
池化和注意力相结合的新闻文本分类方法
2019-12-04 03:15陶永才杨朝阳
小型微型计算机系统 2019年11期
陶永才,杨朝阳,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001)2(郑州大学 软件技术学院,郑州 450002)
1 引 言
文本分类(Text Categorization)是指依据文本的内容,由计算机根据某种自动分类算法,把文本判分为预先定义好的类别[1].文本分类属于数据挖掘和信息检索的前提性工作,也是自然语言处理领域的常见任务[2].
近年来,在大规模数据集的文本分类工作中,基于神经网络的深度学习算法取得了良好的效果,成为主流方法.但是与传统的机器学习算法相比,深度学习算法存在模型参数多、时间复杂度高等不足,导致模型的训练时间长、所需计算资源大.此外,在长文本分类中,深度学习算法的训练时间长、迭代速度慢的缺点更加明显,而新闻文本就属于一种信息密度大的长文本数据.
为解决上述问题,本文提出了一种结合池化操作和注意力机制的简单模型,池化操作用来提取文本的有效特征,注意力机制能够关注到文本中的关键信息.实验表明,该模型应用于新闻文本分类任务时具有速度快且正确率高的优势.
2 相关工作
在深度学习广泛应用于自然语言处理领域之前,统计机器学习是文本分类中的主要方法.常见的机器学习分类算法主要有SVM[3]、朴素贝叶斯[4]、决策树[5]等.一般来说,机器学习算法构造的分类模型首先需要人工设计文本特征,然后训练模型学习特征,最后给出分类结果.在小规模数据集上,这些模型取得了不错的结果,而且计算速度快、可解释性强.不过这类方法需要事先标注特征,特征的好坏直接影响了分类器的效果,对数据集质量要求高,同时难以考虑词义信息.
近年来深度学习算法在文本分类任务上得到了广泛应用,能从大规模数据集中自动学习特征.深度学习是指基于深度神经网络的机器学习算法,深度神经网络主要可以分为卷积神经网络CNN(Convolution Neural Network)、循环神经网络RNN(Recurrent Neural Network)等[6].CNN最早应用在图像领域,由LeCun等[7]提出,后来在自然语言处理领域中应用于关系分类和句子分类,其基本结构是卷积层加池化层.当CNN的卷积层数增加时,模型能提取更深层的特征,但会遇到梯度消失的问题.于是Kaiming He等[8]提出了残差结构,将上一层的梯度通过额外的映射传递到下一层,很大程度上缓解了梯度衰减,让CNN的性能得到了大幅增强.RNN由Elman等[9]提出的简单循环网络改进而来,因为RNN能够对变长序列进行处理,它在语音识别和文本处理上应用广泛,其基本结构是对序列的循环编码层.针对时间序列的长期依赖问题,产生了RNN的一些改进:长短时记忆网络LSTM[10](Long Short Term Memory)和门循环单元GRU(Gate Recurrent Unit)[11].Gers等[12]首次将LSTM应用在文本分类上,相对机器学习算法取得了显著提升,进一步双向LSTM也被引入文本处理领域,Bi-LSTM(Bi-directional Long Short-Term Memory)的特点在于不仅可以提取前文特征,还可以获得后面序列的特征.在Bi-LSTM的基础上,Sutskever等[13]提出了结合注意力机制的Seq2Seq模型,该模型在包括文本分类的多个任务上得到了成功应用.
深度学习方法虽然能从大规模数据集中自动学习特征,但存在可解释性差、收敛时间长等不足[14].考虑到深度学习模型复杂性,一些简化的模型被提了出来,它们也能在大规模数据集上得到很好的效果.Joulin等[15]提出FastText模型,该方法基于CBOW(Continuous Bag of Words)语言模型,构造了一种基于词向量平均的非线性分类器.Shen等[16]提出SWEM(Simple Word Embedding Model)模型,该方法基于词向量的最大池化和平均池化,没有使用深度神经网络.Vaswani等[17]提出生成模型Transformer,该模型使用多个并行的注意力层进行编码,在机器翻译上获得了突破,证明了注意力机制的编码效果优于LSTM.Shen等[18]使用双向自注意力机制的分类模型DiSAN(Directional Self-attention Network),在文本分类、文本推理等多个数据集上取得良好效果,该模型未使用CNN与RNN结构,仅包含了前馈神经网络.
本文提出的注意力池化模型与SWEM模型相关,其基本思想是对词向量直接进行池化操作,以最大限度地保留词义信息.考虑到新闻文本的特征,本文加入了注意力机制用于提取长文本的全局特征,并在中文新闻数据集上进行了实验.
3 基于池化的分类模型
本文提出的结合了注意力机制的池化模型主要包含两部分:池化层和注意力层.模型结构如图1所示,下面对该模型各部分进行详细描述.
3.1 词嵌入层
词嵌入层的作用是将文本编码成词向量.该层输入的是一个l×b的文本矩阵,其中l是文本的固定长度,b是批处理的文本数量.然后将文本中的每个词转换为词向量,得到用词向量表示的文本序列s=(ω1,ω2,…,ωn),其中n为每个文本序列的长度,词向量ω∈Rd,d是词向量维数.最终词嵌入层的输出是一个l×b×d的词向量矩阵.
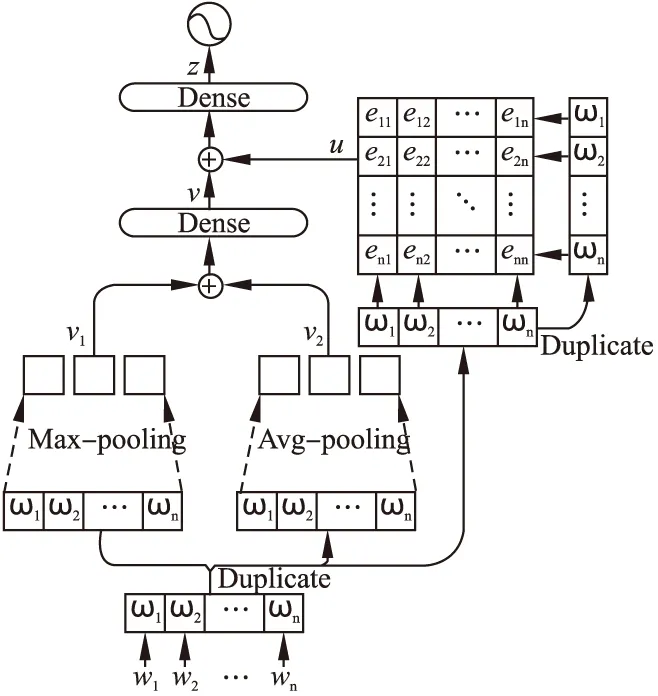
图1 注意力池化模型结构图Fig.1 Attention pooling model structure chart
3.2 池化层
池化层的作用是提取词向量序列中的全局特征,该部分包括最大池化和平均池化.词向量上的每一维反映了不同信息,池化操作能提取词向量中的综合信息.池化层的操作如图2所示.图2的左侧代表最大池化操作,即在每个词向量的相应维度上取最大值;图2的右侧代表平均池化操作,即在每个词向量的相应维度上取平均值.

图2 词向量池化操作示意图Fig.2 Word vector using pooling operation schematic diagram
最大池化的具体操作是在词向量矩阵的每一维上开辟一个滑动窗口,提取窗口中文本序列中所有词在某一词向量维度上的最大值.词向量的值的大小代表词与文本信息的相关性,所以最大池化每个窗口提取的是相关性最大的那个词,不相关的词则被过滤掉.在池化层对s进行最大池化操作.最大池化操作的形式化表示如式(1)所示.
v1=Max-pooling(ω1,ω2,…,ωn)
(1)
其中,v1表示最大池化操作后得到的向量.
平均池化是计算滑动窗口中所有词在某一词向量维度上的平均值,与最大池化不同,平均池化提取到的是文本序列上所有词的综合信息.在池化层对s进行最大池化操作的同时也进行平均池化操作.平均池化操作的形式化表示如式(2)所示.
(2)
其中,v2表示平均池化操作后得到的向量,ωj表示序列s上某一维词向量的数值,j∈[1,n].
考虑到最大池化保留了词向量的突出信息,平均池化保留了全部词向量的信息,所以接下来对最大池化、平均池化的结果作向量拼接,之后通过一个全连接层F得到文本v,其形式化表示如式(3)所示.
v=F(v1⊕v2)
(3)
其中,⊕表示向量的拼接操作.
3.3 注意力层
注意力层的作用是注意到和整体文本序列关联最紧密的局部特征.注意力机制是给定一个查询,将模型的学习更集中在与查询最相关的部分而非所有能获取的信息上,过滤掉不相关的信息,能在一定程度上减少计算量.本文采用自注意力机制来获取文本中最重要的特征,自注意力机制的特点在于查询是文本内部的词,最后计算所有词的权重分布.
注意力层能得到各个词的权重,权重代表了词在文本中的重要程度,最终通过词的加权平均合成文本的表示u.本文对词的打分函数使用多层感知机,以反映词之间的相关性.自注意力机制的计算方法如式(4)~式(6)所示.
(4)
eij=f(ωi,ωj)
(5)
(6)
其中,ai代表词对文本的注意力权重,⊙代表点乘操作,即向量间逐元素相乘,eij代表某个词ωi与另一个词ωj通过打分函数得到的分数,f代表多层感知机构成的打分函数.
3.4 输出层
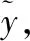
z=G(v⊕u)
(7)
(8)
4 实验设置
本节主要介绍注意力池化模型在中文新闻文本分类任务上进行实验的相关设置.
4.1 实验数据
本文采用NLPCC2014中文新闻分类评测数据集1http://tcci.ccf.org.cn/conference/2014/pages/page04_eva.html.该数据集具有两级类别层次,一级类别包括24类,二级类别包括367个类.每个样本由新闻标题、新闻内容、一级类别、二级类别组成,图3给出了样本的格式.
训练集中包含42689个样本,测试集中包含11577个样本,训练集和测试集在类别分布上具有一致性.训练集中的样本平均长度为470.6个词,属于长文本数据.在去除虚词等停用词后,样本的平均长度为425.7个词.
4.2 数据预处理
数据集的预处理阶段包括分词、去除停用词等.原始样本处理后有新闻标题、新闻内容和一级标签,为保留更多特征,实验中将新闻标题与新闻内容合并.实验使用开源的jieba-0.39中文分词工具2https://github.com/fxsjy/jieba对新闻文本内容进行分词.分词后将每个文本采用较短补零、较长截断的方式统一成固定长度,以方便矩阵运算.实验中固定样本长度设为420.
实验采用的预训练词向量由SGNS[19](skip-gram model with negative sampling)模型在中文语料库上训练得到,向量维度为300.最后得到的有效词向量个数为20542.对于训练后词表中的未登录词,使用[-1,1]内随机生成的300维向量初始化.

图3 数据集格式
Fig.3 Data set format
4.3 评价指标
本文将宏查准率、宏召回率、宏F1值作为评价指标.其中,宏查准率MacroP用来评价分类器的正确率.宏召回率MacroR用来评价分类器的覆盖率.宏F1值MacroF1是宏查准率与宏召回率的调和平均值,用来评价分类器的综合性能.它们的计算方法如式(9)~式(11)所示.
(9)
(10)
(11)
其中,n代表类别总数,correctk代表正确分类为类别k的标签数目,predictk代表分类为类别k的标签总数,truek代表数据集中真实为类别k的标签数目.
本文还将正确率作为评价指标,用于评价总体的分类效果.正确率Accuracy的计算方法如式(12)所示.
(12)
其中,correct代表所有分类正确的样本数,alldocuments代表数据集中的样本总数.
4.4 训练环境
训练环境为:Python 3.6,Tensorflow-GPU-1.4.0,GPU NVIDIA 1080ti,11G显存,16G内存,1TB硬盘,操作系统Ubuntu 16.04.主要超参数设置如下:dropout率设为0.7,词向量维度设为300,全连接神经网络上的learning rate设为0.003,batchsize设为64,固定句长设为420.
训练过程中优化算法采用Adam optimizer,损失函数采用交叉熵函数,另外使用早期停止策略(early stopping)预防过拟合.模型在验证集上训练取得最好表现后在测试集上进行测试.
5 实验结果与分析
本节主要介绍注意力池化模型在中文新闻文本数据集上进行的相关实验及分析.
5.1 模型对比
为了验证注意力池化模型的有效性,本文将其与标准的深度学习模型CNN、LSTM以及池化模型SWEM进行了比较.基准模型为SWEM,各个模型的超参数设置与注意力池化模型中全连接神经网络层的相同.各个模型在训练集上的正确率对比结果见表1.
表1 模型对比结果
Table 1 Model comparison result

Accuracy/%MacroP/%MacroR/%MacroF1/%CNN74.9776.3279.2677.68LSTM72.5371.5673.1271.82SWEM79.5176.9675.8876.42OURS83.9678.7477.5178.12
如表1所示,注意力池化模型在测试集上达到了83.96%的准确率,优于标准的CNN、LSTM模型以及池化模型SWEM,并且在迭代速度和迭代次数上都存在优势.CNN模型的准确率达到了74.97%,效果不如SWEM和注意力池化模型,是由于对于长文本来说,CNN能提取出局部特征,但是不能注意到整个文本中最重要的部分,CNN分类的MacroF1值最高,证明其在各个类别上的准确率较好.LSTM在测试集上达到了72.53%的准确率,虽然LSTM能兼顾上文的信息,但是由于新闻文本的长度较长,LSTM中遗忘门会丢弃过长之前的文本特征,LSTM中的记忆门只会记住一段长度前的信息,导致在过长的文本处理中,正确率反而会有所下降.模型速度对比结果如表2所示.
表2 时间复杂度对比结果
Table 2 Time complexity comparison result
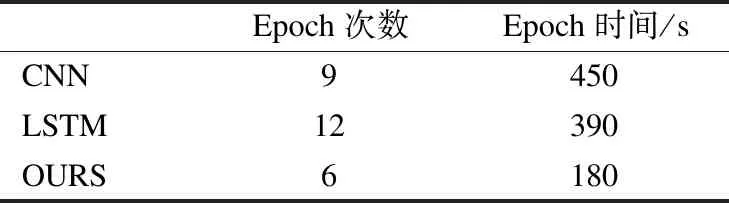
Epoch次数Epoch时间/sCNN9450LSTM12390OURS6180
由表2可以看出注意力池化模型在运算速度上也存在一定优势,在达到相同的最高准确率75%时,注意力池化模型用了6次epoch,共3min,而CNN模型用了9次epoch,共7.5min,LSTM模型使用了12次epoch,共6.5min.
实验对不同长度样本上的分类结果进行了统计,其中超过200长度的样本共34269条,正确分类的样本数为28450;不超过200长度的样本共8420条,正确分类的样本数为6399.注意力池化模型在超过200长度样本上的分类正确率为83.21%,不超过200长度的分类正确率为76.61%.结果表明在注意力池化模型上,长文本的分类效果较好.在长度小于200的新闻文本中,正确率不高的原因除了更短的新闻文本蕴含着更少的类别信息外,更多在于本文的模型难以提取到较短新闻文本中的类别特征.
5.2 简化测试
为了评估注意力池化模型中各个部分对于整体性能的贡献度,本文对模型进行了简化测试,即分别去除模型中某个部分,然后统计正确率的变化情况,实验结果如图4所示.结果表明最大池化部分对整个模型的贡献度最大,因为在去除最大池化部分后,整个模型正确率下降了8.45%,下降得最多,这和最大池化的操作有助于捕捉新闻文本的信息的假设是相符的.去除注意力部分后,模型性能下降了3.93%,下降得最少,说明注意力机制对整个模型贡献度最小,但是在加入注意力机制前,单纯的池化模型的正确率为80.03%,自注意力机制的添加使得池化模型得到了一定程度的提升.而去除平均池化部分后,模型性能下降了6.32%,证明平均池化也在整个模型的性能中起到比注意力更重要的特征提取作用.
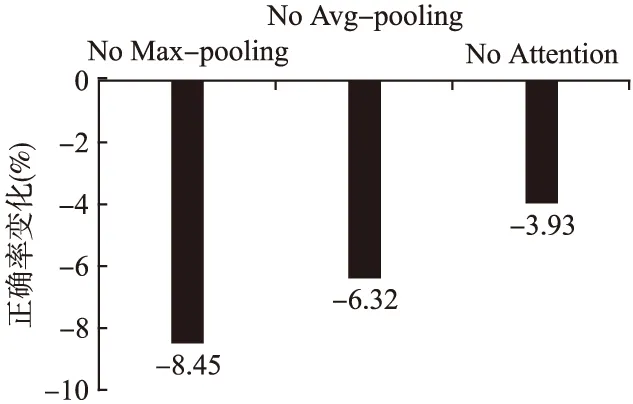
图4 模型简化测试结果Fig.4 Ablation study result
5.3 泛化能力分析
为了评估注意力池化模型的泛化能力,本文在整个数据集上做了五折交叉验证实验:将训练集与测试集的所有样本随机打乱,划分成五组分别进行训练和分类.实验结果如图5所示.交叉验证中各组的正确率都在82~84%之间,F1值的变化也相对平缓,说明整个模型稳定性强.正确率未达到最佳的原因在于训练集和测试集在划分五组的时候采用了随机打乱并划分,导致与标准测试集存在一定偏差.
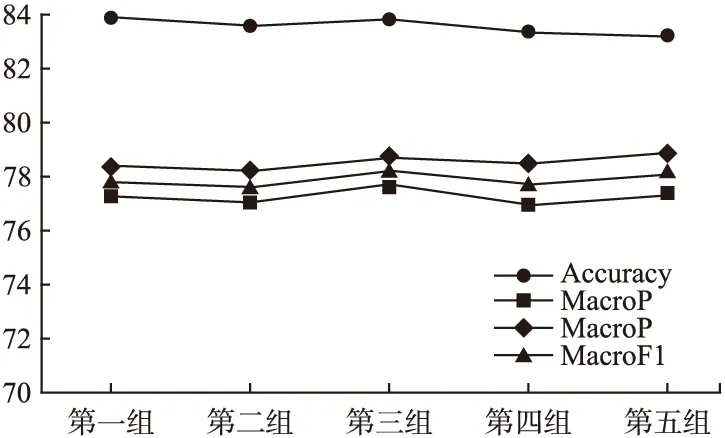
图5 五折交叉验证结果Fig.5 5-fold cross-validation result
在确定超参数dropout率时,本文统计了不同dropout率在训练集和测试集上对模型正确率的影响,如图6所示.由测试集上的正确率变化看出,当dropout率小于0.7时,模型表现出欠拟合;dropout率大于0.7时,模型出现过拟合现象.因此dropout率最终使用表现最好的数值0.7.
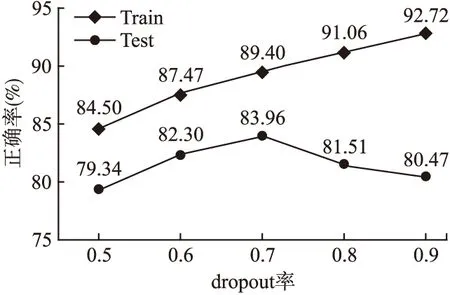
图6 dropout率对模型正确率的影响Fig.6 Effect of dropout on accuracy
6 结论与展望
在中文文本分类工作中,采用深度神经网络算法存在训练时间长等不足,因此本文提出了一种基于最大池化的模型.考虑到新闻文本的特征,该模型加入了自注意力机制.由于注意力机制能从长文本的编码中获得到更关键的信息,本文的模型更适合于长文本的特征抽取.最终注意力池化模型在NLPCC新闻数据集上达到了83.96%的正确率,相对标准深度学习算法,在保证正确率的情况下保持有速度优势.
目前模型存在的不足有对于短文本的处理效果并不理想,准确率还未达到最佳.为了使准确率进一步提高,下一步工作可以对该模型的编码部分继续改进以更好地提取句子特征,以及将其应用在其他更多领域的数据集上.
猜你喜欢
计算机应用(2022年9期)2022-09-25
医学食疗与健康(2022年3期)2022-04-23
软件导刊(2022年3期)2022-03-25
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
软件(2018年1期)2018-02-05
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
