.实验结果如图6所示.

图6 不同模型的BLEU分数随句长变化的对比
从图6的结果可以说明,本文提出的新模型和训练方法可以有效提高模型的性能,同时也证明了对于深度模型,聚集层与层之间的输出信息可以有效改善机器翻译的性能,强化学习和对抗性训练进行模型训练,要优于传统的单模型的训练方法;另一方面,也说明了,对于大规模的数据而言,神经机器翻译模型的表现优于统计机器翻译模型.
为了进一步来验证本文方法的有效性,在newstest2017上测试了训练过程中测试集的困惑度随训练过程的变化情况,结果如图7所示.
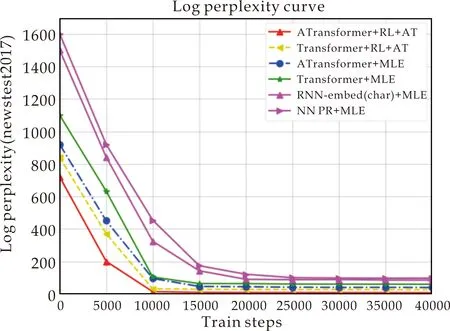
图7 不同模型在Newtest2017测试集上的困惑度随训练过程的表现
新模型是否具有很好的鲁棒性,也是衡量一个模型的泛化能力的重要考虑因素.因此,对于所有的模型,在微博语料上进行困惑度指标随训练过程变化的测试,实验结果如图8所示.
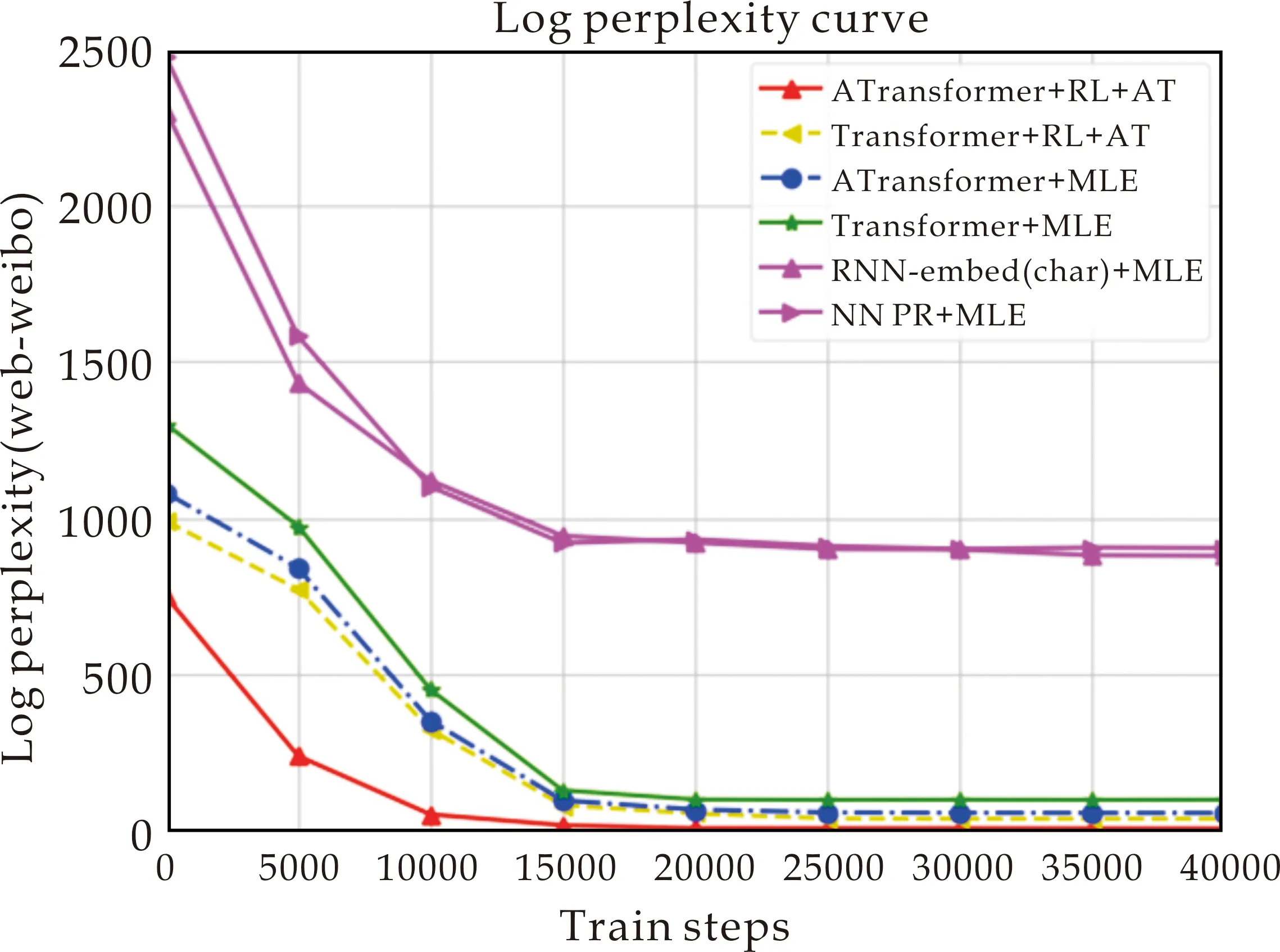
图8 不同模型在微博语料测试集上的困惑度随训练过程的表现
为了量化结果,将实验过程中的重要结果统计至表3所示.
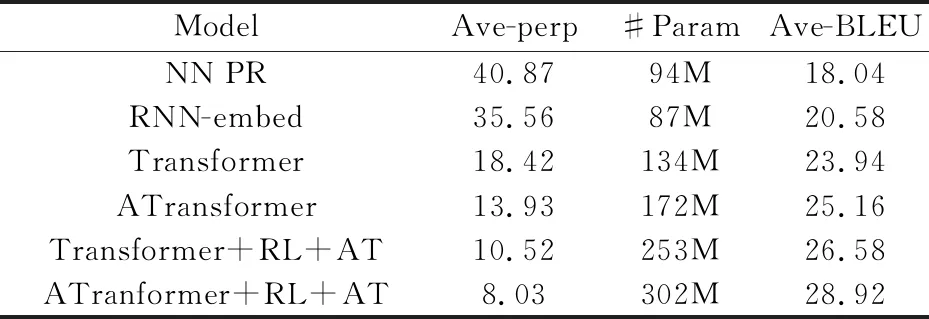
表3 不同方法对比实验结果
需要说明的是,在表3中,第3列表示保存模型参数的文件所占内存的大小,不同于其它文献中参数量的统计方式.本文将参数保存到了ckpt文件中,方便之后模型的调用来完成相关的任务,以便更好地进行fine-tuning.通过以上的分析,可以得出使用ATransformer模型并且结合强化学习方法和对抗性训练的方法可以显著提高机器翻译模型的性能,说明了跨层,融合深度模型层之间的关联信息以及利用强化学习和对抗性训练来优化神经机器翻译模型的方法是有效的.
3.3 算法复杂度分析
通过实验分析,本文所提出的方法在准确性和鲁棒性方面,相较于传统方法,有了很大的提高.对于新方法,结合了attention机制,模型是多个相同层的堆叠,因此,以每一层为研究对象,进行算法的时间复杂度分析,在每一层中,对于主层而言,每一个词都需要编码为固定长度的d维向量,因此,整个输入的计算取决于句长n,而注意力模型,需要对每个词进行计算来关注每个词的权重信息,即也由句长n来决定,所以主层的时间复杂度主要集中于注意力模型的计算,其时间复杂度为O(d·n2),对于序列操作,attention的并行处理机制,使得其将原始的时序操作的O(n)降为O(1),而对于合并层,对于主层的计算结果,合并层主要是对结果进行聚合计算,因此,时间复杂度为O(1).这说明,新方法不仅没有增加额外的时间开销,而且还提升了翻译的性能.但是,从空间复杂度进行分析,宏观上来看,由于新方法增加了对抗训练机制,因此需要更大的空间来存储参数,增加了空间开销,从表3可以直观的看到.这也是无法避免的.
4 结论
本文主要针对Transformer模型进行了改进,并且单独设计了判别器,将强化学习方法和对抗性训练方法相结合,让两个模型相互对抗训练,以此来优化新模型ATransformer的性能.最后,实验结果表明,所提出的方法能够改善机器翻译模型的性能,提高了机器翻译的质量,有助于机器翻译技术的进一步研究.在后续的工作中,会从判别器的结构设计来展开研究,以降低模型的空间开销.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
厦门大学学报(自然科学版)(2021年4期)2021-06-22
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
电脑知识与技术(2019年23期)2019-11-03
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
