
基于混合采样和Stacking集成的电信用户网别预测
2019-11-25 05:34卢光跃闫真光吕少卿
西安邮电大学学报 2019年4期
卢光跃, 闫真光, 吕少卿, 吴 洋
(西安邮电大学 陕西省信息通信网络及安全重点实验室, 陕西 西安 710121)
电信用户网别更换是指原有使用电信运营商2G、3G网络服务的用户迁移至该运营商的4G网络。电信用户网别更换是一种非契约关系下的用户迁移。在非契约关系下,用户发生迁移网络行为甚至离网行为很难被电信运营商所知,而利用数据挖掘模型,则可准确识别即将换网的潜在目标用户,对其进行针对性的劝转分流。
电信业务预测本质上属于监督学习的分类任务,但真实电信用户数据集中的分类问题,如用户欠费、用户离网以及用户网别更换等问题都是不平衡比例较大的分类问题。现有的决策树、随机森林和支持向量机等分类器算法,通常在均衡数据集上具有良好的分类效果[1],而对不平衡数据进行预测时,会偏向多数类样本而忽略少数类样本的预测性能,导致分类器算法对少数类样本预测精度远小于对多数类样本预测精度[2-3]。
目前,处理不平衡数据集有数据层面和算法层面[4]两种解决途径。算法层面主要是对分类器算法进行改善以适应不平衡数据,但这样会增加算法开销[5-7]。数据层面方法主要使用过采样和欠采样技术对原始数据进行均衡处理[8]。人工合成少数类过采样方法(synthetic minority oversampling technique,SMOTE)[9]通过对少数类样本的插值进行数据扩充,可应用于各不平衡子集,结合随机森林分类器实现分类预测[10];或者给少数类边界样本更高的支持度,从而根据支持度较高的样本进行SMOTE采样,以避免过采样的盲目性[11]。欠采样技术则是对多数类采样,自动聚类欠采样(automatic clustering under-sampling,ACUS)通过带有样本权值的聚类,选择每个簇中权值较高的多数类样本和全部少数类样本,构建平衡数据集提高分类器算法精度[12];基于遗传算法的欠采样方法(under-sampling method using genetic algorithm,GAUS)通过遗传算法进行多数类样本选择,并且使用分类器性能作为遗传算法的适应函数以避免分类边界的失真[13]。但是,单独采用欠采样或者过采样方法,都会发生关键数据丢失或模型过拟合的问题。
基于具有噪声的密度聚类欠采样方法(density-based spatial clustering of applications with noise,DBSCAN)[14]不必事先指定簇数目,并对噪声数据不敏感,根据数据中元素密度进行数据集聚类,便能够分析出任意空间形状。因此,本文拟基于DBSCAN与SMOTE相结合的混合采样方法(DS-HS),对电信用户数据集进行均衡处理,并利用Stacking集成学习算法训练得出分类结果,从而建立网别预测模型,识别潜在的网别更换用户。
1 电信用户网别更换预测模型的建立
电信用户数据包括脱敏后用户标识、用户入网龄、用户性别、用户年龄、月使用流量、月通话时长和使用网别等12维属性。其中数值类型属性可以直接使用,性别属性需通过one-hot编码后使用。确定电信用户数据集的网别更换标签,便可利用混合采样方法对电信用户数据集进行均衡处理,再通过Stacking集成学习算法训练分类预测模型,从而完成网别更换的分类预测。
1.1 网别更换标签的生成
将电信用户前10个月的使用数据作为历史数据,后2个月的用户信息生成用户换网标签,0表示网别未发生改变,1表示网别改变。电信用户数据集中始终使用4G网络的用户占数据集多数,为多数类样本,对应标签为0;电信用户数据集中2G、3G网络迁移至4G网络的用户占数据集少数,为少数类样本,对应标签为1。
1.2 DBSCAN聚类欠采样
设多数类样本邻域半径为ε,邻域半径内包含最少样本点个数为Mp。若某一多数类样本的ε领域内样本点个数大于Mp,则为核心用户点;若小于Mp且在其余核心用户点邻域半径内,则为边界样本点;余下样本点属于噪声样本。
将DBSCAN聚类过程遍历多数类样本集,并设置ε=0.8、Mp=15实现样本标识。若某一多数类样本点被标识为核心用户点,则创建包含该样本点的新簇C,并将其邻域内全部样本对象放入簇C的候选集中。若候选集中样本对象还未属于其他簇,则检查候选样本邻域内是否包含至少Mp个样本点,满足则添加至簇C;遍历检查候选集中样本并扩展簇C。循环检查每次加入簇C中的候选集,直至簇C中再无新样本点加入,即簇C完成聚类。从剩余多数类样本集合中随机选择未被标识的样本点,根据上述过程继续聚类,直至所有样本点遍历完毕,最终完成多数类样本集合的DBSCAN聚类。
利用DBSCAN聚类实现电信用户多数类样本集合的簇集合划分,剔除所有噪声样本点,选择各簇中的核心样本点提升欠采样效果。
1.3 SMOTE过采样
SMOTE过采样通过启发式方法合成少数类样本,避免对少数类样本的反复选择,使用插值生成新的少数类样本,从而避免分类器模型的过拟合[12]。过采样方法步骤如下。
步骤1设少数类样本集合
D={x1,x2,…,xM},
其中xM表示第M个样本,初始化过采样率为N。
步骤2利用欧式距离计算所有少数类样本与样本xM的距离,得到k个最近邻样本。
步骤3根据过采样率N,从k个最近邻样本中随机选择P个样本。假设最近邻样本为xp,[0,1]区间内的随机数为ω,则新合成的少数类样本可表示为
x′=xM+ω(xp-xM)。
(1)
步骤4依次选择少数类样本集合中每一个样本并确定其最近邻样本,再根据式(1)生成新样本,最终实现全体少数类样本的过采样。
对于电信用户数据集生成标签后的两类样本集合,并行使用过采样和欠采样构建平衡数据集。多数类样本采样率为N=1/10,即使用DBSCAN聚类欠采样,选择原多数类样本总数的1/10样本;少数类样本则根据采样完成后全体多数类样本总数设定过采样率,利用SMOTE过采样插值生成新少数类样本,从而完成数据集均衡过程。
1.4 Stacking集成学习训练模型
Stacking(Stacked generalization)也称堆叠算法[15],是一种基分类器集成学习方法,可以整合多个异质基分类器,从而根据不同基分类器的预测差异性保证整合后的最终预测结果[16]。
将混合采样均衡后的电信用户数据集输入至两层Stacking集成学习结构,第一层学习结构由决策树、随机森林和Adboost等3个异质分类器组成,第二层学习结构则由单个逻辑回归分类器构成。具体网别预测模型训练过程如下。
步骤1输入均衡数据集I,划分为训练集Itrain和测试集Itest,设置交叉验证折数为10折。
步骤2第一层学习,将训练集Itrain按照交叉验证折数划分10份,挑选其中9份不相交样本集用于异质分类器训练,训练所得分类器对剩余1份样本集和Itest集合预测,获得网别更换标签;重复上述过程10次,获得Itrain全部样本分类预测结果和全部异质分类器对Itest的10次预测结果。
步骤3第一层3个分类器对Itrain的全部分类预测标签和其原始网别更换标签构成第二层学习训练集,对Itest的10次预测结果求平均后标签值和其原始类标签构成第二层学习测试集。
步骤4第二层学习。将步骤3中训练数据输入第二层分类器,并完成第二层测试集数据的预测,实现电信用户数据集网别更换预测。
构建电信用户网别更换预测模型的流程如图1所示。

图1 电信用户网别更换预测模型构建流程
2 实验分析
2.1 实验数据集描述
实验数据集分别为Crowd sourced Mapping、Winequality-White和Wilt等3个不平衡的UCI数据集[17]及脱敏电信用户数据集,如表1所示。将均衡后的数据集中75%样本为训练数据,剩余25%为测试数据进行训练。
2.2 不同采样方法的性能比较
根据不平衡电信数据集分类评价指标[18],即少数类样本检测精度TPR、多数类样本检测精度TNR和整体预测性能的评价指标Gm,分别验证随机混合采样方法、ACUS欠采样方法、DE-NHS采样方法[19]和DS-HS采样方法处理不平衡电信用户数据集的均衡性能,对比结果如表2所示。由表2可以看出,DS-HS采样方法预测网别更换用户的精度为86.1%,预测未更换网别用户的精度为85.5%,整体预测性能为85.9%,均高于随机混合采样、ACUS和DE-NHS方法,具有较好的数据集均衡性能。
2.3 不同分类算法的性能比较
采用DS-HS采样方法,将均衡后数据集分别输入至Stacking、Adaboost和使用投票法代替原Stacking二层分类器的分类算法,进而对比预测结果,如表3所示。从表3可见,Stacking分类算法预测少数类样本性能和整体预测精度性能均优于Adaboost和Stacking二层投票分类算法。

表1 数据集信息描述
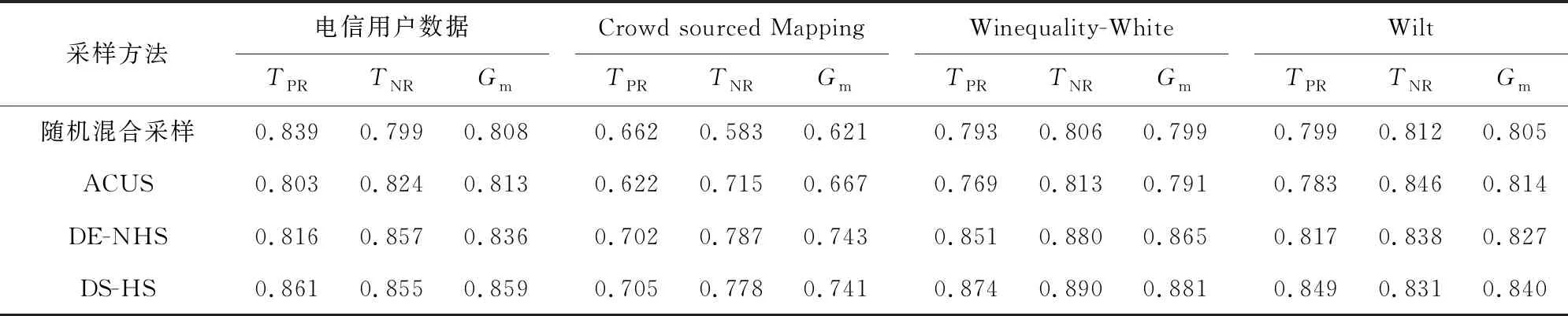
表2 不同采样方法的均衡性能对比

表3 不同分类算法仿真结果对比
3 结语
基于混合采样和Stacking集成学习的电信用户网别预测模型,根据历史用户数据生成网别更换标签,结合DBSCAN聚类欠采样去除样本集中噪声样本和SMOTE过采样插值生成新样本的混合采样方法,完成了数据集均衡处理。通过Stacking集成学习算法训练分类预测模型,从而完成了网别更换的分类预测。实验结果表明,该模型比随机混合采样、ACUS和DE-NHS采样方法预测准确率高,具有较好的数据集均衡性能,同时与Adaboost和Stacking二层投票分类算法相比,能够更好识别潜在的网别更换用户。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
