
基于改进稀疏栈式编码的车型识别
2020-01-06 02:13代乾龙
计算机工程与应用 2020年1期
代乾龙,孙 伟
中国矿业大学 信息与控制工程学院,江苏 徐州221008
1 引言
在全面建设小康社会的奋斗中,国民经济发展迅速,我国汽车保有量呈现爆炸式增长,使得公路交通安全面临着巨大的挑战。车型分类是智能交通系统中的重要组成部分具有广泛的应用[1-2],包括交通流量统计、智能泊车系统和车型检测。目前,研究人员在车型识别的问题上做了大量的研究工作。Zhang等人[3]提出了一种方法,使用参数化的三维模型对车辆进行分类。他们与通用车辆尺寸进行了比较,得出了车型分类的结果。但是当车辆不完整或多辆车相互遮挡时,该方法效果较差。文献[4-5]提取了车辆的外观特征(例如SIFT[6])以实现车辆类型分类。Zhang等人[7]从车辆正面图像中提取HOG特征,并将这些特征发送到SVM分类器进行车型分类。
目前,基于车型分类研究工作主要分为手工标注特征和深度学习两种。Negri 等人[8]提出了一种基于定向轮廓点的投票算法,用于其多类车辆类型识别系统。Psyllos等人[9]使用SIFT功能识别车辆的标志、制造商和型号。Zhang[10]融合了PHOG 特征和Gabor 变换特征来表示车辆,并提出了一种用于识别车辆类型的级联分类器方案。Peng等人[11]通过车牌颜色、车辆前部宽度和车辆类型分类的类型概率表示车辆。耿庆田等人[12]提出一种新的车型检测方法,将HOG 特征和LBP 特征进行融合。但是这些方法使用的是手工标注的特征,在复杂场景中可能不具有足够的辨别力。刘应新等人[13]利用深度学习通过训练大量的数据来获得车型分类模型,提出前景提取和深度学习相结合的车型分类方法。石磊等人[14]采用caffe 框架利用深度网络对车型进行训练从而识别车型。但是深度学习的训练需要大量的带标注的数据集,需要消耗大量的人力物力成本。
针对传统手工标注和深度学习算法的不足,本文提出一种基于稀疏栈式编码的车型识别方法。利用稀疏栈式编码网络从无标注的数据集上自动学习特征字典,在通过特征字典对图像进行卷积操作,最后利用少量的带标签的数据进行微调。本文算法的网络结构简单(只有四层网络结构),能够自动提取图像特征,在保证分类准确率较高的同时不需要大量的制作好的带标签的数据集。
2 栈式稀疏自编码网络
2.1 稀疏自动编码
自动编码算法(auto-encoder)是神经网络中最常见的一种典型算法,主要用于数据降为或者特征的抽取,其属于无监督学习。对于给定的没有标注的数据集,自动编码算法通过无监督学习方式自动的学习数据集的特征。自动编码算法由三层网络组成,除去输入层和输出层,其内部还有一个隐藏层。自动编码器的目的是在进行系列的训练后,输出值约等于输入值。自动编码器结构如图1所示。

图1 稀疏自动编码网络结构
如果输入层x={x1,x2,…,xm}共有m 个节点,隐藏层h={h1,h2,…,hk}共有k 个节点,输出层和输入层的节点数目相同即,y 是通过隐藏层节点h 对x 的重构。输入层和隐藏层之间的权重矩阵,偏置,隐藏层和输出层之间的权重矩阵为偏置,其中表示隐藏层第i 个节点与输入层第j 个节点之间的权重。是输出层第j 个节点的偏置值。隐藏层h 的第j 个节点为:

输出值为aj=f(hj),其中是sigmoid激活函数。
同理输出层x̂的值为:

在训练过程中,要使得fW,b(x)=x̂≈x,就需要不断地调整权重,使得输入和输出之间的误差J(W,b)最小:

稀疏自动编码(sparse autoencoder)就是对隐藏层施加一个稀疏约束,用尽可能少的神经元来表达原始的数据。如果神经元的输出结果近似于1,则认为它是被激活的,否则认为它被抑制。
在自编码器中隐藏层神经元j 输出的平均激活值为:

在加入稀疏性限制后,自动编码器还需增加额外的稀疏惩罚项,惩罚̂ 和ρ 偏差明显过大的结果,始终保证隐藏层神经元的平均激活值一直在0 的附近。稀疏惩罚项可以有很多种,其中一种KL(Kullback-Leibler)散度定义为:

增加稀疏惩罚项后的损失函数为:
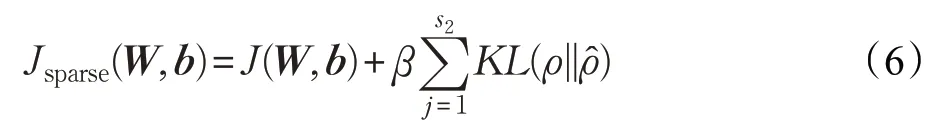
其中β 是惩罚项权重因子。
2.2 栈式稀疏自动编码
栈式稀疏自动编码器是深度学习领域中经常用到的一个学习模型。与单层稀疏自动编码网路相比,栈式稀疏自动编码网络含有两个以上的隐藏层,并且还可以对输入的图像特征进行非线性变换,学习到更加复杂的函数关系,具有更加优秀的表征能力。对于输入的图像,单隐藏层的稀疏自编码器学习到的是原输入图像的一阶特征(比如图像中的边缘)。如果继续增加隐藏层,那么第二个隐藏层会对第一层的特征进行学习,从第一层特征中抽象出更高层次的特征(比如图像的轮廓或者角点等)。栈式稀疏自编码器就是在原来稀疏自编码基础上继续加入隐藏层,增加的隐藏层替换掉原来的输出层。多级别的特征提取使得稀疏栈式自动编码网络拥有较高的容错能力,并且对于图像的平移、旋转等变换具有高度不变性,其结构如图2所示。

图2 栈式稀疏自动编码网络结构
对于如何设置栈式稀疏自编码网络的权重初始值,一种主流的方法就是通过逐层贪婪训练法(greedy layerwise training)来获得合适的权重初始值。该方法通过使用原始图像的数据来训练第一层网络得到网络参数的初始值。然后把第一个隐藏层的输出当作原始输入数据送入第二个隐藏层进行训练,如图3所示。在进行第二个隐藏层训练的时候,第一个隐藏层的参数保持不变,第二个隐藏层的输出即为网络提取的图像的新特征。相比于随机初始值而言,逐层贪婪训练方法会得到更为适合的网络初始值。

图3 第二层稀疏自动编码网络
2.3 softmax分类器
在实际应用中,常见的分类器主要时softmax 分类器和SVM分类器。SVM拿到的是类别的得分,softmax得到的是属于某一类别的概率。结合wolfe[15]等人的研究,softmax分类器更适合本文的车型识别分类。
为了计算每种车型的概率,采用softmax 分类器作为网络的输出层。softmax分类器层的输入是先前经过卷积核池化处理过的特征向量,输出是类别的概率向量。假设训练集为{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))} ,则y(i)∈{1,2,…,k},由于选取的数据集是BIT-Vehicle 数据集,一共有6类车型,所以本文中k=6。给定x(i),假设一个函数来估算每个分类结果出现的概率:


Softmax的损失函数为:

其中,1{⋅}为示性函数,取值规则为1{值为真的表达式}=1。
3 改进稀疏栈式编码
本文算法在传统的稀疏栈式编码的基础上,增加了卷积和池化操作。首先通过稀疏栈式编码提取得到图像的特征字典,之后把特征字典作为卷积核对图像进行卷积操作,进一步提取车辆的更高层的语义特征,增强模型的表征能力。由于卷积后的维数较大,还需对卷积后的特征图进行池化处理,减少计算的成本。改进后的车型识别算法系统流程图,如图4所示。
3.1 卷积
20 世纪60 年代,Hubel 等人研究表明,猫和猴子的大脑视觉皮层含有神经元,它们能够对局部区域做出反应[16]。受到启发,Lecun 等人提出了卷积网络[16](convolutional network),也就是今天所说的卷积神经网络(Convolutional Neural Network)。卷积神经网络的一大特长就是其权值共享结构能够模拟出生物的神经网络。卷积神经网络在很多领域表现都很优秀,尤其是图像处理领域,是现在图像分类、识别等研究领域不可或缺的工具。

图4 改进稀疏栈式编码算法流程图
本文利用卷积神经网络参数共享的思想,使每个隐藏层的节点(神经元)只关注一个特性,只与一部分连续的输入点相连。在上一步通过自编码器提取特征后,把这些提取的特征作为探测器,对图像进行卷积操作,从而在原图像上的不同区域得到不同的特征激活值。假设,图像I 的大小为n×n,通过栈式稀疏编码网络得到k 个特征向量f={f1,f2,…,fk}。特征卷积需要对图像I中所有的w×w(图像patch 大小)的区域计算特征映射,使用一个w×w 大小的窗口对I进行滑动扫描,当某个特征fi与I 的某个区域相关时,则fi对该区域产生映射,得到一个维度为(n-w+1)×(n-w+1)的特征图(feature map)。当对所有的区域进行卷积完成后,得到总维度为k×(n-w+1)×(n-w+1)。对于含有m 幅图像的图像库来说,维度为m×k×(n-w+1)×(n-w+1) 。卷积过程如图5所示。

图5 特征字典对图像进行卷积操作
3.2 池化
从理论上讲,通过卷积层得到的特征层可以直接送入分类器进行分类训练,但是这样往往会带来巨大计算量的问题。例如,对于一个128×128 的图像,采用卷积核为8,则经过卷积得到的卷积特征向量长度为400×(128-8+1)×(128-8+1)=5 856 400。计算困难并且容易出现过拟合的现象。为了防止卷积神经网络的输出维数太大从而导致过拟合的现象的出现,同时也为了减少计算成本,提升运行速度,还需要对卷积后的特征进行池化操作(pooling)。池化是通过计算图像局部区域上的某特定特征的平均值或者最大值等来计算概要统计特征。常见的池化方法分为最大池化(max pooling)、均值池化(mean pooling),计算过程如图6 所示。最大池化可以降低参数误差导致的估计均值发生的偏移误差,更多地保留图像的纹理信息。而均值池化则是减少邻域大小受限造成的估计值方差增大的误差,能保留更多的图像背景信息。由于车型分类更多的参考汽车纹理而不是图像的背景信息,所以最大池化更适合本文的车型分类。

图6 两种池化方法
4 实验与分析
4.1 实验数据以及预处理
本文实验所用的数据集为北京理工大学实验室公布的BIT-Vehicle 数据集,共有9 850 张车辆的图像。图像分别在不同时间和位置由两台摄像机拍摄的。图像包含照明条件,比例,车辆表面颜色和视点的变化。由于拍摄延迟和车辆的尺寸,一些车辆的顶部或底部部分不包括在图像中。在一个图像中可能存在一个或两个车辆,因此每个车辆的位置被预先标注。数据集还可以用于评估车辆检测的性能。数据集中的所有车辆分为6类:公交车(Bus)558张、微型车(Microbus)883 张、小型货车(Minivan)476 张、轿车(Sedan)5 922 张、越野车(SUV)1 392张和卡车(Truck)822张,如图7所示。

图7 BIT-Vehicle数据集样本
在进行训练前,还需要对图像进行预处理,去除图像的噪声,相关性等对特征提取的干扰。常见的图像处理方式有去均值、归一化和PCA/ZCA 白化等。本文采用ZCA 白化方法对数据进行预处理,白化的作用主要是降低数据的冗余性,经过ZCA 白化处理后会降低图像特征之间的相关性,并且所有的特征方差相等,处理后的数据接近原始数据[17]。
4.2 实验结果与分析
本文在BIT-Vehicle数据集测试了算法的性能,在隐藏层神经元节点数设置为400,双隐藏层,字典训练稀疏性参数设置为0.05的情况下,白天场景车型识别准确率达到了80.15%,夜间场景车型识别准确率为74.6%。大多数错误的分类出现在在“SUV”和“Sedan”之间,因为这两种车型之间的外观非常的相似。部分结果如图8 所示。

图8 部分车型识别结果
4.2.1 神经元数量对结果的影响
为了研究隐藏层中的神经元的数量对车型识别准确率的影响程度,设置了不同数量隐藏层神经元进行试验,如图9示。从曲线图中,不难发现,当节点的数目小于400 时,车辆识别准确率随着节点的数目增加而上升。但是当隐藏层节点数目超过400时,车辆识别的准确率并没有提升,反而迅速下降。因此,本文最终选择400个隐藏层节点。

图9 不同数量的隐藏节点对检索结果的影响
4.2.2 不同隐藏层数对结果的影响
同时本文还研究了隐藏层层数对车型识别准确率的影响,在保持其他条件不变的情况下,分别把隐藏层层数设置为单层、双层和三层,并对其进行比较,如表1所示。

表1 不同隐藏层设置比较
根据表1 的结果,如果隐藏层的层数增加,车型识别的准确率也跟着增加。这是因为层数设置的越多,网络结构越深,能提取图像更高层次的特征,使得特征有更加强大的表征能力。在实验中,从单层到双层准确率增长迅速,从双层到三层准确率增长缓慢,但是消耗的时间和存储成本却急剧增加,综合考虑,把隐藏层设置为两层比较合理。
4.2.3 与其他算法比较
本文算法还和其他的一些车型识别算法进行了对比。在微调阶段,选取1 000张图像和5 000张图像作为样本标签进行有监督训练,结果如表2所示。

表2 本文算法与其他算法比较
文献[14]使用的是深度卷积神经网络对来训练车型识别模型,识别准确率比传统的神经网络训练的模型更高,以文献[14]算法为有监督训练模型的典型,与本文算法进行对比。在标签数据集较少的情况小,本文算法表现比较好,当增大标签的数据集时,文献[14]算法识别准确率逐步提高,并有超过本文算法的趋势。但是现实生活中,数据集标签的制作是困难的,本文算法的优点是能够在较小的数据集中有较优越的表现。同时在5 000 张训练集图片,计算机配置为Intel®Core™i5-3470 的同样条件下,本文提出的网络训练时间用时31 min,远小于文献[14]算法的5 h。
5 结论
本文提出了一种改进的稀疏栈式编码车型识别的方法,在传统的稀疏编码的基础上,增加了卷积核池化模块,通过训练得到的特征字典作为卷积核对数据集中的图像进行卷积操作,增强了模型的图像特征的描述能力。同时,本文还对隐藏层的节点个数和隐藏层的层数的选取进行了对比,讨论了不同的隐藏层的节点数和层数对于车型识别准确率的影响。最后,与神经网络进行对比,说明本文算法在少量的有标注数据集上的优越性。
猜你喜欢
车迷(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
中国交通信息化(2020年11期)2021-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
汽车与安全(2015年12期)2015-09-10
车迷(2015年12期)2015-08-23
