
基于人工智能的医院临床研究信息平台开发与实现
2019-11-22 02:11胡龙军高文学蔡国君王聪健侯冷晨杨佳芳1c陈恳陈跃军
中国医疗设备 2019年11期
胡龙军,高文学,蔡国君,王聪健,侯冷晨,杨佳芳,1c,陈恳,陈跃军
1. 同济大学附属第十人民医院 a. 医务处;b. 临床研究办公室;c. 信息处,上海 200072;2. 上海森亿医疗科技有限公司,上海 201203
引言
科研已经成为临床医生一项非常重要的工作内容[1]。然而,临床业务工作占据了医生大部分时间,使医生在科研上投入的精力相对有限。另外,在科研过程中,病历数据的查询和收集也占据大量时间,延长了医生的科研周期[2]。能否使医院医疗大数据快速有效的被应用已成为临床科研发展面临的重要挑战。目前,人工智能在虚拟助理[3]、医学影像[4]、病理诊断[5]、医院管理[6]等广泛应用,但医院的大数据应用存在技术基础薄弱、数据整合与挖掘难度高、应用需求和策略不明晰等问题,未能有效满足临床医生科研应用需求[7]。
为使临床人员能便捷、充分获取院内数据,提升院内大数据的应用能力,现介绍我院基于人工智能开发的临床研究信息平台,以期为临床人员提供临床科研过程中数据的采集、分析和管理服务,从而提升医院科研水平和综合竞争力。
1 平台系统设计
针对数据驱动的临床研究场景,集成医院海量临床信息库(HIS、EMR、LIS、RIS 等),基于自然语言处理、机器学习等AI 引擎实现各类医学文本数据的结构化、标准化和归一化等处理,形成可被临床研究直接分析、利用的科研数据。基于治理后的数据,面向临床应用提供辅助诊疗模型、专病知识问答、语义搜索引擎服务,最终实现面向临床的数据需求功能(CRF 电子表单设计和数据分析)、数据检索功能(简单检索和智能检索)、队列研究功能(筛选数据、交叉分析和订阅数据)、随访功能(远程随访问卷和智能健康咨询)、数据安全功能(用户权限管理和数据访问管理)、数据展示功能(科研数据治理和科研数据概览)等(图1)。

图1 临床研究信息平台系统设计
2 人工智能技术应用
由于医疗领域的专业性和特殊性,医学领域的自然语言处理技术落后于通用领域。在中文医学领域,现有的自然语言处理工具仅能针对医学文本做一些特定词表和规则匹配,或是套用通用领域的自然语言处理模型,其效果和可靠性都难以达到使用要求。
本院开发的信息平台,依托医院内部海量语料数据,将入院记录、病程记录、检查报告中的检查所见、检查结论、手术操作中的操作记录以及出院记录等语法、语义多样的自然语句描述的非结构化医学文本内容作为输入信息,基于自然语言处理算法、深度学习算法,完成分词、命名实体识别、关系提取处理过程从而实现结构化变量的输出,进一步做标准化处理。人工智能技术处理医学文本信息示意图,如图2。
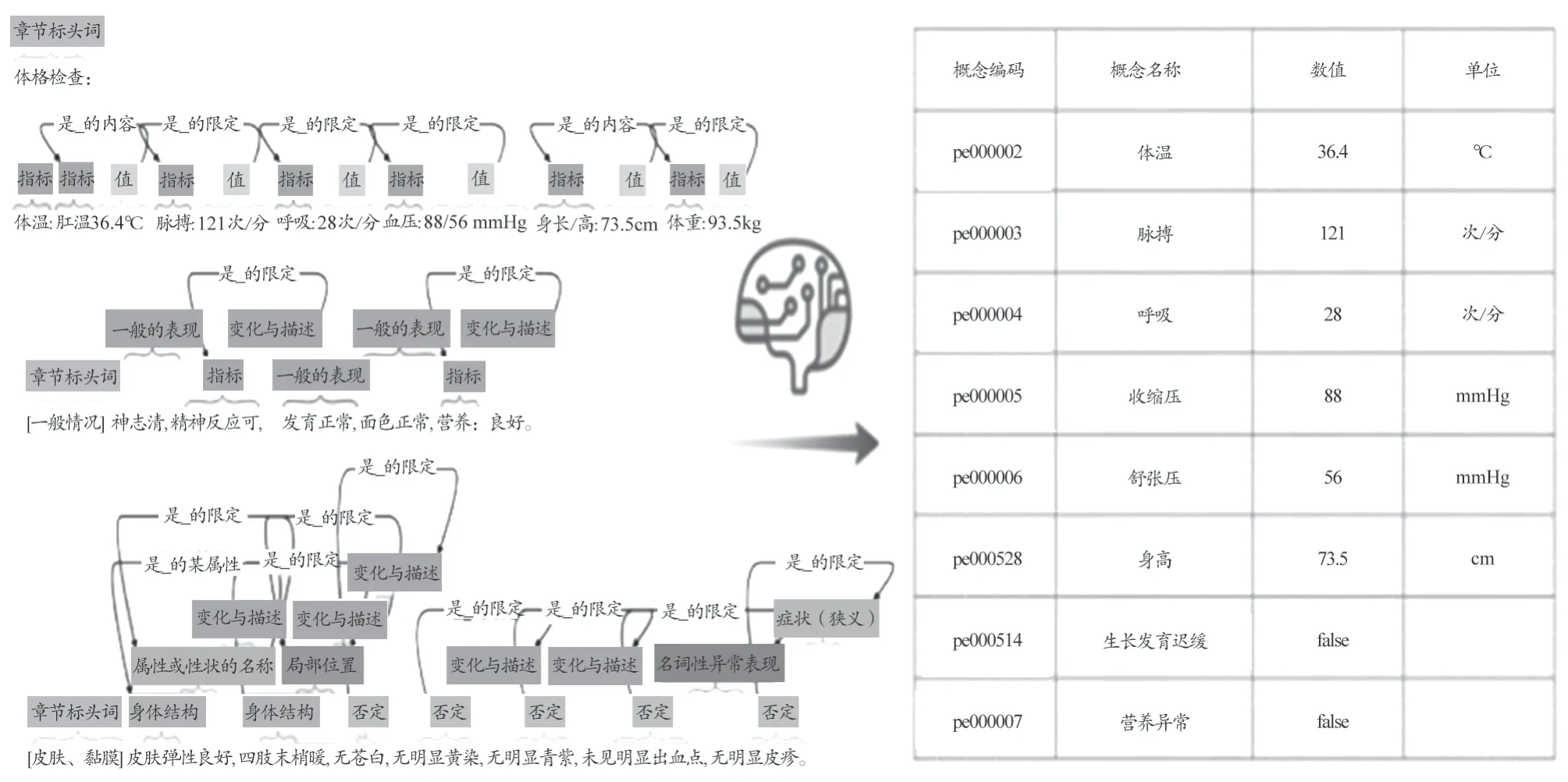
图2 人工智能技术处理医学文本信息示意图
另外,通过使用深度学习和自然语言处理自动化辅助构建的图结构的术语网络,整合医学逻辑范畴网络以及中文语用范畴网络,使术语网络同时具备精确性、形式性、计算性、可读性等特点,让人工智能可以通过网络理解中文,理解医学逻辑。
3 平台系统架构
系统开发环境为Windows 和OSX,采用HTML5、Angular 和C#编程语言。采用容器云技术搭建分布式架构医院信息平台,与院内业务系统、院外随访系统对接,利用消息中间件实现各业务系统的数据整合。容器云架构中基础设施层采用Kubernetes 进行容器编排,Ceph 进行分布式存储,Flannel 构建虚拟子网;管理层负责发布、监控、管理信息平台应用的服务;应用层通过Orion Health Rhapsody 消息引擎和Kettle 数据ETL 引擎,建立统一的数据交换接口,同业务系统与数据库相独立,双方发生问题时都不会影响对方业务系统使用。临床研究信息平台硬件系统架构,如图3。
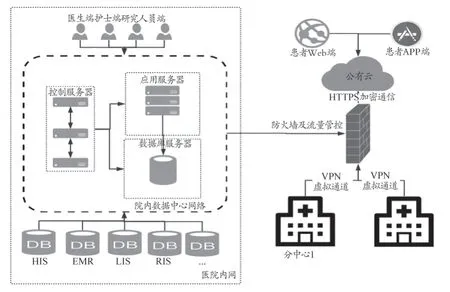
图3 临床研究信息平台硬件系统架构
未来,本研究项目将涉及多中心医院数据,各分中心可通过VPN 协议发起申请,无需共享原始医疗数据,经线上线下结合的审批流程后直接返回数据统计结果和质量报告。
4 平台建设成果
开发建成了具有“科研项目、智能搜索、队列发现、随访管理、系统管理、科研驾驶舱”等六大功能模块的信息平台(图4)。
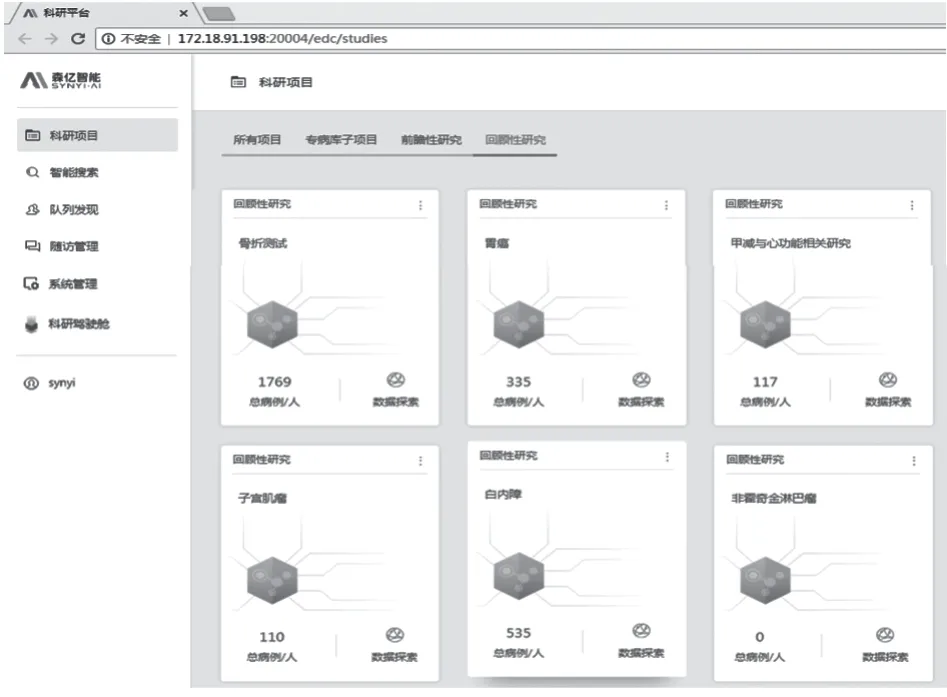
图4 医院临床研究信息平台界面
4.1 科研项目
该模块可满足用户科研数据的定向需求,即用户可在该系统中根据研究目的自定义设计CRF 电子表格模板,待模板需求信息明确后,可从智能搜索和队列发现模块中入组信息,对于遗漏空白内容,也可查找对应病历信息针对性补充。
该模块的数据探索功能可支持对定向需求中的科研数据的分析,包括数据清洗、数据查询、统计分析和预测模型四部分。其中数据清洗能够实现对数据进行自动或半自动化清洗,以及分析型变量的衍生,即缺失值与异常值的处理、数据转换与分组、一个患者多条记录数据处理等;数据查询可对清洗后的数据进一步直观了解;统计分析功能可帮助用户对数据进行简单描述性分析;预测模型功能嵌套了多种主流的机器学习模型,帮助用户快速构建精度更高的疾病预后与诊断模型,同时基于构建的机器学习模型对研究疾病进行个体化的预测。
4.2 智能搜索
4.2.1 简单检索
支持直接输入关键字、疾病、诊断、ICD 码等任意搜索词,可以搜到符合检索条件的患者和病历。在简单检索里面可以通过切换姓名、门诊号、住院号、医保卡号和病案号对相关患者进行精准检索。
4.2.2 智能检索
支持多条件、复杂组合、独立变量、同一次就诊、事件时序等高级检索,支持对医院系统的结构化信息(个人信息、就诊信息、过敏消息、诊断信息)和非结构化信息(放射报告、入院记录、出院小结、病案首页)等进行检索,同时支持对搜索结果进行细化和多条件关系再搜索。
以上两种搜索结果,可根据“筛选工具”对患者的年龄、性别、病历年份、就诊类型、就诊科室作进一步的筛选。
4.3 队列发现
队列发现模块有三大功能:① 将智能检索结果加入该模块中,同时通过韦恩图筛选符合研究要求的队列数据,并进行可视化展示;② 通过韦恩图对不同队列数据进行交叉分析;③ 订阅管理,当队列数据量太少无法满足研究需要时,设置数据订阅条件,待医院产生的新数据进入平台后,符合条件的会自动进入研究队列中。
4.4 随访管理
用户可在该系统中根据不同病种自定义设计随访表单模板,该系统可对微信绑定认证的随访患者推送表单,并会默认将对应随访表单作为微信消息的链接自动推送给患者,患者可通过微信公众号打开查看并填写,提交后数据会显示在该系统对应表单里;另外,该模块存储大量健康知识库,用户可以通过绑定微信,输入关键字,获取相关健康内容。
4.5 系统管理
系统管理是对用户进行一些权限管理与数据安全管理,严格控制患者信息。给每个科室开放一个账号,针对不同科室、科室内人员设置不同的数据访问权限,若临床人员从该平台导出数据,需向临床研究办公室提出申请。
4.6 科研驾驶舱
科研驾驶舱是对全院科研数据集中展示,包括数据治理中心和科研数据概览两大功能,其中数据治理中心从多个维度展现数据集成和治理工作成果(图5),数据治理中心子模块:基于各类医学术语标准,将诊断、检验、药品的文本信息归一为2893 类、1041 类、6169 类;在此基础上,已完成诊断、检验、药品的标准化数据量为32498155 条、18233285 条、80900072 条;同时结构化各类检查报告、病历文书、入院记录等文本信息1259019 份。科研数据概览子模块:可查看入组病例数、已录入字段数、已进行随访次数等数据,用户也可查看项目的进度情况,包括已结束、正开展和未发布等。

图5 科研驾驶舱功能模块中展示的全院数据治理情况
5 展望
5.1 临床研究信息平台助力医院科研工作上升新台阶
现有医院信息系统已比较完善,但缺乏医疗大数据治理、分析、应用的信息化、智能化支撑平台,导致基于医疗数据驱动的临床研究受限。针对普遍存在临床数据采集与医院信息系统割裂、数据分散在多个应用系统(如检验、放射、病理等)、缺少患者随访跟踪支持软件[8]等问题,本院开发的临床研究信息平台可为医院数据的存储、采集、分析等提供一站式服务与管理。医院科研人员不仅可快速检索历史数据,也能创建队列收集实时数据,更能获得智能化数据分析支持。目前,本院心内科与骨科已在该平台建立单病种队列研究项目,并实时获取样本数据,为其节省大量时间,极大提升科研效率。由于数据驱动模式是临床问题发现的重要方式之一[9],该临床研究信息平台的建立,将解决长期困扰临床医生的数据难获取问题,助力其解决临床问题,提升个人临床能力水平,促使医院科研能力进一步发展,从而提高医院整体竞争力。
5.2 人工智能驱动医疗大数据发挥巨大价值
随着医疗卫生信息化建设的进程加快,医疗数据的类型和规模正以前所未有的速度增长,以至无法利用目前主流软件工具,在合理时间内达到撷取、管理并整合目的[10]。针对不同来源和不同格式的数据,规范化的收集存储是第一道工序[11]。然而,医疗信息以文本形式储存为主,且存在歧义和非标准化描述,如何将其转化为结构化可利用数据非常困难[12]。自然语言处理是人工智能领域重要基础技术[13],目前自然语言处理在语义分析、知识库建设和文本处理方面取得很大进展[14],可实现各类医学文本数据的结构化、标准化和归一化。另外,机器学习作为人工智能的一个重要分支[15],具有高效率、高准确性等诸多优点,其和医学领域的结合已经成为当前热点之一[16]。例如,梅奥诊所借助其所研发的临床文本分析和知识抽取系统完成对过往病历、医学文献的解析及知识提取,最终形成机器智能辅助临床诊疗[17]。可见,医疗大数据蕴含价值巨大,但如没有人工智能发展及由此带来的自然语言处理、机器学习等技术的进步,数据价值很难被挖掘和应用。所以说,随着人工智能不断发展,医疗大数据能被充分利用,必将发挥巨大价值,促进医疗健康事业快速发展。
猜你喜欢
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
商界(2019年12期)2019-01-03
军营文化天地(2018年2期)2018-12-15
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
