
基于聚合度热点适应机制的网络舆情大数据收敛算法
2019-12-04 02:31:56孙骏
井冈山大学学报(自然科学版) 2019年6期
孙 骏
基于聚合度热点适应机制的网络舆情大数据收敛算法
孙 骏
(安徽职业技术学院信息工程学院,安徽,六安 230011)
为解决当前网络舆情大数据收敛算法普遍存在的收敛困难及热点聚类生成速度较低等难题,提出了一种基于聚合度热点适应机制的网络舆情大数据收敛算法。首先,通过增量用户节点与存量热点之间的信息交互关系,设计了一种基于聚合度初始化机制的数据收敛方案,采用匹配机制逐个对存量热点与增量用户节点间差异度及聚合度进行比对,能够将增量用户节点纳入性能最佳的存量热点所形成的种子聚类,提高聚类形成速度。随后,针对热点数量处于密集状态等极端情况,特别是用户特征匹配过程中难以实现快速匹配等不足,设计迭代方式,以逐步消除种子聚类差异度,提升大数据匹配性能,改善用户节点与热点之间信息交互质量。仿真实验表明:与当前常用的时间片累积挖掘收敛方案(Convergence Scheme for Time Slice Cumulative Mining,TSCM算法)及热点度显影收敛方案(Convergence Scheme of Hotspot Degree Development,HDD算法)相比,本文算法具有更高的收敛速度和聚类形成质量。
聚合度;网络舆情;热点;差异度;聚类匹配;热点度显影
0 引言
在5G技术的推动之下,各种新兴超宽带应用如视频直播、远程高清授课、4K超高清在线视频等业务也不断呈现爆发式增长态势[1]。由于这类应用主要以用户为单位进行业务推广,因此采取一定方式搜集用户行为特征,获取相应网络舆情大数据信息,成为当前业界及监管部门的热门研究领域之一[2]。
Tzy等[3]提出了一种基于时间窗累计热度均值差分机制的网络舆情大数据收敛算法,该算法通过对热度较高的用户集群进行累计统计,并引入数据挖掘算法进行时间窗滑动的方式,实现对网络舆情大数据快速匹配,具有良好的用户粘度。然而,该算法需要耗费大量资源进行数据建模及窗口滑动,收敛性能较差。Shu等[4]提出了一种基于热点度聚类分割机制的网络舆情大数据收敛算法,该算法主要通过预设热节点方式,并在数据收敛周期内进行热点聚类捕捉,能够适应有快速匹配需求的具体场景,特别适用于网络监管等领域。不过,该算法与文献[3]存在类似的缺陷,均存在资源耗费严重的问题,从而在相当程度上制约了该算法的实际部署应用。Wei等[5]提出了一种基于人际关系热点显影机制的网络舆情大数据算法,该算法主要针对人际关系热点与网络舆情大数据之间存在的线性关系,以人际关系热点为数据建模口,实现关系密切条件下网络舆情大数据样本的高速收敛,具有很强的实际部署价值。然而,该算法需要首先对关系数据库进行全样本入库,存在一定的数据泄露风险。此外,算法运行过程中严重依赖E-R映射关系,相当程度上存在较为严重的收敛缓慢难题。
鉴于当前算法普遍存在的待改进之处,本文提出了一种基于聚合度热点适应机制的网络舆情大数据收敛算法。首先通过分析增量用户节点与存量热点之间的信息交互关系,设计了一种基于聚合度初始化机制的数据收敛方案,该方案能够显著提高聚类生成速度。随后,本文基于迭代思想构建基于热点适应-差异度迭代的快速匹配方法,显著改善热点与用户之间交互质量,进一步提高算法收敛速度。最后通过MATLAB仿真实验,证明本文算法所具有的优越性能。
1 本文用户及行为模型分析
网络舆情大数据挖掘过程中首先需要分析用户行为及用户特征集合[6-7],实践中将用户行为、用户特征看作是一个有向图,见图1。其拓扑形式如式(1):

其中,为有向图,为用户特征,为用户行为。
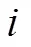
设和为两个不同的热点用户形成的初始聚类,聚类之间的重合节点为(,),见式(2)。

其中为和的具有联系的用户节点,若和之间无重合,则为空集;若和有之间有共同的隶属关系,则(,)可根据实际情况加入不同的初始聚类。
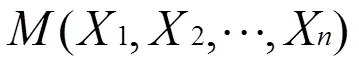
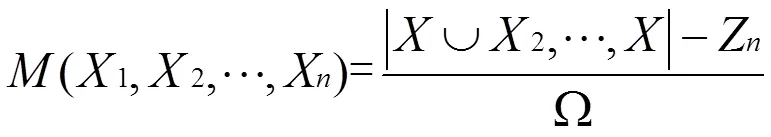

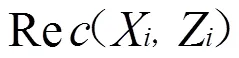



相关参数定义同模型(4)。
2 本文算法设计
考虑到当前算法存在的不足,本文设计了一种基于聚合度热点适应机制的网络舆情大数据收敛算法(Convergence Algorithm for Large Data of Network Public Opinion based on Hotspot Adaptation Mechanism of Convergence Degree, HACD算法)。所提算法主要由基于聚合度初始化机制的数据收敛方案,以及基于热点适应-差异度迭代的快速匹配方法两部分构成,详情如下。
2.1 基于聚合度初始化机制的数据收敛

按模型(6)计算收敛种子聚类的聚合度:


网络进行数据收敛时,优先逐个对热点进行收敛种子聚类差异度匹配[10],当仅当待聚合的用户节点与热点之间的差异度低于收敛种子聚类差异度时,见图2,将用户节点纳入当前热度最高的节点。

图2 基于聚合度初始化机制的数据收敛
2.2 基于热点适应-差异度迭代的快速匹配
采用基于聚合度初始化机制的数据收敛方案虽然能够较快实现用户节点收敛,然而当热点数量处于密集状态时,单纯采用该数据收敛方式很难提高收敛速度,这是由于用户特征匹配过程中难以实现快速匹配所致。因此,本文基于热点适应-差异度迭代方式构建一种快速匹配方法,详情如下:


图3 基于热点适应-差异度迭代的快速匹配方法
3 仿真实验
为验证本文算法性能,采取MATLAB仿真实验环境。在本次仿真过程中,自行构建了网络舆情数据集,利用文献[11]采用的爬虫方式,针对安徽省十九大、十九大一中全会热点新闻及安徽2009-2019年两会热点新闻爬取原始数据,爬取对象主要为微博、百度百家号、凤凰大风号、今日头条、主要新闻门户网站、主要中央新闻网站(人民网、新华网等)。热点匹配词汇为“从严治党”、“巡视”、“严重违纪”等反腐方面,单个匹配词汇爬取数据不低于1万条。与此同时,仿真实验采用当前常用的时间片累积挖掘收敛方案[12](Convergence Scheme for Time Slice Cumulative Mining,TSCM算法)及热点度显影收敛方案[13](Convergence Scheme of Hotspot Degree Development,HDD算法)。仿真指标采用收敛时间、聚类生成时间两个指标。在网络舆情数据集中,利用所提算法、文献[12]和文献[13]方法,分别在高密度热点及低密度热点环境下进行仿真。仿真参数表如下:
表1 仿真参数
Table1 Simulation parameters
参数数值 网络生存周期(min)不低于128min 节点密度不低于100 用户节点最大跳数不低于8 节点个数不低于1024 聚类类型网络舆情聚类
3.1 收敛时间
图4(a)、(b)显示了收敛时间的仿真测试结果,本文算法收敛时间显著低于TSCM算法和HDD算法,且收敛时间较为平稳,起伏较小。这是由于本文算法综合考虑到当前算法的不足,通过基于聚合度初始化机制的数据收敛方案显著增加了节点收敛速度,改善收敛质量。此外,本文设计了基于热点适应-差异度迭代的快速匹配方法,通过该方法能够进一步提高用户特征匹配速度,增强聚类形成质量。TSCM算法主要通过积累方式进行收敛,节点密度较高时需要耗费大量时间片资源进行聚类形成过程,局限性较高。HDD算法单纯采用热度最高方式进行收敛,随着节点密度不断增加,其固有的强拮抗作用将减缓聚类形成速率,因此收敛性能亦要低于本文方案。

图4 收敛时间
3.2 聚类生成时间
图5(a)、(b)显示了聚类生成时间的仿真测试结果,本文算法的聚类生成时间一直处于较低水平,且无较大幅度的起伏波动。这是由于本文算法能够通过基于聚合度初始化机制的数据收敛方案提高热点及聚类形成速度,有效增强收敛质量,因此聚类生成时间较小。TSCM算法在聚类形成过程中需要进行长时间的数据挖掘及聚类收敛,特别是随着热点密度的增加,其数据挖掘效率将呈现剧烈下降态势,因此聚类形成时间较长。HDD算法在热点密度较大时未考虑收敛速度下降的因素,导致聚类生成时间也发生剧烈波动,因此该算法的聚类生成时间要显著低于本文方案。

图5 聚类生成时间
4 结束语
为解决当前网络舆情大数据收敛算法普遍存在的热点聚类形成困难,用户收敛速度较低等不足,提出了一种基于聚合度热点适应机制的网络舆情大数据收敛算法。算法主要基于收敛度思想,分别设计了基于聚合度初始化机制的数据收敛方案及基于热点适应-差异度迭代的快速匹配方法,能够显著提高聚类收敛速度,增强网络收敛性能。
下一步,将引入超高频数据热点建模机制,提高本文算法在网络拓扑及行为多变状态下收敛性能,进一步促进本文算法在实际领域中的使用。
[1] Yang J L, Huang T, Song W M. Discover the Network Mechanisms Underlying the Connections Between Aging and Age-Related Diseases[J]. Scientific Reports, 2016, 23(6): 32-56.
[2] Guo J, Feng C. Implementation of Envelope Analysis on a Wireless Condition Monitoring System for Bearing Fault Diagnosis[J]. International Journal of Automation and Computing,2015,12(01):14-24.
[3] Wang T S, Lin H T, Wang P. Weighted-Spectral Clustering Algorithm for Detecting Community Structures in Complex networks[J]. Artificial Intelligence Review,2017,47(4): 463-483.
[4] Shu Y, Zhang L W, Liang L. Discovering Similar Chinese Characters in Online Handwriting with Deep Convolutional Neural Networks[J]. International Journal on Document Analysis and Recognition (IJDAR),2016, 19(3): 237-252.
[5] Ze X Z, Xia J, Richard N. Discovering Causal Interactions Using Bayesian Network Scoring and Information Gain[J]. BMC Bioinformatics,2016,17(1): 1021-1036.
[6] Wei Z, Xiao K Z, Zhao K. Analysis of Associtivity and Community Structure in Mobile Social Networks[J]. Procedia Computer Science,2017,107(6): 630-635.
[7] 乔少杰,郭俊,韩楠,等. 大规模复杂网络社区并行发现算法[J]. 计算机学报,2017,40(3):687-700.
[8] 张皓,王明斐,陈艳浩. 基于Kullback-Leibler距离的二分网络社区发现方法[J]. 计算机应用研究,2017,34(5): 1480-1483.
[9] Kai L, Zhi G. Image Segmentation with Fuzzy Clustering Based on Generalized Entropy[J]. Journal of Computers, 2014, 9(7): 1678-1683.
[10] Zhi Z Z, Zhen Y W. Mining Overlapping and Hierarchical Communities in Complex Networks[J]. Physica A: Statistical Mechanics and its Applications, 2015, 421(41): 296-311.
[11] Cho K, Van Merrienboer B, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Computer Science, 2014,(6):3130-3145.
[12] Yi C, Xiao L W, Xin X, et al. Overlapping Community Detection in Weighted Networks Via a Bayesian Approach[J]. Physical A: Statistical Mechanics and its Applications, 2017,468(12): 790-801.
[13] Claudio M R. Effects of Multi-state Links in Network Community Detection[J]. Reliability Engineering and System Safety,2017,163(12): 46-56.
The Convergence Algorithm for Large Data of Network Public opinion Based on Hotspot Adaptation Mechanism of Convergence Degree
SUN Jun
(School of Information Engineering, Anhui Vocational and Technical College, Liu’an, Anhui 230011, China)
In order to solve the common problems of convergence and low speed of hot spot clustering in current large data convergence algorithms of network public opinion, a new convergence algorithm of large data of network public opinion based on hotspot adaptation mechanism of convergence degree is proposed. Firstly, through the information interaction between incremental user nodes and stock hotspots, a data convergence scheme based on aggregation degree initialization mechanism is designed. The difference degree and aggregation degree between stock hotspots and incremental user nodes are compared one by one by using matching mechanism, which can bring incremental user nodes into seed clustering formed by stock hotspots with the best performance and greatly improve the aggregation class formation speed. Subsequently, aiming at the extreme situation that the number of hot spots is in a dense state, the difference degree of seed clustering is gradually eliminated by iteration, so as to improve the convergence performance of large data and the quality of information interaction between user nodes and hot spots. The simulation results show that, compared with the convergence scheme for Time Slice Cumulative Mining (TSCM) and the Hotspot Development convergence scheme (HDD), the proposed algorithm has the advantages of fast convergence speed, high clustering quality and strong practical deployment value.
aggregation degree; network pblic opinion; hotspot; difference degree; clustering matching; hotspot degree development
TP393
A
10.3969/j.issn.1674-8085.2019.06.009
1674-8085(2019)06-0047-05
2019-03-13;
2019-05-20
安徽省高等学校人文社会科学研究项目(SKA2018A0774)
孙 骏(1970-),男,安徽六安人,副教授,硕士,主要从事计算机网络、网络舆情等方面的研究(E-mail:junsun70@sina.com).
猜你喜欢
加油站服务指南(2022年6期)2022-07-28 06:07:02
食品与发酵工业(2021年14期)2021-08-02 12:47:08
车迷(2019年10期)2019-06-24 05:43:28
快乐语文(2018年7期)2018-05-25 02:32:00
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
安徽化工(2016年5期)2016-02-27 08:25:04
中国民政(2016年24期)2016-02-11 03:34:38
天然产物研究与开发(2014年1期)2014-04-27 14:15:13
中国记者(2014年6期)2014-03-01 01:39:53
