
采用最大修改字节重定向写入策略的相变存储器延寿方法
2019-12-18 07:23汪东升王海霞
计算机研究与发展 2019年12期
高 鹏 汪东升 王海霞
1(北京大学工学院 北京 100871)2(清华大学计算机系 北京 100084)3(北京信息科学与技术国家研究中心(清华大学)北京 100084)(gaopeng1982@pku.edu.cn)
相变存储器(phase change memory,PCM)是一种新兴的非易失性存储器件,具有存储密度高和静态功耗低等优点.这在低功耗时代无疑是一个显著的优势.然而,基于PCM的存储技术仍存在写入寿命较低的缺点,使其难以被应用于实际系统,更难以对抗恶意程序.因此,如何延长PCM存储系统的写入寿命,成为该领域研究中的一个关键性问题.
一个典型的PCM存储单元被认为可以承受105至109次写入操作,远低于目前广泛使用的DRAM器件(通常可以承受大于1014次写入)[1].而且一旦采用了多层化技术,PCM单元的寿命还会继续降低.一个实用的PCM存储系统包含了上百万个存储单元,因此决定其寿命的因素不仅应该包括单个存储单元的写入次数上限,还应考虑存储系统的内部结构以及应用的特性.
现代内存系统普遍的构成方式为:多片存储芯片并联、共享访问地址线.因此,一个PCM内存系统的使用寿命问题需要考虑内存系统的结构的影响.一个由多片PCM并联而成的内存系统而言,其寿命取决的因素有:不同地址间的磨损分布和同一地址内的磨损分布.前者指不同地址间的写入频繁程度的差别;而后者指在同一个地址内不同的存储位置,特别是不同存储芯片间的写入频繁程度的差别本文称为片间磨损局部性.
为讨论片间磨损局部性对PCM内存的寿命影响,本文首先收集实际应用的内存写入数据,并分析其在各个存储芯片间的磨损分布的模式.实验结果显示,各存储芯片的修改频度存在一定的不平衡性,且因程序而异.这种局部性会造成某些存储芯片过快达到其写入次数上限而出现故障,进而影响整个存储系统的可用性.
为了解决由这一局部性带来的寿命衰减问题,本文提出了一种称为最大磨损转移(redirecting the most modified byte,RMB)的寿命延长方法.该方法的核心在于保护当前承受最多磨损的存储芯,避免其被进一步的写入.通过为每个存储芯片添加数据比较器和写入计数器,可以识别出在写入时发生了修改的芯片和当前承受了最多写入的芯片.然后,关闭承受了最多写入的芯片的写入,并将未来对该芯片的写入导向到额外添加的长寿命的辅助芯片中.
通过动态的最大磨损转移策略,RMB方法不仅可以减少PCM存储器上的总写入量,而且还可以平衡各PCM芯片之间的写入量差别,从而在整体上延长PCM内存的寿命.此外,相比于广泛使用的磨损均衡方法,RMB方法不会将写入量均摊给那些原本只应该承受较低写入量的存储芯片,从而使其免受额外磨损.
此外,为了测试RMB方法的效能,本文提出了一种基于该方法的混合内存设计方案,称为HPS(hybrid PCM system).该方案采用磁性随机存储器(magnetic RAM,MRAM)作为长寿命的辅助存储芯片.实验结果显示,该设计对于典型测试程序具有良好表现.相比未使用任何寿命延长方法的内存系统,HPS可以最多延长7.9倍的寿命;相比于经典的写减少方法PRES,也可以延长5.14倍的寿命.
本文的贡献包括2个方面:
1)提出了片间磨损局部性是导致相变内存系统寿命衰减的重要原因.
2)提出了一种兼具写减少和磨损均衡效果的方法,可有效对抗因片间磨损局部性引起的磨损.
1 相关工作
延长相变内存的寿命一般可以通过2种途径:平衡存储单元间的写入量差异和减少写入量.平衡存储单元间的写入量差异防止了某些单元被过快磨损而导致的寿命迅速下降问题.Joo等人[2]和Zhou等人[3]分别采用数据周期位移和数据段交换的方案达到这一目标.而Wu等人[4]和Seong等人[5]分别采用地址重映射技术,避免了对某些地址的集中写入,实现了一种可以对抗恶意写入行为的存储系统.Start-Gap以及Region Based Start-Gap[6]方法采用环状队列实现了地址-数据间进行重映射,进而延长了基于PCM的存储系统的寿命.
写减少方法通过减少存储单元的改变次数来降低总的写入量.DCW[7],FNW(Flip-N-Write)[8],Min-shift[9],FlipMin[10],PRES[11-12]是5种典型的写减少方法.其中,DCW仅使用待写入数据作为唯一的一个候选向量来与目标地址已有数据进行比较,并写入相异位.而其他4种方法通过采用位移或编码技术,提供了更多的候选向量,进一步降低了相异位的数量.
为了发挥不同存储器件各自的优势,越来越多的研究开始转向混合使用异质存储器件的设计方案.Dhiman等人[13]、Park等人[14]提出了将DRAM和PCM混合的方案,将小容量的DRAM芯片作为PCM存储系统的缓存,用以缓存经常读写的数据,从而降低存储系统整体的延迟和功耗,延长PCM部分的使用寿命.Joo等人[15]使用了STT-RAM作为PCM的cache,延长了系统的写入寿命.张德志等人[16]实现了一种基于DRAM和PCM的混合内存模拟器,为研究异构存储器的使用提供了便利条件.吴炀等人[17]提出了一种高效的DRAM-PCM混合内存模型及布局机制,并通过使用纠删码提高了系统的可靠性.

Fig.1 Logical and physical structures of the main memory图1 内存的逻辑结构和物理结构
2 研究动机
2.1 内存的逻辑结构与物理结构
内存负责存储运行时处理器需要的数据及其产生的数据.从中央处理器/操作系统的角度来看,内存可以被抽象为1个2维表.每次读写操作的最小原子单位是这个表的1行.本文将其称为1个内存行(memory line,ML).每个内存行通常包含32 b或64 b.每个内存行对应1个地址(address),用于访问该行中的数据.整个内存包含上百万条内存行,所有内存行的地址构成系统可用的物理地址空间.
从构成的角度来看,内存分为存储控制器和存储单元.前者一般集成于中央处理器中,对处理器/操作系统提供一个抽象的内存访问界面;后者负责实际存储数据.存储单元一般由1条或多条DIMM(dual in-line memory module)形式的内存条组成.一条DIMM内存条包含了8或16个存储芯片.这些存储芯片共享地址线,同时进行读取或写入操作.每个内存芯片读写时的数据位宽一般为8 b,即单次访问时的最小读写位数为8 b.此外,基于DRAM的内存存储单元的内部结构还有更精细的结构,包括Rank,Bank,Column,Row,RowBuffer等,但这些结构和本文没有直接联系,在此不做赘述.内存的逻辑结构和物理结构如图1所示:
2.2 问题的提出
现代内存系统通常采用多片存储芯片通过共享地址总线并联而成.因此,当一个数据被写入内存时,每个存储芯片只负责存储该数据的一部分.由于数据的数值分布是非均匀的,因此,各数据分段被改变的概率也不会完全相同.例如当存储大量数值接近零的小整数时,负责存储低位的存储芯片将更加活跃;负责存储高位的存储芯片因几乎总是存储零值而受到相对较少的修改.
数据值分布的不均匀性导致了存储这些数值的存储芯片的改变概率不同.这对于写入寿命近乎无限的DRAM器件而言,并不构成问题.然而,对于写入寿命有限的存储器件如PCM而言,这种和存储位置相关的磨损不平衡性,将会导致负责存储变化频率较大的数据段的芯片承受更多的磨损,缩短其使用寿命,进而导致整个存储系统陷入故障状态.
应对非均衡分布的常用方法是采用磨损均衡技术.这一技术将写入时发生的磨损尽可能均摊到所有存储单元上,从而降低对某个存储单元寿命的集中损耗,进而增加系统的总体可用性.然而,值得注意的是,磨损均衡方法对于承受较少写入的存储单元来说是不公平的.具体而言,本应该承受较少写入的单元将被迫承受从其他负担较重单元转移出的写入负荷.
因此,如果能够构造一种方法,使其可以将额外的写入从负担较重的存储单元中转移出来并加以记录,而又不必将其写入到写入负担较轻的存储单元中,那么这种方法可以同时降低所有存储单元的写入量,以及各个存储单元之间的写入量差异,进而提升整个存储系统的寿命,这就是本文提出的方法的核心思想.
2.3 片间磨损局部性
本文将这种发生在多芯片存储器中的非平衡磨损现象称为片间磨损局部性.常用的时空局部性和数据内容无关,仅和内存行对应的地址重用性有关.因此,在图1(a)中,片间磨损局部性体现在水平方向,各个字节间的访问热度不同.而时空局部性,表现的是在垂直方向,内存访问地址(memory address,MA)之间的访问频度分布.
片间磨损局部性本质上是由数据值分布的非均衡性以及内存的物理结构所共同引起的.例如频繁使用数值较小的二进制数据,将会导致存储低位数据的存储单元频繁发生变化;而存储高位数据的存储单元变化较慢.为了展示数据值和片间磨损局部性之间的联系,本文首先通过数值模拟给与展示,如图2所示.
首先,本文定义一个数据集合D,包含106个定长二进制整数,并假设这些整数服从高斯分布(高斯分布的平均值用mean表示,方差用sigma表示.通过设定均值和方差的关系,可以保证数据集D内99%以上的整数非负,而此时D中的负数所占比例很小,在模拟中被忽略).之后,这些整数将被依次写入到1个8 b的存储单元中,用以观察在不同均值和方差的组合条件下写入数据集D时,各个存储位的磨损情况.如图2所示,磨损分布的变化与数据均值的变化紧密相关,并出现了一定的周期性.当均值为2的幂次时,各个存储芯片几乎被均匀磨损,方差sigma几乎没有影响.当数据均值不是2的幂次时,对于方差sigma较小的数据集,片间磨损局部性更加明显,这是因为更小的方差将导致数据更加集中于某些数值附近,数值间的变化更多地表现为少数几个低位的变化.当方差sigma变大时,数据集合中将出现更多种类的数值,数值之间的差别也会变大,因此整体磨损分布呈现为较为平缓的分布,表明片间磨损局部性较弱.当呈现均匀分布时,即为极限情况.

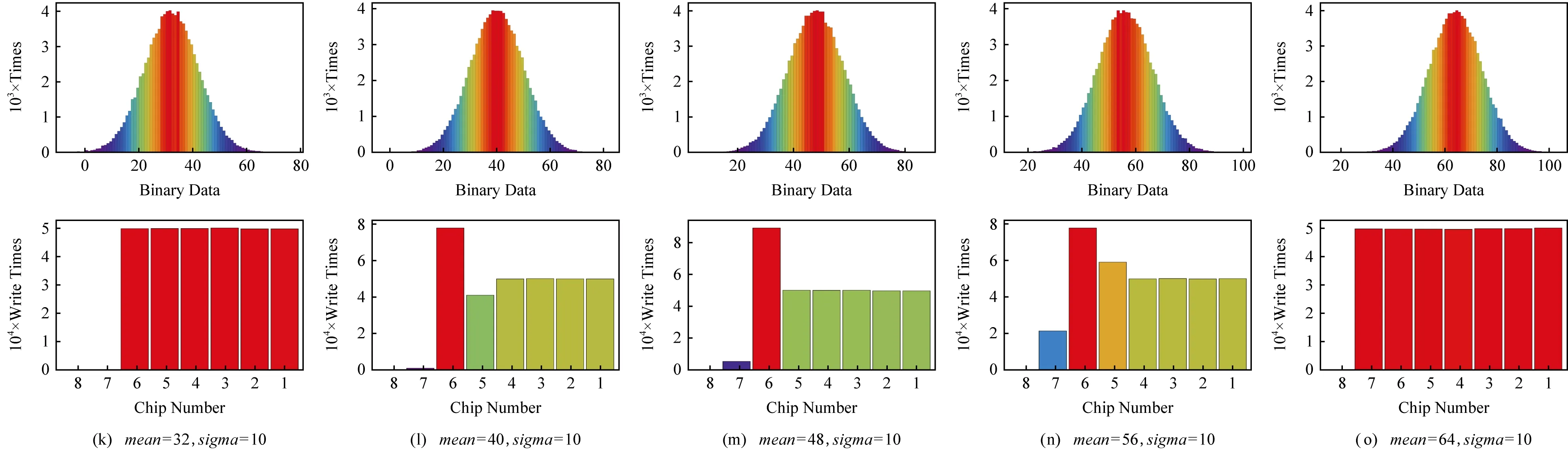
Fig.2 Chips modification with different mean and variation图2 带有不同均值和方差的数据集下芯片间磨损的分布情况
为进一步研究实际应用中片间磨损局部性的情况,本文使用GEM5模拟器运行并收集了12个典型应用的访存踪迹(假设内存是由8个8 b的存储芯片构成,任何1 b发生改变,那么存储该位的存储芯片就被认为发生了1次改写,每个存储芯片的修改概率可以从修改次数和总的写入次数中得到),并统计了各芯片的修改概率.其结果如图3所示.在某些测试程序如libquantum,其芯片1发生修改的概率为芯片3的30倍以上.模拟和测试程序均显示,在多芯片并联构成的内存中,不同存储芯片之间的修改频繁程度,存在着较大的差别,而这一差别必然会影响到由PCM构成的内存寿命.

Fig.3 Variance of modification possibilities across chips with benchmarks图3 测试程序中各芯片间的修改频率的变化示意图
3 RMB方法的设计与分析
3.1 基本思想
片间磨损局部性会导致多个存储芯片磨损程度的差异,进而导致某些存储芯片过快用尽写入寿命.对这一问题的一种解决方法是将这些写入量从受到较多磨损的芯片上转移出来.但是被转移出的这部分写入量仍然需要存储器件来保存.针对转移出的数据的存放问题,磨损均衡方法将其分配给其他轻负载单元.而RMB方法的核心在于将这部分数据转移并存储到附加的长寿命存储器件中,从而同时减少存储器件的总写入量和各存储芯片之间的写入量差异.因此,RMB方法可以被认为是一种兼具写减少和磨损均衡能力的寿命延长方法.
3.2 RMB方法的结构
一个采用了RMB方法的存储系统包含主存储芯片(main storage chip,MSC)、辅助存储芯片(auxiliary storage chip,ASC)、芯片修改次数计数器(modification counter,MC)以及最多被修改芯片指针(most-modified chip index,MCI),其组成框图如图4所示.每个MC负责记录每个对应的MSC的修改次数.每当一个MSC中的某个位置发生了一次修改(写入值与已有值不同),那么该MSC对应的MC就被加1.MCI用于存储目前被最多修改的MSC的编号.ASC包含了数据域(data zone,DZ)、标志域(tag zone,TZ)和有效域(valid zone,VZ).数据域(以ASC.Data表示)用于存放被转移的数据,标志域(以ASC.Tag表示)用于指示被转移的数据属于哪一个MSC,有效域(以ASC.Valid表示)则表示相应的标志域和数据域是否有效.

Fig.4 Block diagram of RMB method图4 RMB方法框图
3.3 读写过程
当给出读取地址后,ASC和各个MSC的同一地址行内的数据都将被读取到内存控制器中.此时,如果ASC行中的有效域被设置,那么其所属的标志域将会被检查,用以发现MSC行中过时的数据字节,这样的字节将被ASC中数据域的对应行的数据代替.如果有效域未被设置,那么说明该ASC行处于无效状态,各MSC字节均为最新数据.此时,内存控制器将读取到的MSC数据转发出去完成读取.
当写入开始时,MSC和ASC中给定地址上的行数据将首先被载入到内存控制器中.根据MCI的内容,以及ASC中有效域和标志域的信息,存在2种可能:
1)如果有效域未被设置,那么ASC中该行的数据域无效.此时,MCI指向的MSC上的待写入数据,将会被写入ASC的数据域,而不是写入对应的MSC中.而标志域也将被修改为当前被映射的MSC的标号.除此之外的各个字节将正常写入各MSC.
2)如果有效域被设置,那么标志域的内容有效,此时,将存在2种分支状况.
① 如果标志域的值等于MCI的值,那么要写入标志域所指向的MSC的字节,将被写入ASC的数据域中,作为更新.除此之外的标志域、MCI以及负责该MSC的MC,均保持不变.
② 如果标志域的值不等于MCI的值,那么标志域所存储的MSC标号,在过去某个时刻曾经是受磨损最多的,而当前已经不再是这样.由于待写入的数据包含了该地址上最新的内容,因此,可以将数据域和标志域视为无效,然后向ASC的数据域直接写入MCI所指向的字节的新数据.而原来标志域所指向的MSC,可以直接用当前最新数据覆盖即可,最后对相应的MC+1.
最后当数据与芯片之间的分配关系确定后,各个MSC和ASC将按照分配的结果完成各自的写入.
3.4 写入过程实例
为了更清晰地展示写入过程,图5给出了1个写入例程.在该例子中,多个数据被连续写入1个应用了RMB系统的某一个内存行.该系统包含2个MSC、1个ASC、2个MC和1个MCI.该例程展示了使用RMB之后的结果之外,还给出了使用理想均衡方法(ideal levelling method,ILM)和不使用任何寿命延长方法(RAW)时的结果.
首先,所有的MSC,ASC,MC都被置为0.
1)当写入数据0x0A之后,MSC#1被修改为0xA,MC#1的值加1,MCI指向MSC#1,如状态1所示.
2)当数据0x0B被写入时,由于此时MCI指向MSC#1,因此该写入将被转移到ASC的DZ中,ASC的Tag也因此指向MSC#1,如状态2所示.
3)当写入数据0xCC时,MSC#2被修改为0xC,而低位数据则由于MCI的导向作用,被写入ASC的DZ中,MSC#1再次得到保护,如状态3所示.

Fig.5 A writing example for the RMB method图5 RMB方法的写入实例
4)状态4与状态3类似,但MCI的值发生了改变.
5)状态5中,数据0xFB被写入,ASC的DZ被修改为0xF,而MSC#1被更新为0xB.最终状态5显示,每MSC都被写入了2次.
不采用任何抗磨损方法的写入结果如状态6所示,状态7显示了采用理想均衡方法的结果.状态5、状态6、状态7的对比显示,MSC的总写入次数得以减少,而且每个MSC的写入量也得到了均衡.究其原因,在RMB方法中当任意一个MSC受到了集中式的写入时,其写入计数就会一直增大,直到大于其他所有MSC的计数,从而引发保护机制,使其未来的写入被导入ASC,从而避免进一步的磨损.不仅总体写入量得到削减,而且各个MSC之间的磨损差异也得以缩小.因此,RMB方法可以被视为是一种特殊的、兼具写入量减少和写入平均能力的寿命延长方法.
4 性能评估
4.1 PCM-MRAM混合内存结构
本文提出了一种实用的内存系统方案HPS,用以作为RMB方法的实现.该方案混合使用了PCM和MRAM作为存储芯片.MRAM与PCM类似,速度较快且具有更长的写入寿命,但存储密度较低,因此MRAM适合小规模的部署于关键位置.
HPS系统的结构分为控制器和存储芯片2个部分,如图6所示.控制器部分包含8个64 b的修改计数器作为MC的实现,1个3 b的寄存器作为MCI的实现.此外,8个8 b的PCM芯片将被作为MSC,1个12 b位宽的MRAM技术构成ASC,包括8 b的数据域、3 b的标志域和1 b的有效域.为了鉴别被修改的字节,该方案使用了比较后写入的方法DCW.该方法在写入前会比较待写入数据和目标地址已有数据,并仅写入相异位.

Fig.6 Hardware structure of HPS图6 HPS的硬件结构
4.2 测试配置
通过在GEM5模拟器中运行测试应用,并记录其读写请求,可以获得这些应用的内存访问踪迹,包括访问地址和新/旧数据.在获得这些数据后,HPS系统可以计算出每个存储芯片的修改次数.本文采用SPEC2006[18]应用来测试HPS的性能.各应用的特性如表1所示,且均使用默认配置.PCM芯片默认可以承受106次写入操作,而MRAM默认可以承受1012次写入操作.测试平台的主要配置参数如表2所示.此外,存储核心的制造差异在本文中不作考虑,并假定整个内存的可用性取决于每一个存储位的可用性,即:如果任何一个存储位到达写入上限,则整个内存被认为进入了故障状态.
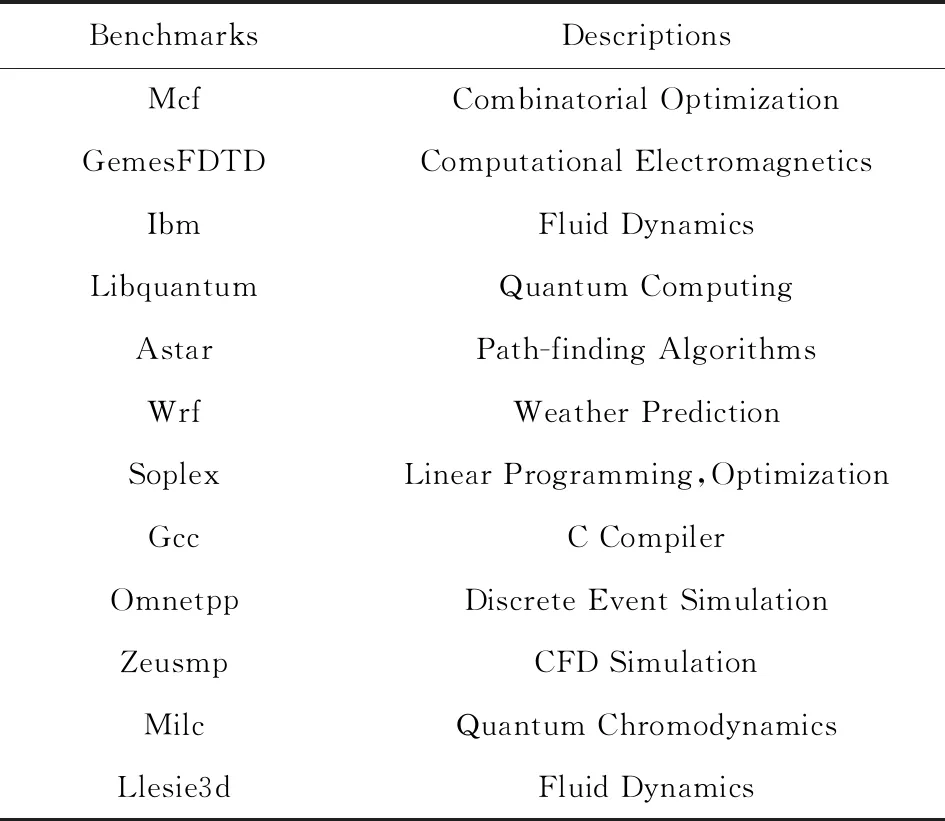
Table 1 SPEC2006 Benchmarks Introduction[18]表1 SPEC2006测试程序介绍[18]

Table 2 Configuration表2 测试平台配置
为了衡量HPS的写入均衡能力,本文采用理想均衡方法ILM和Start-Gap,与HPS系统进行对比.理想均衡方法代表了磨损均衡方法的理论上限,Start-Gap方法则是一种易于实现的经典磨损均衡方法.为了公平比较,本文在Start-Gap方法的思想上进行了一定的修改.原始Start-Gap方法在内存地址之间留了一个移动数据用的间隙(gap),而本文实现的Start-Gap方法,为每个内存行定义了一个循环队列,该队列包含各个存储芯片的对应行.因此,该方法需要一个和ASC的数据域同样大小的存储空间作为Gap,需要和ASC的标志域同样大小的存储空间存放Gap的位置标号.采用Start-Gap方法将和HPS系统的实现代价非常接近,因此两者的对比是公平合理的.
为了衡量RMB方法的写减少效果,本文使用典型的写减少方法FNW和PRES作为对比方案.为了保持硬件开销的公平性,FNW方法的翻转状态标志位为8 b,即每8 b的数据对应1个翻转状态标志位.PRES方法的编码向量编号为8 b,即使用28个候选向量.
比较寿命时,本文采用的方法:将采集的各个测试程序的访存踪迹模拟写入PCM存储单元,记录其被改变的次数.此时,某个存储单元上的最高改变次数被认为是该程序造成的最大写入计数,并以其倒数作为寿命.同样的过程应用于不同的寿命延长方法,包括RAW等参考系统.然后,以RAW方法下的寿命为1,对所有数据做归一化处理能得到各个方法的归一化寿命延长结果.
4.3 与经典磨损均衡方法的对比
与不采用任何寿命延长方法的内存相比,HPS系统可以延长其寿命多达7.9倍,如图7所示.特别是对于片间磨损局部性较强的应用,如mcf,libquantum,HPS的表现甚至优于ILM.然而,对于芯片间的修改概率差别较小的应用,如lbm,soplex,gcc,HPS系统比ILM略有差距.但理想均衡方法是此类方法的理论上限,一般的磨损均衡方法是无法达到这一性能的.因此,在大多数情况下,HPS系统优于Start-Gap方法.

Fig.7 Endurance comparison among 4 methods图7 4种方法下的相变内存寿命比较结果
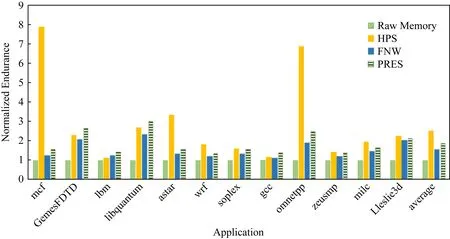
Fig.8 Endurance comparison among 4 methods图8 4种方法下的相变内存寿命比较结果
4.4 与经典写减少方法的对比
对于那些片间磨损局部性较强的程序,如mcf,libquantum,omnetpp而言,HPS系统的表现优于FNW方法,对比结果如图8所示,其原因在于FNW的起效条件.FNW方法仅在相邻写入数据的相异位数量超过字长一半的情况下才会生效,否则该方法将等同于DCW方法.因此,对每次翻转位数较少的程序而言,FNW方法难以奏效.
HPS系统也优于经典的写减少方法PRES.究其原因,对于片间磨损局部性较强的程序,前后相继的2个写入数据一般也具有较少的相异位.由于PRES方法只能保证无偏数据集上的平均写入量减少效果最优,而无法保证在数据集有偏的条件下,特别是相邻写入数据相异位较少时的效果.在这种情况下,PRES的随机映射机制,可能反而会增加相邻写入数据的相异位.如图8所示,HPS系统比经典的PRES方法可以最多延长达5.14倍的寿命.
4.5 实现代价分析
本文以存储芯片数量作为衡量各方法实现代价的指标,并采用相对值进行比较.一个典型的、不带有任何寿命延长方法的内存系统,通常是由8个8 b的存储芯片构成,即每个内存行为64 b.以该系统将作为对比基础,其实现代价定为100%.
HPS系统在基础系统之上,为每个内存行添加8 b的存储空间、3 b标志域和1 b作为有效位.因此,其相对存储代价为(64+8+3+1)/64×100%=118.75%.除此之外,HPS系统还需要8个64 b的全局修改计数寄存器,1个3 b的寄存器作为MCI,以及8个64 b的加法器对MC执行加法操作.
Start-Gap方法同样需要一个额外的存储芯片作为Gap.因此每行内存需要额外的8 b存储空间作为Gap,以及3 b的Gap位置指针.因此,其存储代价为(64+8+3)/64×100%=117.2%,略低于HPS系统.
FNW和PRES方法同样需要额外的存储空间.这2种方法均采用每64 b的存储空间附加8 b标志位的方式实现,因此其对应的存储代价为112.5%.
4.6 读写时间影响分析
RMB方法的读操作比其它正常的读取流程来说,多加了一个ASC有效域的检查步骤,即单个位是否为1的检查.鉴于PCM存储器的读取时间比DRAM要长得多,因此,这一检查步骤完全可以利用读取延迟隐藏.之后的数据选择传输过程可以采用多个2选1选择器实现.如图6所示,RMB方法的读取过程,额外需要1个选择器.而由其带来的延迟远小于PCM器件的读取延迟,几乎可以忽略.
RMB方法的写入过程稍显复杂.最长的写入路径包括了ASC的标志域和有效域的2次检查、MCI、标志域和有效域的写入.但是PCM技术的写入延迟更大,几乎可达读取延迟的10倍左右.因此,增加的写入时间延迟,在总的时间延迟中所占的比例很小.
5 对RMB方法的进一步讨论
本文介绍了RMB方法的工作流程、实现、性能以及实现代价.为了更好地研究这一方法,本节将对其做进一步的讨论.
RMB方法可以类比于cache系统.cache系统基于时空局部性,根据访问地址的被访问频度决定是否缓存该地址内的数据,且缓存的最小单位是本文中定义的一个内存行;而RMB方法是建立在片间磨损局部性的基础上,根据被修改芯片的写入计数来决定是否缓存该位置,且缓存的最小单位是一个字节.
RMB也是一种使用缓存的方法,本文提出的RMB方法,仅设计为跟踪一个存储芯片,这是基于实现代价的考虑.因此其必然存在由于容量限制而导致的替换发生.对发生在同一内存行的多个位置上的写入,这一设计处理能力是不足的.但如果放宽实现代价限制,那么RMB方法完全可以扩展为采用多个ASC芯片的实现方式,且其主要组成和工作流程非常相似.这种扩展的RMB方法称为RMBK,其中参数K代表采用了K个ASC芯片.RMBK方法尽管代价较高,但可以跟踪并转移同一内存行中K个存储位置发生的改变,从而更好地提高PCM内存的寿命.
此外,RMB方法对2个存储芯片交替写入而导致的颠簸现象也有一定的防御能力.首先,颠簸现象实际上在RMB系统中也是不容易出现的.其原因是:1)要达到颠簸状态,先要求2个存储芯片的总写入计数完全一样,否则只会继续磨损那个计数值较小的芯片;2)交替写入的内容必须出现在同一内存行中,否则,会被2个不同行上的ASC分别吸收.之后,某一内存行的频繁写入操作会导致该内存行被长期缓存在上级cache中,也就是说这些写入操作事实上都是发生在cache中,而几乎不会发生在内存一级.综上所述,以上这些条件限制了颠簸出现的可能性,因此避免了在实际程序中遇到这类问题.而且,即使在出现颠簸的情况下,RMB方法也仍然能够使用ASC芯片来吸收至少一半的写入量.
6 结 论
针对相变内存写入寿命不足的问题,本文首先在结合内存系统结构的基础上,分析并提出了片间磨损局部性的概念,并指出该局部性是导致相变内存寿命损失的一个重要原因.为了解决这一局部性带来的问题,本文提出了一种称为RMB的相变内存寿命延长方法.通过关闭已承受最多磨损芯片上的未来写入,并将这些写入转移到附加的长寿命存储芯片中,该方法兼具了写减少和磨损均衡的效果.实验证明,其寿命延长的能力在某些情况下甚至优于理想磨损均衡算法.此外,该方法也可以方便地与其他寿命延长方法相互结合,更好地延长存储器的写入寿命.
猜你喜欢
科技视界(2022年10期)2022-05-20
能源工程(2022年1期)2022-03-29
文萃报·周五版(2021年35期)2021-09-13
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
电脑知识与技术·经验技巧(2018年5期)2018-09-29
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
科教导刊·电子版(2016年36期)2017-04-22
电脑爱好者(2015年21期)2015-09-10
