
一种多语种生成式自动摘要方法的实现
2019-11-20 05:52易志伟赵亚慧崔荣一
延边大学学报(自然科学版) 2019年3期
易志伟, 赵亚慧, 崔荣一
( 延边大学 工学院, 吉林 延吉 133002 )
0 引言
文本摘要通常是指从一个文档中生成一段包含原始文档主要信息的文本.由于文本摘要的篇幅相比原始文档大幅减少,因此可为读者节省大量阅读时间,同时也可起到信息压缩的作用.1958年, Luhn首次提出了基于“簇”的自动摘要方法[1].相比人工撰写摘要,由于自动摘要技术可以大幅提高撰写摘要的效率,因此引起了学术界的广泛关注.目前,生成自动摘要的方法可分为抽取式摘要(extractive summarization)和生成式摘要(abstractive summarization).抽取式摘要的特点是摘要中的句子是原文中的句子,又叫做“句子摘录”.该方法通常使用TextRank[2]和LexRank[3]算法在文本中进行摘要句的抽取,但由于这两种算法都是基于PageRank算法[4]对拓扑图进行迭代计算,所以抽取式摘要所抽取的句子往往含有大量冗余信息,并且句子之间连贯性不强,可读性较差.生成式摘要的特点是摘要中的句子是重新生成的句子,其使用的方法主要是基于序列到序列(sequence - to - sequence, Seq2Seq)模型的深度学习方法[5].由于该方法生成的摘要具有长度较短、冗余性较低、句子的概括性较强等优点,因此生成式摘要更加受到了学者的青睐[6-8].但目前为止,基于Seq2Seq模型的生成式自动摘要系统只能处理单一语种的文本,若要处理其他语种的文本,需要利用其他语种的语料重新训练新的模型.本文将中、英、朝3种语种的训练数据一起训练,得到一个可以同时处理中文、英文、朝文3种文本的多语种自动摘要模型,并通过实验验证本文方法的有效性.
1 生成式摘要模型
循环神经网络(recurrent neural network,RNN)[9]的主要用途是处理、预测序列数据和挖掘数据中的时序信息,常用于语音识别、语言模型以及机器翻译等领域.循环神经网络的内部结构如图1所示.
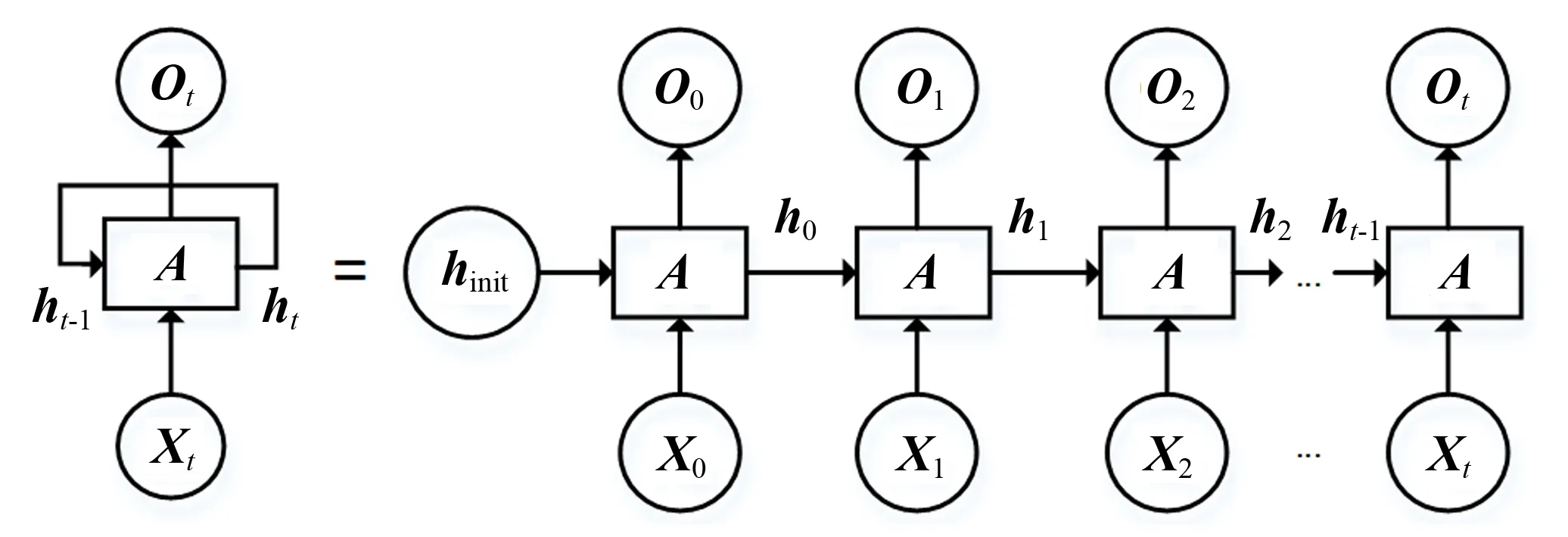
图1 循环神经网络按时间展开后的结构图
在循环神经网络中,输入为一个序列,用X={X0,X1,X2,…,Xt}表示.在每个时刻t, RNN的隐藏状态ht由式(1)更新.
ht=f(ht -1,Xt),
(1)
其中f代表一个非线性激活函数,可以是sigm oid函数或tan h函数.RNN网络可以学习从开始到当前时刻的信息,并对下一个时刻的输出进行预测.例如,在文本预测的任务中,对于当前时刻t, 输出Ot的概率分布为P(Xt|Xt -1,Xt -2,…,X1).根据式(2),对词袋中的每一个词Xj依次计算P(Xj), 计算得到的概率即为词袋中每个词在下一个时刻出现的概率.
(2)
式(2)中,W为一个参数矩阵,Wj是矩阵的第j行,Ot是循环神经网络在t时刻的输出,K是词袋的大小,j∈[1,K].由于标准的循环神经网络学习远距离信息的能力较弱,因此很多学者对标准的循环神经网络进行了改进.例如: S.Hochreiter等提出的长短时记忆网络(long short - term memory, LSTM)[10],K.Cho等提出的门控循环单元(gated recurrent unit, GRU)[11],Tao等提出的简单循环单元(simple recurrent unit, SRU)[12].由于长短时记忆网络能够记忆历史信息,学习远距离信息的能力较强,因此本文使用长短时记忆网络.
Seq2Seq模型由2个循环神经网络组成:一个负责对输入序列进行编码,称为编码器(encoder);一个负责对目标序列进行解码,称为解码器(decoder).Seq2Seq模型的基本流程为:首先使用一个循环神经网络读取输入的句子,并将整个句子的信息压缩到一个固定维度的编码中;然后再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子.Seq2Seq模型示意图如图2所示.
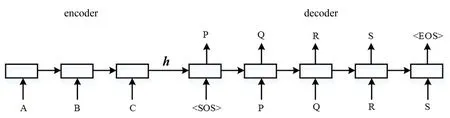
图2 Seq2Seq模型示意图
在图2中,A、B、C是输入序列,〈SOS〉、P、Q、R、S、〈EOS〉是目标序列.Encoder将来自输入序列的信息编码成一个中间的语义向量h, Decoder接收语义向量h, 并将其解码为输出序列.Seq2Seq模型的目标函数是最大化对数似然函数P(Y|X):
(3)
其中T表示输出序列的时间序列大小,y1:t -1表示输出序列的前t-1个时间点对应的输出,X为输入序列.式(3)将自动摘要问题视为条件语言模型.建立该模型的目的是为在已知输入文本的条件下,使生成整个目标摘要句的概率最大.
2 多语种自动摘要系统的设计
传统的基于Seq2Seq模型的自动摘要系统只能处理单一语种的文本.在此以中文为例,描述其生成自动摘要的步骤.
Step1 对中文所有训练语料进行预处理,训练语料由文本和对应的摘要成对组成(“文本-摘要”对).首先分别获取训练语料的文本部分和摘要部分的词表,并在2个词表中都添加〈unk〉用以表示未登录词.在输入端和输出端得到2个词表后,还需要在输出端的摘要词表中添加〈SOS〉和〈EOS〉,用以表示摘要的开始和结束.
Step2 对所有输入端的文本进行分词,并将文本的词项序列按照每个词项在词表中的id转换为数字序列,未登录词用词表中的〈unk〉来替代.同时,将输出端所有摘要句的开头处加上〈SOS〉,在摘要句的末尾处加上〈EOS〉,并按照输出端的词表将摘要的词项序列转换为数字序列,未登录词用词表中的〈unk〉表示.
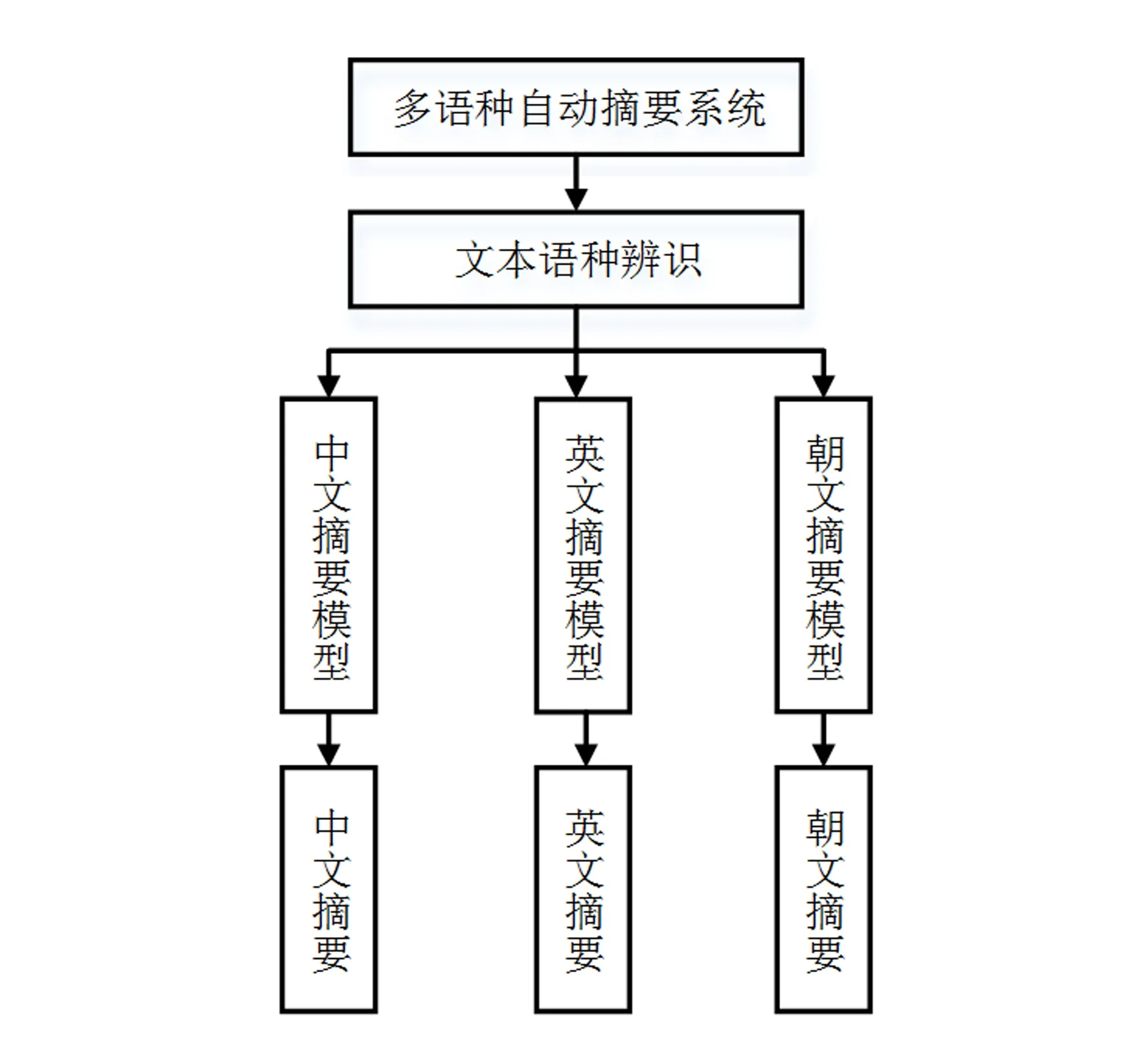
图3 传统的多语种摘要模型
Step3 将所有的训练数据转换为数字序列后,用Seq2Seq模型对其进行训练.
若要使传统的自动摘要系统能够处理多语种的文本,则需要额外训练对应语种的模型,并将不同语种的模型结合起来使用.以中、英、朝3种语种为例,传统的多语种自动摘要系统的工作方式如图3所示.由图3可以看出,传统的多语种自动摘要系统需要先分别训练中文、英文和朝文的摘要模型,然后再将他们融合到一起.输入文本后,系统首先进行语种识别,然后调用对应语种的摘要模型来生成摘要.
本文提出的多语种自动摘要系统的构建方式如下:
Step1 训练中文、英文、朝文3个语种语料的文本部分和摘要部分.首先将3个语种的文本部分和摘要部分分别放在一起,然后分别获取文本部分和摘要部分的词表,并在这2个词表中都添加〈unk〉用以表示未登录词.在输出端得到摘要部分的词表后,在该词表中添加〈SOS〉和〈EOS〉,用以表示摘要的开始和结束.
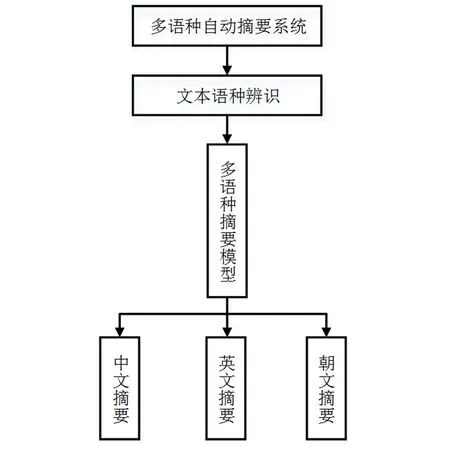
图4 本文提出的多语种自动摘要模型
Step2 对所有输入端的文本进行分词,并按照每个词项在词表中的id将文本的词项序列转换为数字序列,未登录词用词表中的〈unk〉来替代.同时,将所有输出端的摘要句的开头加上〈SOS〉,在摘要句的最后加上〈EOS〉,按照输出端的词表将摘要的词项序列转换为数字序列,未登录词用词表中的〈unk〉表示.这样,输入端和输出端的词表中都含有3种语言的单词.训练数据由3部分组成:中文的“文本-摘要”对、英文的“文本-摘要”对和朝文的“文本-摘要”对.
Step3 将所有的训练数据转换为数字序列后,用Seq2Seq模型对其进行训练.
上述的多语种自动摘要模型如图4所示.
3 实验结果与分析
3.1 实验语料
本实验采用的数据均来自科技文献(包含生物、海洋和航空3个领域)的摘要和标题,其中将摘要作为模型的输入,将标题作为模型的输出.实验的训练语料和测试语料的数量如表1所示.

表1 训练和测试语料的数量
3.2 评价指标
评价指标采用ROUGE(recall-oriented understudy for gisting evaluation)方法,该方法目前被广泛应用于摘要的自动评测任务中[13].ROUGE评价方法中包含5种评价指标,分别为ROUGE -N、ROUGE -L、ROUGE -W、ROUGE -S、ROUGE -SU,其中每一种指标都要分别计算P(precision,准确率)、R(recall,召回率)和F(F-measure,F值).目前,通常使用ROUGE -1、ROUGE -2和ROUGE -L指标中的F值作为自动摘要的评价指标.ROUGE -1和ROUGE -2均属于ROUGE -N指标,其计算公式为:
(4)
(5)
(6)
其中:n-gram表示n元词; {ref-summaries}表示参考摘要,即人工撰写的摘要; {sys-summaries}表示计算机生成的摘要;Count(n-gram)表示句子中的n-gram数量;Countmatch(n-gram)表示计算机生成的摘要和参考摘要中同时出现n-gram的数量;N表示n-gram的长度;ROUGE-N(F)为ROUGE-N(P)和ROUGE-N(R)的调和平均数.ROUGE -L指标的计算公式如下:
(7)
(8)
(9)
其中:X表示参考摘要;Y表示计算机生成的摘要;len(X)表示X的长度(词项个数);len(Y)表示Y的长度;LCS(X,Y)表示X和Y的最大公共子序列的长度;ROUGE-L(F)为ROUGE-L(P)和ROUGE-L(R)的调和平均数.
3.3 实验及结果分析
实验的训练参数设置如下: Seq2Seq模型中的编码器和解码器都采用长短时记忆网络结构,隐层神经元个数设为100,迭代次数设为20次.训练单语种摘要模型时,先对输入端的文本进行预处理,然后按词频从大到小的顺序保留前5 000个词作为输入端词表;输出端生成词表的方式和输入端一样,但由于输出端的摘要比输入端的文本长度短,因此保留前2 000个词作为输出端词表.训练中、英、朝3种语种摘要模型时,输入端将3种语料的输入端词表均放在一起并去重,由此得到一个新的词表;输出端将3种语料的输出端词表均放在一起并去重后,由此得到一个新的词表.
实验时首先分开训练中、英、朝3个语种的语料,然后用各自的模型分别运行它们的测试集,并记录ROUGE评分.再将中、英、朝3个语种的语料放在一起训练,然后运用该模型分别运行中、英、朝3种语料的测试集,并记录ROUGE评分.实验结果如表2所示.
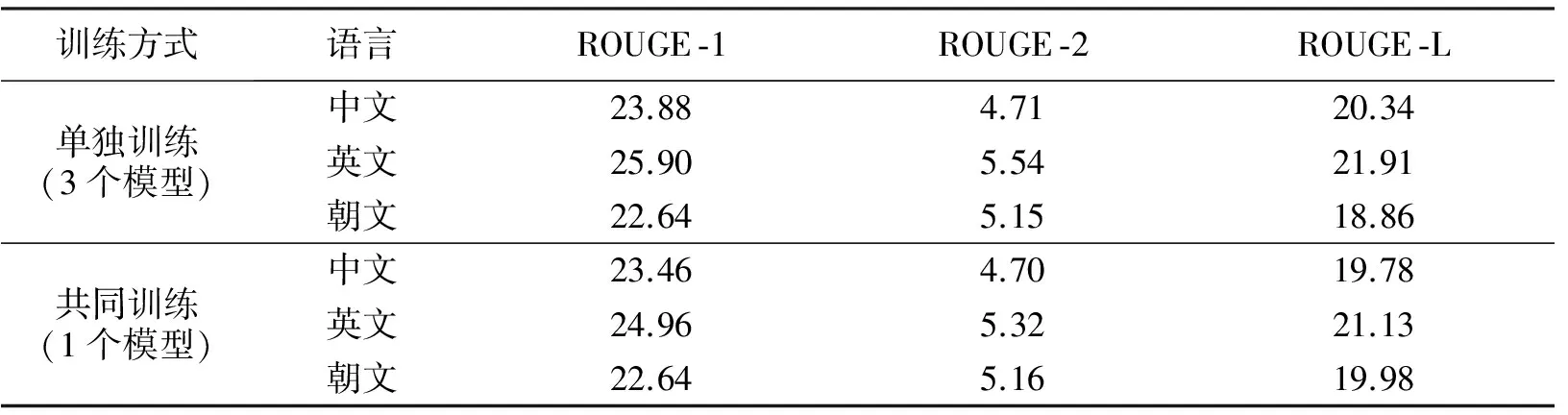
表2 不同训练方式下的实验结果
从表2可以看出,本文方法在中文和英文测试集上的3个ROUGE指标仅略低于单独训练模型所得的3个指标,可忽略不计;而在朝文测试集上,两种方法的3个ROUGE指标基本相同.这表明,本文的训练方法有效.
表3为同一文本在两种模型下所得的摘要样例.由表3可以看出,在中文样例和英文样例中,使用本文方法生成的摘要比使用传统方法生成的摘要更接近参考摘要的语义;而在朝文样例中,使用传统方法的效果相对更好.综合来看,本文方法生成摘要的效果与传统方法接近,因此表明本文方法有效.
4 结论
实验结果表明,将中、英、朝3个语种的语料放在一个模型中训练,其效果与各语言单独训练的效果接近,说明本文提出的将3种语种共同训练的方法是有效可行的.由于本文方法比传统方法简洁、高效,因此具有更好的潜在应用价值.本文在实验中,使用的训练语料规模较小,模型的泛化能力较弱,因此在今后的研究中我们将扩大训练数据规模,提高模型的泛化能力,以此进一步验证和完善本文方法.

表3 同一文本在两种模型下所得的摘要样例
猜你喜欢
韩国语教学与研究(2022年1期)2022-09-19
广东教学报·教育综合(2022年69期)2022-06-23
时代邮刊(2021年8期)2021-07-21
英语世界(2021年13期)2021-01-12
——三份医学英语词表比较分析
江西理工大学学报(2020年2期)2020-05-21
中国边疆民族研究(2014年0期)2014-02-13
新东方英语(2014年1期)2014-01-07
图书馆建设(2012年3期)2012-10-23
对联(2011年20期)2011-09-19
高中生·天天向上(2009年11期)2009-12-17
